

关于数据可视化相关论文
今天看了看老师推荐的sets and set-typed data visualization 集合类型数据可视化大合集 (http://www.cvast.tuwien.ac.at/SetViz)这个网站(需要FQ软件),真的是,怎么说那,首先英语太菜,网页需要翻译-_-||,其次英语视频听得一知半解(只听关键字),还好说明文档很详细以及浏览器自带的翻译不错(O(∩_∩)O哈哈~),能让我有一个大概的了解(突然又有了迫切地想要提高英语能力的感觉,不知能坚持多久)
首先我找到了Jigsaw: Visual Analytics for Exploring and Understanding Document Collections(拼图:用于探索和理解文档集合的可视化分析),jigsaw是一款可视化的软件,说实话,其中关于软件的论文,参加的比赛,获得的奖项(这项研究部分得到了VACCINE DHS卓越中心和NSF奖IIS-0915788和CCF-0808863(FODAVA铅)的支持。过去对该项目的支持来自国土安全部NVAC计划和NSF奖IIS-0414667),我只能说很厉害啊(没大看懂,不明觉厉-_-||,只觉得软件挺好玩的-_-||)。
软件开发的背景:调查分析师和研究人员获取线索并连接少量证据以发现更大的计划,故事或叙述,并简单地获得对信息的更好理解。通常情况下,证据的各个部分都是短文本文档或电子表格,分析人员必须检查这些文档的大量集合,以便将这些文档“拼凑在一起”,并形成关于将来可能发生的行为的良好支持假设。随着要审查的文件数量的增加,分析师理解数据并作出判断变得越来越具有挑战性。
软件开发的作用:创建了可视化分析系统Jigsaw,以帮助分析师和研究人员更好地探索,分析和理解这些文档集合。具体目标是帮助分析师更及时和准确地了解整个文本报告中嵌入的大型故事和重要概念。拼图提供了可视化的集合,每个可视化描述文档的不同方面。
我的测试:首先拿了一个关于人员信息的json文件:

