
一、 What is Machine Learning?
提供了两种定义
-
Arthur Samuel 定义的比较随意,也是老一点的版本:
"the field of study that gives computers the ability to learn without being explicitly programmed."(使计算机能够在没有明确编程的情况下学习的研究领域) -
Tom Mitchell提供了一个比较新的定义:
"A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E."(一个计算机程序,从经验E中学习关于某一类任务T和性能度量P的知识,如果它在T中的性能,如P所度量的那样,随着经验E的提高而提高。)
Example: playing checkers. 例如:下棋
E = the experience of playing many games of checkers E=下了很多棋的经验
T = the task of playing checkers. T=下棋的任务
P = the probability that the program will win the next game. P=程序能够赢下一盘棋的可能性
二、机器学习主要类型——监督学习、无监督学习
一般来说,任何机器学习问题都可以分为两大类:监督学习和无监督学习。
(一)监督学习(Supervised Learning)
1. 定义
术语监督学习,意指给出一个算法, 需要部分数据集已经有正确答案:比如给定房价数据集, 对于里面每个数据,算法都知道对应的正确房价, 即这房子实际卖出的价格,然后基于已有数据,对房子价格进行预测。
用更术语的方式来定义:回归问题属于监督中的一种,意指要预测一个连续值的输出,比如房价;分类问题指预测一个离散值的输出。
2. 解释
在分类问题中,有时会有超过两个的值, 输出的值可能超过两种。
举个具体例子, 胸部肿瘤可能有三种类型,所以要预测离散值0,1,2,3 0就是良性肿瘤,没有癌症。 1 表示1号癌症,假设总共有三种癌症。 2 是2号癌症,3 就是3号癌症。 这同样是个分类问题,因为它的输出的离散值集合 分别对应于无癌,1号,2号,3号癌症 。这里只使用了一个特征属性,即肿瘤块大小, 来预测肿瘤是恶性良性。在其它机器学习问题里, 有着不只一个的特征和属性。
那么,你如何处理 无限多特征呢?甚至你如何存储无数的东西 进电脑里,又要避免内存不足? 事实上,等我们介绍一种叫支持向量机(SVM)的算法时, 就知道存在一个简洁的数学方法,能让电脑处理无限多的特征。
3. 总结
监督学习基本思想是:监督学习中,对于数据集中的每个数据, 都有相应的正确答案,(训练集) 算法就是基于这些来做出预测。就像那个房价, 或肿瘤的性质。
回归问题,即通过回归来预测一个连续值输出。
分类问题, 目标是预测离散值输出。
4.例(自测)
下面是个小测验题目:
假设你有家公司,希望研究相应的学习算法去 解决两个问题。第一个问题,你有一堆货物的清单。 假设一些货物有几千件可卖, 你想预测出,你能在未来三个月卖出多少货物。 第二个问题,你有很多用户, 你打算写程序来检查每个用户的帐目。 对每个用户的帐目, 判断这个帐目是否被黑过(hacked or compromised)。 请问,这两个问题是分类问题,还是回归问题?
答案:问题1是个回归问题 ; 问题2则是分类问题
(二)无监督学习(Unsupervised Learning)
1. 引子
在上一节中学了监督学习,其中数据集 每个样本 都已经被标明为:正样本或者负样本,即良性或恶性肿瘤。 即:对于监督学习中的每一个样本,我们已经被清楚地告知了 什么是所谓的正确答案。而在无监督学习中,没有属性或标签这一概念,也就是说所有的数据都是一样的,没有区别。
所以在无监督学习中,我们只有一个数据集,没人告诉我们该怎么做,我们也不知道每个数据点究竟是什么意思。它只告诉我们现在有一个数据集,而你能在其中找到某种结构吗?
