[半转载] 7.16 Zhang_RQ gragh/string 学习笔记
写在前面的前面
本文转自 \(DReamLion\) 的 blog 戳此 ,除AC自动机部分为本人拙笔之外,其余均为 \(DReamLion\) 亲笔,特此鸣谢
写在前面
讲师: \(Zhang\_RQ\)
内容:图论(上午): \(Tarjan\) 差分约束 欧拉回路 二分图;字符串(下午):哈希,\(KMP\) ,\(Trie\) 树,\(AC\) 自动机,\(Manacher\)
笔记 \(by \ DReamLion\) ,部分代码来自 @\(wsy\_jim\)
图论
Tarjan
有向图Tarjan
不是今天讲的,具体内容见寒假的课件
- 找强连通分量
int m,e[N],ne[N],h[N],idx,n,dfn[N],low[N],num;
int sta[N],top;
int bel[N],sum[N],res=0;
void add(int a,int b){
e[idx]=b,ne[idx]=h[a],h[a]=idx++;
}
inline int read(){
int x=0,y=1;char c=getchar();
while (c<'0'||c>'9') {if (c=='-') y=-1;c=getchar();}
while (c>='0'&&c<='9') x=x*10+c-'0',c=getchar();
return x*y;
}
void tarjan(int x){
dfn[x]=low[x]=++num;
sta[++top]=x;
for(int i=h[x];~i;i=ne[i]){
int j=e[i];
if(!dfn[j]){
tarjan(j);
low[x]=min(low[x],low[j]);
}else if(!bel[j]) low[x]=min(low[x],dfn[j]);
}
if(low[x]==dfn[x]){
bel[x]=++res;
++sum[res];
while(sta[top]!=x){
++sum[res];
bel[sta[top]]=res;
--top;
}
--top;
}
}
int main(){
memset(h,-1,sizeof h);
n=read(),m=read();
for(int i=1;i<=m;i++){
int a,b;
a=read(),b=read();
add(a,b);
}
for(int i=1;i<=n;++i) if(!dfn[i]) tarjan(i);
for(int i=1;i<=res;i++){
for(int j=1;j<=n;j++){
if(bel[j]==i) printf("%d ",j);
}
printf("\n");
}
return 0;
}
无向图Tarjan
概念
割点:对于一个无向图,如果把一个点删除后这个图的极大连通分量数增加了,那么这个点就是这个图的割点(又称割顶)
割边:对于一个无向图,如果删掉一条边后图中的连通分量数增加了,则称这条边为割边(又称桥)
一些等价的性质
(设 \(v\) 是连通图 \(G\) 的节点, \(e\) 是连通图 \(G\) 的一条边)
- \(v\) 是 \(G\) 的一个割点 = 存在与 \(v\) 不同的两个节点 \(u\) 和 \(w\) ,使得任意一条 \(u\) 到 \(w\) 的道路 \(P_{uw}\) 都经过 \(v\) = \(V-v\) 可划分为两个节点集 \(U\) 和 \(W\) ,使得对任意节点 \(u\in U\) 和 \(w\in W\) ,节点 \(v\) 都在每一条道路 \(P_{uw}\) 上
- \(e\) 是 \(G\) 的一条割边 = \(e\) 不属于 \(G\) 的任何回路 = 存在 \(G\) 的节点 \(u\) 和 \(w\) ,使得 \(e\) 属于 \(u\) 和 \(w\) 的任何一条道路 \(P_{uw}\) = \(G-e\) 可以划分为两个节点集 \(U\) 和 \(W\) ,使得对任何节点 \(u\in U\) 和 \(w\in W\) ,在 \(G\) 中道路 \(P_{uw}\) 都经过 \(e\)
算法
\(Tarjan\) 基于在无向图上的 \(dfs\)
\(dfn_x\) :点 \(x\) 的 \(dfs\) 序,即 \(dfs\) 中第一次搜索到 \(x\) 的次序
\(low_x\) :\(x\) 经过至多一条非树边能访问到的所有节点中最小的 \(dfn\) ,即在以 \(x\) 为根的子树内的点通过一条非树边到达的 \(dfn\) 最小的节点 \(y\) 的 \(dfn\) 值,\(y\) 能到达 \(x\)
\(low\) 的更新方法:\((u,v)\) 有边。若 \(v\) 是 \(v\) 在 \(dfs\) 树上的孩子,则有 \(low_u=min(low_u,low_v)\) ,否则 \(low_u=min(low_u,dfn_v)\)
选定一个根节点,从该点开始 \(dfs\) ,遍历整张图
对于根节点,若它有两棵及以上的子树,则它是割点。因为若去掉这个点,它的子树之间不能互相到达
对于非根节点 \(u\) ,若存在 \(u\) 的孩子 \(v\) ,有 \(dfn_u\le low_v\) ,说明 \(v\) 无法到达 \(u\) 的祖先,即 \(u\) 是割点。因为从 \(v\) 到以 \(u\) 为根的子树外的点都必须经过点 \(u\)
对于点 \(u\) 和 \(u\) 的孩子 \(v\) ,若存在边 \((x,y)\) ,有 \(dfn_u<low_v\) ,则边 \((x,y)\) 是割边,因为以 \(v\) 为根的子树内的点都必须经过该边
- 找点双连通分量
int e[N],ne[N],h[N],idx=2;
