

【MYSQL】MYSQL入门基础
0 前言
软件安装
查看服务器的版本
- 方式一:登录到mysql服务端
select version(); - 方式二:没有登录到mysql服务端
mysql --version
或
mysql --V
启动关闭服务
-
注意安装时创建的服务名,我设置的为MYSQL5:
启动:net start mysql5;
关闭:net stop mysql5;
mysql8和SQLyog的问题:
使用sqlyog连接 Mysql 出现1251错误_四问四不知的博客-CSDN博客_sqlyog连接mysql错误码1251
按照视频教程安装5.5版本:
如果安装完软件没有启动,可以到安装的bin目录下找到MySQLInstanceConfig.exe文件,运行即可。
- 选择Detailed Configuration
- 选择开发机Developer machine内存最小
- 从上到下分别是多功能数据库、事务性数据库、非事务性数据库。选择第一个。
- C:存储空间,跳过
- 并发数:第一个20,第二个500适用于在线的,第三个可以自己设置。选择第一个。
- 设置端口号3306,默认是3306。
- 设置字符集,第一个是标准的、第二个utf8大部分、第三个自选可以使用utf8。选择第三个。
- 设置服务名字以及是否开机启动服务、并将Mysql添加到环境变量
- 选择第一个设置密码,两个相等。并打钩允许远程机访问。
- 直接点击执行即可。
图形用户界面SQLyog介绍:
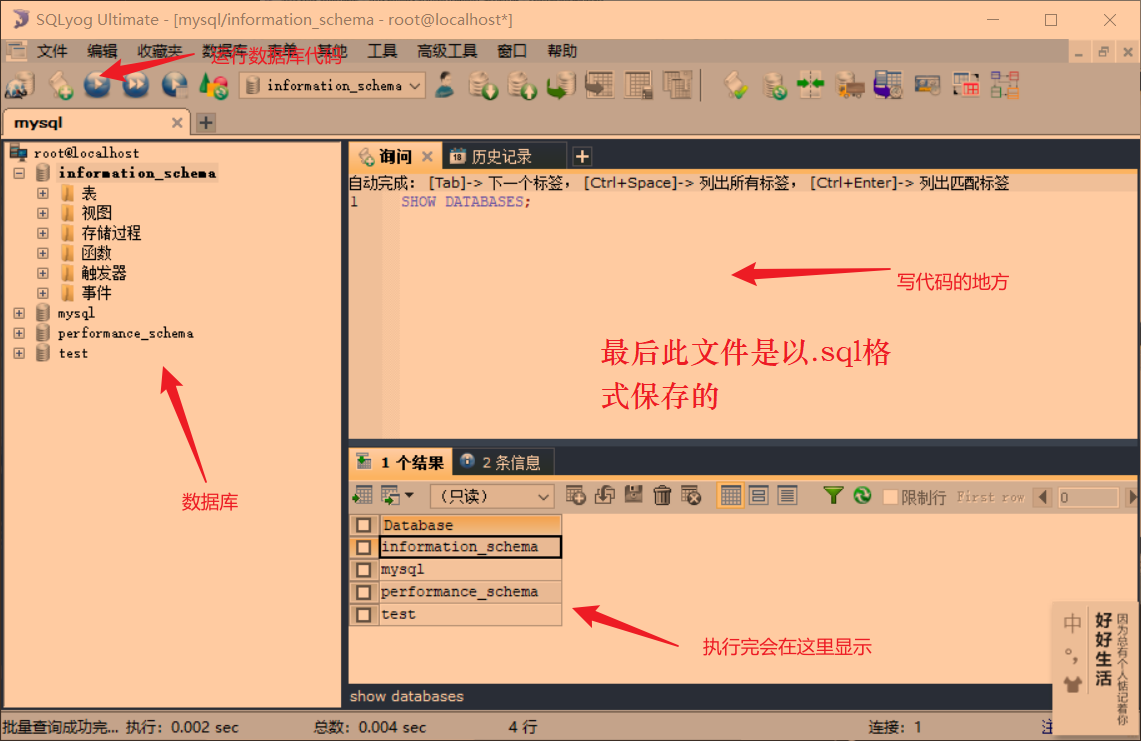
编写的代码,想执行哪部分,先选中而后F9。如果想规范化代码,先选中而后F12。
my.ini的介绍
可以直接更改my.ini,更改完需要重新启动mysql服务。net start mysql。
点击查看代码
# MySQL Server Instance Configuration File
# ----------------------------------------------------------------------
# Generated by the MySQL Server Instance Configuration Wizard
#
#
# Installation Instructions
# ----------------------------------------------------------------------
#
# On Linux you can copy this file to /etc/my.cnf to set global options,
# mysql-data-dir/my.cnf to set server-specific options
# (@localstatedir@ for this installation) or to
# ~/.my.cnf to set user-specific options.
#
# On Windows you should keep this file in the installation directory
# of your server (e.g. C:\Program Files\MySQL\MySQL Server X.Y). To
# make sure the server reads the config file use the startup option
# "--defaults-file".
#
# To run run the server from the command line, execute this in a
# command line shell, e.g.
# mysqld --defaults-file="C:\Program Files\MySQL\MySQL Server X.Y\my.ini"
#
# To install the server as a Windows service manually, execute this in a
# command line shell, e.g.
# mysqld --install MySQLXY --defaults-file="C:\Program Files\MySQL\MySQL Server X.Y\my.ini"
#
# And then execute this in a command line shell to start the server, e.g.
# net start MySQLXY
#
#
# Guildlines for editing this file
# ----------------------------------------------------------------------
#
# In this file, you can use all long options that the program supports.
# If you want to know the options a program supports, start the program
# with the "--help" option.
#
# More detailed information about the individual options can also be
# found in the manual.
#
#
# CLIENT SECTION
# ----------------------------------------------------------------------
#
# The following options will be read by MySQL client applications.
# Note that only client applications shipped by MySQL are guaranteed
# to read this section. If you want your own MySQL client program to
# honor these values, you need to specify it as an option during the
# MySQL client library initialization.
#
[client]
port=3306
[mysql]#客户端的配置
default-character-set=utf8
# SERVER SECTION
# ----------------------------------------------------------------------
#
# The following options will be read by the MySQL Server. Make sure that
# you have installed the server correctly (see above) so it reads this
# file.
#
[mysqld]#服务端的配置
# The TCP/IP Port the MySQL Server will listen on
port=3306
#Path to installation directory. All paths are usually resolved relative to this.
basedir="C:/Program Files (x86)/MySQL/MySQL Server 5.5/" 安装目录
#Path to the database root
datadir="C:/ProgramData/MySQL/MySQL Server 5.5/Data/" 数据目录
# The default character set that will be used when a new schema or table is
# created and no character set is defined
character-set-server=utf8 字符集
# The default storage engine that will be used when create new tables when
default-storage-engine=INNODB 存储引擎
# Set the SQL mode to strict
sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"
# The maximum amount of concurrent sessions the MySQL server will
# allow. One of these connections will be reserved for a user with
# SUPER privileges to allow the administrator to login even if the
# connection limit has been reached.
max_connections=100 最大连接数
四张表

1. 基础概念
-
数据库软件:又称数据库管理系统,DBMS。
-
表:表是结构化文件,存储某种特定的数据,数据库中存有很多的表。每个表都有一个名字标识自己。
-
数据类型:数据库中每个列都有数据类型。数据类型限制可存储在列中的数据种类(防止写错),还能帮助正确的排序数据,并在优化磁盘使用方面有重要作用。
-
主键:其值能唯一区分表中的每个行。
- 主键满足条件:每行都要有一个主键值(不允许为NULL),任两行的主键不同。
- 主键的好习惯:不更新、不重用主键列的值,不在主键列中使用可能更改的值(比如 身份证号可能增加位数、邮箱地址改变)。
-
MySQL的语法规范
- 不区分大小写,但建议关键字大写,表名、列名小写
- 每条命令最好用分号结尾
- 每条命令根据需要,可以进行缩进 或换行
- 注释
单行注释:#注释文字
单行注释:-- 注释文字(两个横线后有个空格)
多行注释:/* 注释文字 */
-
MySQL语言的组成:
DQL(Data Query Language)有关数据查询的SELECT;
DML(Data Management Language)数据的操作语言;
DDL(Data Define Language)数据的定义语言;
TCL(Transaction Control Language)事物控制语言;
2. 实用程序
2.1 安装
Windows下安装MySQL详细教程 - m1racle - 博客园 (cnblogs.com)
登录命令:
mysql -u root -p
password:123456
命令结束用;
退出exit或quit
帮助help
- SQL不区分大小写。许多程序员喜欢
关键字大写,而其他的列以及表名使用小写。 - 多条SQL语句间必须加分号
;。 - 处理SQL语句空格被忽略。多使用多行给出SQL语句。
3. 创建数据库、导入以及删除
3.1 创建数据库
CREATE DATABASE IF NOT EXISTS database_name;
-
CREATE DATABASE语句的后面是要创建的数据库名称。建议数据库名称尽可能是有意义和具有一定的描述性。 -
IF NOT EXISTS是语句的可选子句。IF NOT EXISTS子句可防止创建数据库服务器中已存在的新数据库的错误。不能在MySQL数据库服务器中具有相同名称的数据库。示例: mysql> create database henan; Query OK, 1 row affected (0.01 sec) 错误: mysql> create luoyang -> ; ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'luoyang' at line 1 mysql> create luoyang; ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'luoyang' at line 1
3.2 显示数据库
SHOW DATABASES;
示例:
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| henan |
| information_schema |
| luoyang |
| mysql |
| performance_schema |
| sys |
+--------------------+
6 rows in set (0.00 sec)
3.3 使用数据库
USE luoyang;
- 从现在开始,所有操作(如查询数据,创建新表或调用存储过程)都将对当前数据库(即
luoyang)产生影响。 - 数据库中有很多的表,可以使用
show tables来显示数据库中的所有表。
示例:
mysql> USE luoyang;
Database changed
3.4 导入数据库
source path\file.sql;
-
path使用绝对地址;mysql> source C:\Users\disheng\Desktop\mysql_scripts\create.sql #此是样例表,create只是创建了表 Query OK, 0 rows affected (0.03 sec) Query OK, 0 rows affected (0.02 sec) Query OK, 0 rows affected (0.02 sec) Query OK, 0 rows affected (0.02 sec) Query OK, 0 rows affected (0.02 sec) Query OK, 0 rows affected (0.01 sec) Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 Query OK, 0 rows affected (0.03 sec) Records: 0 Duplicates: 0 Warnings: 0 Query OK, 0 rows affected (0.03 sec) Records: 0 Duplicates: 0 Warnings: 0 Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> source C:\Users\disheng\Desktop\mysql_scripts\populate.sql;# 此处是将数据填充进去
3.5 删除数据库
DROP DATABASE IF EXISTS database_name;
- 遵循
DROP DATABASE是要删除的数据库名称。 与CREATE DATABASE语句类似,IF EXISTS是该语句的可选部分,以防止您删除数据库服务器中不存在的数据库。
mysql> DROP DATABASE IF EXISTS luoyang;
Query OK, 6 rows affected (0.07 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| henan |
| information_schema |
| luoyang |
| mysql |
| performance_schema |
| sys |
+--------------------+
6 rows in set (0.00 sec)
3.6 显示数据库中的表
SHOW TABLES;
mysql> show tables;
+-----------------+
| Tables_in_henan |
+-----------------+
| customers |
| orderitems |
| orders |
| productnotes |
| products |
| vendors |
+-----------------+
6 rows in set (0.00 sec)
3.7 显示表中所有的列
SHOW COLUMNS FROM 表的名字;
DESCRIBE 表的名字;(同功能的命令)
示例:
mysql> SHOW COLUMNS FROM customers;
+--------------+-----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-----------+------+-----+---------+----------------+
| cust_id | int | NO | PRI | NULL | auto_increment |
| cust_name | char(50) | NO | | NULL | |
| cust_address | char(50) | YES | | NULL | |