对于给定的数据集,无监督学习算法可能会判定该数据集包含几个不同的聚类,这就是所谓的聚类算法 ,它被用在许多地方。
2. 例子
google的新闻(一类新闻会出现在一起):谷歌新闻所做的就是搜索成千上万条新闻 ,然后自动的将他们聚合在一起。因此,有关同一主题的新闻被显示在一起。聚类算法和无监督学习算法也可以被用于许多其他的问题。
基因组学中的应用:
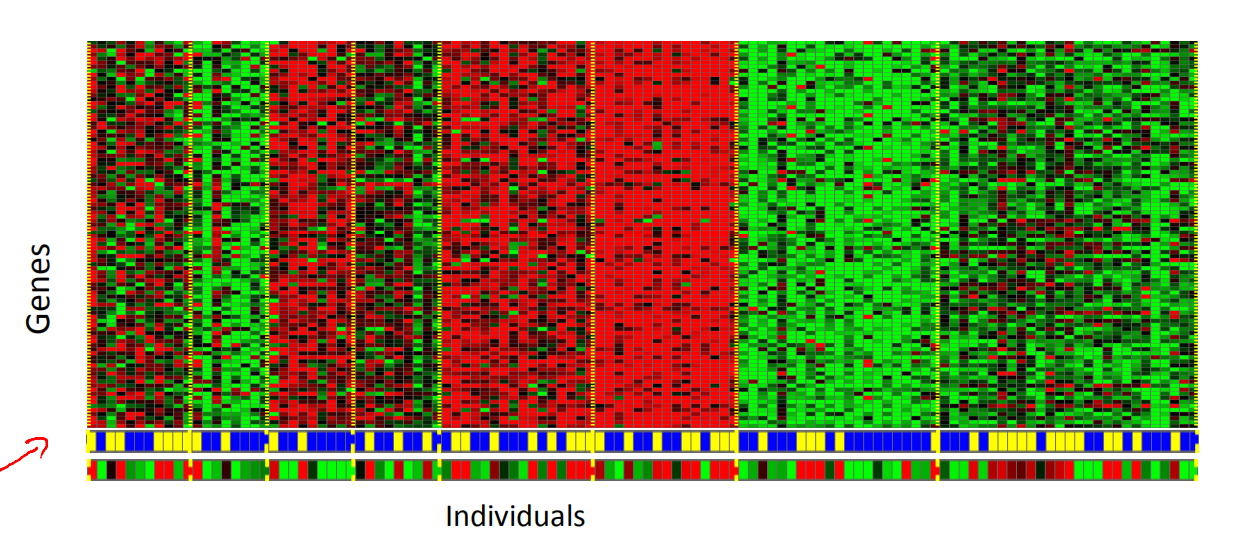
3.定义
以上就是无监督学习:我们没有提前告知这个算法相关的分类, 相反我们只是告诉算法,这儿有一堆数据,我不知道这个数据是什么东东,我不知道里面都有些什么类型,叫什么名字,我甚至不知道都有哪些类型,请问你可以自动的找到这些数据中的类型吗? 然后自动的按得到的类型把这些个体分类(虽然事先我并不知道哪些类型)。
因为对于这些数据样本来说,我们**没有给算法一个 正确答案 **,所以这就是无监督学习。
4.聚类算法的应用
聚类只是无监督学习的一种
1)组织大型的计算机集群(计算机协同归类):管理大型数据中心 ,也就是 大型计算机集群。试图 找出哪些机器趋向于“协同工作”, 如果你把这些机器放在一起,你就可以让你的数据中心更高效地工作。
2)用于社交网络的分析(朋友分类):如果可以得知 哪些朋友你用email联系的最多,或者知道你的Facebook好友,或者你Google+里的朋友。知道了这些之后,我们是否可以自动识别,哪些是很要好的朋友组,哪些仅仅是互相认识的朋友组。
3)市场分割中的应用:对于庞大的客户信息数据库,给出一个客户数据集,能否自动找出不同的市场分割,并自动将你的客户分到不同的 细分市场中,从而有助于在 不同的细分市场中 进行更有效的销售。
4)天文数据分析 。通过这些聚类算法 我们发现了许多 惊人的、有趣的 以及实用的 关于星系是如何诞生的理论 所有这些都是聚类算法的例子 。
5. 鸡尾酒宴问题
宴会上只有两个人,两个人 同时说话。我们准备好了两个麦克风 ,把它们放在房间里。两个麦克风距离这两个人 的距离是不同的,每个麦克风都记录下了来自两个人的声音的不同组合。运用算法对两个声音进行分离。
6. 介绍Octave的编程环境
Octave是一个免费的 开放源码的软件。使用Octave或Matlab这类的工具 许多学习算法,都可以用几行代码就可以实现。
在硅谷 很多的机器学习算法,我们都是先用Octave 写一个程序原型,因为在Octave中实现这些学习算法的速度快得让你无法想象。在这里 每一个函数,例如 SVD (意思是奇异值分解) 但这其实是解线性方程 的一个惯例,它被内置在Octave软件中了。
你可以在C++或 Java或Python中 实现这个算法 ,只是会 更加复杂而已;而如果你使用Octave的话 会学的更快 ,并且如果你用 Octave作为你的学习工具 和开发原型的工具 ,你的学习和开发过程 会变得更快。
而事实上在硅谷 ,很多人会这样做 :他们会先用Octave 来实现这样一个学习算法原型 ,只有在确定 这个算法可以工作后 才开始迁移到 C++ Java或其它编译环境 。事实证明 这样做 实现的算法 比你一开始就用C++ 实现的算法要快多了
7.例(自测)
问题:无监督学习 它是一种学习机制。你给算法大量的数据 ,要求它找出数据中 蕴含的类型结构。以下的四个例子中 ,哪一个 您认为是 无监督学习算法 而不是监督学习问题 。