int n,m,dfn[N],low[N];
int sta[N],top=0;
int son=0,res=0;
set<int> s[N];
bool cut[N];//是否是割点
inline int read(){
int x=0,y=1;char c=getchar();
while (c<'0'||c>'9') {if (c=='-') y=-1;c=getchar();}
while (c>='0'&&c<='9') x=x*10+c-'0',c=getchar();
return x*y;
}
void add(int a,int b){
e[idx]=b,ne[idx]=h[a],h[a]=idx++;
}
void tarjan(int x,int fa){
dfn[x]=low[x]=++idx;
for(int i=h[x];~i;i=ne[i]){
int j=e[i];
if(j==fa) continue;
if(!dfn[j]){
sta[++top]=i;
tarjan(j,x);
son++;
low[x]=min(low[x],low[j]);
if(low[j]>=dfn[x]){
res++;cut[x]=1;
while(sta[top]!=i){
s[res].insert(e[sta[top]]);
s[res].insert(e[sta[top]^1]);
--top;
}
s[res].insert(x),s[res].insert(j);
--top;
}
}else low[x]=min(low[x],dfn[j]);
}
if(fa==0&&son==1) cut[x]=0;
}
int main(){
memset(h,-1,sizeof h);
n=read(),m=read();
for(int i=1;i<=m;i++){
int a,b;
a=read(),b=read();
add(a,b);
add(b,a);
}
tarjan(1,0);
for(int i=1;i<=res;i++){
for(set<int>::iterator j=s[i].begin();j!=s[i].end();j++){
printf("%d ",*j);
}
printf("\n");
}
return 0;
}
- 找边双连通分量
int e[4*N],ne[4*N],h[N],idx;
int n,m,dfn[N],low[N],res=0,top=0,sta[N],num=0;
int bel[N],sum[N];
bool cut[4*N];
inline int read(){
int x=0,y=1;char c=getchar();
while (c<'0'||c>'9') {if (c=='-') y=-1;c=getchar();}
while (c>='0'&&c<='9') x=x*10+c-'0',c=getchar();
return x*y;
}
void add(int a,int b){
e[idx]=b,ne[idx]=h[a],h[a]=idx++;
}
void tarjan(int x,int fa){
dfn[x]=low[x]=++num;
sta[++top]=x;
for(int i=h[x];~i;i=ne[i]){
int j=e[i];
if(j==fa) continue;
if(!dfn[j]){
tarjan(j,x);
low[x]=min(low[x],low[j]);
if(low[j]>dfn[x]){
res++;
cut[i]=1;
bel[j]=res;
while(sta[top]!=j){
sum[res]++;
bel[sta[top]]=res;
top--;
}
top--;
}
}else low[x]=min(low[x],dfn[j]);
}
}
int main(){
memset(h,-1,sizeof h);
n=read(),m=read();
for(int i=1;i<=m;i++){
int a,b;
a=read(),b=read();
add(a,b);
add(b,a);
}
tarjan(1,0);
for(int i=0;i<=res;i++){
for(int j=1;j<=n;j++){
if(bel[j]==i) printf("%d ",j);
}
printf("\n");
}
return 0;
}
例题
-
[HDU 4738] Caocao's Bridges
给出一个由\(n\)个点和\(m\)条边构成的无向图,表示\(n\)个岛屿之间的\(m\)条道路,现在周瑜有一个炸.药,可以炸掉任意的一条道路,不过每条道路都有一个权值,代表这条道路上防守的卫兵数量,如果周瑜想要炸掉这条道路就必须带上不少于这条路权值的士兵才行,现在问能否带上尽量少的士兵去炸掉一条道路,使得整张无向图变为不相连的两部分。 \(n\le 1000,T\le 12\)
板子题 求最小割边
坑点:①特判图是不连通的 ②如果一个割边的权值是 \(0\) ,那么答案也是 \(1\) ③可能会有重边
-
[POJ 2117] Electricity
给定一张无向图,求任意删掉一个点能得到的最大联通分量数。 \(n\le 10^4\)
只有删割点的时候连通分量数才会增加
删掉一个割点时增加的连通分量数就是满足 \(low_v\ge dfn_u\) 的 \(v\) 的个数(对于根节点要 \(-1\) ,因为没有祖先那一侧的连通块了)
-
[POJ 1523]
给定一个连通网络,网络的结点数\(<=1000\),求出这个网络的所有割点编号,并求出若删去其中一个割点\(k\)后,对应的,原网络会被分割为多少个连通分量?