| cust_city | char(50) | YES | | NULL | |
| cust_state | char(5) | YES | | NULL | |
| cust_zip | char(10) | YES | | NULL | |
| cust_country | char(50) | YES | | NULL | |
| cust_contact | char(50) | YES | | NULL | |
| cust_email | char(255) | YES | | NULL | |
+--------------+-----------+------+-----+---------+----------------+
总结:
数据库 create database luoyang;创建数据库luoyang show databases;显示存在的所有数据库 use luoyang;使用数据库luoyang 表 show tables;显示数据库中的所有表 show columns from table_name;显示表中所有列信息,包含列名、数据类型等(describe table_name)
4 检索数据
说明:自己创建了henan数据库,并导入数据create.sql和 popular.sql,下面的均基于此数据库操作。
此数据库的展示:
mysql> show tables; +-----------------+ | Tables_in_henan | +-----------------+ | customers | | orderitems | | orders | | productnotes | | products | | vendors | +-----------------+ 6 rows in set (0.00 sec) mysql> describe customers;//描述列表 +--------------+-----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------------+-----------+------+-----+---------+----------------+ | cust_id | int | NO | PRI | NULL | auto_increment | | cust_name | char(50) | NO | | NULL | | | cust_address | char(50) | YES | | NULL | | | cust_city | char(50) | YES | | NULL | | | cust_state | char(5) | YES | | NULL | | | cust_zip | char(10) | YES | | NULL | | | cust_country | char(50) | YES | | NULL | | | cust_contact | char(50) | YES | | NULL | | | cust_email | char(255) | YES | | NULL | | +--------------+-----------+------+-----+---------+----------------+ 9 rows in set (0.00 sec)
4.1 SELECT命令检索数据
想要什么,从什么地方选择
总结:
- 选择所有、单、多列
mysql> select * from customers; #选择所有列 mysql> select cust_address from customers;#选择其中一列 mysql> select cust_address, cust_city, cust_state from customers;
- 限定符DISTINCT:消除重复的信息。可用于单列限定,当有多列时,只能限定多列。注意:限定符对所有的列起作用,多列都相同才算相同,有一列不同就会列出来
mysql> select vend_id from products; mysql> select distinct vend_id from products; mysql> select distinct vend_id, prod_id from products;#修饰多列时,只要有一列不同就不算相同,只能消除每个列都完全相同的
- 限制结果
select vend_id from products limit 5;;//结果中从index=0开始的前5行[0,5) SELECT vend_id FROM products limit 5, 5; //结果中从index=5开始数5行[5, 10)
- 完全限定的表名
- 其就类似于python中import导入数据时的
.操作SELECT DISTINCT customers.country FROM yiibaidb.customers;
使用IFNULL(exp1,exp2)函数:
主要功能是,判断exp1是否是NULL,如果是,那么就返回exp2,如果不是那就不操作。可以用于SELECT之后。
SELECT IFNULL(commission_pct, 0.0) AS result FROM employees;
注意:
- 使用SELECT检索的结果是原始的、未排序数据;
- 检索多个列时,输出结果中列的排序与
SELECT后的排序相同;- SQL语句不区分大小写。不过一般将关键字大写,其他的小写;
- SQL语句所有空格被忽略。在一行给出需要加分号
;,但是尽量写成多行易于调试;
4.2 对检索结果进行排序
首先,《MySQL必知必会》书中提供了两个文件create.sql和populate.sql,刚学会将其导入数据库
CREATE DATABASE example;
USE example;
SOURCE path\create.sql;此处是导入了空表,没有数据填充的空表
SOURCE path\populate.sql;此处是导入数据。
展示结果:
mysql> SHOW COLUMNS FROM customers;
mysql> SELECT cust_id FROM customers;
总结:
操作均为ORDER BY这一行。
关键字: ORDER BY
关键字: DESC
mysql> SELECT prod_name -> FROM products -> ORDER BY prod_name;//按照prod_name列排序,也可以使用别的列排序 mysql> SELECT prod_name -> FROM products -> ORDER BY prod_id;//使用别的列进行排序 mysql> SELECT prod_id, prod_price, prod_name -> FROM products -> ORDER BY prod_price, prod_name;//使用多列进行排序,默认是升序。先按照第一个排序,如果其中有重复的会按照第二个排序,否则就不再排序 mysql> SELECT prod_id, prod_price, prod_name -> FROM products -> ORDER BY prod_price DESC, prod_name;//DESC关键字放在列名后,表示降序,只对紧邻的列有用 mysql> SELECT prod_id, prod_price, prod_name -> FROM products -> ORDER BY prod_price DESC, prod_name -> LIMIT 2;//可以使用LIMIT来限定输出结果的个数
- 使用
ORDER BY对选的结果进行排序,默认是升序,如果需要降序,就在列后面加上DESC关键字;- 排序不仅可以使用选定的列,也可以使用别的列作为排序的依据;
- 排序不仅可以使用单列作为依据,也可以使用多列。多列适用于存在重复的值,再次使用第二个列作为排序的依据;
- 关键字使用顺序:
SELECTFROMORDER BYLIMIT。
ERROR:
mysql> select distinct vend_id -> from products -> order by prod_price -> limit 2; ERROR 3065 (HY000): Expression #1 of ORDER BY clause is not in SELECT list, references column 'henan.products.prod_price' which is not in SELECT list; this is incompatible with DISTINCT参考链接:mysql 5.7Expression #1 of ORDER BY clause is not in SELECT list_一共丢七只羊的专栏-CSDN博客
原因是:使用
distinct会将数据先放在临时集合里,而后根据prod_price进行排序,但是此时在此集合中并没有select prod_price,因此才会报此列不存在与select listselemysql> select vend_id -> from products -> order by products.prod_price;#显式写出 mysql> select vend_id, prod_price -> from products -> order by prod_price;#或者也select prod_price
4.3 过滤数据
4.3.1 单个WHERE子句
关键字: WHERE
WHERE 后可以使用如下几种匹配:
等价:等于(=)、不等于(!=或者<>)。
范围:大于(>)、小于(<)、大于等于(>=)、小于等于(<=)。
区间:
BETWEEN a1 AND a2,其中包含a1以及a2。关于匹配值是否带引号
''的说明:
- 如果匹配的是字符串,则带上单引号
'',如果是数字,则不带。有关NULL值的说明:
NULL值与0、空格、空字符串不相同,其表示不包含值。先单独对
NULL进行检查。因为当含有NULL的列参与筛选时,此列由于如何都不能匹配NULL值,因此不会返回此行信息。检查列数值中是否含有
NULL,可以在where后使用IS NULL子句。有关WHERE使用顺序的说明:
WHERE用于FROM后,对SELECT后的信息进行再次过滤,而后对过滤后的信息进行ORDER BY排序,而LIMIT用于ORDER BY后。
mysql> SELECT prod_name, prod_price //数值匹配
-> FROM products
-> WHERE prod_price=2.5;
+---------------+------------+
| prod_name | prod_price |
+---------------+------------+
| Carrots | 2.50 |
| TNT (1 stick) | 2.50 |
+---------------+------------+
2 rows in set (0.00 sec)
mysql> SELECT prod_name, prod_price//字符匹配
-> FROM products
-> WHERE prod_name='fuses';
+-----------+------------+
| prod_name | prod_price |
+-----------+------------+
| Fuses | 3.42 |
+-----------+------------+
1 row in set (0.00 sec)
mysql> SELECT prod_name, prod_price //ORDER BY使用于WHERE后
-> FROM products
-> WHERE prod_price<=10
-> ORDER BY prod_price;
+----------------+------------+
| prod_name | prod_price |
+----------------+------------+
| Carrots | 2.50 |
| TNT (1 stick) | 2.50 |
| Fuses | 3.42 |
| Sling | 4.49 |
| .5 ton anvil | 5.99 |
| Oil can | 8.99 |
| 1 ton anvil | 9.99 |
| Bird seed | 10.00 |
| TNT (5 sticks) | 10.00 |
+----------------+------------+
9 rows in set (0.00 sec)c)
mysql> SELECT vend_id, prod_name //不等于
-> FROM products
-> WHERE vend_id <> 1003;
+---------+--------------+
| vend_id | prod_name |
+---------+--------------+
| 1001 | .5 ton anvil |
| 1001 | 1 ton anvil |
| 1001 | 2 ton anvil |
| 1002 | Fuses |
| 1002 | Oil can |
| 1005 | JetPack 1000 |
| 1005 | JetPack 2000 |
+---------+--------------+
7 rows in set (0.00 sec)
mysql> SELECT prod_name, prod_price //BETWEEN AND
-> FROM products
-> WHERE prod_price BETWEEN 5 AND 10;
+----------------+------------+
| prod_name | prod_price |
+----------------+------------+
| .5 ton anvil | 5.99 |
| 1 ton anvil | 9.99 |
| Bird seed | 10.00 |
| Oil can | 8.99 |
| TNT (5 sticks) | 10.00 |
+----------------+------------+
5 rows in set (0.00 sec)
mysql> SELECT cust_id //判NULL
-> FROM customers
-> WHERE cust_email IS NULL;
+---------+
| cust_id |
+---------+
| 10002 |
| 10005 |
+---------+
2 rows in set (0.00 sec)
4.3.2 WHERE子句组合使用
关键字:
ANDORINNOT
AND多个子句满足才返回,优先级高于OR,因此要使用括号()来确定计算顺序
OR只要满足一个子句就返回
IN的作用类似于OR,对于括号内匹配的都要返回
NOT对INBETWEENEXISTS取反WHERE vend_id=1003 AND prod_price<=10;//AND WHERE (vend_id=1002 OR vend_id=1003) AND prod_price>=10;//OR WHERE vend_id IN (1002, 1003) AND prod_price<=10;//IN WHERE vend_id NOT IN (1002, 1003);//NOT
mysql> SELECT prod_id, prod_price, prod_name
-> FROM products
-> WHERE vend_id=1003 AND prod_price<=10;
+---------+------------+----------------+
| prod_id | prod_price | prod_name |
+---------+------------+----------------+
| FB | 10.00 | Bird seed |
| FC | 2.50 | Carrots |
| SLING | 4.49 | Sling |
| TNT1 | 2.50 | TNT (1 stick) |
| TNT2 | 10.00 | TNT (5 sticks) |
+---------+------------+----------------+
5 rows in set (0.00 sec)
mysql> SELECT prod_name, prod_price
-> FROM products
-> WHERE vend_id=1002 OR vend_id=1003;
+----------------+------------+
| prod_name | prod_price |
+----------------+------------+
| Fuses | 3.42 |
