后缀自动机SAM做题笔记
后缀自动机
又一个不是人脑想出来的算法。
\(endpos\) 等价类
\(endpos\) ,顾名思义,就是结束的位置,具体的,是子串结束的位置。
那么 \(endpos(T)\) 就是子串 \(T\) 在母串 \(S\) 中出现的所有位置的右端点集合。
一般来说,SAM中节点,也就是状态点的个数等于 \(endpos\) 等价类的个数。
有两个个性质:
-
如果子串 \(x\) 是子串 \(y\) 的后缀,那么 \(endpos(y) \subseteq endpos(x)\),原因就是,越短的后缀显然出现的次数可能更多。
-
对于一个 \(endpos\) 集合 \(v\) ,集合里的子串长度必定是 \([minlen(v),len(v)]\) ,也就是说子串的长度恰好为 \(minlen(v),minlen(v)+1...len(v)-1,len(v)\),其中 \(minlen(v)\) 是集合 \(v\) 中最短串的长度, \(len(v)\) 是最长串的长度。原因也比较显然,因为根据前一个性质,长度变长,出现次数只会单调不增,那么必然存在不变的一段区间,该区间的子串属于同一个 \(endpos\) 集合。
后缀链接树
回顾刚才的两条性质,就会有长度小的子串的 \(endpos(u)\) 会包含以它作为后缀的长度长的 \(endpos(v)\) ,举个例子:
显然短的 \(b\) 所在集合包含了两个长的串的集合,或者说是两个长串集合的并。
那么这就是一个树形结构了。
所以我们把集合小的,也就是长的串所在集合 \(u\) ,作为儿子,它的父亲就是更短的那个串,视作点 \(v\) ,那么有 \(len(v) = minlen(u) - 1\)。
根节点是全集,但是没有任何串。
这里的一个很有用的性质相信在前面也发现了,就是一个节点的 \(endpos\) 集合可以由儿子集合的并得到,而且并的过程并不会出现交集。这条性质非常重要。
后缀自动机的构造
这是一个在线算法。
如果你在网上看过一堆奇奇怪怪的 SAM 的 DAG 图,先别着急,其实你并不需要理解这个图怎么来的,但是你要理解这个图能干啥,怎么用。
首先同样来明确几个概念:
-
自动机中每个状态,都代表一个 \(endpos\) 等价类,这个状态可以匹配该等价类中所有子串。
-
同样的我们有后缀链接 \(fa(u)\) ,那么有 \(minlen(u) = len(fa(u)) + 1\)。
-
\(last\) 就是当前插入的整个字符串代表的状态点。
-
每个状态存储
fa[u] len[u] ch[u][k]三个状态,前两者已经说明,第三个叫做转移状态,可以当作next,具体的在接下来介绍。
对于一开始的空串,我们记 last = 1。
考虑每次在结尾插入字符串,我们新建一个节点 \(np\) ,令 \(p = last\) ,再更新 \(last = np\) 因为现在 \(np\) 是字符串结尾所在的状态了,也就是整个串所在的状态了。
那么有 \(len(np) = len(p) + 1\) 因为整体长度增长一个。
那么我们是要从状态 \(p\) 转移到状态 \(np\) ,也就是走一步通过当前字符 \(op\) 的边。
于是考虑跳后缀链接,来找这样的转移指针。
for(;p && !ch[p][op];p = fa[p])ch[p][op] = np;
这段话的含义就是,不断的找能否从 \(p\) 转移状态,如果当前 \(p\) 没有走字符 \(op\) 的转移,那么显然他转移到 \(np\) 了,就记录一下,然后继续找了。
接下来干什么呢?
此时我们得到了一个 \(p\),要么这个 \(p\) 可以转移,要么这个 \(p\) 是 \(0\) 也就是转移不了。
分类讨论:
- \(p = 0\) 找不到了,那就回根吧!
fa[np] = 1 - \(p \ne 0\) 也就是找到转移了,但是这时还得分类,令 \(q = ch[p][op]\) 也就是转移过来的状态:
- \(len[q] = len[p] + 1\) 此时刚好是后缀链接的关系,符合我们的构造关系,直接有
fa[np] = q。 - \(len[q] \ne len[p] + 1\) 此时代表他俩并不能直接相连,所以我们要新建节点让他俩连起来,并把当前 \(p\) 到根上所有转移状态链接到新节点。
那么就是:
int nq = ++cnt; fa[nq] = fa[q];len[nq] = len[p] + 1;ch[nq] = ch[q]; fa[q] = fa[np] = nq; for(;p && ch[p][op] == q;p = fa[p])ch[p][op] = nq; - \(len[q] = len[p] + 1\) 此时刚好是后缀链接的关系,符合我们的构造关系,直接有
恭喜你,你完成了字符串的插入,也就是后缀自动机的构建~~
实际上我们的 \(fa\) 指针就是后缀链接树,我们的 \(ch\) 状态转移指针就是大家经常看见的 DAG 辣!
