神经网络加速器硬件架构
脉动阵列(谷歌TPU系列)
TPU中的脉动阵列及其实现:https://www.cnblogs.com/sea-wind/p/10995360.html
深入理解Google TPU的脉动阵列架构:http://chips.dataguru.cn/article-11106-1.html
IC基础(六):3x3脉动阵列计算矩阵相乘:https://blog.csdn.net/MaoChuangAn/article/details/88992191
特点

达芬奇架构(华为Ascend系列)
华为的通用AI之路:深度解读达芬奇架构硬件篇:http://www.360doc.com/content/19/0829/15/49486385_857764589.shtml
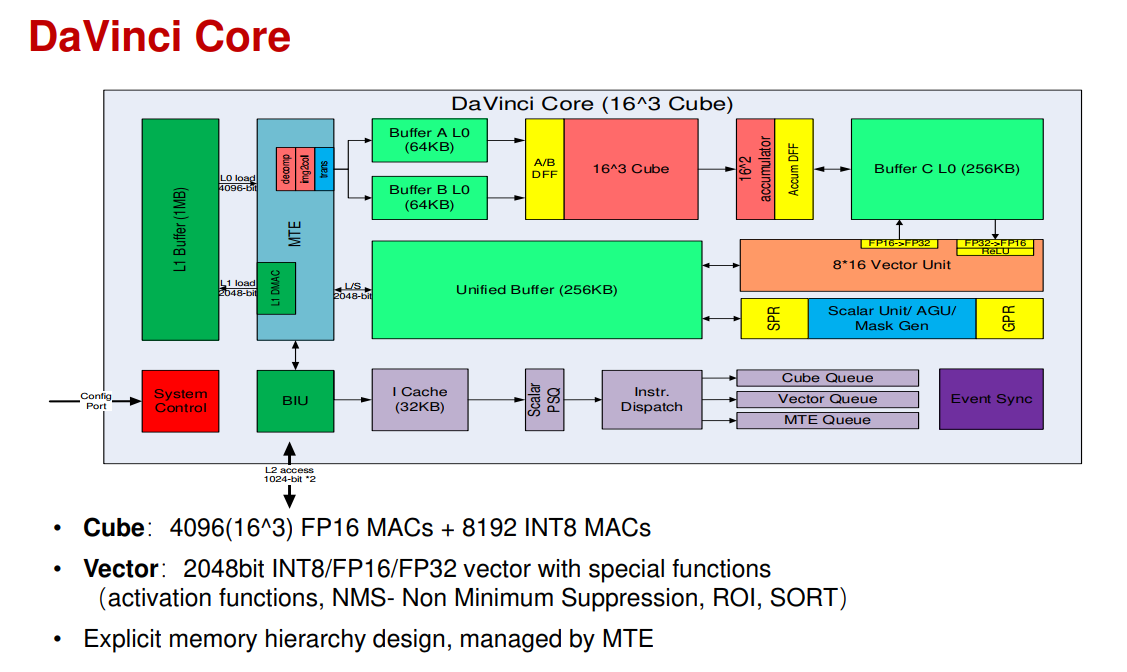
从大的结构上看,数据从L1预取到L0后,依次发射到Cube中进行2D matrix运算,结果写到buffer C中,可以通过Vector单元进行卷积和全连接之后的后处理运算(operation fusion,和TPU以及NVDLA的结构类似),然后写回到Unified Buffer中等待下一次调度。最下方是控制通路,指令经I cache取得后,译码分发到Scalar,Vector和MTE三个单元中进行对应的运算。整体数据通路和寒武纪的“DINANAO”是很类似的,通过显式的内存管理调度数据进入主运算cube或后处理单元,各buffer内部空间划分出ping-pong存储块,保证数据存取的连续性。下方的控制加上scalar和vector运算,相当于集成了一个通用CPU在其中,这样的话支持任何算法都没有问题了。scalar负责控制流和简单运算,vector来解决MAC矩阵所不擅长的pooling,activation等操作,这几部分相互配合补充,很好的实现对AI算法全场景的支持。可以明显看出,最核心的运算还是在cube,主要面向流行的深度学习算法,在其他AI算法上使用vector和scalar运算,算力比cube低不少,因此这类算法的性能是低于SIMT结构的GPU的。
特点
1、达芬奇架构追求的是一个全场景的scalable设计,以一个通用的硬件架构,实现从低端到高端的全覆盖。
2、包含1D scalar unit(full flexiblity)、2D vector unit(rich & efficient operations)、3D matrix unit (high intensity)
3、显式内存层次结构设计,由MTE管理
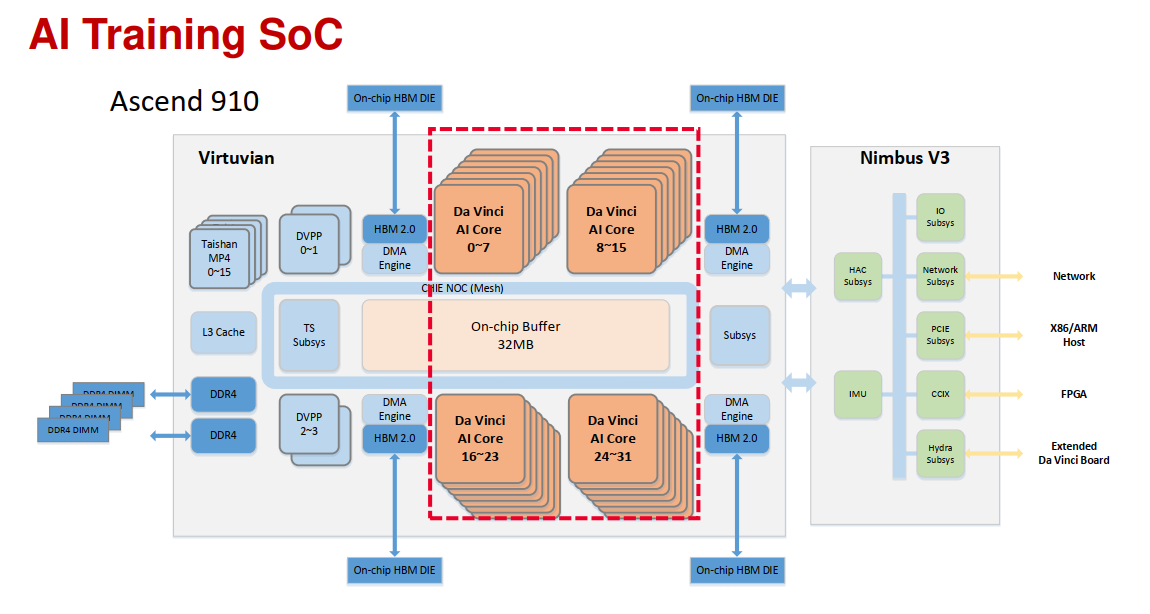
昇腾310和昇腾910

NVDLA
官方文档:http://nvdla.org/primer.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号