| Oil can | 8.99 |
| Detonator | 13.00 |
| Bird seed | 10.00 |
| Carrots | 2.50 |
| Safe | 50.00 |
| Sling | 4.49 |
| TNT (1 stick) | 2.50 |
| TNT (5 sticks) | 10.00 |
+----------------+------------+
9 rows in set (0.00 sec)
mysql> SELECT prod_name, vend_id ,prod_price
-> FROM products
-> WHERE vend_id=1002 OR vend_id=1003 AND prod_price>=10;
+----------------+---------+------------+
| prod_name | vend_id | prod_price |
+----------------+---------+------------+
| Fuses | 1002 | 3.42 |
| Oil can | 1002 | 8.99 |
| Detonator | 1003 | 13.00 |
| Bird seed | 1003 | 10.00 |
| Safe | 1003 | 50.00 |
| TNT (5 sticks) | 1003 | 10.00 |
+----------------+---------+------------+
6 rows in set (0.00 sec)
mysql> SELECT prod_name, vend_id ,prod_price
-> FROM products
-> WHERE vend_id=1002;
+-----------+---------+------------+
| prod_name | vend_id | prod_price |
+-----------+---------+------------+
| Fuses | 1002 | 3.42 |
| Oil can | 1002 | 8.99 |
+-----------+---------+------------+
2 rows in set (0.00 sec)
mysql> SELECT prod_name, vend_id ,prod_price
-> FROM products
-> WHERE (vend_id=1002 OR vend_id=1003) AND prod_price>=10;
+----------------+---------+------------+
| prod_name | vend_id | prod_price |
+----------------+---------+------------+
| Detonator | 1003 | 13.00 |
| Bird seed | 1003 | 10.00 |
| Safe | 1003 | 50.00 |
| TNT (5 sticks) | 1003 | 10.00 |
+----------------+---------+------------+
4 rows in set (0.00 sec)
mysql> SELECT prod_name, prod_price, vend_id
-> FROM products
-> WHERE vend_id IN (1002, 1003);
+----------------+------------+---------+
| prod_name | prod_price | vend_id |
+----------------+------------+---------+
| Fuses | 3.42 | 1002 |
| Oil can | 8.99 | 1002 |
| Detonator | 13.00 | 1003 |
| Bird seed | 10.00 | 1003 |
| Carrots | 2.50 | 1003 |
| Safe | 50.00 | 1003 |
| Sling | 4.49 | 1003 |
| TNT (1 stick) | 2.50 | 1003 |
| TNT (5 sticks) | 10.00 | 1003 |
+----------------+------------+---------+
9 rows in set (0.00 sec)
mysql> SELECT prod_name, prod_price, vend_id
-> FROM products
-> WHERE vend_id IN (1002, 1003) AND prod_price<=10;
+----------------+------------+---------+
| prod_name | prod_price | vend_id |
+----------------+------------+---------+
| Fuses | 3.42 | 1002 |
| Oil can | 8.99 | 1002 |
| Bird seed | 10.00 | 1003 |
| Carrots | 2.50 | 1003 |
| Sling | 4.49 | 1003 |
| TNT (1 stick) | 2.50 | 1003 |
| TNT (5 sticks) | 10.00 | 1003 |
+----------------+------------+---------+
7 rows in set (0.00 sec)
mysql> SELECT prod_name, prod_price, vend_id
-> FROM products
-> WHERE vend_id NOT IN (1002, 1003);
+--------------+------------+---------+
| prod_name | prod_price | vend_id |
+--------------+------------+---------+
| .5 ton anvil | 5.99 | 1001 |
| 1 ton anvil | 9.99 | 1001 |
| 2 ton anvil | 14.99 | 1001 |
| JetPack 1000 | 35.00 | 1005 |
| JetPack 2000 | 55.00 | 1005 |
+--------------+------------+---------+
5 rows in set (0.00 sec)
4.3.3 通配符过滤
总结:
关键字:LIKE
作用:是查找值中的局部匹配,类似于查找文献时的匹配,只不过此处是对字符,找文献是对单词。
LIKE关键字:用于WHERE后,对过滤出来的结果进行局部匹配,WHERE prod_name LIKE "%anvl"。使用的通配符如下:
百分号
%:可以代表任意个、任意数量的字符,数量可以是0个、1个、2个...下划线
_:只能代表一个字符。注意:
空格:保存词时,注意可能出现的情况,如词的尾部含有空格,可以使用
%。
NULL的情况:%可以匹配任何字符,但是不能匹配NULL,因此需要提前判断。通配符的使用注意:
- 不要过度使用通配符。如果其他操作符能达到目的,应该使用其他的操作符;
- 将通配符放在搜索开始处,搜索起来最慢;
- 仔细注意通配符的位置。
mysql> SELECT prod_name, prod_id
-> FROM products
-> WHERE prod_name LIKE "%anvil";
+--------------+---------+
| prod_name | prod_id |
+--------------+---------+
| .5 ton anvil | ANV01 |
| 1 ton anvil | ANV02 |
| 2 ton anvil | ANV03 |
+--------------+---------+
3 rows in set (0.00 sec)
mysql> SELECT prod_name, prod_id
-> FROM products
-> WHERE prod_name LIKE '_ ton anvil';
+-------------+---------+
| prod_name | prod_id |
+-------------+---------+
| 1 ton anvil | ANV02 |
| 2 ton anvil | ANV03 |
+-------------+---------+
2 rows in set (0.00 sec)
mysql> SELECT prod_id, prod_name//输出结果于此处的顺序相关
-> FROM products
-> WHERE prod_name LIKE '_ ton anvil';
+---------+-------------+
| prod_id | prod_name |
+---------+-------------+
| ANV02 | 1 ton anvil |
| ANV03 | 2 ton anvil |
+---------+-------------+
2 rows in set (0.00 sec)
4.3.4正则表达式
总结:
关键字:REGEXP
- 使用:
WHERE prod_name REGEXP '正则表达式';
几种匹配字符的符号:
匹配任意单个字符:
.常用于字符串中间替换任何字符。因为正则表达式就是用于子串的匹配。匹配特殊单个字符:
.()-|[]?*+等,需要进行转义,前面加\\如\\.用于匹配.。使用字符类匹配单个字符:
[:alpha:]类似于a-z等,在使用时外边需要再加个[]表示范围。
给单个字符的匹配范围:
[123]表示只能取1或2或3[1|2|3],另外还有[abc]表示[a|b|c]。注意不能省略[],否则如1|2|3 ton,将其看为1或2或3 ton。范围太长可以使用-,如[1-3] [a-z]。匹配多个字符: 对前面的一个字符进行匹配(为了对字符的数目进行控制)
*匹配0个或者多个
+匹配1个或者多个,类似{1,}
?匹配0个或者1个,类似{0,1}
{n}匹配n个
{n,}匹配大于等于n个
{n,m}匹配范围定位字符:
^文本开始
$文本结尾
LIKE 与 REGEXP的区别:
- LIKE后面的串是对整个字符串的匹配,而REGEXP后面的串是对字符串中的子串的匹配。
- 而如果想让REGEXP完成LIKE的工作,可以使用
^$来实现。
mysql> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '.000'
-> ORDER BY prod_name;
+--------------+
| prod_name |
+--------------+
| JetPack 1000 |
| JetPack 2000 |
+--------------+
2 rows in set (0.00 sec)
mysql> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '\\([0-9] sticks*\\)';
+----------------+
| prod_name |
+----------------+
| TNT (1 stick) |
| TNT (5 sticks) |
+----------------+
2 rows in set (0.00 sec)
mysql> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP 'sticks?';
+----------------+
| prod_name |
+----------------+
| TNT (1 stick) |
| TNT (5 sticks) |
+----------------+
2 rows in set (0.00 sec)
mysql> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '\\([0-9] sticks+\\)';
+----------------+
| prod_name |
+----------------+
| TNT (5 sticks) |
+----------------+
1 row in set (0.00 sec)
mysql> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP 'p.ck';
+--------------+
| prod_name |
+--------------+
| JetPack 1000 |
| JetPack 2000 |
+--------------+
2 rows in set (0.00 sec)
mysql> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '^[12\\.]';
+--------------+
| prod_name |
+--------------+
| .5 ton anvil |
| 1 ton anvil |
| 2 ton anvil |
+--------------+
3 rows in set (0.00 sec)
mysql> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '[15]';
+----------------+
| prod_name |
+----------------+
| .5 ton anvil |
| 1 ton anvil |
| JetPack 1000 |
| TNT (1 stick) |
| TNT (5 sticks) |
+----------------+
5 rows in set (0.00 sec)
mysql> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '1000|2000';
+--------------+
| prod_name |
+--------------+
| JetPack 1000 |
| JetPack 2000 |
+--------------+
2 rows in set (0.00 sec)
mysql> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '[a-c]';
+----------------+
| prod_name |
+----------------+
| .5 ton anvil |
| 1 ton anvil |
| 2 ton anvil |
| Detonator |
| Bird seed |
| Carrots |
| JetPack 1000 |
| JetPack 2000 |
| Oil can |
| Safe |
| TNT (1 stick) |
| TNT (5 sticks) |
+----------------+
12 rows in set (0.00 sec)
mysql> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '1|2|3 ton';
+---------------+
| prod_name |
+---------------+
| 1 ton anvil |
| 2 ton anvil |
| JetPack 1000 |
| JetPack 2000 |
| TNT (1 stick) |
+---------------+
5 rows in set (0.00 sec)
mysql> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '[[:space:]][0-9]';
+--------------+
| prod_name |
+--------------+
| JetPack 1000 |
| JetPack 2000 |
+--------------+
2 rows in set (0.00 sec)
mysql> SELECT prod_name
-> FROM products
-> WHERE prod_name REGEXP '0{3}';
+--------------+
| prod_name |
+--------------+
| JetPack 1000 |
| JetPack 2000 |
+--------------+
2 rows in set (0.00 sec)
5 创建计算字段
总结:
函数:Concat()
关键字:AS
为什么需要计算字段?
