spring实现数据库读写分离
现在大型的电子商务系统,在数据库层面大都采用读写分离技术,就是一个Master数据库,多个Slave数据库。Master库负责数据更新和实时数据查询,Slave库当然负责非实时数据查询。因为在实际的应用中,数据库都是读多写少(读取数据的频率高,更新数据的频率相对较少),而读取数据通常耗时比较长,占用数据库服务器的CPU较多,从而影响用户体验。我们通常的做法就是把查询从主库中抽取出来,采用多个从库,使用负载均衡,减轻每个从库的查询压力。
采用读写分离技术的目标:有效减轻Master库的压力,又可以把用户查询数据的请求分发到不同的Slave库,从而保证系统的健壮性。我们看下采用读写分离的背景。
随着网站的业务不断扩展,数据不断增加,用户越来越多,数据库的压力也就越来越大,采用传统的方式,比如:数据库或者SQL的优化基本已达不到要求,这个时候可以采用读写分离的策 略来改变现状。
具体到开发中,如何方便的实现读写分离呢?目前常用的有两种方式:
1 第一种方式是我们最常用的方式,就是定义2个数据库连接,一个是MasterDataSource,另一个是SlaveDataSource。更新数据时我们读取MasterDataSource,查询数据时我们读取SlaveDataSource。这种方式很简单,我就不赘述了。
2 第二种方式动态数据源切换,就是在程序运行时,把数据源动态织入到程序中,从而选择读取主库还是从库。主要使用的技术是:annotation,Spring AOP ,反射。下面会详细的介绍实现方式。
在介绍实现方式之前,我们先准备一些必要的知识,spring 的AbstractRoutingDataSource 类
AbstractRoutingDataSource这个类 是spring2.0以后增加的,我们先来看下AbstractRoutingDataSource的定义:
public abstract class AbstractRoutingDataSource extends AbstractDataSource implements InitializingBean {}
AbstractRoutingDataSource继承了AbstractDataSource ,而AbstractDataSource 又是DataSource 的子类。DataSource 是javax.sql 的数据源接口,定义如下:
 View Code
View Code DataSource 接口定义了2个方法,都是获取数据库连接。我们在看下AbstractRoutingDataSource 如何实现了DataSource接口:


public Connection getConnection() throws SQLException { return determineTargetDataSource().getConnection(); } public Connection getConnection(String username, String password) throws SQLException { return determineTargetDataSource().getConnection(username, password); }
很显然就是调用自己的determineTargetDataSource() 方法获取到connection。determineTargetDataSource方法定义如下:
protected DataSource determineTargetDataSource() { Assert.notNull(this.resolvedDataSources, "DataSource router not initialized"); Object lookupKey = determineCurrentLookupKey(); DataSource dataSource = this.resolvedDataSources.get(lookupKey); if (dataSource == null && (this.lenientFallback || lookupKey == null)) { dataSource = this.resolvedDefaultDataSource; } if (dataSource == null) { throw new IllegalStateException("Cannot determine target DataSource for lookup key [" + lookupKey + "]"); } return dataSource; }
我们最关心的还是下面2句话:
Object lookupKey = determineCurrentLookupKey();
DataSource dataSource = this.resolvedDataSources.get(lookupKey);
determineCurrentLookupKey方法返回lookupKey,resolvedDataSources方法就是根据lookupKey从Map中获得数据源。resolvedDataSources 和determineCurrentLookupKey定义如下:
private Map<Object, DataSource> resolvedDataSources;
protected abstract Object determineCurrentLookupKey()
看到以上定义,我们是不是有点思路了,resolvedDataSources是Map类型,我们可以把MasterDataSource和SlaveDataSource存到Map中,如下:
key value
master MasterDataSource
slave SlaveDataSource
我们在写一个类DynamicDataSource 继承AbstractRoutingDataSource,实现其determineCurrentLookupKey() 方法,该方法返回Map的key,master或slave。
好了,说了这么多,有点烦了,下面我们看下怎么实现。
上面已经提到了我们要使用的技术,我们先看下annotation的定义:
@Retention(RetentionPolicy.RUNTIME) @Target(ElementType.METHOD) public @interface DataSource { String value(); }
我们还需要实现spring的抽象类AbstractRoutingDataSource,就是实现determineCurrentLookupKey方法:
public class DynamicDataSource extends AbstractRoutingDataSource { @Override protected Object determineCurrentLookupKey() { // TODO Auto-generated method stub return DynamicDataSourceHolder.getDataSouce(); } } public class DynamicDataSourceHolder { public static final ThreadLocal<String> holder = new ThreadLocal<String>(); public static void putDataSource(String name) { holder.set(name); } public static String getDataSouce() { return holder.get(); } }