类似例题2,具体过程这里不写了
-
[Network]
给定一张无向图,有若干次询问,每次询问时添加一条边,问图中还剩多少条割边。 \(n\le 10^5,q\le 1000\)
添加边 \((u,v)\) 会使路径 \((u,v)\) 上的边不能是割边(添加一条非树边会构成一个环,环上的边就不是割边了)
各条非树边之间互不影响
找生成树跑 \(tarjan\)
割边计数,去掉路径上的割边数量即为答案
边上答案下放到点上
树上差分
差分约束
算法
判断差分约束系统是否有解
给定一个 \(n\) 元的不等式组,判断其是否有解
每个不等式组形如 \(x_i-x_j\le c_k\)
不等式变形后为 \(x_i\le x_j+c_k\) ,类似最短路的松弛操作。因此从 \(j\) 点向 \(i\) 点连一条长度为 \(c_k\) 的有向边以表示这个约束
最后加一个虚拟的 \(0\) 号点并向所有点加一边权为 \(0\) 的有向边,跑以 \(0\) 号点为源点的单源最短路,如果有负环则无解,否则有解则某一组解为每个点的距离
判是否有负环用 \(Bellman\_ford\) 或 \(SPFA\) ,因为有负边所以不能用 \(dijkstra\)
复杂度 \(O(nm)\)
例题
-
[Luogu P1993] 小 k 的农场
板子题
-
[Luogu P4926] [1007] 倍杀者
给定 \(x_{a_i} \ge (k_i-t)\times x_{b_i} ,(k_i+t)\times x_{a_i}>x_{b_i}\),求最大的 \(t\) 使得不等式无解
二分答案
取 \(log\) 以后变成差分约束问题
*注意取 \(log\) 的操作!因为 \(log(ab)=log(a)+log(b)\) ,所以通过取 \(log\) 把乘法变成加法,类似P2384
其实不取也能过,因为乘积也不大- 连边
\[x_{a_i}\ge (k_i-t)\times x_{b_i} \\ log_2(x_{a_i})\ge log_2(x_{b_i})+log_2(k_i)-t \]add(b,a,log2(k-t))\[(k_i+t)\times x_{a_i}>x_{b_i} \\ log_2(x_{a_i})+log_2(k_i+t)>log_2(x_{b_i}) \\ log_2(x_{a_i})>log_2(x_{b_i})-log_2(k_i+t) \]add(b,a,-log2(k+t))- 仅当 \(t=0\) 时,不等式仍然有解,即不存在,输出 \(-1\)
- 查 \(t\) 具体是多少用二分答案
欧拉图
概念
定义:存在欧拉回路的图即欧拉图 这不废话吗
欧拉回路:经过所有边恰好一次的图
奇点/偶点:度数为奇数/偶数的点
判定
对于无向图,连通且所有点都是偶点
对于有向图,所有点都在一个强连通分量中且每个点出度和入度相等
Hierholzer算法
选择任一顶点为起点,遍历所有相邻边
深搜,访问相邻顶点,每次删经过的边
若顶点无相邻边就将顶点入栈
栈中顶点倒序输出,就是从起点出发的欧拉回路
void dfs(int x){
for(int y=1;y<=n;y++){
if(mp[x][y]>0){
mp[x][y]--;
mp[y][x]--;
dfs(y);
}
}
s[tmp--]=x;
}
例题
-
[The Necklace]
将每种颜色看做一个点,每个珠子的两种颜色就是在这两种颜色之间连边,跑欧拉回路(跑遍所有边=用尽所有珠子)
二分图
概念
定义:若一个无向图满足可以将点集分为两部分且两部分点集之间无连边,则为二分图
性质:二分图只有偶环,没有奇环 证明就感性理解一下吧
匹配:一个边的子集且所有点至多出现一次
最大匹配:边最多的匹配(最大匹配可转换为网络流问题)
判定
黑白染色
int n;// n表示点数
int h[N], e[M], ne[M], idx;// 邻接表存储图
int color[N];// 表示每个点的颜色,-1表示未染色,0表示白色,1表示黑色
// 参数:u表示当前节点,c表示当前点的颜色
bool dfs(int u, int c){
color[u] = c;
for (int i = h[u]; i != -1; i = ne[i]){
int j = e[i];
if (color[j] == -1){
if (!dfs(j, !c)) return false;
}
else if (color[j] == c) return false;
}
return true;
}
bool check(){
memset(color, -1, sizeof color);
bool flag = true;
for (int i = 1; i <= n; i ++ )
if (color[i] == -1)
if (!dfs(i, 0)){
flag = false;
break;
}
return flag;
}
二分图最大匹配
概念
交错路:一条路径,其中的边(点)的状态是交错的(非匹配边,匹配边,非匹配边,匹配边......)