数据库中统计的数据并不一定符合应用程序的要求,可能在格式、信息整合、数据计算方面有需求,直接在数据库处进行计算字段而后传输给应用程序,否则容易占用带宽。也就是说我们需要直接从数据库中检索出转换、计算或格式化过的数据,而不是直接检索出数据。
计算字段运行时在
SELECT语句内创建的。这样更有助于后边的WHERE语句的过滤。字段于列的区别:字段常用于连接时,列常用于说表的列。
Concat()拼接函数:
使用方法:
SELECT Concat(RTrim(vend_name),'(',RTim(vend_country),')') AS vend_title。相当于是将筛选出来的列,进行重新组合,变成字符串输出。
RTrim()删除右端空格、LTrim()、TRim()由于拼接成的列只能打印出来,但是名字仍然是
Concat(RTrim(vend_name),'(',RTim(vend_country),')'),因此不能被引用。所以使用AS关键字起个别名,就可以被客户机引用。
AS的使用:使用AS后就可以引用。并且查看时,列的名字发生了变化。
除此之外,使用AS相当于是起别名,当出现列表的字段名不易理解时,可以使用AS起别名,起别名的方式有使用AS或者使用空格也可以。但是如果使用的别名中有空格或者特殊字符,那么就要使用双引号将其括起来。当然单引号也可以。
列的值的算数计算:
可使用的运算符:
+-*\使用方法:
SELECT prod_id, quantity,item_price, quantity*item_price AS expanded_price。要先将列找出来,之后再进行计算,并起别名。注意:多数DBMS使用+或者||实现拼接,MySQL使用Concat()函数实现,要注意。
mysql> SELECT Concat(RTrim(vend_name),'(',RTrim(vend_country),')') AS vend_title
-> FROM vendors
-> ORDER BY vend_name;
+------------------------+
| vend_title |
+------------------------+
| ACME(USA) |
| Anvils R Us(USA) |
| Furball Inc.(USA) |
| Jet Set(England) |
| Jouets Et Ours(France) |
| LT Supplies(USA) |
+------------------------+
6 rows in set (0.00 sec)
mysql> SELECT prod_id,
-> quantity,
-> item_price,
-> quantity*item_price AS expanded_price
-> FROM orderitems
-> WHERE order_num = 20005;
+---------+----------+------------+----------------+
| prod_id | quantity | item_price | expanded_price |
+---------+----------+------------+----------------+
| ANV01 | 10 | 5.99 | 59.90 |
| ANV02 | 3 | 9.99 | 29.97 |
| TNT2 | 5 | 10.00 | 50.00 |
| FB | 1 | 10.00 | 10.00 |
+---------+----------+------------+----------------+
4 rows in set (0.00 sec)
SELECT salary AS "out put" FROM employees;
SELECT salary "out put" FROM employees;
6 函数
6.1 文本处理函数
总结:
注意:不同DBMS实现的函数不同,可移植性不强,因此如果决定使用函数,应该保证做好代码注释。
文本处理函数


- 可以直接作用于列上。如下面列出vend_name只是为了与后面的形成对比。
mysql> SELECT vend_name, Upper(vend_name) AS vend_name_upcase -> FROM vendors -> ORDER BY vend_name; +----------------+------------------+ | vend_name | vend_name_upcase | +----------------+------------------+ | ACME | ACME | | Anvils R Us | ANVILS R US | | Furball Inc. | FURBALL INC. | | Jet Set | JET SET | | Jouets Et Ours | JOUETS ET OURS | | LT Supplies | LT SUPPLIES | +----------------+------------------+ 6 rows in set (0.01 sec)
6.2 时间处理函数
日期时间处理函数
- 一般来说,日期和时间采用对应的数据类型和格式存储,以便过滤与节省存储。但是其存储格式与应用程序使用的日期时间格式不同,因此需要这些时间日期转换函数。
- 不论是插入或者更新表值还是用WHERE子句进行过滤,日期必须为yyyy-mm-dd格式。

mysql> SELECT cust_id, order_num -> FROM orders -> WHERE order_date='2005-09-01'; +---------+-----------+ | cust_id | order_num | +---------+-----------+ | 10001 | 20005 | +---------+-----------+ 1 row in set (0.00 sec) mysql> SELECT cust_id, order_num //应该使用此格式,因为这种写法比较保险,order_date关键字列可能改变,比如其值变为 日期 和 时间,此种写法就比上面的写法好。 -> FROM orders -> WHERE Date(order_date)='2005-09-01'; +---------+-----------+ | cust_id | order_num | +---------+-----------+ | 10001 | 20005 | +---------+-----------+ 1 row in set (0.00 sec) mysql> SELECT cust_id, order_num -> FROM orders -> WHERE Year(order_date)=2005 AND Month(order_date)=9; +---------+-----------+ | cust_id | order_num | +---------+-----------+ | 10001 | 20005 | | 10003 | 20006 | | 10004 | 20007 | +---------+-----------+ 3 rows in set (0.01 sec)
6.3 数值处理函数
- 数值处理函数

6.4 聚集函数
聚集函数
- 有时需要的是汇总信息,而不是实际的表中的信息。聚合函数用于检索以及汇总数据,以便分析和报表的生成。
- 返回单个值。
聚集函数类型
AVG() :返回某列平均值
COUNT():返回某列的行数
MAX():返回某列最大值
MIN():返回某列最小值
SUM():返回某列值之和
聚集函数注意事项:
- 五个函数在计算某列的值时,会自动忽略NULL的行;
- 五个函数都可以作用于某个列,括号中为列关键字即可;
- COUNT( *)可用于计算所有的行数;
- 五个函数可以与WHERE配合使用,将过滤的值进行操作;
- 五个函数的括号中可以传入不同列的算数运算操作
+ - * \;- AVG函数一次只能计算一列,要计算多列应该多次使用AVG函数。
DISTINCT与聚集函数:
- DISTINCT用于AVG、SUM、COUNT时,只能修饰列名,并且是‘贴身修饰’,不能修饰计算表达式。
- 不写DISTINCT时,就是ALL。因为ALL是默认的。
组合SELECT后的表达式:
- SELECT后的表达式可以是 多个,中间使用逗号隔开,每个表达式可以使用
AS创建别名。mysql> SELECT AVG(prod_price) AS acg_price -> FROM products -> WHERE vend_id = 1003; +-----------+ | acg_price | +-----------+ | 13.212857 | +-----------+ 1 row in set (0.00 sec) mysql> SELECT (AVG(prod_price)+AVG(prod_price))/2 AS MM -> FROM products -> ; +---------------+ | MM | +---------------+ | 16.1335714280 | +---------------+ 1 row in set (0.01 sec) mysql> SELECT AVG(prod_price) AS avg_price1, AVG(prod_price) AS avg_price2 -> FROM products -> ; +------------+------------+ | avg_price1 | avg_price2 | +------------+------------+ | 16.133571 | 16.133571 | +------------+------------+ 1 row in set (0.00 sec) mysql> SELECT COUNT(*) AS num_cast -> FROM customers; +----------+ | num_cast | +----------+ | 5 | +----------+ 1 row in set (0.01 sec) mysql> SELECT COUNT(cust_email) AS num_cast -> FROM customers; +----------+ | num_cast | +----------+ | 3 | +----------+ 1 row in set (0.00 sec) mysql> SELECT AVG(item_price*quantity) AS avg_price -> FROM orderitems -> WhERE order_num = 20005; +-----------+ | avg_price | +-----------+ | 37.467500 | +-----------+ 1 row in set (0.01 sec) mysql> SELECT AVG(DISTINCT prod_price) AS avg_price -> FROM products -> ; +-----------+ | avg_price | +-----------+ | 17.780833 | +-----------+ 1 row in set (0.00 sec)
7 分组数据
总结:
关键字:GROUP BY
- 为什么需要分组呢?通俗点讲,如某个公司选择批量购买路由器,将市场上的所有路由器品牌厂家价格等做个表,想统计一共有多少个产品可供选择可以
SELECT COUNT(*) AS number from products;即可,但是如果想知道每个公司可提供的品牌有多少个或者每个公司的路由器的平均价格等,需要根据公司序号对公司进行分组,而后再每个公司中计算数量或者平均值。相当于是缩小原来数据的范围。
目的:按照某一列或者某几列对数据进行分组,对每组信息进行相关计算或者信息统计。其会对输出结果进行排序。但是不要依赖,排序时仍然要使用
ORDER BY。实施:按照目的可以得知,在
SELECT时,需要列出多列名称,以及计算或者信息统计的函数。如mysql> SELECT vend_id, prod_price, SUM(prod_price) -> FROM products -> GROUP BY vend_id, prod_price;#分组依据的关键字都要在select中出现 +---------+------------+-----------------+ | vend_id | prod_price | SUM(prod_price) | +---------+------------+-----------------+ | 1001 | 5.99 | 5.99 | | 1001 | 9.99 | 9.99 | | 1001 | 14.99 | 14.99 | | 1003 | 13.00 | 13.00 | | 1003 | 10.00 | 20.00 | | 1003 | 2.50 | 5.00 | | 1002 | 3.42 | 3.42 | | 1005 | 35.00 | 35.00 | | 1005 | 55.00 | 55.00 | | 1002 | 8.99 | 8.99 | | 1003 | 50.00 | 50.00 | | 1003 | 4.49 | 4.49 | +---------+------------+-----------------+ 12 rows in set (0.00 sec) mysql> select quantity*item_price as price//可以使用别名 -> from orderitems -> group by price; +---------+ | price | +---------+ | 59.90 | | 29.97 | | 50.00 | | 10.00 | | 55.00 | | 1000.00 | | 125.00 | | 8.99 | | 4.49 | | 14.99 | +---------+ 10 rows in set (0.00 sec)规定:
GROUP BY后包含单列或多列。包含多列时,都相同时才作为一组。GROUP BY后可以使用AS起的别名的。
SELECT列出的所有 列 或者 表达式 都要作为GROUP BY分组的依据,除了聚集计算外(count、min、max、AVG、sum)。NULL问题。NULL将作为一个分组,若该列存在NULL的话。
关键字顺序。
SELECTFROMWHEREGROUP BYORDER BY。说明:select列出的所有列都要作为分组的依据,因为如果相同才分为一组,是要对信息进行合并的,如果将所有信息都列出来,再按照某一列分组是没办法合并信息的。
在外联结学习的时候,使用了聚合计算
COUNT(),此处也是如此,COUNT()作用到整张表上输出为一个值,因为整张表是一个组,因此如果SELECT需要列出多列,那需要先进行GROUP BY分组,而后COUNT()对所有的组内进行聚合计算。而在使用分组时,SELECT列出的所有项都要出现在GROUP BY中,分组是要对重复信息的合并,列出但是没有出现在GROUP BY中,进行合并时没有办法处理这部分信息。关键字:WITH ROLLUP
- 作用:类似于excel表格中的最后一行,汇总的行。表示总计。
- 实施:用于