封装良好的结构体SAM代码~
template <int N>
struct SAM{
int last = 1,cnt = 1,fa[N],ch[N][26],len[N],n;
int t,k,vis[N];
char s[N];
inline void insert(char x){
int op = x - 'a',np = ++cnt,p = last;
len[last = np] = len[p] + 1;
for(;p && !ch[p][op];p = fa[p])ch[p][op] = np;
if(!p)fa[np] = 1;
else{
int q = ch[p][op];
if(len[q] == len[p] + 1)fa[np] = q;
else{
int nq = ++cnt;
len[nq] = len[p] + 1;
rep(i,0,25)ch[nq][i] = ch[q][i];
fa[nq] = fa[q];
fa[q] = fa[np] = nq;
for(;p && ch[p][op] == q;p = fa[p])ch[p][op] = nq;
}
}
}
inline void build(){
scanf("%s",s+1);
n = strlen(s + 1);
rep(i,1,n)insert(s[i]);
}
};
SAM<(int)1e6>sam;
注意事项:SAM 点数最多 2n-1,所以开两倍空间。
良好性质:SAM 的建造是线性复杂度的,匹配什么的也都是线性的,总之可以用来解决几乎字符串的所有问题!但也不是全部。
后面还有好多,用法总结刷题笔记先咕着吧,一时半会写不完。
习题
话放在前面,由于 SAM 节点的拓扑关系,本质上是取决于后缀树上面的关系的,也就是长度的关系,所以在 SAM 上面 dp 的时候,你可以真正建图连边,也可以开个桶计数排序,然后倒序的做 dp,是完全等效的,而且后者常数可能会更优秀。
SAM 求本质不同子串
题意
求每次插入字符后产生的本质不同子串个数。
Solution
考虑在 SAM 插入字符串的过程,那么每次添加的本质不同字符串个数就是
maxlen(np) - minlen(np) + 1因为加入了新的 \(endpos\) 产生了新的集合。那么这个式子就等价于len(np) - len(fa(np))因为根据前文提到的后缀链接树性质minlen(u) = len(fa(u)) + 1
code
#include<bits/stdc++.h>
#define rep(i,a,b) for(int i=(a);i<=(b);++i)
#define Rep(i,a,b) for(int i=(a);i<(b);++i)
#define rrep(i,a,b) for(int i=(a);i>=(b);--i)
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=0;
while(ch<'0'||ch>'9'){if(ch=='-')f=1;ch=getchar();}
while(ch>='0'&&ch<='9')x=(x<<1)+(x<<3)+(ch^48),ch=getchar();
if(f)x=-x;
}
template <typename T,typename ...Args>
inline void read(T &tmp,Args &...tmps){read(tmp);read(tmps...);}
using ll = long long;
int n,now;
const int N = 2e5 + 5;
ll ans;
namespace SAM{
int fa[N],len[N],cnt = 1,last = 1;
map<int,int>ch[N];
inline void insert(int x){
int cur = ++cnt,p = last;
len[last = cur] = len[p] + 1;
for(;p && !ch[p][x];p = fa[p])ch[p][x] = cur;
if(!p)fa[cur] = 1;
else{
int q = ch[p][x];
if(len[q] == len[p] + 1)fa[cur] = q;
else{
int nq = ++cnt;
ch[nq] = ch[q];len[nq] = len[p] + 1;fa[nq] = fa[q];
fa[q] = fa[cur] = nq;
for(;p && ch[p][x] == q;p = fa[p])ch[p][x] = nq;
}
}
ans += len[cur] - len[fa[cur]];
}
}
using namespace SAM;
signed main(){
read(n);
rep(i,1,n){
int x;
read(x);
insert(x);
printf("%lld\n",ans);
}
}
这道题就是上一道题的完整版。
题意
求字符串本质不同子串个数
Solution1
沿用上一道题的做法,累加答案。
code
#include<bits/stdc++.h>
#define rep(i,a,b) for(int i=(a);i<=(b);++i)
#define Rep(i,a,b) for(int i=(a);i<(b);++i)
#define rrep(i,a,b) for(int i=(a);i>=(b);--i)
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=0;
while(ch<'0'||ch>'9'){if(ch=='-')f=1;ch=getchar();}
while(ch>='0'&&ch<='9')x=(x<<1)+(x<<3)+(ch^48),ch=getchar();
if(f)x=-x;
}
template <typename T,typename ...Args>
inline void read(T &tmp,Args &...tmps){read(tmp);read(tmps...);}