增广路:以非匹配点为端点的路径,增广路的长度为奇数
性质
当二分图中不存在增广路时,此时的匹配为最大匹配
将增广路的边的状态翻转可以使匹配数 \(+1\)
匈牙利算法
每次寻找增广路
时间复杂度:\(O(nm)\)
\(code1\)
int n1,n2,m;
int h[4*N],e[4*M],ne[4*M],idx;
int match[N];
bool st[N];
void add(int a,int b){
e[idx]=b,ne[idx]=h[a],h[a]=idx++;
}
bool find(int x){
for(int i=h[x];~i;i=ne[i]){
int j=e[i];
if(!st[j]){
st[j]=true;
if(match[j]==0||find(match[j])){
match[j]=x;
return true;
}
}
}
return false;
}
int main(){
memset(h,-1,sizeof h);
n1=read(),n2=read(),m=read();
for(int i=1;i<=m;i++){
int x,y;
x=read();y=read();
add(x,y+n1);
add(y+n1,x);
}
int res=0;
for(int i=1;i<=n1;i++){
memset(st,false,sizeof st);
if(find(i)) res++;
}
cout<<res;
return 0;
}
\(code2\)
int n,m,e,u,v;
int ans=0,mp[maxn][maxn],match[maxn];
bool vis[maxn];
bool dfs(int u){
for(int v=1;v<=m;v++){
if(vis[v]==true||(!mp[u][v])) continue;
vis[v]=true;
if(match[v]==0||dfs(match[v])){
match[v]=u;
return true;
}
}
return false;
}
int main(){
read(n),read(m),read(e);
for(int i=1;i<=e;i++){
read(u),read(v);
mp[u][v]=1;
}
for(int i=1;i<=n;i++){
for(int j=1;j<=m;j++) vis[j]=false;
ans+=dfs(i);
}
cout<<ans<<endl;
return 0;
}
*网络流可以跑到 \(O(\sqrt {n}m)\) ,但是有时候只能用匈牙利
例题
-
[CF1139E] Maximize Mex
建图时分别将权值和集合建为两类点,题中的一个点即为图中的一条边
倒序处理所有操作,删边即变为加边,每次从上次答案处匹配
时间复杂度:\(O(n\times(权值+d))\)
霍尔定理
概念
完美匹配:当二分图的左右部点数量相同时才会谈完美匹配。完美匹配是所有点都是匹配点的一个匹配
定理:对于任何左(右)部点的子集 \(S\) ,与 \(S\) 相邻的右(左)部点的数量不小于 \(|S|\) ,满足该条件的二分图存在完美匹配
定理也可推广到左右部点点数不相同或是点的子集
例题
-
[CERC 2016] 二分毯 Bipartite Blanket
P3679 [CERC2016]二分毯 Bipartite Blanket
在左右部点分别找两个合法子集 \(S,T\) ,则 \(S \cup T\) 满足 \(V\) 被至少一个匹配 \(M\) 覆盖
若一个集合满足霍尔定理,那么它的子集也一定满足
因为将可行状态排过序,所以 \(\ge T-V\) 的部分即为后缀。二分或维护指针求出来边界的位置即可
例题
-
P4589 智力竞赛
在一张 \(DAG\) 中找 \(n+1\) 条链进行覆盖(可相交),最大化没有被覆盖的点的权值
\(floyd\) 求传递闭包后跑二分图最大匹配,若不能覆盖就二分答案
-
P1129 矩阵游戏
将黑色格子所在的行和列连边,跑一遍最大匹配,若是完美匹配即可
