Python自动化之sqlalchemy
如果该数 据库支持 自增列 ,则 SQLAlchemy 默认 自动 设定 表中第一个 类型 为整形 的主键 为自增列
ORM介绍
orm英文全称object relational mapping,就是对象映射关系程序,简单来说我们类似python这种面向对象的程序来说一切皆对象,但是我们使用的数据库却都是关系型的,为了保证一致的使用习惯,通过orm将编程语言的对象模型和数据库的关系模型建立映射关系,这样我们在使用编程语言对数据库进行操作的时候可以直接使用编程语言的对象模型进行操作就可以了,而不用直接使用sql语言。

orm的优点:
隐藏了数据访问细节,“封闭”的通用数据库交互,ORM的核心。他使得我们的通用数据库交互变得简单易行,并且完全不用考虑该死的SQL语句。快速开发,由此而来。
ORM使我们构造固化数据结构变得简单易行。
缺点:
无可避免的,自动化意味着映射和关联管理,代价是牺牲性能(早期,这是所有不喜欢ORM人的共同点)。现在的各种ORM框架都在尝试使用各种方法来减轻这块(LazyLoad,Cache),效果还是很显著的。
sqlalchemy安装
在Python中,最有名的ORM框架是SQLAlchemy。用户包括openstack\Dropbox等知名公司或应用,主要用户列表http://www.sqlalchemy.org/organizations.html#openstack
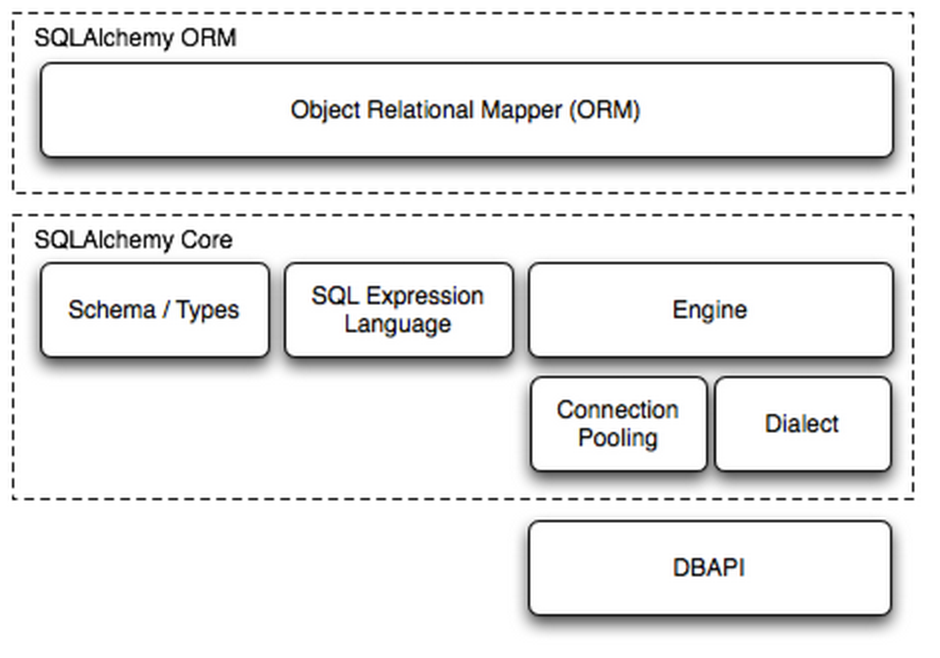
Engine使用Schema Type创建一个特定的结构对象,之后通过SQL Expression Language将该对象转换成SQL语句,然后通过 ConnectionPooling 连接数据库,再然后通过 Dialect 执行SQL,并获取结果。
MySQL-Python连接
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>
- MySQL:数据库名称
- MySQLdb:数据库驱动名称
安装sqlalchemy
- pip install SQLAlchemy
- pip install pymysql
sqlalchemy基本使用
CREATE TABLE user (
id INTEGER NOT NULL AUTO_INCREMENT,
name VARCHAR(32),
password VARCHAR(64),
PRIMARY KEY (id)
)
ORM简单使用
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
#创建数据库连接,但是此时并没有去连接数据库,而是第一次执行sql的时候才会连接
engine = create_engine("mysql+pymysql://root:alex3714@localhost/testdb",
encoding='utf-8', echo=True)
Base = declarative_base() #生成orm基类
class User(Base):
__tablename__ = 'user' #表名
id = Column(Integer, primary_key=True)
name = Column(String(32))
password = Column(String(64))
Base.metadata.create_all(engine) #创建表结构
另一种创建表的方式(貌似使用的人不多)
from sqlalchemy import Table, MetaData, Column, Integer, String, ForeignKey
from sqlalchemy.orm import mapper
metadata = MetaData()
user = Table('user', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(50)),
Column('fullname', String(50)),
Column('password', String(12))
)
class User(object):
def __init__(self, name, fullname, password):
self.name = name
self.fullname = fullname
self.password = password
mapper(User, user) #the table metadata is created separately with the Table construct, then associated with the User class via the mapper() function
mapper(User,user)为什么没有id呢,因为如果该数 据库支持 自增列,则SQLAlchemy默认自动设定表中第一个类型为整形的主键为自增列。
Session_class = sessionmaker(bind=engine) #创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例
Session = Session_class() #生成session实例
user_obj = User(name="alex",password="alex3714") #生成你要创建的数据对象
#此时还没创建对象呢,不信你打印一下id发现还是None
Session.add(user_obj) #把要创建的数据对象添加到这个session里, 一会统一创建
#此时也依然还没创建
Session.commit() #现此才统一提交,创建数据
查询
my_user = Session.query(User).filter_by(name="alex").first()
print(my_user)
结果
<main.User object at 0x105b4ba90>返回的数据映射成一个对象了
取出数据
print(my_user.id,my_user.name,my_user.password)
输出
1 alex alex3714
变成可读
def __repr__(self):
return "<User(name='%s', password='%s')>" % (
self.name, self.password)
当print的时候会调用__repr__,而实际上是调用的 __str__,内部会把__str__ = __repr__

 浙公网安备 33010602011771号
浙公网安备 33010602011771号