
爬虫系列(六) 用urllib和re爬取百度贴吧
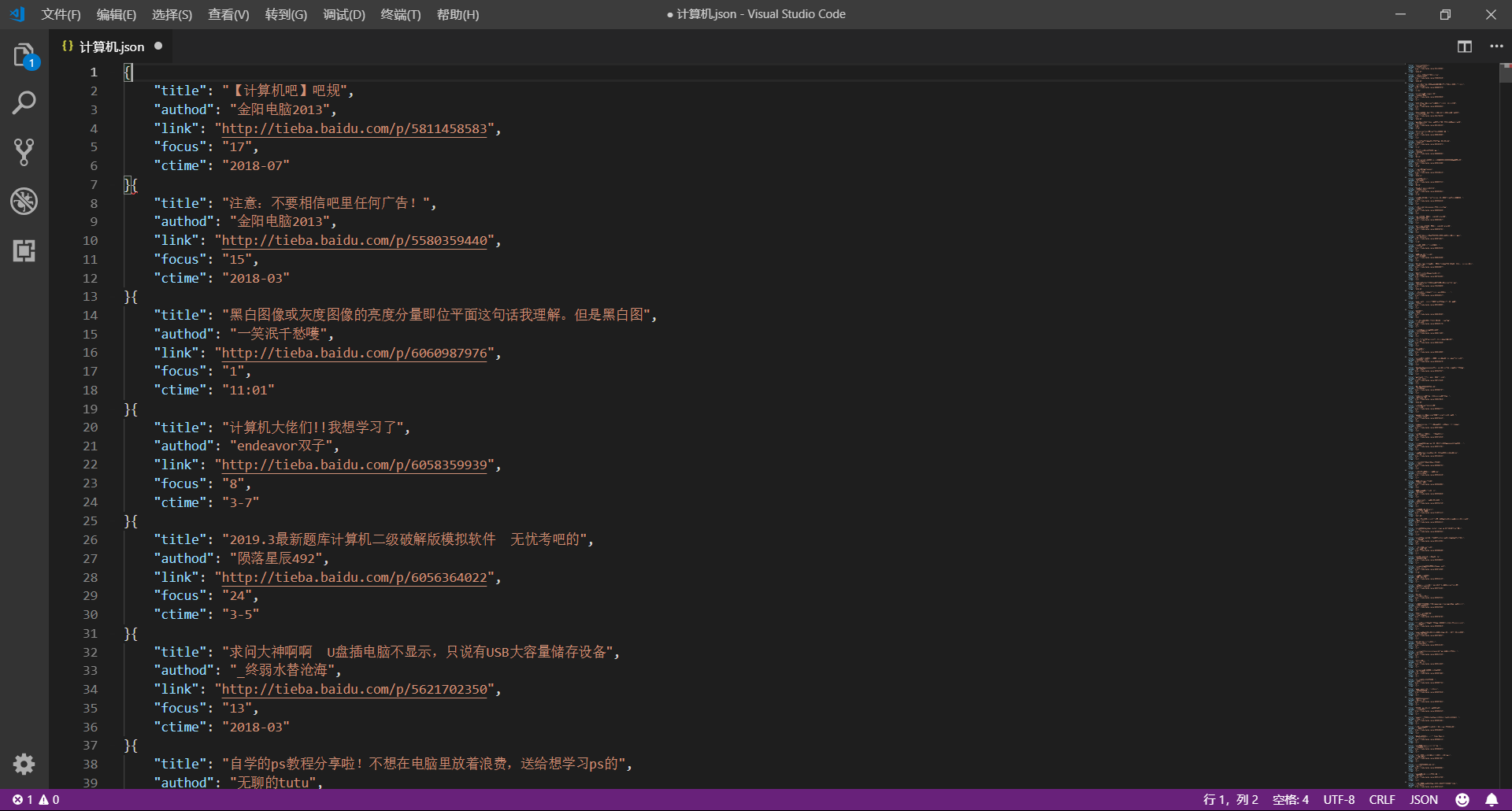
这篇文章我们将使用 urllib 和 re 模块爬取百度贴吧,并使用三种文件格式存储数据,下面先贴上最终的效果图
1、网页分析
(1)准备工作
首先我们使用 Chrome 浏览器打开 百度贴吧,在输入栏中输入关键字进行搜索,这里示例为 “计算机吧”
(2)分析 URL 规律
接下来我们开始分析网站的 URL 规律,以便于通过构造 URL 获取网站中所有网页的内容
第一页:http://tieba.baidu.com/f?kw=计算机&ie=utf-8&pn=0
第二页:http://tieba.baidu.com/f?kw=计算机&ie=utf-8&pn=50
第三页:http://tieba.baidu.com/f?kw=计算机&ie=utf-8&pn=100
...