-
P2825 游戏
[LOJ 2057] 「TJOI / HEOI2016」游戏
把每行和每列中的合法非空子段抽象成一个点,对于每个可放炸弹的位置 \((i,j)\) ,从其所在的行内合法子段对应的节点想其所在的列内合法子段对应的节点连一条有向边
跑二分图匹配,最大匹配数即为答案
-
P3731 新型城市化
取补,补图是二分图
城市群即为补图中的独立集,最大城市群即为补图中最大独立集
定理:最大独立集= \(n-\) 最大匹配
给定一张二分图,要删一条边使得最大匹配 \(-1\) ,即求哪些边一定在最大匹配里
定理:若一条边一定在最大匹配中,则在最终的残量网络中,这条边一定满流,且这条边的两个顶点一定不在同一个强连通分量中 p
所以 \(Dinic+Tarjan\)
字符串
字符串哈希
算法
把字符串转换为一个正整数来快速判断字符串是否相等
对于一个长度为 \(n\) 的字符串,其哈希值为 \(\sum_{i\ge 1}^{i\le n}s_i\times base^{n-i} \pmod P\) ,其中 \(base\) 和 \(P\) 是自选的
其中 \(base\) 称为底数,\(P\) 称为模数,都是自选的
感觉这么说比较抽象,其实就是设一个进制 \(x\) ,把这个串看成一个 \(x\) 进制数:
\(num=s_1\times x^0+s_2\times x^1+s_3\times x^2+...+s_n\times x^{n-1}\)
然后对一个比较大的质数取模
因此我们判断两个字符串的一个方法是直接判断哈希值是否相等(虽然有概率出错,解决方法见下文)
此外,我们也可快速算出字符串任意子串的哈希值。预处理出前缀哈希值,乘上 \(base\) 的若干次逆元即可
关于模数
模数一般用较大的质数,是为了减小冲突的概率
在实践中自然溢出(\(unsigned \ long \ long\))的冲突概率是最小的,毕竟这是一个 \(2^{64}\) 的模数
在 \(10^5\) 级别时可能会出现哈希冲突,可以用双模数
综上所述,最保险的哈希方法是自然溢出加上对大质数取模。
常用模数:1𝑒9+7,1𝑒9+9,19260817,998244353,1𝑒7+9,1𝑒7+7,5𝑒5+9
常用进制数:131,13331
关于如何卡 \(hash\) ,戳这里看 \(zzz \ gg\) 的神仙方法/se
\(code\)
typedef unsigned long long ull;
// h[k]存储字符串前k个字母的哈希值, p[k]存储 P^k mod 2^64
ull f[maxn],bas[maxn];
int base 13331;
bool check(int l1,int r1,int l2,int r2){//比较两段是否相等
return f[r1]-f[l1-1]*bas[r1-l1+1]==f[r2]-f[l2-1]*bas[r2-l2+1];
}
...
scanf("%s",s+1);
len=strlen(s+1);
bas[0]=1;
for(int i=1;i<=len;++i){
f[i]=f[i-1]*base+(s[i]-'a'+1);//存储字符串从前往后的哈希值
bas[i]=bas[i-1]*base;//bas[i]=base^i
}
例题
-
允许失配 \(k\) 次的匹配
给定一个模式串和源串,问源串中有多少子串与模式串至多有 \(k\) 个不同 \(n\le 10^6,k\le5\)
没加子串,每次二分+ \(Hash\) 找到第一个不同的位置,从这个位置之后继续匹配
时间复杂度 \(O(nk\log n)\)
-
[EOJ 4] 项链

\(n\le 10^5\)
暴力枚举长度和位置再用 \(Hash\) 判断
时间复杂度:调和级数 \(\sum_{i=1}^{n} \frac{n}{i} =O(n \ln n)\)
-
[NOI 2017] 蚯蚓排队
链表维护原串
哈希表暴力维护所有串的 \(Hash\) 值
KMP
算法
在线性时间内完成字符串匹配的算法
给定一个源串和模式串,求出模式串在源串中出现的次数及出现的位置