namespace SAM{
const int N = 2e5 + 5;
int n,ch[N][26],fa[N],len[N],cnt = 1,last = 1;
long long f[N],ans;
char s[N];
long long dfs(int u){
if(f[u])return f[u];
rep(i,0,25)if(ch[u][i])f[u] += dfs(ch[u][i]) + 1;
return f[u];
}
inline void solve(){
printf("%lld\n",ans);
}
inline void insert(char x){
int op = x - 'a';
int p = last,np = ++cnt;
len[last = np] = len[p] + 1;
for(;p && !ch[p][op];p = fa[p])ch[p][op] = np;
if(!p)fa[np] = 1;
else{
int q = ch[p][op];
if(len[q] == len[p] + 1)fa[np] = q;
else{
int nq = ++cnt;
len[nq] = len[p] + 1;
rep(i,0,25)ch[nq][i] = ch[q][i];
fa[nq] = fa[q];
fa[q] = fa[np] = nq;
for(;p && ch[p][op] == q;p = fa[p])ch[p][op] = nq;
}
}
ans += len[np] - len[fa[np]];
}
inline void build(){
read(n);
scanf("%s",s+1);
rep(i,1,n)insert(s[i]);
}
}
signed main(){
SAM::build();
SAM::solve();
}
Solution2
SAM有一个良好的性质就是从原点出发,遍历 SAM 的 DAG 我们可以得到这个字符串的所有子串,就有一个感性的理解,你考虑把这个字符串的所有后缀都扔进了一个字典树,然后把字典树尾巴相同的部分给完全压缩了,这就是 SAM 的 DAG。于是我们类比 AC 自动机,考虑怎么 dp ,那其实有前面的性质就很简单了 $$dp[i] = \sum (dp[ch[i][j] + 1)$$ 其中
ch[i][j]是i的转移状态,其实就是 DAG 上的一条边。
这个转移式子的含义,就是把儿子的方案数加上了,同时加一是加上从自己到转移状态这条边所代表的字符。
code
#include<bits/stdc++.h>
#define rep(i,a,b) for(int i=(a);i<=(b);++i)
#define Rep(i,a,b) for(int i=(a);i<(b);++i)
#define rrep(i,a,b) for(int i=(a);i>=(b);--i)
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=0;
while(ch<'0'||ch>'9'){if(ch=='-')f=1;ch=getchar();}
while(ch>='0'&&ch<='9')x=(x<<1)+(x<<3)+(ch^48),ch=getchar();
if(f)x=-x;
}
template <typename T,typename ...Args>
inline void read(T &tmp,Args &...tmps){read(tmp);read(tmps...);}
const int N = 1e5 + 5;
struct SAM{
int fa[N],ch[N][26],len[N],tong[N],rnk[N],cnt,last;
long long siz[N];
char s[N];
int n;
inline void insert(char x){
int op = x - 'a';
int p = last,np = last = ++cnt;
len[np] = len[p] + 1;
for(;p && !ch[p][op];p = fa[p])ch[p][op] = np;
if(!p)fa[np] = 1;
else{
int q = ch[p][op];
if(len[q] == len[p] + 1)fa[np] = q;
else{
int nq = ++cnt;
fa[nq] = fa[q];
memcpy(ch[nq],ch[q],sizeof(ch[nq]));
len[nq] = len[p] + 1;
fa[np] = fa[q] = nq;
for(;p && ch[p][op] == q;p = fa[p])ch[p][op] = nq;
}
}
}
inline void build(){
scanf("%s",s+1);
n = strlen(s+1);
memset(ch,0,sizeof(ch));
memset(fa,0,sizeof(fa));
memset(len,0,sizeof(len));
memset(tong,0,sizeof(tong));
cnt = last = 1;
rep(i,1,n)insert(s[i]);
}
inline void solve(){
rep(i,1,cnt)tong[i] = 0,siz[i] = 1;
siz[1] = 0;
rep(i,1,cnt)tong[len[i]]++;
rep(i,1,cnt)tong[i] += tong[i-1];
rep(i,1,cnt)rnk[tong[len[i]]--] = i;
rrep(i,cnt,1){
int p = rnk[i];
rep(j,0,25)if(ch[p][j])siz[p] += siz[ch[p][j]];
}
printf("%lld\n",siz[1]);
}
}sam;
signed main(){
int t;
read(t);
while(t--)sam.build(),sam.solve();
}
SAM 求字典序第 k 小子串