GROUP BY后面。mysql> SELECT vend_state, COUNT(*) AS num -> FROM vendors -> GROUP BY vend_state; +------------+-----+ | vend_state | num | +------------+-----+ | MI | 1 | | OH | 1 | | CA | 1 | | NY | 1 | | NULL | 2 | +------------+-----+ 5 rows in set (0.00 sec) mysql> SELECT vend_state, COUNT(*) AS num -> FROM vendors -> GROUP BY vend_state WITH ROLLUP; +------------+-----+ | vend_state | num | +------------+-----+ | NULL | 2 | | CA | 1 | | MI | 1 | | NY | 1 | | OH | 1 | | NULL | 6 | //区别在此处,此处多出一行,总计 +------------+-----+关键字:HAVING
- 目的:用于过滤分组。留下哪些分组,排除哪些分组,不论是基于排序的列过滤还是基于聚合计算过滤都行。
- 使用方式:与WHERE使用方式相同,HAVING支持所有的WHERE操作符,包括通配符条件和带多个操作符的子句)
- 与WHERE的区别:HAVING是对分组的过滤,WHERE是对行的过滤。先需要对行过滤,而后分组,之后过滤分组。
- 具体使用时,where像是基于原来的列进行过滤,而having像是对统计后的信息进行过滤分组。
mysql> SELECT cust_id, COUNT(*) AS orders -> FROM orders -> GROUP BY cust_id -> HAVING COUNT(*)>=2; +---------+--------+ | cust_id | orders | +---------+--------+ | 10001 | 2 | +---------+--------+ 1 row in set (0.00 sec) mysql> SELECT vend_id, COUNT(*) AS num_prod -> FROM products -> WHERE prod_price >= 10 -> GROUP BY vend_id -> HAVING COUNT(*) >=2; +---------+----------+ | vend_id | num_prod | +---------+----------+ | 1003 | 4 | | 1005 | 2 | +---------+----------+ 2 rows in set (0.00 sec) mysql> SELECT order_num, SUM(quantity*item_price) AS ordertotal -> FROM orderitems -> GROUP BY order_num -> HAVING ordertotal >=50 -> ORDER BY ordertotal; +-----------+------------+ | order_num | ordertotal | +-----------+------------+ | 20006 | 55.00 | | 20008 | 125.00 | | 20005 | 149.87 | | 20007 | 1000.00 | +-----------+------------+ 4 rows in set (0.00 sec)
分组与排序:
名称 ORDER BY GROUP BY 输出 按列排序输出的结果 分组行。可能不是分组的顺序。 列名 任何列(包含没有选择的)都可以使用 所有选择的列或者表达式都要写 聚集函数 不一定需要 需要
- 一般在使用Group by 子句时,应该也给出order by子句,这是保证正确排序的唯一方法。
子句顺序
子句 说明 是否必须使用 SELECT 返回的列或者表达式 是 FROM 从中检索数据的表 仅在从表中选择数据时使用 WHERE 行级过滤 否 GROUP BY 分组说明 仅在按组计算聚集时使用 HAVING 组级过滤 否 ORDER BY 输出排序顺序 否 LIMIT 要检索的行数 否
8 使用子查询(多表)
为什么要使用子查询?子查询是什么?子查询是嵌套在其他查询中的查询,这些查询有先后关系,先查询嵌套的,再以嵌套查询的结果放到外部的查询中使用。前面都是基于一张表的简单查询,而子查询可以在多个表中查询。如两张表中使用顾客id号相关联起来,通过判断一张表的某些列得到最终的顾客id,而后根据此id去另一张表中获得相对的信息。
8.1 多个关联的表的信息查询--应用于WHERE条件中
-
应用于WHERE条件中的子查询,一个表中获取的结果作为另一个表的过滤依据。
-
示例:主要目的是获取产品为TNT的顾客姓名与联系人,由检索TNT得到订单号
order_num,由订单号得到顾客号cust_id,由顾客号得到顾客信息。mysql> SELECT cust_name, cust_contact -> FROM customers -> WHERE cust_id IN (SELECT cust_id -> FROM orders -> WHERE order_num IN (SELECT order_num -> FROM orderitems -> WHERE prod_id='TNT2')); +----------------+--------------+ | cust_name | cust_contact | +----------------+--------------+ | Coyote Inc. | Y Lee | | Yosemite Place | Y Sam | +----------------+--------------+ 2 rows in set (0.00 sec) -
注意:
- 子查询可以嵌套,但是嵌套层数不能太深,否则影响性能。
- 嵌套的子句SELECT的列与外部的WHERE列要匹配,通常是单列与单列匹配,如果需要也可以多列。
- 子查询常常和
IN配合使用,也可以与= <>配合使用。
8.2 子查询作为计算字段--应用于SELECT中
-
应用于计算字段的子查询,需要根据当前表的信息作为依据,获取另一个表中的统计或计算数据(count、*),并将此数据与当前查询的信息合为一张表展现出来。
-
示例:找出每个客户订单总数。
mysql> SELECT cust_name, -> cust_state, -> (SELECT COUNT(*) -> FROM orders -> WHERE orders.cust_id=customers.cust_id) AS orders#此处必须使用完全限定列名 -> FROM customers -> ORDER BY cust_name; +----------------+------------+--------+ | cust_name | cust_state | orders | +----------------+------------+--------+ | Coyote Inc. | MI | 2 | | E Fudd | IL | 1 | | Mouse House | OH | 0 | | Wascals | IN | 1 | | Yosemite Place | AZ | 1 | +----------------+------------+--------+ 5 rows in set (0.00 sec)- 说明:
- 第5行必须使用完全限定列名,因为需要将customers中的cust_id作为检索的依据,在检索orders中 cust_id与其相等的数量。上述代码的过程为外部检索顾客名字以及状态,子查询中检索对应顾客的订单数量,对于外部表的每一行都进行了数量的统计较好理解一下,如外部表第一行
customers.cust_id=3,那么就去orders表中查找cust_id=3的信息有多少行。
- 第5行必须使用完全限定列名,因为需要将customers中的cust_id作为检索的依据,在检索orders中 cust_id与其相等的数量。上述代码的过程为外部检索顾客名字以及状态,子查询中检索对应顾客的订单数量,对于外部表的每一行都进行了数量的统计较好理解一下,如外部表第一行
- 相关子查询:
WHERE customers.cust_id = orders.cust_id,涉及外部查询的子查询为相关子查询。任何时候只要列名有多义性就要使用这种语法。 - 建议:逐渐增加子查询来建立查询。首先建立和测试最内层的查询,然后用硬编码数据建立和测试外层查询,并且确认它正常后才嵌入子查询。
- 说明:
9 联结表(多表)
什么是联结表?联结表是一个动词,是将关系表联结起来,因为两个表通过键值相联系,在一个表中的主键变为另一个表中的外键,通过这个键值将两个表的对应行对应起来。外键定义了两个表的关系。
为什么使用联结?因为在设计与创建关系表时需要考虑表中的重复数据、修改数据等是否方便。设计关系表的最终目的是表A通过外键与表B建立关系,A中可以重复索引表B中的项,如果B实现在A中就会包含大量的重复信息;此外修改B中的信息可以只修改一次,如果B实现在A中就要修改多次。也就是说当一个表中的某些信息总是重复出现,或者修改时总是需要对同一信息进行多处修改,那么就需要考虑将此列信息单独创建一个表。
使用联结优势?关系数据可以有效的存储和方便的处理,关系数据库的可伸缩性远比非关系数据库要好。可以考虑将所有信息都放在一块形成一张大表,或者将所有信息放在多张信息不重复的表中,后者更为方便维护与更改。可伸缩性是指能够适应不断增加的工作量而不失败。
9.1 简单联结
-
理解联结
- 联结可以将存储在多个表中的数据使用单条SELECT语句检索出数据,联结是一种机制,使用特殊的语法可以连接多个表返回一组输出。联结在运行时关联表中正确的行。
- 联结不是物理实体,也即是说在实际的表中不会记录哪些表联结在一起,联结需要
MySQL根据需要建立,它存在于查询的执行中。 - 使用关系表时,在关系列中插入合法的数据很重要,为防止插入非法数据,可以指示MySQL只允许在表中的对应列出现合法值。
-
使用WHERE子句创建联结
-
联结两个表


目的:输出所有商品的供应商以及商品名字、价格。通过products表中的供应商号可以从供应商表vendors中找到对应的供应商名字。
联结:
FROM后列出对应的两个表,WHERE对两个表的对应键进行联结。重点:在一条
SELECT语句中联结几个表时,相应的关系时在运行中构造 的。在数据库的定义中不存在能只是MySQL如何对表进行联结的东西。在联结两个表时实际上是将第一个表中的每一行与第二个表中的每一行配对。WHERE子句作为过滤条件,它只包含那些匹配给定条件的行。如果没有WHERE子句,第一个表中的每个行将于第二个表中的每个行配对,而不管他们逻辑上是否可以配在一起。mysql> SELECT vend_name,prod_name,prod_price -> FROM vendors,products -> WHERE products.vend_id=vendors.vend_id -> ORDER BY vend_name,prod_price; +-------------+----------------+------------+ | vend_name | prod_name | prod_price | +-------------+----------------+------------+ | ACME | Carrots | 2.50 | | ACME | TNT (1 stick) | 2.50 | | ACME | Sling | 4.49 | | ACME | Bird seed | 10.00 | | ACME | TNT (5 sticks) | 10.00 | | ACME | Detonator | 13.00 | | ACME | Safe | 50.00 | | Anvils R Us | .5 ton anvil | 5.99 | | Anvils R Us | 1 ton anvil | 9.99 | | Anvils R Us | 2 ton anvil | 14.99 | | Jet Set | JetPack 1000 | 35.00 | | Jet Set | JetPack 2000 | 55.00 | | LT Supplies | Fuses | 3.42 | | LT Supplies | Oil can | 8.99 | +-------------+----------------+------------+ 14 rows in set (0.00 sec) -
联结多个表

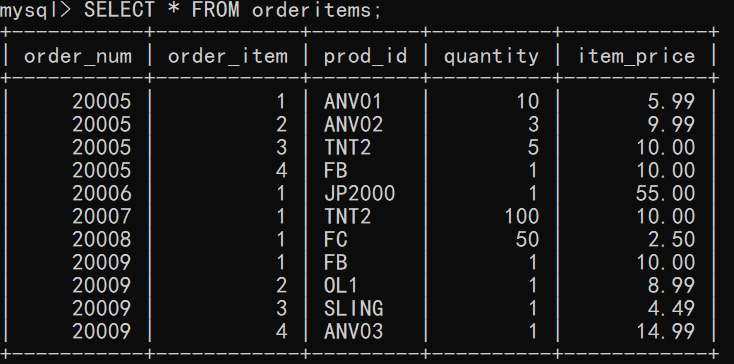
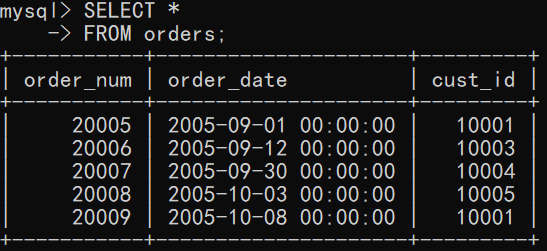
目的:输出购买TNT2的顾客。可通过订单详情表获取TNT2对应的订单号,由订单表查询订单号获取顾客ID,再有顾客表查询顾客ID得到顾客姓名。
联结:
FROM后列出多个表,WHERE后是对应表的联结关系,各个关系使用AND联结。注意:不要联结不必要的表,耗费不必要的资源。
mysql> SELECT cust_name, cust_state -> FROM customers, orders, orderitems -> WHERE orderitems.prod_id='TNT2' -> AND orderitems.order_num = orders.order_num -> AND orders.cust_id = customers.cust_id; +----------------+------------+ | cust_name | cust_state | +----------------+------------+ | Coyote Inc. | MI | | Yosemite Place | AZ | +----------------+------------+ 2 rows in set (0.00 sec)
-
-
使用内部联结
INNER JOIN ... ON...-
联结单个表
使用:
INNER JOIN后紧接着表,ON后紧接着联结关系。此关系式用于FROM 表后。mysql> SELECT vend_name, prod_name, prod_price -> FROM vendors INNER JOIN products -> ON products.vend_id=vendors.vend_id -> ORDER BY vend_name, prod_price; +-------------+----------------+------------+ | vend_name | prod_name | prod_price | +-------------+----------------+------------+ | ACME | Carrots | 2.50 | | ACME | TNT (1 stick) | 2.50 | | ACME | Sling | 4.49 | | ACME | Bird seed | 10.00 | | ACME | TNT (5 sticks) | 10.00 | | ACME | Detonator | 13.00 | | ACME | Safe | 50.00 | | Anvils R Us | .5 ton anvil | 5.99 | | Anvils R Us | 1 ton anvil | 9.99 | | Anvils R Us | 2 ton anvil | 14.99 | | Jet Set | JetPack 1000 | 35.00 | | Jet Set | JetPack 2000 | 55.00 | | LT Supplies | Fuses | 3.42 | | LT Supplies | Oil can | 8.99 | +-------------+----------------+------------+ 14 rows in set (0.00 sec) -