核心思想是减少暴力匹配时浪费的信息,利用 \(nxt\) 数组进行优化
\(nxt\) 数组:前缀和后缀相同的最大长度
\(nxt\) 的求法:从上一个位置继承下来,nxt[i]=nxt[i-1],新加入的字符能匹配就 \(+1\) ,否则跳 \(nxt\)
匹配时的做法:暴力匹配,失配时跳 \(nxt\) 而不是从头开始
时间复杂度:\(O(n+m)\) (\(i\) 最多会变 \(n\) 次,\(j\) 最多会变 \(m\) 次)
- 找 \(nxt\)
for(int i=2,j=0;i<=m;i++){
while(j&&s2[j+1]!=s2[i]) j=nxt[j];
if(s2[j+1]==s2[i]) ++j;
nxt[i]=j;
}
- \(KMP\) 的过程
for(int i=1,j=0,i<=n;i++){
while(j&&s2[j+1]!=s1[i]) j=nxt[j];
if(s2[j+1]==s1[i]) ++j;
if(j==m) ans.push_back(i-m+1),j=nxt[j];
}
例题
-
动物园
\(nxt\):\(S\) 串前 \(i\) 个字符最长公共前后缀
\(num\):\(S\) 串前 \(i\) 个字符不重叠的公共前后缀数量
倍增直接跳 \(nxt\) ,加卡常可过
正解要先考虑可以重叠的答案
num[i]=num[nxt[i]]+1先暴力跳 \(nxt\) 直到 \(j\le \frac{i}{2}\) ,\(num[i]\) 即为之后能跳的步数
记录 \(i\) 能跳 \(nxt\) 直到 \(nxt=0\) 的步数为 \(num[i]\)
等到跳到 \(j\le \frac{i}{2}\) 时,让 \(ans\times (num[j]+1)\) 即可
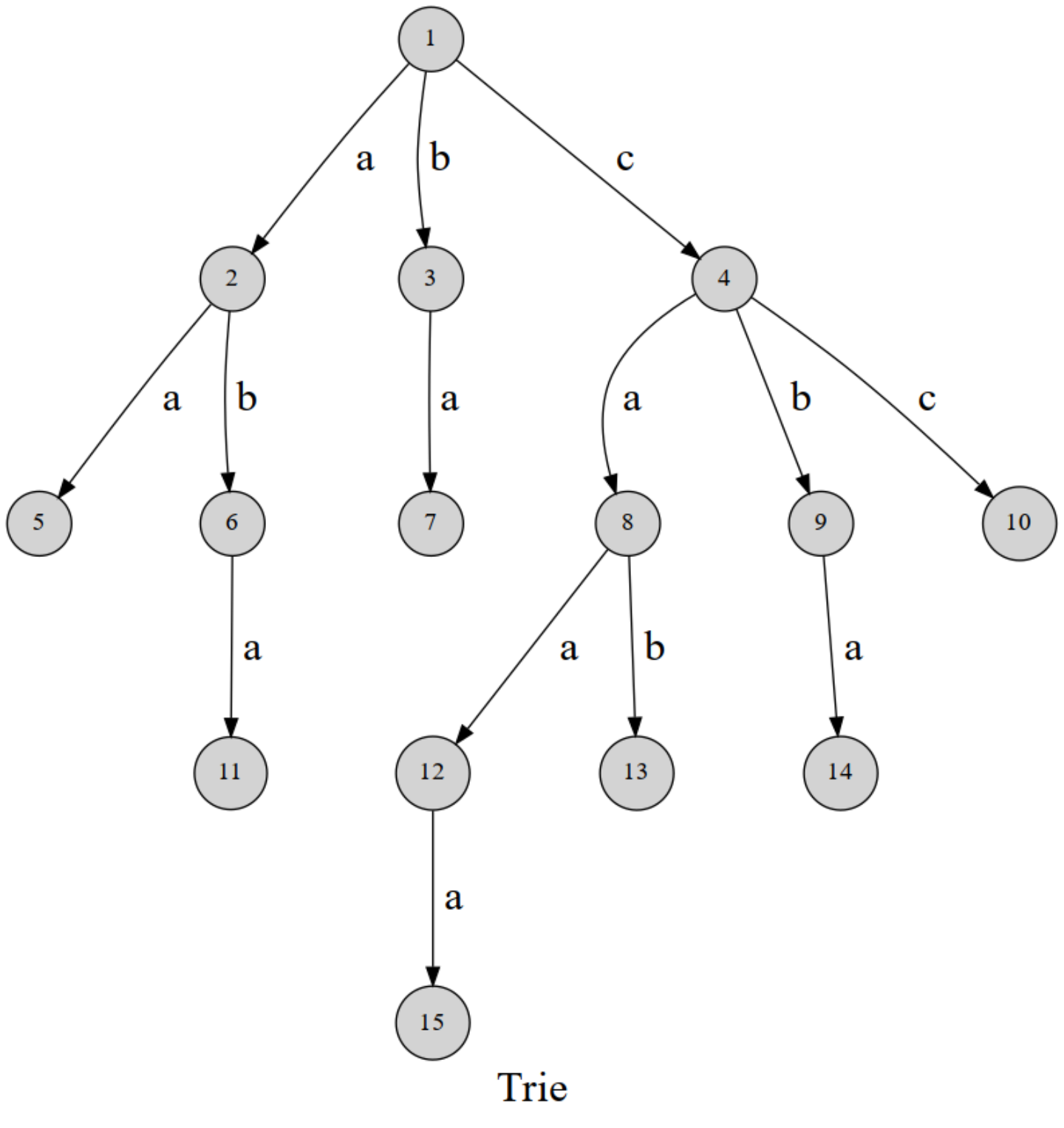
Trie树
概念
字典树,又称单词查找树
把节点作为状态,梓喵(字母)放在边上
核心思想是以空间换时间,利用字符串的公共前缀来降低查询时间的开销,从而达到提高效率的目的
插入、查找的时间复杂度:均为 \(O(k)\) ,其中 \(k\) 为字符串长度
空间复杂度:\(O(NC)\) ,其中 \(N\) 是节点个数,\(C\) 是字符集大小
性质:
- 根节点不包含字符,除根节点以外每个节点只包含一个字符
- 从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串
- 每个节点的所有子节点包含的字符串不相同
- 如果字符的种数为n,则每个结点的出度为n(从这里也可看出在空间上有很多浪费)
- Trie树是一棵多叉树,只要先序遍历整棵树,输出相应的字符串便是按字典序排序的结果
- 作为其他算法的辅助结构,如后缀树、\(AC\) 自动机等
用法:维护若干串,查询一个串是否是这些串的前缀
图解(来自课件):
-
初始化
int trie[N][26];//假设字符串由小写字母构成 int cnt=1;//节点个数 -
将字符串插入 \(Trie\) 树
void insert(char *s){ int len=strlen(s),x=1; for(int i=0;i<len;i++){ int ch=s[i]-'a'; if(!trie[x][ch]) trie[x][ch]=++cnt;//开点 x=trie[x][ch]; } end[x]=true;//记录每个位置是不是字符串的结尾 } -
查询是否是前缀
(当然还有各种变形,\(search\) 可以设为 \(int\) 型来返回某些信息)
bool search(char *s){ int len=strlen(s),x=1; for(int i=0;i<len;i++){ int ch=s[i]-'a'; x=trie[x][ch]; if(!x) return false; } return end[x]; }
01Trie
把数字当成二进制串插入 \(Trie\) 里
可查一个数的前驱后继(有点类似平衡树)