Solution
我们回顾刚才的 dp ,我们求出来了 SAM 上每一个状态节点的不同子串个数,那么类比以前学过的种种奇形怪状的
第 k 大问题,比如平衡树,权值线段树,或者我觉得可能最恰当的是数位 dp 吧,它和 SAM 的这个最奇怪,我们可以写出来在 SAM 上面求第 k 小的方法。注意我们为了方便,原来的加一我们可以直接初始化为一,然后再变成 $$dp[i] = 1 + \sum dp[ch[i][j]]$$,含义就是节点的 dp 值算上了从父亲走到他的这一方案,方便我们求。
- 起点为原点。
- 按照字典序遍历出边
- 若 $$ k > dp[ch[i][j]]$$ 证明走这条路选不了第 k 小,直接
k -= dp[ch[i][j]],走到下一步。- 若 $$k \le dp[ch[i][j]]$$ 证明答案在必定在这条路径上,于是走这条边,输出这条边的字符,并且
k--,原因就是你走了这一条边了,已经少了一种方案了,我个人的一个十分感性的理解就是对 dp 的逆过程。
code
#include<bits/stdc++.h>
#define rep(i,a,b) for(int i=(a);i<=(b);++i)
#define Rep(i,a,b) for(int i=(a);i<(b);++i)
#define rrep(i,a,b) for(int i=(a);i>=(b);--i)
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=0;
while(ch<'0'||ch>'9'){if(ch=='-')f=1;ch=getchar();}
while(ch>='0'&&ch<='9')x=(x<<1)+(x<<3)+(ch^48),ch=getchar();
if(f)x=-x;
}
template <typename T,typename ...Args>
inline void read(T &tmp,Args &...tmps){read(tmp);read(tmps...);}
namespace SAM{
const int N = 2e6 + 5;
int n,fa[N],ch[N][26],len[N],last = 1,cnt = 1,tong[N],siz[N],rnk[N];
char s[N];
inline void insert(char x){
int op = x - 'a';
int p = last,np = ++cnt;
len[last = np] = len[p] + 1;
for(;p && !ch[p][op];p = fa[p])ch[p][op] = np;
if(!p)fa[np] = 1;
else{
int q = ch[p][op];
if(len[q] == len[p] + 1)fa[np] = q;
else{
int nq = ++cnt;
len[nq] = len[p] + 1;
rep(i,0,25)ch[nq][i] = ch[q][i];
fa[nq] = fa[q];
fa[q] = fa[np] = nq;
for(;p && ch[p][op] == q;p = fa[p])ch[p][op] = nq;
}
}
}
inline void build(){
scanf("%s",s+1);
n = strlen(s + 1);
rep(i,1,n)insert(s[i]);
rep(i,1,cnt)siz[i] = 1;
rep(i,1,cnt)tong[len[i]]++;
rep(i,1,cnt)tong[i] += tong[i-1];
rep(i,1,cnt)rnk[tong[len[i]]--] = i;
rrep(i,cnt,1){
int p = rnk[i];
rep(j,0,25)siz[p] += siz[ch[p][j]];
}
// rep(i,1,cnt)printf("%d ",siz[i]);
// puts("");
}
inline void query(int k){
int u = 1;
while(k){
rep(i,0,25){
if(!ch[u][i])continue;
if(k > siz[ch[u][i]])k -= siz[ch[u][i]];
else{
putchar('a' + i);
u = ch[u][i];
--k;
break;
}
}
}
puts("");
}
}
using namespace SAM;
signed main(){
build();
int t;
read(t);
while(t--){
int k;
read(k);
query(k);
}
}
/*
abcdefgdssassgsfsdf
5
3
8
6
5
2
*/
SAM 求 LCS 最长公共子串
Solution
考虑对一个建 SAM,拿另一个来在 SAM 上匹配,那么维护
len匹配长度和u当前节点,失配了就跳后缀链接往回走,因为这时无法匹配更长的,自然要保留后缀来往下匹配,所以跳后缀链接,然后分类讨论一下就好了,复杂度是线性的,非常优秀。
code
#include<bits/stdc++.h>
#define rep(i,a,b) for(int i=(a);i<=(b);++i)
#define Rep(i,a,b) for(int i=(a);i<(b);++i)
#define rrep(i,a,b) for(int i=(a);i>=(b);--i)
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=0;
while(ch<'0'||ch>'9'){if(ch=='-')f=1;ch=getchar();}
while(ch>='0'&&ch<='9')x=(x<<1)+(x<<3)+(ch^48),ch=getchar();
if(f)x=-x;
}
template <typename T,typename ...Args>
inline void read(T &tmp,Args &...tmps){read(tmp);read(tmps...);}