从DynamicDataSource 的定义看出,他返回的是DynamicDataSourceHolder.getDataSouce()值,我们需要在程序运行时调用DynamicDataSourceHolder.putDataSource()方法,对其赋值。下面是我们实现的核心部分,也就是AOP部分,DataSourceAspect定义如下:
public class DataSourceAspect { public void before(JoinPoint point) { Object target = point.getTarget(); String method = point.getSignature().getName(); Class<?>[] classz = target.getClass().getInterfaces(); Class<?>[] parameterTypes = ((MethodSignature) point.getSignature()) .getMethod().getParameterTypes(); try { Method m = classz[0].getMethod(method, parameterTypes); if (m != null && m.isAnnotationPresent(DataSource.class)) { DataSource data = m .getAnnotation(DataSource.class); DynamicDataSourceHolder.putDataSource(data.value()); System.out.println(data.value()); } } catch (Exception e) { // TODO: handle exception } } }
为了方便测试,我定义了2个数据库,shop模拟Master库,test模拟Slave库,shop和test的表结构一致,但数据不同,数据库配置如下:
<bean id="masterdataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource"> <property name="driverClassName" value="com.mysql.jdbc.Driver" /> <property name="url" value="jdbc:mysql://127.0.0.1:3306/shop" /> <property name="username" value="root" /> <property name="password" value="yangyanping0615" /> </bean> <bean id="slavedataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource"> <property name="driverClassName" value="com.mysql.jdbc.Driver" /> <property name="url" value="jdbc:mysql://127.0.0.1:3306/test" /> <property name="username" value="root" /> <property name="password" value="yangyanping0615" /> </bean> <beans:bean id="dataSource" class="com.air.shop.common.db.DynamicDataSource"> <property name="targetDataSources"> <map key-type="java.lang.String"> <!-- write --> <entry key="master" value-ref="masterdataSource"/> <!-- read --> <entry key="slave" value-ref="slavedataSource"/> </map> </property> <property name="defaultTargetDataSource" ref="masterdataSource"/> </beans:bean> <bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource" ref="dataSource" /> </bean> <!-- 配置SqlSessionFactoryBean --> <bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"> <property name="dataSource" ref="dataSource" /> <property name="configLocation" value="classpath:config/mybatis-config.xml" /> </bean>
在spring的配置中增加aop配置
<!-- 配置数据库注解aop -->
<aop:aspectj-autoproxy></aop:aspectj-autoproxy>
<beans:bean id="manyDataSourceAspect" class="com.air.shop.proxy.DataSourceAspect" />
<aop:config>
<aop:aspect id="c" ref="manyDataSourceAspect">
<aop:pointcut id="tx" expression="execution(* com.air.shop.mapper.*.*(..))"/>
<aop:before pointcut-ref="tx" method="before"/>
</aop:aspect>
</aop:config>
<!-- 配置数据库注解aop -->
下面是MyBatis的UserMapper的定义,为了方便测试,登录读取的是Master库,用户列表读取Slave库:
public interface UserMapper { @DataSource("master") public void add(User user); @DataSource("master") public void update(User user); @DataSource("master") public void delete(int id); @DataSource("slave") public User loadbyid(int id); @DataSource("master") public User loadbyname(String name); @DataSource("slave") public List<User> list(); }
好了,运行我们的Eclipse看看效果,输入用户名admin 登录看看效果
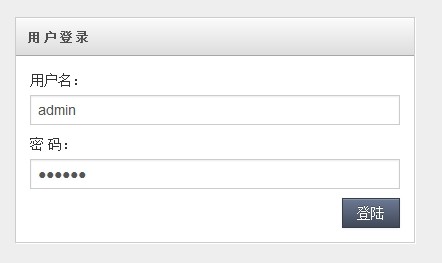
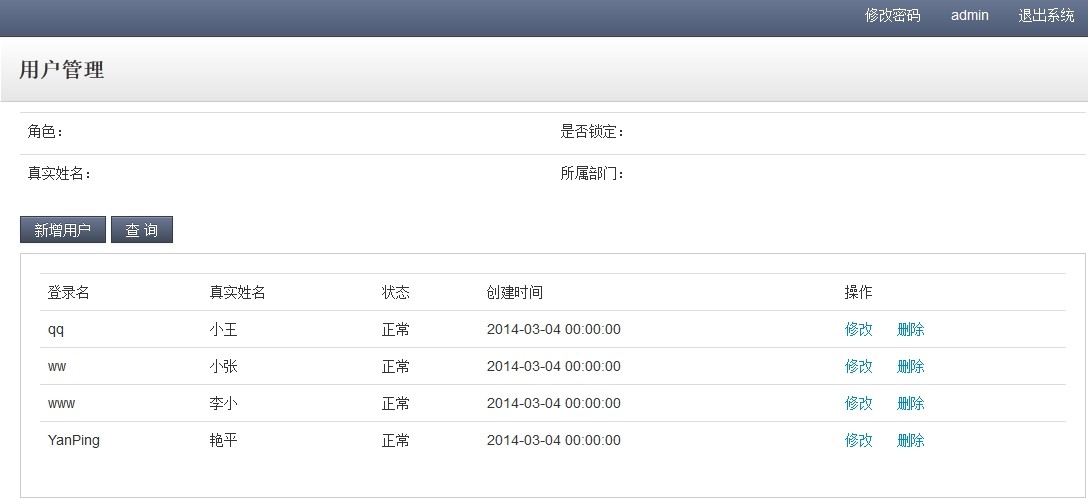
从图中可以看出,登录的用户和用户列表的数据是不同的,也验证了我们的实现,登录读取Master库,用户列表读取Slave库。
感谢阅读,希望这篇文章能给你带来帮助!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号