经典操作:维护一个数集,查询时给定一个数字,从数集中选出一个数,最大化或最小化两个数的异或和
-
初始化
int val[32*N];//点的值 int trie[32*N][2];//边的值 int cnt=1;//节点个数 -
将 \(x\) 插入 \(01Trie\) 里
void insert(int x){ int p=0; for(int i=32;i>=0;i--){ int ch=(x>>i)&1; if(!trie[p][ch]) trie[p][ch]=++cnt; p=trie[p][ch]; } } -
查询所有数中异或 \(x\) 结果最大的数
int query(int x){ int p=0,sum=0; for(int i=32;i>=0;i--){ int ch=(x>>i)&1; if(trie[p][!ch]){ p=trie[p][!ch]; sum+=(1<<i); } else p=trie[p][ch]; } return sum; }写法二:
int query(int x){ int u=0; for(int i=32;i>=0;i--){ int v=(x>>i)&1;//贪心,优先寻找和当前位不同的数 if(ch[u][v^1]) u=ch[u][v^1]; else u=ch[u][v]; } return val[u];//返回答案 }
例题
-
于是他错误的点名开始了 \((Trie)\)
-
补退选 \((Trie)\)
-
统计难题 \((Trie)\)
-
单词数 \((Trie)\)
-
Xor Sum \((01Trie)\)
-
Chip Factory \((01Trie)\)
-
Codechef REBXOR \((01Trie)\)
-
The xor-longest Path \((01Trie)\)
【引用参考】
AC自动机
算法
AC自动机用来处理多个模式串与源串的匹配问题
可理解为在多个串上的 \(KMP\)
\(Trie\) 树维护这些串,\(nxt\) 数组变为 \(fail\) 指针
如果当前点匹配失败,则将指针转移到 \(fail\) 指针指向的位置,如此一来就省去了回溯的时间,可以持续匹配下去
\(fail\) 的含义与 \(nxt\) 数组含义大体相同, \(nxt\) 指在一条模式串上后缀和前缀相同的最大长度,而 \(fail\) 指针由一条模式串的后缀指向另几条模式串的最长相同前缀,又因为 \(Trie\) 树上前缀相同的字符串共用一条链 ,将 \(fail\) 指针对应到 \(Trie\) 树上,如果 \(fail[i]=j\) ,那么 \(rt\rightarrow j\) 的字符串是 \(rt\rightarrow i\) 的字符串的一个后缀。
\(fail\) 指针的构造:\(bfs\)
- 首先,我们知道 \(fail\) 指针只会指向比自己深度小的点,所以 \(rt\) 的儿子们只能指向 \(rt\)
- 其次,对于一个点 \(i\) 的父亲 \(fa\) ,\(fa\) 的 \(fail\) 指针指向的节点 \(k\) 如果有和 \(i\) 值相同的儿子 \(j\) ,那么 \(i\) 的 \(fail\) 指针就可以指向 \(j\) ,即最长前缀后缀的扩展,用 \(bfs\) 即可实现
- 如果找不到 \(j\) ,那么找 \(k\) 的 \(fail\) 指针指向的节点是否有和 \(i\) 值相同的儿子,以此向上找
- 如果找到根节点都没有,那么就将 \(i\) 的 \(fail\) 指针指向根节点
void getfail(){
queue<int> q;
for(int i=0;i<26;i++){
if(!son[1][i]) continue;
fail[son[1][i]]=0;
q.push(son[1][i]);
}
while(!q.empty()){
int x=q.front();
q.pop();
for(int i=0;i<26;i++){
if(!son[x][i]) continue;
int tmp=fail[x];