[ { "Name": "John Smith", "Gender": "M", "Age": 38, "Height": 72, "Weight": 198 }, { "Name": "Mary Wilson", "Gender": "F", "Age": 22, "Height": 56, "Weight": 132 }, { "Name": "Jeff Jones", "Gender": "M", "Age": 35, "Height": 69, "Weight": 177 }, { "Name": "Sarah Taylor", "Gender": "F", "Age": 49, "Height": 61, "Weight": 109 }, { "Name": "Marty Maple", "Gender": "M", "Age": 26, "Height": 75, "Weight": 177 }, { "Name": "Jane Doe", "Gender": "F", "Age": 38, "Height": 61, "Weight": 126 }, { "Name": "Jack Carlson", "Gender": "M", "Age": 67, "Height": 68, "Weight": 184 }, { "Name": "Meghan Trainor", "Gender": "F", "Age": 44, "Height": 58, "Weight": 145 } ]
导入,上传后,设置几个属性,选择一个属性值后展现其余属性与此属性的关系:
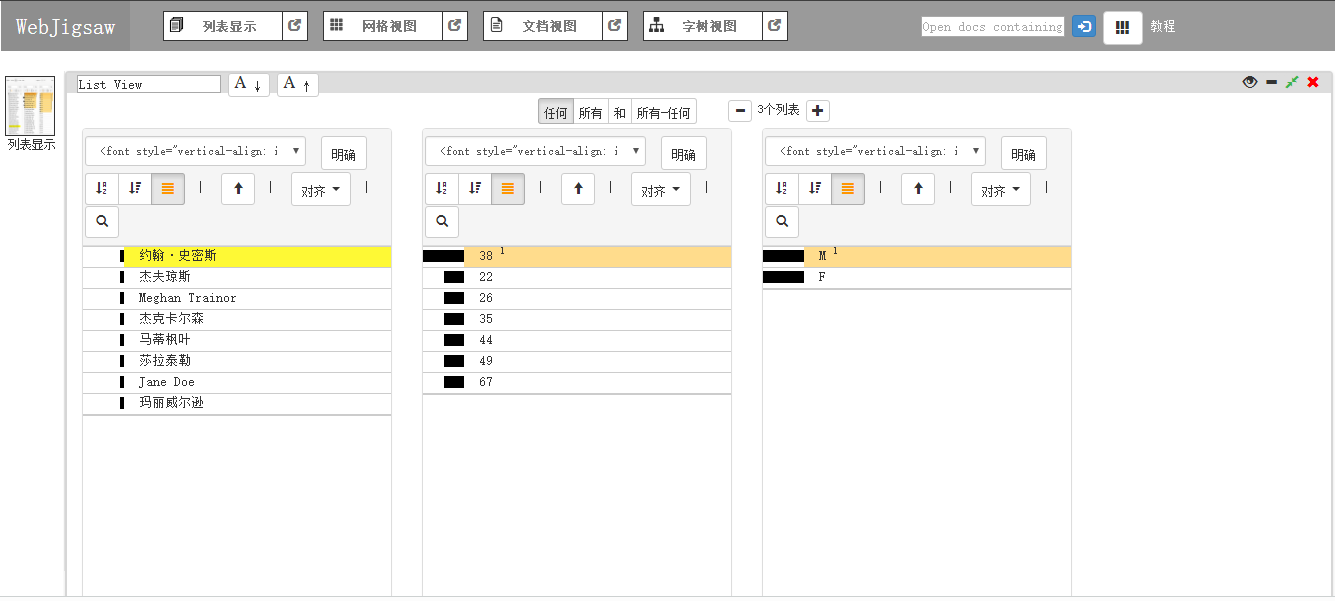
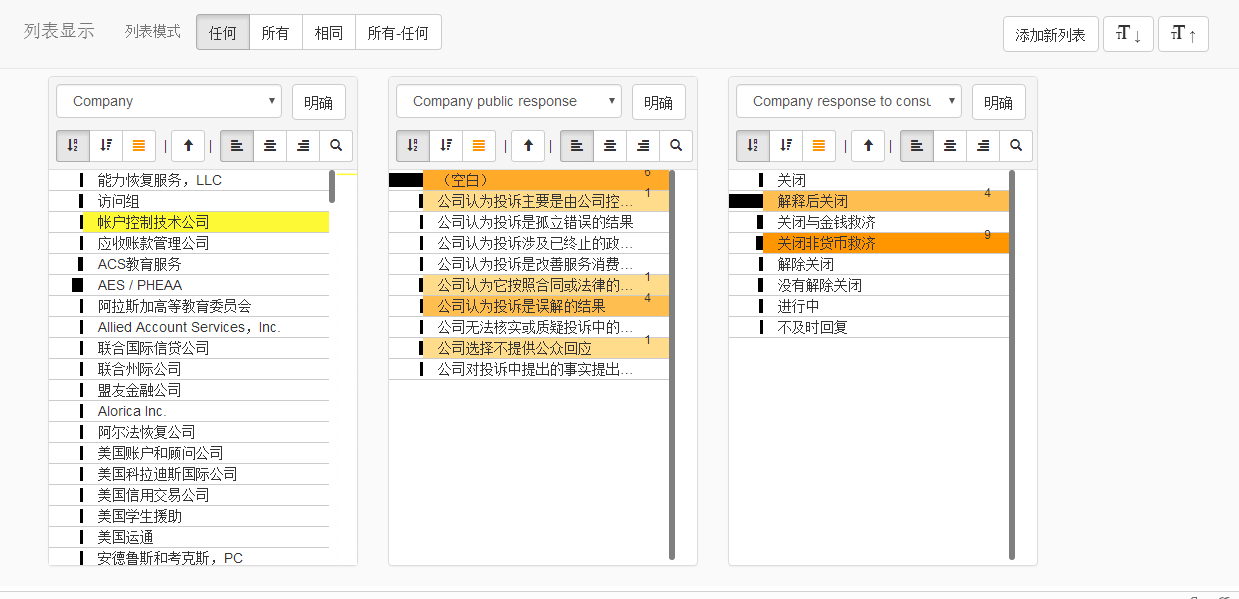
还有一个是关于学生投诉银行的数据,展示结果为:(其中黄色为选择的值,橙色为关联值,深橙色为深度关联的值)
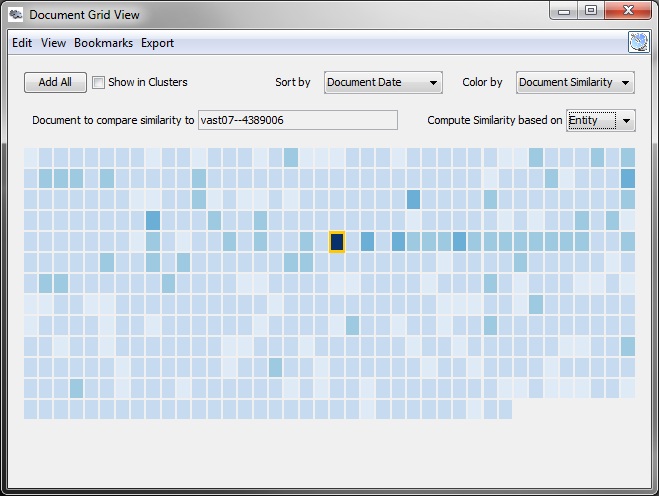
其中还有节点连接图,文档集群图,文档网格图。。。。。。(需要把软件下载到本地,考虑流量问题没有测试(ಥ﹏ಥ),以上为基于web版测试)

关于Jigsaw,让我进一步感到可视化的便捷,能够让我们在复杂的数据中获得想要的关系,从中得出我们的结论,其中这种列表显示的方式个人觉得非常的直观,用黄色,橙色,深橙色使属性之间的联系一目了然。
(注:
和这个有些相像,我尝试把文件射雕英雄传.txt导入Jigsaw,可能格式不对,或者编码有问题,或者文件过大,没有解析出来)。
关于论文,还会继续更新中~

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步