namespace SAM{
const int N = 1e6 + 5;
int n,fa[N],ch[N][26],siz[N],len[N],tong[N],cnt = 1,last = 1,rnk[N],ans[N];
char s[N];
inline void insert(char x){
int op = x - 'a',p = last,np = ++cnt;siz[np] = 1;
len[last = np] = len[p] + 1;
for(;p && !ch[p][op];p = fa[p])ch[p][op] = np;
if(!p)fa[np] = 1;
else{
int q = ch[p][op];
if(len[q] == len[p] + 1)fa[np] = q;
else{
int nq = ++cnt;
len[nq] = len[p] + 1;
rep(i,0,25)ch[nq][i] = ch[q][i];
fa[nq] = fa[q];
fa[q] = fa[np] = nq;
for(;p && ch[p][op] == q;p = fa[p])ch[p][op] = nq;
}
}
}
inline void build(){
scanf("%s",s+1);
n = strlen(s+1);
rep(i,1,n)insert(s[i]);
scanf("%s",s+1);
n = strlen(s + 1);
int u = 1,cnt = 0,ans = 0;
rep(i,1,n){
int op = s[i] - 'a';
if(ch[u][op])u = ch[u][op],cnt++;
else{
for(;u && !ch[u][op];u = fa[u]);
if(u)cnt = len[u] + 1,u = ch[u][op];
else cnt = 0,u = 1;
}
ans = max(ans,cnt);
}
printf("%d",ans);
}
}
using namespace SAM;
signed main(){
build();
}
Solution
我们依旧对第一个串建 SAM,那么对于 SAM 上一个状态点,跟接下来所有串的公共最长匹配长度,显然就是所有串在匹配到这个节点时最长长度的最小值,那么维护这么一个东西就好了,同时注意,对于一个节点
u和它的后缀链接节点fa[u]我们可以拿当前的mx[u]来更新mx[fa[u]]原因显然,我匹配的长了,我包含了我的后缀链接,所以我的后缀链接节点也可以这么长,只不过没被更新而已。
于是答案就是所有最小值的最大值好绕。
code
#include<bits/stdc++.h>
#define rep(i,a,b) for(int i=(a);i<=(b);++i)
#define Rep(i,a,b) for(int i=(a);i<(b);++i)
#define rrep(i,a,b) for(int i=(a);i>=(b);--i)
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=0;
while(ch<'0'||ch>'9'){if(ch=='-')f=1;ch=getchar();}
while(ch>='0'&&ch<='9')x=(x<<1)+(x<<3)+(ch^48),ch=getchar();
if(f)x=-x;
}
template <typename T,typename ...Args>
inline void read(T &tmp,Args &...tmps){read(tmp);read(tmps...);}
namespace SAM{
const int N = 1e6 + 5;
int n,fa[N],ch[N][26],siz[N],len[N],tong[N],cnt = 1,last = 1,rnk[N];
char s[N];
int mx[N],mi[N],ans;
inline void insert(char x){
int op = x - 'a',p = last,np = ++cnt;siz[np] = 1;
len[last = np] = len[p] + 1;
for(;p && !ch[p][op];p = fa[p])ch[p][op] = np;
if(!p)fa[np] = 1;
else{
int q = ch[p][op];
if(len[q] == len[p] + 1)fa[np] = q;
else{
int nq = ++cnt;
len[nq] = len[p] + 1;
rep(i,0,25)ch[nq][i] = ch[q][i];
fa[nq] = fa[q];
fa[q] = fa[np] = nq;
for(;p && ch[p][op] == q;p = fa[p])ch[p][op] = nq;
}
}
}
inline void ckmax(int &x,int y){if(x < y)x = y;}
inline void ckmin(int &x,int y){if(x > y)x = y;}
inline void build(){
scanf("%s",s+1);
n = strlen(s+1);
rep(i,1,n)insert(s[i]);
rep(i,1,cnt)tong[len[i]]++;
rep(i,1,cnt)tong[i] += tong[i-1];
rrep(i,cnt,1)rnk[tong[len[i]]--] = i;
rep(i,1,cnt)mi[i] = INT_MAX;
while(scanf("%s",s + 1) != EOF){
n = strlen(s + 1);
int u = 1,L = 0;
rep(i,1,n){
int op = s[i] - 'a';
if(ch[u][op])++L,u = ch[u][op],ckmax(mx[u],L);
else{
for(;u && !ch[u][op];u = fa[u]);