while(tmp&&!son[tmp][i]) tmp=fail[tmp];
if(son[tmp][i]) tmp=son[tmp][i];
fail[son[x][i]]=tmp;
q.push(son[x][i]);
}
}
}
查询时与 \(Trie\) 树类似,这里以查源串中有多少个模式串出现为例
int query(char *s){
int x=1,ans=0,len=strlen(s);
for(int i=0;i<len;i++){
int j=s[i]-'a';
int k=son[x][j];
while(k>1&&flg[k]!=-1){
ans+=flg[k];
flg[k]=-1;
k=fail[k];
}
x=son[x][j];
}
return ans;
}
可以直接构造 \(Trie\) 图来进行多串匹配
\(Trie\) 图的构建:
- 初始化根节点儿子门的 \(fail\) 指针时,我们新建一个节点 \(0\) ,将 \(0\) 的所有儿子指向 \(rt\) ,然后 \(rt\) 的 \(fail\) 指向 \(0\) 就可以了
- \(bfs\) 遍历父亲的子节点时,如果不存在节点 \(i\) 那么我们可以 \(i\) 设为父亲 \(fail\) 的与 \(i\) 值相同的儿子,效果相同,如此一来每个节点都会有实际值
- 无论父亲的 \(fail\) 存不存在与 \(i\) 值相同的儿子,我们都可以将 \(i\) 的 \(fail\) 设为它,因为它在之前已经被处理好,有实际值
void build_fail(){
queue<int> q;
for(int i=0;i<26;i++) son[0][i]=1;
q.push(1);fail[1]=0;
while(!q.empty()){
int x=q.front();
q.pop();
int fafail=fail[x];
for(int i=0;i<26;i++){
int j=son[x][i];
if(!j){son[x][i]=son[fafail][i];continue;}
fail[j]=son[fafail][i];
q.push(j);
}
}
}
查询同上
例题
-
阿狸的打字机
-
魔法咒语
在 \(AC\) 自动机上DP(各种自动机:AC自动机,后缀自动机,麻将自动机......?)
矩阵乘法优化
-
病毒
-
喵星球上的点名
-
单词
Manacher
算法
用来查找一个字符串的最长回文子串的线性方法
将字符串 \(S\) 扩展为 \(T\) ,在空隙上都补上 # 以处理回文中心不在字符上(即回文串长度为偶数)的情况
e.g.: S=abc ->T=#a#b#c#
主要思想:利用之前的已知信息来优化
维护当前最长的回文串和其回文中心:设 \(p[i]\) 表示以 \(T[i]\) 为中心的回文半径长度,求出所有 \(p[i]\) 且取其中最大值即为答案
对于一个新加入的位置,从关于回文中心对称的位置继承答案
这样每次更新答案的时候都是本质不同的回文串,复杂度自然就是线性的
时间复杂度:因为 \(T\) 的长度实际上比 \(S\) 加了一倍,所以复杂度为 \(O(2n)\) ,仍是线性的,即 \(O(n)\)
\(code\)
scanf("%s",s+1);
n=strlen(s+1);
for(int i=1;i<=n;i++) st[i*2-1]='#',st[i*2]=s[i];
n=n*2+1;st[n]='#';
int mxr=1,mid=1;
for(int i=1;i<=n;i++){
hw[i]=min(hw[2*mid-i],mxr-i);
while(st[i-hw[i]]==st[i+hw[i]]&&i+hw[i]<=n) ++hw[i];
if(i+hw[i]>mxr){
mxr=i+hw[i];
mid=i;
}
}
int ans=0;
for(int i=1;i<=n;i++) ans=max(ans,hw[i]-1);
printf("%d\n",ans);
例题
-
密码
-
最长双回文串
-
双倍回文
【引用参考】
期待czy学长的补全!