联结多个表
使用:
INNER JOIN...ON...算一个整体,联结一个写一个,有多个这样的表,就写多次。mysql> SELECT cust_name, cust_state -> FROM customers INNER JOIN orders ON customers.cust_id=orders.cust_id -> INNER JOIN orderitems ON orderitems.order_num=orders.order_num -> WHERE orderitems.prod_id='TNT2'; +----------------+------------+ | cust_name | cust_state | +----------------+------------+ | Coyote Inc. | MI | | Yosemite Place | AZ | +----------------+------------+ 2 rows in set (0.00 sec)在外联结学习的时候,使用了聚合计算
COUNT(),此处也是如此,COUNT()作用到整张表上输出为一个值,因为整张表是一个组,因此如果SELECT需要列出多列,那需要先进行GROUP BY分组,而后COUNT()对所有的组内进行聚合计算。而在使用分组时,SELECT列出的所有项都要出现在GROUP BY中,分组是要对重复信息的合并,列出但是没有出现在GROUP BY中,进行合并时没有办法处理这部分信息。
-
9.2 高级联结
- 自联结:
FROM时联结的两个表是同一个表,为的是统计同一张表中的信息。 - 自然联结:由于表使用外键与其他表建立关系,因此在合并输出表时,会输出所有的数据,包括重复的列。因此使用自然联结会排除重复的列,留下的都是唯一的列。
- 外部联结:表通过外键与其他表建立联系,但是此表的外键的项可能没有用完原表中所有的项。比如A表是商品表,有一栏是供应商,B表是供应商信息表,A表中的商品可能只对应一部分供应商,而其他的供应商的商品没有采纳。内部联结时只能列出能够联结的项,对于没有联结的项没有输出,而外部联结会将所有的项都输出,不论是否联结。(此处的项指的是一行信息)外部联结可以指定方向,指定的这个表中的所有项都会输出。
- 联结的两种方式,一种是使用WHERE,一种是使用JOIN。使用呢JOIN的联结方式中,应该总是提供联结条件,否则会得出笛卡尔积。在一个联结中可以包含多个表,甚至对于每个联结可以采用不同的联结类型,虽然这样做是合法的,在一起测试之前,应该先分别测试每个联结。
9.2.1 自联结
-
用途:自联结常用于从相同表中检索数据,而不是用子查询,因为使用自联结的处理速快快于子查询。
-
语法:WHERE
FROM products as p1, products as p2 -
示例:找出与'DTNTR'相同的供货商的产品。

mysql> SELECT p1.prod_id, p1.prod_name -> FROM products As p1, products AS p2 -> WHERE p1.vend_id=p2.vend_id -> AND p2.prod_id='DTNTR'; +---------+----------------+ | prod_id | prod_name | +---------+----------------+ | DTNTR | Detonator | | FB | Bird seed | | FC | Carrots | | SAFE | Safe | | SLING | Sling | | TNT1 | TNT (1 stick) | | TNT2 | TNT (5 sticks) | +---------+----------------+ 7 rows in set (0.00 sec)说明:通过
vend_id建立联结,通过限制p2表的prod_id来得到对应的vend_id,从而在p1表中输出对应vend_id的商品。注意:当不进行
DTNTR限制的时候,两个表中的vend_id相等的项会对应联结,也就是只要相等,就会像笛卡尔积似的排列组合在一起。如下所示,通过观察products表发现,vend_id项有重复的项,因此这些相等的vend_id项会组合,因此p1中的一个项会对应p2中的三个项。使用WHERE联结的项,如果出现重复的,就会使用笛卡尔积一一组合进行输出mysql> SELECT p1.prod_id, p1.prod_name -> FROM products AS p1, products AS p2 -> WHERE p1.vend_id=p2.vend_id; +---------+----------------+ | prod_id | prod_name | +---------+----------------+ | ANV01 | .5 ton anvil | | ANV01 | .5 ton anvil | | ANV01 | .5 ton anvil | | ANV02 | 1 ton anvil | | ANV02 | 1 ton anvil | | ANV02 | 1 ton anvil | | ANV03 | 2 ton anvil | | ANV03 | 2 ton anvil | | ANV03 | 2 ton anvil | | DTNTR | Detonator | | DTNTR | Detonator | | DTNTR | Detonator | | DTNTR | Detonator | | DTNTR | Detonator | | DTNTR | Detonator | | DTNTR | Detonator | | FB | Bird seed | | FB | Bird seed | | FB | Bird seed | | FB | Bird seed | | FB | Bird seed | | FB | Bird seed | | FB | Bird seed | | FC | Carrots | | FC | Carrots | | FC | Carrots | | FC | Carrots | | FC | Carrots | | FC | Carrots | | FC | Carrots | | FU1 | Fuses | | FU1 | Fuses | | JP1000 | JetPack 1000 | | JP1000 | JetPack 1000 | | JP2000 | JetPack 2000 | | JP2000 | JetPack 2000 | | OL1 | Oil can | | OL1 | Oil can | | SAFE | Safe | | SAFE | Safe | | SAFE | Safe | | SAFE | Safe | | SAFE | Safe | | SAFE | Safe | | SAFE | Safe | | SLING | Sling | | SLING | Sling | | SLING | Sling | | SLING | Sling | | SLING | Sling | | SLING | Sling | | SLING | Sling | | TNT1 | TNT (1 stick) | | TNT1 | TNT (1 stick) | | TNT1 | TNT (1 stick) | | TNT1 | TNT (1 stick) | | TNT1 | TNT (1 stick) | | TNT1 | TNT (1 stick) | | TNT1 | TNT (1 stick) | | TNT2 | TNT (5 sticks) | | TNT2 | TNT (5 sticks) | | TNT2 | TNT (5 sticks) | | TNT2 | TNT (5 sticks) | | TNT2 | TNT (5 sticks) | | TNT2 | TNT (5 sticks) | | TNT2 | TNT (5 sticks) | +---------+--------------
9.2.2 自然联结
-
自然联结是对两张表中,
字段和数据类型都相同的字段进行等值连接,再将表中重复的字段去掉就是自然联结。 -
语法:
FROM customers NATURAL JOIN products -
注意:
- 必须是
列名相同且类型相同,不允许带ONUSING。 SELECT处要使用SELECT *时能够自动排除相同的列,使用其他方式的输出不能自行排除相同的列,需要自己列出输出。
- 必须是
-
示例:
mysql> SELECT * -> FROM orders NATURAL JOIN orderitems;#会自动联结,会自动排除 +-----------+---------------------+---------+------------+---------+----------+------------+ | order_num | order_date | cust_id | order_item | prod_id | quantity | item_price | +-----------+---------------------+---------+------------+---------+----------+------------+ | 20005 | 2005-09-01 00:00:00 | 10001 | 1 | ANV01 | 10 | 5.99 | | 20005 | 2005-09-01 00:00:00 | 10001 | 2 | ANV02 | 3 | 9.99 | | 20005 | 2005-09-01 00:00:00 | 10001 | 3 | TNT2 | 5 | 10.00 | | 20005 | 2005-09-01 00:00:00 | 10001 | 4 | FB | 1 | 10.00 | | 20006 | 2005-09-12 00:00:00 | 10003 | 1 | JP2000 | 1 | 55.00 | | 20007 | 2005-09-30 00:00:00 | 10004 | 1 | TNT2 | 100 | 10.00 | | 20008 | 2005-10-03 00:00:00 | 10005 | 1 | FC | 50 | 2.50 | | 20009 | 2005-10-08 00:00:00 | 10001 | 1 | FB | 1 | 10.00 | | 20009 | 2005-10-08 00:00:00 | 10001 | 2 | OL1 | 1 | 8.99 | | 20009 | 2005-10-08 00:00:00 | 10001 | 3 | SLING | 1 | 4.49 | | 20009 | 2005-10-08 00:00:00 | 10001 | 4 | ANV03 | 1 | 14.99 | +-----------+---------------------+---------+------------+---------+----------+------------+ 11 rows in set (0.00 sec) mysql> SELECT orders.*, orderitems.* -> FROM orders NATURAL JOIN orderitems;#会自动联结,但不会排除重复 +-----------+---------------------+---------+-----------+------------+---------+----------+------------+ | order_num | order_date | cust_id | order_num | order_item | prod_id | quantity | item_price | +-----------+---------------------+---------+-----------+------------+---------+----------+------------+ | 20005 | 2005-09-01 00:00:00 | 10001 | 20005 | 1 | ANV01 | 10 | 5.99 | | 20005 | 2005-09-01 00:00:00 | 10001 | 20005 | 2 | ANV02 | 3 | 9.99 | | 20005 | 2005-09-01 00:00:00 | 10001 | 20005 | 3 | TNT2 | 5 | 10.00 | | 20005 | 2005-09-01 00:00:00 | 10001 | 20005 | 4 | FB | 1 | 10.00 | | 20006 | 2005-09-12 00:00:00 | 10003 | 20006 | 1 | JP2000 | 1 | 55.00 | | 20007 | 2005-09-30 00:00:00 | 10004 | 20007 | 1 | TNT2 | 100 | 10.00 | | 20008 | 2005-10-03 00:00:00 | 10005 | 20008 | 1 | FC | 50 | 2.50 | | 20009 | 2005-10-08 00:00:00 | 10001 | 20009 | 1 | FB | 1 | 10.00 | | 20009 | 2005-10-08 00:00:00 | 10001 | 20009 | 2 | OL1 | 1 | 8.99 | | 20009 | 2005-10-08 00:00:00 | 10001 | 20009 | 3 | SLING | 1 | 4.49 | | 20009 | 2005-10-08 00:00:00 | 10001 | 20009 | 4 | ANV03 | 1 | 14.99 | +-----------+---------------------+---------+-----------+------------+---------+----------+------------+ 11 rows in set (0.00 sec)
9.2.3 外部联结
-
外联结包括左联结和右联结,必须使用
ON提供联结条件。外部联结是为了弥补内部联结的不足,内部联结只能将存在联结的项列出来,但是对于不存在联结的项没有列出,而外部联结是将指定的表的所有项都列出,不管是否能在另一个表中查到(联结成功)。 -
语法:
FROM customers LEFT OUTER JOIN products ON...