if(u)L = len[u] + 1,u = ch[u][op],ckmax(mx[u],L);
else L = 0,u = 1;
}
}
rrep(i,cnt,1){
u = rnk[i];
ckmax(mx[fa[u]],min(mx[u],len[fa[u]]));
ckmin(mi[u],mx[u]);
mx[u] = 0;
}
}
rep(i,1,cnt)ckmax(ans,mi[i]);
printf("%d",ans);
}
}
using namespace SAM;
signed main(){
build();
}
SAM 后缀树的应用
题意
一个字符串,对于每一种长度的子串,求出该长度出现最多次子串的出现次数。
Solution
出现次数,显然等价于该子串所在的 \(endpos\) 集合大小,而在前文提过,在后缀树上面,一个集合等于所有儿子集合的并,而且这些儿子集合两两不交。有了这条性质,对于一个状态,他的出现次数,显然可以通过树形 dp 得到,与其说是树形 dp ,不如说是类似树上差分了。那么对于每个状态,用他的出现次数来他的长度的答案就好了。
code
#include<bits/stdc++.h>
#define rep(i,a,b) for(int i=(a);i<=(b);++i)
#define Rep(i,a,b) for(int i=(a);i<(b);++i)
#define rrep(i,a,b) for(int i=(a);i>=(b);--i)
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=0;
while(ch<'0'||ch>'9'){if(ch=='-')f=1;ch=getchar();}
while(ch>='0'&&ch<='9')x=(x<<1)+(x<<3)+(ch^48),ch=getchar();
if(f)x=-x;
}
template <typename T,typename ...Args>
inline void read(T &tmp,Args &...tmps){read(tmp);read(tmps...);}
namespace SAM{
const int N = 1e6 + 5;
int n,fa[N],ch[N][26],siz[N],len[N],tong[N],cnt = 1,last = 1,rnk[N],ans[N];
char s[N];
inline void insert(char x){
int op = x - 'a',p = last,np = ++cnt;siz[np] = 1;
len[last = np] = len[p] + 1;
for(;p && !ch[p][op];p = fa[p])ch[p][op] = np;
if(!p)fa[np] = 1;
else{
int q = ch[p][op];
if(len[q] == len[p] + 1)fa[np] = q;
else{
int nq = ++cnt;
len[nq] = len[p] + 1;
rep(i,0,25)ch[nq][i] = ch[q][i];
fa[nq] = fa[q];
fa[q] = fa[np] = nq;
for(;p && ch[p][op] == q;p = fa[p])ch[p][op] = nq;
}
}
}
inline void build(){
scanf("%s",s+1);
n = strlen(s+1);
rep(i,1,n)insert(s[i]);
rep(i,1,cnt)tong[len[i]]++;
rep(i,1,cnt)tong[i] += tong[i-1];
rep(i,1,cnt)rnk[tong[len[i]]--] = i;
rrep(i,cnt,1)siz[fa[rnk[i]]] += siz[rnk[i]];
rep(i,1,cnt)ans[len[i]] = max(ans[len[i]],siz[i]);
rep(i,1,n)printf("%d\n",ans[i]);
}
}
using namespace SAM;
signed main(){
build();
}
大 BOSS 来啦!
题意
给出一个字符串\(S\)
给出\(Q\)个操作,给出\(L, R, T\),求字典序最小的\(S_1\),使得\(S_1\)为\(S[L..R]\)的子串,且\(S_1\)的字典序严格大于\(T\)。输出这个\(S_1\),如果无解输出\(-1\)
\(1 \leq |S| \leq 10 ^ 5, 1 \leq Q \leq 2 \times 10 ^ 5, 1 \leq L \leq R \leq |S|, \sum |T| \leq 2 \times 10 ^ 5\)
Solution
我们发现虽然题目只是加上了一个区间的限制,但是恶心了可不是一点啊!!!
首先考虑没有区间限制咋做。很简单,字典序最小的严格大于 T 的一定是 T + x,这里 x 是能匹配的最小的字符。于是贪心跳就好了。
接下来我们发现,跳的过程会被区间给限制住啊!!!
那怎么办?
还是 \(endpos\) 集合,他又回来了。
假设我们当前匹配长度是 \(len\) ,那么对于给定的区间 \([l,r]\) ,我们下一步能跳到的节点,就必须要求它的 \(endpos\) 集合,包含 \([l+len,r]\) 之间里的任意一个位置,对吧。仔细想想,我们下一步跳的边,代表我们往当前的匹配串结尾加进来一个字符,于是这个状态的 \(endpos\) ,也就是这个字符,必须得是能在 \([l+len,r]\) 里面的。
那考虑怎么询问集合呢?
回忆之前的树上差分,我们统计的是集合大小。
那么我们可以用线段树合并得到真正的集合。
注意我们需要每一个节点的线段树,也就是集合,那么就都需要新建节点来合并了。
匹配的时候,如果要跳这条边,还得query(1,1,n,l+len,r) > 0这样子,代表存在节点在 \([l+len,r]\) 的区间里的,于是你走了这条边。
于是这题就做完了!
code
#include<bits/stdc++.h>
#define rep(i,a,b) for(int i=(a);i<=(b);++i)
#define Rep(i,a,b) for(int i=(a);i<(b);++i)
#define rrep(i,a,b) for(int i=(a);i>=(b);--i)
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=0;
while(ch<'0'||ch>'9'){if(ch=='-')f=1;ch=getchar();}
while(ch>='0'&&ch<='9')x=(x<<1)+(x<<3)+(ch^48),ch=getchar();
if(f)x=-x;
}
template <typename T,typename ...Args>
inline void read(T &tmp,Args &...tmps){read(tmp);read(tmps...);}
const int NN = 4e5 + 5;
int N;
namespace seg{
int root[NN],cnt;
struct segment_tree{
int l,r;
}tr[NN<<5];
#define lt(k) tr[k].l
#define rt(k) tr[k].r
#define mid ((l+r)>>1)
vector<int>g[NN];
int modify(int l,int r,int pos){
int k = ++cnt;
if(l == r)return k;
if(pos <= mid)lt(k) = modify(l,mid,pos);
else rt(k) = modify(mid+1,r,pos);
return k;
}
int merge(int x,int y,int l,int r){
if(!x || !y || l == r)return x | y;
int k = ++cnt;
lt(k) = merge(lt(x),lt(y),l,mid);
rt(k) = merge(rt(x),rt(y),mid+1,r);
return k;
}
int query(int k,int l,int r,int L,int R){
if(!k)return k;
if(l >= L && r <= R)return 1;
return (L <= mid && query(lt(k),l,mid,L,R)) || (R > mid && query(rt(k),mid+1,r,L,R));
}
}
namespace SAM{
int n,last = 1,cnt = 1,fa[NN],ch[NN][26],len[NN];
char s[NN];
inline void insert(char x){
int op = x - 'a';
int p = last ,np = ++cnt;
len[last = np] = len[p] + 1;
seg::root[np] = seg::modify(1,N,len[np]);
for(;p && !ch[p][op];p = fa[p])ch[p][op] = np;
if(!p)fa[np] = 1;
else{
int q = ch[p][op];
if(len[q] == len[p] + 1)fa[np] = q;
else{
int nq = ++cnt;
len[nq] = len[p] + 1;
rep(i,0,25)ch[nq][i] = ch[q][i];
fa[nq] = fa[q];
fa[q] = fa[np] = nq;
for(;p && ch[p][op] == q;p = fa[p])ch[p][op] = nq;
}
}
}
inline void build(){
scanf("%s",s+1);
n = strlen(s + 1);
N = n;
rep(i,1,n)insert(s[i]);
}
}
void dfs(int u){
for(int v : seg::g[u]){
dfs(v);
seg::root[u] = seg::merge(seg::root[u],seg::root[v],1,N);
}
}
int mx[NN];
signed main(){
SAM::build();
rep(i,1,SAM::cnt)seg::g[SAM::fa[i]].push_back(i);
dfs(1);
//printf("N=%d\n",N);
int q;
read(q);
char s[NN];
int n;
while(q--){
int l,r;
read(l,r);
scanf("%s",s + 1);
n = strlen(s + 1);
int u = 1,i = 1,v;
for(i = 1;;++i){
mx[i] = -1;
rep(j,i <= n ? s[i] - 'a' + 1 : 0,25){
v = SAM::ch[u][j];
//printf("v=%d\n",v);
if(v && seg::query(seg::root[v],1,N,l + i - 1,r)){
mx[i] = j;
break;
}
}
v = SAM::ch[u][s[i] - 'a'];
if(!v || i == n + 1 || !seg::query(seg::root[v],1,N,l + i - 1,r))break;
u = v;
}
while(i && mx[i] == -1)--i;
if(!i)puts("-1");
else{
// printf("i=%d mx=%d\n",i,mx[i]);
Rep(j,1,i)putchar(s[j]);
// //printf("mx=%d\n",mx[i]);
putchar(mx[i] + 'a');
puts("");
}
}
}
最后一只 BOSS!
[NOI2018] 你的名字
题意
给定母串 S ,每次给定一个区间和一个字符串 T,求 T 有多少本质不同子串,没在
S[l..r]出现过。
Solution
首先你学会了上一道题,于是你表示:不就区间限制吗!爷不怕!
然后你发现你不会统计答案了(悲
别急,我们按题意一点一点来。
首先你可以边做边统计出来,以当前 T[i] 作为结尾的最长匹配长度。
其次你发现你可以通过对 T 建 SAM 然后通过len[np] - len[fa[np]]统计出来插入 T[i] 后 T 增加的本质不同子串个数。
然后分别思考这两个东西是啥。
首先匹配长度 \(len\),意味着你在 \(i - len\) 个以 T[i] 结尾的子串无法匹配,这些子串以 T[i] 结尾,长度为 \([len+1,i]\)。
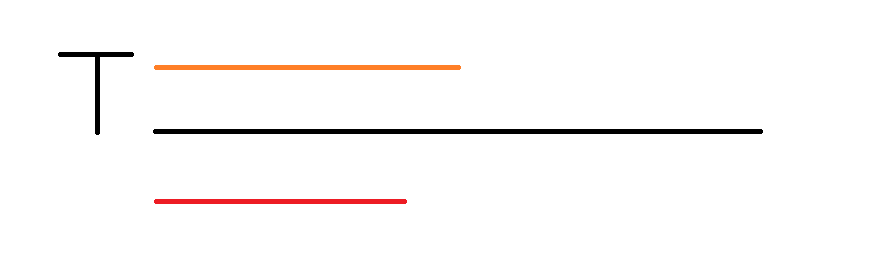
其次是增加的本质不同子串个数\(len[np] - len[fa[np]]\) 那么同样意味着有这些新增的本质不同串,长度为 \([len[fa[np]]]+1,len[np]]\) 注意到 \(len[np] = i\) ,我们可以更形象点画个图
黑的是 T[1,i]。
假设橙色的是T不匹配S的以T[i]结尾的开头部分。
假设红色的是 T 新增的本质不同子串的开头部分。
于是你发现当前对答案的贡献,就是这两条线段长度取\(\min\),因为要同时满足两个条件:新增本质不同,不匹配。
于是ans += min(i - len,i - len[fa[last]])
于是您在 NOI 得到了100pts!!!