FROM customers RIGHT OUTER JOIN products ON... -
说明:其中的
LEFT或者RIGHT是指定联结的哪个表中的项要完整输出。 -
示例:统计所有每个顾客的订单数量。
- 内部连接:不能将所有的顾客列出来
mysql> SELECT customers.cust_name, customers.cust_id, COUNT(orders.order_num) -> FROM customers INNER JOIN orders -> ON customers.cust_id=orders.cust_id -> GROUP BY customers.cust_id; +----------------+---------+-------------------------+ | cust_name | cust_id | COUNT(orders.order_num) | +----------------+---------+-------------------------+ | Coyote Inc. | 10001 | 2 | | Wascals | 10003 | 1 | | Yosemite Place | 10004 | 1 | | E Fudd | 10005 | 1 | +----------------+---------+-------------------------+ 4 rows in set (0.00 sec)- 外部联结:将customers表中的所有顾客列出来
mysql> SELECT customers.cust_name, customers.cust_id, COUNT(orders.order_num) -> FROM customers LEFT OUTER JOIN orders -> ON customers.cust_id=orders.cust_id -> GROUP BY customers.cust_id; +----------------+---------+-------------------------+ | cust_name | cust_id | COUNT(orders.order_num) | +----------------+---------+-------------------------+ | Coyote Inc. | 10001 | 2 | | Mouse House | 10002 | 0 | | Wascals | 10003 | 1 | | Yosemite Place | 10004 | 1 | | E Fudd | 10005 | 1 | +----------------+---------+-------------------------+ 5 rows in set (0.00 sec) -
注意:
GROUP BY的用途mysql> SELECT COUNT(customers.cust_id) -> FROM customers; +--------------------------+ | COUNT(customers.cust_id) | +--------------------------+ | 5 | +--------------------------+ 1 row in set (0.01 sec)在外联结学习的时候,使用了聚合计算
COUNT(),COUNT()作用到整张表上输出为一个值,因为整张表是一个组,因此如果SELECT需要列出多列,那需要先进行GROUP BY分组,而后COUNT()对所有的组内进行聚合计算。而在使用分组时,SELECT列出的所有项都要出现在GROUP BY中,分组是要对重复信息的合并,列出但是没有出现在GROUP BY中,进行合并时没有办法处理这部分信息。
10 组合查询
-
组合查询是将多个查询的结果汇总起来输出,比如自动化1-6班每个班提交一个表,而后对此表进行汇总,最后提交给辅导员。组合查询是将所有的查询组合在一块输出。
-
语法:可组合多个查询,中间使用
UNION组合即可。但是如果要排序只能在最后一个组合的后边添加ORDER BY。SELECT ... FROm ... WHERE .. UNION #!!! SELECT ... FROM ... WHERE ... ORDER BY... #!!! -
注意:
-
因为是将输出组合,因此就要求每个查询输出的
形式要相同,保证能够组合起来。因此通常组合的情况有:-
在单个查询中,从不同的表返回类似结构的数据;
-
多个查询中,从单个表中返回数据。
在单个查询中,从不同的表返回类似结构的数据时,并不要求返回的列名是一致的,其表达的内容是一致就可以(结构、类型)。如果内容不一致,组合在一起没有意义。如下:
select posts_id,posts_name,posts_status from yy_posts UNION select user_id,user_nickname,user_status from yy_user
-
-
使用
UNION时,必须有两个或两个以上的SELECT语句组成,UNION中的每个查询必须包含相同的列、表达式或聚集函数,列数据类型需要兼容。 -
UNION从查询结果集中自动去除了重复的行,其行为与WHERE相同。如果需要列出所有的,使用UNION ALL即可,WHERE是无法完成列出所有行的操作的。 -
如果对组合的结果进行排序,只能使用一条
ORDER BY子句,出现在最后一个SELECT中。
-
-
示例:输出价格小于等于5商品,同时也包含供应商1001、1002的所有商品
- 使用
WHERE多个限定子句
mysql> SELECT vend_id, prod_id, prod_price -> FROM products -> WHERE prod_price <=5 -> OR vend_id IN (1001, 1002); +---------+---------+------------+ | vend_id | prod_id | prod_price | +---------+---------+------------+ | 1001 | ANV01 | 5.99 | | 1001 | ANV02 | 9.99 | | 1001 | ANV03 | 14.99 | | 1003 | FC | 2.50 | | 1002 | FU1 | 3.42 | | 1002 | OL1 | 8.99 | | 1003 | SLING | 4.49 | | 1003 | TNT1 | 2.50 | +---------+---------+------------+ 8 rows in set (0.00 sec)-
使用
UNIONmysql> SELECT vend_id, prod_id, prod_price -> FROM products -> WHERE prod_price<=5 -> UNION -> SELECT vend_id, prod_id, prod_price -> FROm products -> WHERE vend_id IN (1001, 1002); +---------+---------+------------+ | vend_id | prod_id | prod_price | +---------+---------+------------+ | 1003 | FC | 2.50 | | 1002 | FU1 | 3.42 | | 1003 | SLING | 4.49 | | 1003 | TNT1 | 2.50 | | 1001 | ANV01 | 5.99 | | 1001 | ANV02 | 9.99 | | 1001 | ANV03 | 14.99 | | 1002 | OL1 | 8.99 | +---------+---------+------------+ 8 rows in set (0.00 sec) -
使用
UNION ALLmysql> SELECT vend_id, prod_id, prod_price -> FROM products -> WHERE prod_price<=5 -> UNION ALL -> SELECT vend_id, prod_id, prod_price -> FROM products -> WHERE vend_id IN (1001, 1002); +---------+---------+------------+ | vend_id | prod_id | prod_price | +---------+---------+------------+ | 1003 | FC | 2.50 | | 1002 | FU1 | 3.42 | | 1003 | SLING | 4.49 | | 1003 | TNT1 | 2.50 | | 1001 | ANV01 | 5.99 | | 1001 | ANV02 | 9.99 | | 1001 | ANV03 | 14.99 | | 1002 | FU1 | 3.42 | | 1002 | OL1 | 8.99 | +---------+---------+------------+ 9 rows in set (0.00 sec) -
使用
ORDER BYmysql> SELECT vend_id, prod_id, prod_price -> FROM products -> WHERE prod_price<=5 -> UNION -> SELECT vend_id, prod_id,prod_price -> FROM products -> WHERE vend_id IN (1001, 1002) -> ORDER BY prod_price; +---------+---------+------------+ | vend_id | prod_id | prod_price | +---------+---------+------------+ | 1003 | FC | 2.50 | | 1003 | TNT1 | 2.50 | | 1002 | FU1 | 3.42 | | 1003 | SLING | 4.49 | | 1001 | ANV01 | 5.99 | | 1002 | OL1 | 8.99 | | 1001 | ANV02 | 9.99 | | 1001 | ANV03 | 14.99 | +---------+---------+------------+ 8 rows in set (0.00 sec)
- 使用
11 表的操作
MySQL中有很多引擎,用于管理和处理数据,在创建表的时候要指出使用哪个引擎,这些引擎通过打包隐藏在MySQL服务器内,都可以执行创建表CREATE TABLE以及查询SELECT等命令。多种引擎适应不同的情况,因此在使用前需要根据情况选择对应的引擎来创建表。
常用的几个引擎是InnoDB MEMORY MyISAM.
11.1 创建表
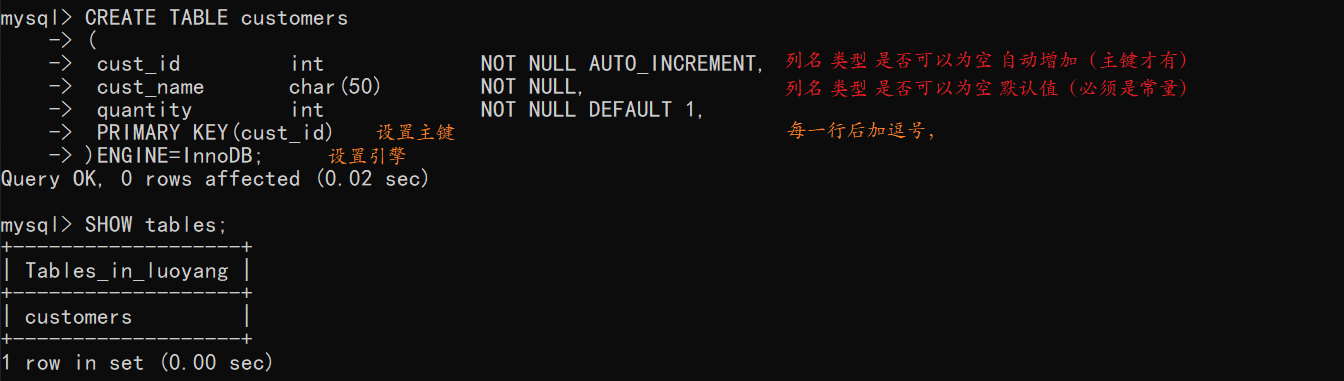
-
语法:
每一行中:
列名 类型 是否为空 默认值/自动增长- 是否为空设置为
NULL或者NOT NULL,如果为NOT NULL,那么插入INSERT值时必须给此列一个值,否则返回错误。 - 默认值:
DEFAULt 1,设置的默认值只支持常量。 - 自动增长:
AUTO_INCREMENT用在主键行后,告诉MySQL本列每增加一行时自动增量。每次执行一个INSERT时,MySQL自动对该列增量,给该列赋予下一个可用的值。当然,也可以在INSERT时给主键指定一个尚未使用的唯一的值来覆盖AUTO_INCREMENT。后续增量从这个值开始。AUTO_INCREMENT中间有下划线的,错了好几次。 - 获取自动增加的主键值:有时候需要根据插入此表的自动生成的主键值来对另一个关联的表进行更改,需要获取刚刚插入的行的主键值,可以使用
last_insert_id()函数。SELECT last_insert_id(),而后此子句可用于其他的语句中。
主键:
- 主键可以使用单个列,其值必须唯一:
PRIMARY KEY (cust_id) - 主键也可以使用多列,这些列的组合唯一即可:
PRIMARY KEY (order_num, order_item) - 主键中只能使用不允许NULL值的列。
引擎:设置引擎可以为
InnoDBMEMORYMyISAM,需要按照需求来设定。外键不能跨引擎。- InnoDB:支持事务处理,不支持全文本搜索(默认),性能不高
- MyISAM:支持全文本搜索,不支持事务处理,性能很高
- MEMORY:功能等同MyISAM,但是数据存储在内存中,速度快(用于创建临时表)
- 是否为空设置为
-
示例:
mysql> CREATE TABLE customers -> ( -> cust_id int NOT NULL AUTO_INCREMENT, -> cust_name char(50) NOT NULL, -> quantity int NOT NULL DEFAULT 1, -> PRIMARY KEY(cust_id) -> )ENGINE=InnoDB; Query OK, 0 rows affected (0.02 sec) mysql> CREATE TABLE orders -> ( -> order_num int NOT NULL AUTO_INCREMENT, -> order_date datetime NOT NULL, -> cust_id int NOT NULL, -> PRIMARY KEY(order_num) -> )ENGINE=InnoDB; Query OK, 0 rows affected (0.02 sec) mysql> SHOW tables; +-------------------+ | Tables_in_luoyang | +-------------------+ | customers | | orders | +-------------------+ 2 rows in set (0.00 sec)
11.2 外键的使用
-
什么是外键?
一张表中有一个非主键的字段指向了另一张表中的主键,该非主键字段称为外键。主要作用就是相互关联。
-
如何创建外键?