但要注意的是,这里的匹配不能跳 \(fa\) 指针了,因为你还有线段树上区间的限制,也许你len--你就,跳 \(fa\) 指针能得到 \(97\) 分,全场居然只有一个数据的一个点能卡这种做法()。
code
#include<bits/stdc++.h>
#define rep(i,a,b) for(int i=(a);i<=(b);++i)
#define Rep(i,a,b) for(int i=(a);i<(b);++i)
#define rrep(i,a,b) for(int i=(a);i>=(b);--i)
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=0;
while(ch<'0'||ch>'9'){if(ch=='-')f=1;ch=getchar();}
while(ch>='0'&&ch<='9')x=(x<<1)+(x<<3)+(ch^48),ch=getchar();
if(f)x=-x;
}
template <typename T,typename ...Args>
inline void read(T &tmp,Args &...tmps){read(tmp);read(tmps...);}
const int N = 2e6 + 5;
int root[N];
char s[N];
vector<int>g[N];
int cnt,tot;
struct seg{
int l,r;
}tr[50000005];
#define lt(k) tr[k].l
#define rt(k) tr[k].r
#define mid ((l+r)>>1)
int modify(int l,int r,int pos){
int k = ++cnt;
if(l == r)return k;
if(pos <= mid)lt(k) = modify(l,mid,pos);
else rt(k) = modify(mid+1,r,pos);
return k;
}
int merge(int x,int y,int l,int r){
if(!x || !y || l == r)return x | y;
int k = ++cnt;
lt(k) = merge(lt(x),lt(y),l,mid);
rt(k) = merge(rt(x),rt(y),mid+1,r);
return k;
}
int query(int k,int l,int r,int L,int R){
if(!k)return 0;
if(l >= L && r <= R)return 1;
return (L <= mid && query(lt(k),l,mid,L,R)) || (R > mid && query(rt(k),mid+1,r,L,R));
}
struct SAM{
int fa[N],ch[N][26],len[N],cnt,last,now,OP,vis[N];
SAM(){cnt = last = 1;}
inline void insert(char x){
int op = x - 'a';
int p = last,np = last = ++cnt;
len[np] = len[p] + 1;
if(OP)root[np] = modify(1,tot,len[np]);
for(;p && !ch[p][op];p = fa[p])ch[p][op] = np;
if(!p)fa[np] = 1;
else{
int q = ch[p][op];
if(len[q] == len[p] + 1)fa[np] = q;
else{
int nq = ++cnt;
len[nq] = len[p] + 1;memcpy(ch[nq],ch[q],sizeof(ch[q]));
fa[nq] = fa[q];fa[q] = fa[np] = nq;
for(;p && ch[p][op] == q;p = fa[p])ch[p][op] = nq;
}
}
now = len[np] - len[fa[np]];
}
void dfs(int u){
rep(i,0,25){
if(ch[u][i]){
dfs(ch[u][i]);
ch[u][i] = 0;
}
}
}
inline void init(){
rep(i,0,cnt)fa[i] = len[i] = 0;
dfs(1);
rep(i,0,25)ch[0][i] = ch[1][i] = 0;
last = cnt = 1;
}
inline void build(char *s){
int len = strlen(s + 1);
if(OP)tot = len;
rep(i,1,len)insert(s[i]);
}
}S,T;
void dfs(int u){
for(int v : g[u]){
dfs(v);
root[u] = merge(root[u],root[v],1,tot);
}
}
inline void solve(){
int l,r;
scanf("%s",s+1);
T.init();
read(l,r);
int n = strlen(s + 1),u = 1,len = 0;
long long ans = 0;
rep(i,1,n){
T.insert(s[i]);
int res = T.now;
int op = s[i] - 'a';
while(1){
if(S.ch[u][op] && query(root[S.ch[u][op]],1,tot,l + len,r)){
u = S.ch[u][op];
++len;
break;
}
if(!len)break;
--len;
if(len == S.len[S.fa[u]])u = S.fa[u];
}
ans += min(res,i - len);
}
printf("%lld\n",ans);
}
signed main(){
// freopen("P4770_19.in","r",stdin);
// freopen("4770.out","w",stdout);
scanf("%s",s+1);
S.OP = 1;
S.build(s);
rep(i,1,S.cnt)g[S.fa[i]].push_back(i);
dfs(1);
int q;
read(q);
while(q--)solve();
}
话说 SAM 还能套 LCT 的说,但是我不会,不想学了(),蒟蒻求赞qaq。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号