创建外键首先需要创建两个表,如上述代码中的
customers和orders两张表。orders中希望引用customers中的主键cust_id,就需要在orders表中先创建cust_id列。而后创建外键,使得从表引用主表。从表是指外键所在的表,主表是指被引用的表。因此总结,先创建对应的列,然后设置此列为外键并与其他表的主键相关联。mysql> ALTER TABLE orders -> ADD CONSTRAINT fk_orders_cstomers FOREIGN KEY(cust_id) -> REFERENCES customers(cust_id); Query OK, 0 rows affected (0.07 sec) Records: 0 Duplicates: 0 Warnings: 0ALTER TABLE ...改变表ordersADD CONSTRAINT fk_orders_customers FOREIGN KEY(cust_id),fk_orders_customers是外键名字,此句是添加约束,名为fk_orders_customers的外键FOREIGN KEY(cust_id)REFERENCES customers(cust_id)此处的REFERENCES是单数,意思是上面的外键引用customers的cust_id主键。ALTER TABLE是修改表,常用于创建外键。
-
外键的作用:
外键是对其他表中项的索引,项是指一行信息。因此外键中的值可以重复,也就是外键中的多个值可以对应其他表中的一个值。
-
当主表主动修改或者删除某项时,必须保证在从表中没有引用此项,否则不能删除;
-
当从表主动插入或者修改某项时,必须保证从表中外键的值来自于主表,否则不能添加。
(如果主表修改连带从表修改,或者主表删除连带从表删除,需要特殊设定。)

# 创建数据库 CREATE DATABASE Test; USE TEMP; # 创建表 CREATE TABLE student(id int (11) primary key auto_increment,name char(255),sex char(255),age int(11))charset utf8; CREATE TABLE student_score(id int (11) primary key auto_increment,class char(255),score char(255),student_id int(11))charset utf8; Alter table student_score add constraint s_id foreign key(student_id) references student(id); # 插入学生信息 INSERT INTO student(name,sex,age) VALUES('学生1','男','12'); # 插入学科及分数信息 INSERT INTO student_score(class,score,student_id) VALUES('语文','100',1); INSERT INTO student_score(class,score,student_id) VALUES('数学','100',1); INSERT INTO student_score(class,score,student_id) VALUES('英语','100',1); #删除外键 alter table student_score drop foreign key s_id; #加入CASCADE约束外键 Alter table student_score add constraint s_id foreign key(student_id) references student(id) ON DELETE CASCADE ON UPDATE CASCADE; -
11.3 删除表
DROP TABLE customers;
11.4 重命名表
mysql> RENAME TABLE customers TO customers22;
Query OK, 0 rows affected (0.03 sec)
11.5 插入数据
- 语法
INSERT INTO customers# 表名
(cust_id,
cust_name,
...
)
VALUES(
1,
'zhx',
...
)
-
说明:
-
前后要一一对应起来,这样可以避免表的结构的变化带来的影响。
-
对于设置了自动增加的主键,其VALUES可设置为
NULL,或者在前面不出现主键名。 -
使用此种语法可以只给某些列提供值,而给其他列不提供值,如果省略,该列必须是允许控制或者给定了默认值。
-
-
插入一行
mysql> INSERT INTO customers(
-> cust_id,#PRIMARY KEY
-> cust_name,
-> quantity)
-> VALUES(1,
-> 'zhx',
-> 2);
Query OK, 1 row affected (0.01 sec)
mysql> SELECT * FROM customers;
+---------+-----------+----------+
| cust_id | cust_name | quantity |
+---------+-----------+----------+
| 1 | zhx | 2 |
+---------+-----------+----------+
1 row in set (0.00 sec)
mysql> INSERT INTO customers(
-> cust_name,#将主键去掉了,因为自动增加
-> quantity)
-> VALUES(
-> 'jhj',
-> 3);
Query OK, 1 row affected (0.01 sec)
mysql> SELECT * FROM customers;
+---------+-----------+----------+
| cust_id | cust_name | quantity |
+---------+-----------+----------+
| 1 | zhx | 2 |
| 2 | jhj | 3 |
+---------+-----------+----------+
2 rows in set (0.00 sec)
INSERT 操作可能很耗时,可能减低等待处理的SELECT语句性能,如果数据检索较为重要,那么可以降低插入语句的优先级。具体使用方法是:
INSERT LOW_PRIMARY INTO
-
插入多行
mysql> INSERT INTO customers( -> cust_name, -> quantity) -> VALUES( -> 'sdc', -> 90),#注意此处有逗号,是并列关系 -> ('skd', -> 23); Query OK, 2 rows affected (0.01 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> SELECT * FROM customers; +---------+-----------+----------+ | cust_id | cust_name | quantity | +---------+-----------+----------+ | 1 | zhx | 2 | | 2 | jhj | 3 | | 3 | oio | 99 | | 4 | sdc | 90 | | 5 | skd | 23 | +---------+-----------+----------+ 5 rows in set (0.00 sec) -
INSERT SELECT
目的是将SELECT语句输出的结果插入INSERT表中。
-
新建一张表:
mysql> CREATE TABLE customers2( -> cust_id int NOT NULL AUTO_INCREMENT, -> cust_name char(50) NOT NULL, -> quantity int NOT NULL, -> PRIMARY KEY(cust_id) -> )ENGINE=InnoDB; Query OK, 0 rows affected (0.03 sec) -
插入数据
mysql> INSERT INTO customers2( -> cust_name, -> quantity) -> VALUES -> ('ppp',22), -> ('kkk',34), -> ('eee',32); Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> SELECT * FROM customers2; +---------+-----------+----------+ | cust_id | cust_name | quantity | +---------+-----------+----------+ | 1 | ppp | 22 | | 2 | kkk | 34 | | 3 | eee | 32 | +---------+-----------+----------+ 3 rows in set (0.00 sec) -
将从
customers2中的SELECT选出的数据导入到customers中注意:其中没有VALUES关键字,同时SELECT选出的列要与插入的内容相同,列名可以不同,对应位置相对应即可,对于主键可以不列出,直接使用自动增加。
mysql> INSERT INTO customers( -> cust_name, -> quantity) -> SELECT cust_name, -> quantity -> FROM customers2 -> WHERE quantity>=30; Query OK, 2 rows affected (0.01 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> SELECT * FROM customers; +---------+-----------+----------+ | cust_id | cust_name | quantity | +---------+-----------+----------+ | 1 | zhx | 2 | | 2 | jhj | 3 | | 3 | oio | 99 | | 4 | sdc | 90 | | 5 | skd | 23 | | 6 | kkk | 34 | | 7 | eee | 32 | +---------+-----------+----------+ 7 rows in set (0.00 sec)
-
11.6 更新和删除数据
原则:
- 仔细检查是否使用WHERE,不使用WHERE时是对整列的数据进行的修改,并且是不可更改的。
- 在进行UPDATE或者DELETE时先使用SELECT进行输出,查看选择的是否正确。
- 如果某表通过外键引用其他的表主键,不允许删除此表中与其他表相关联的数据项。
-
更新数据:对WHERE选择的行的列进行重新设置(修改)
-
语法:设置需要修改的列的值
UPDATE customers#表名 SET quantity=100 #设置某一列的值为100 WHERE cust_name='kk'#选定需要修改的列-
向customers2中添加信息
mysql> INSERT INTO customers2( -> cust_name, -> quantity) -> VALUES -> ('eee',20), -> ('kkk',30); Query OK, 2 rows affected (0.01 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> SELECT * FROM customers2; +---------+-----------+----------+ | cust_id | cust_name | quantity | +---------+-----------+----------+ | 1 | ppp | 22 | | 2 | kkk | 34 | | 3 | eee | 32 | | 4 | eee | 20 | | 5 | kkk | 30 | +---------+-----------+----------+ 5 rows in set (0.00 sec) -
更新顾客eee的商品数量为100
mysql> UPDATE customers2 -> SET quantity=100 -> WHERE cust_name='eee'; Query OK, 2 rows affected (0.01 sec) Rows matched: 2 Changed: 2 Warnings: 0 mysql> SELECT * FROM customers2; +---------+-----------+----------+ | cust_id | cust_name | quantity | +---------+-----------+----------+ | 1 | ppp | 22 | | 2 | kkk | 34 | | 3 | eee | 100 | | 4 | eee | 100 | | 5 | kkk | 30 | +---------+-----------+----------+ 5 rows in set (0.00 sec)
-
-
-
删除数据:只是删除选中的行,而不是列,如果没有WHERE选中,那么就是所有列的数据,但是其只是删除的数据而不是表。
-
语法:
DELETE FROM customers #表名 WHERE cust_name='kkkkk'; -
示例:
mysql> DELETE FROM customers2 -> WHERE cust_name='kkk'; Query OK, 2 rows affected (0.01 sec) mysql> SELECT * FROM customers2; +---------+-----------+----------+ | cust_id | cust_name | quantity | +---------+-----------+----------+ | 1 | ppp | 22 | | 3 | eee | 100 | | 4 | eee | 100 | +---------+-----------+----------+ 3 rows in set (0.00 sec) -
注意:
-
DELETE只适合与删除整行,如果只是删除个别列,还是要使用UPDATE将此列SET=NULL即可。要求此行必须能够设置为NULL。
-
如果是删除整个表的内容,使用DELETE是逐行删除,占用时间较长,可以使用TRUNCATE TABLE语句
mysql> SELECT * FROM customers2; +---------+-----------+----------+ | cust_id | cust_name | quantity | +---------+-----------+----------+ | 1 | ppp | 22 | | 3 | eee | 100 | | 4 | eee | 100 | +---------+-----------+----------+ 3 rows in set (0.00 sec) mysql> TRUNCATE customers2; Query OK, 0 rows affected (0.03 sec) mysql> SELECT * FROM customers2; Empty set (0.00 sec) -
-
12数据库、表以及数据的增删改查操作DML
数据库
| 操作 | 数据库 |
|---|---|
| 增 | CREATE DATABASE IF NOT EXISTS teacher CHARSET=UTF8 ; |
| 删 | DROP DATABASE IF EXISTS teacher; |
| 改 | ALTER DATABASE teacher CHARSET=GBK; |
| 查 | SHOW DATABASES; SHOW CREATE DATABASE teacher; SELECT DATABASE();//查看当前数据库 |
| 用 | USE teacher; |
- 增:可设置数据库的编码方式,有UTF8(通用字符编码)、GBK(简体中文)、GB2312(简体中文)
- 改:只能修改编码
- 查:前者显示所有数据库,后者显示创建数据库的语句
表
| 操作 | 表 |
|---|---|
| 增 | CREATE TABLE IF NOT EXISTS stu(3+4)engine=InnoDB; |
| 删 | DROP TABLE IF EXISTS stu; |
| 改(添加字段) | ALTER TABLE stu ADD age INT; |
| 改(删除字段) | ALTER TABLE stu DROP email; |
| 改(修改字段) | ALTER TABLE stu CHANGE sex xingbie INT; |
| 改(修改类型) | ALTER TABLE stu MODIFY xingbie VARCHAR(20); |
| 改(修改引擎) | ALTER TABLE teacher ENGINE=MYSIAM; |
| 改(修改表名) | ALTER TABLE teacher RENAME TO stu; |
| 查 | DESC stu; SHOW CREATE TABLE stu\G; SHOW TABLES FROM 其他数据库名; |
-
增:
3+4表名:
字段名称 类型 [NULL/NOT NULL] [AUTO_INCREMENT] [PRIMARY KEY] [COMMENT] [DEFULT]
name varchar(20) NOT NULL AUTO_INCREMENT PRIMARY KEY COMMENT '主键' DEFAULT ‘姓名不详’;
-
改(添加字段):
下面两个关键字分别表示在第一个位置添加字段、在某个字段后添加字段
FIRST:
ALTER TABLE stu ADD age INT FIRST;AFTER:
ALTER TABLE stu ADD age INT AFTER name; -
改(修改**):
CHANGE:将原字段变为新字段(字段名以及类型)
MODIFY:只修改类型
ENGINE:InnoDB、MyISAM、MEMORY
-
查:
\G表明是按照习惯阅读方式展示;
通过FROM可以在不更换数据库的情况下查看其他数据库的表有哪些。
-
注意:
当表中含有中文时,先执行
set names gbk;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通