通过观察不难发现,它的 URL 十分有规律,主要的请求参数分析如下:
kw:搜索的关键字,使用 URL 编码,可以通过urllib.parse.quote()方法实现ie:字符编码的格式,其值为 utf-8pn:当前页面的页码,并且以 50 为步幅增长
所以完整的 URL 可以泛化如下:http://tieba.baidu.com/f?kw={keyword}&ie=utf-8&pn={page}
核心代码如下:
import urllib.request
import urllib.parse
# 获取网页源代码
def get_page(url):
# 构造请求头部
headers = {
'USER-AGENT':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 构造请求对象
req = urllib.request.Request(url=url,headers=headers)
# 发送请求,得到响应
response = urllib.request.urlopen(req)
# 获得网页源代码
html = response.read().decode('utf-8')
# 返回网页源代码
return html
(3)分析内容规律
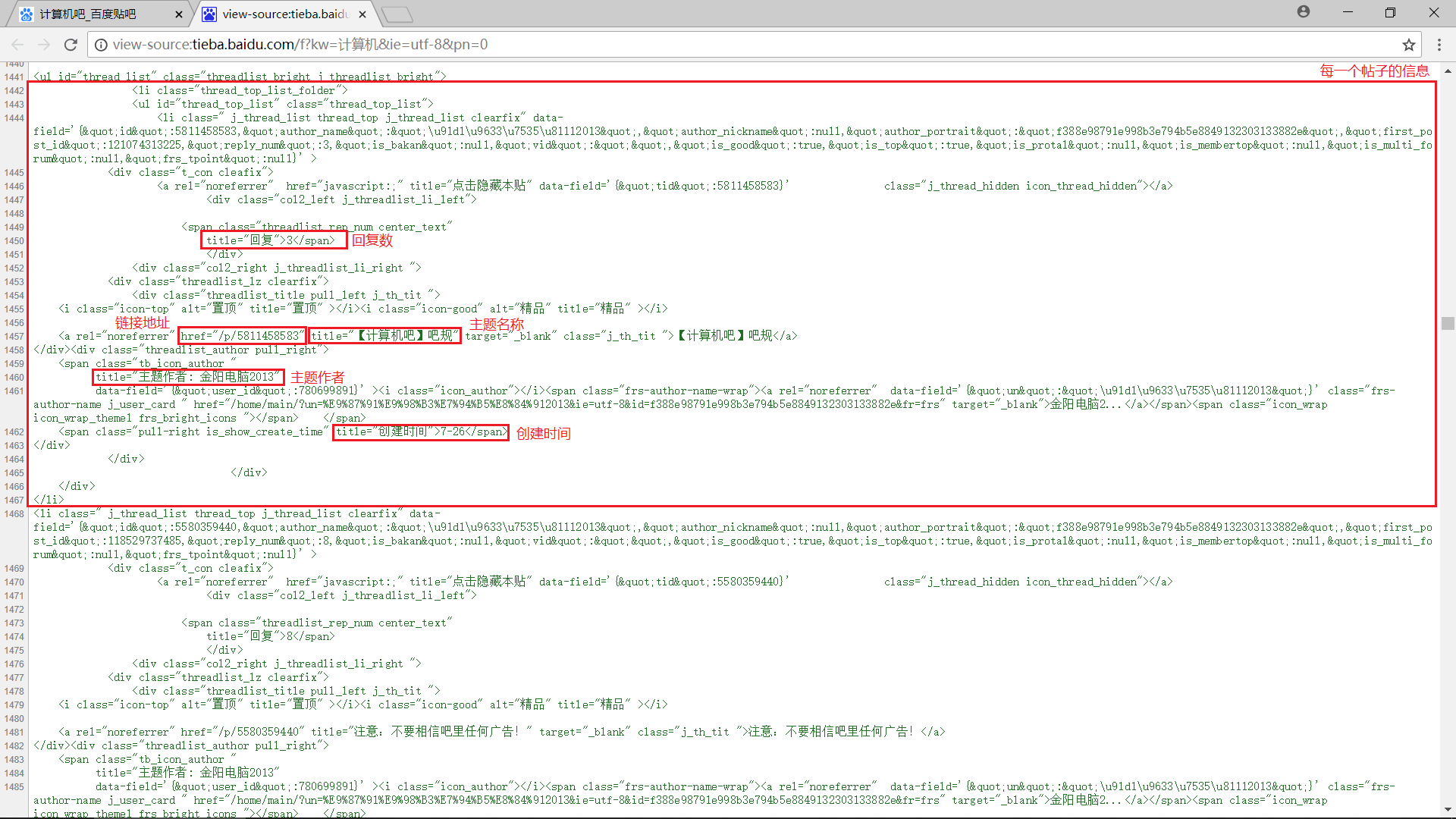
接下来我们直接使用快捷键 Ctrl+U 打开网页的源代码,认真分析每一页中我们需要抓取的数据
容易发现每一个帖子的内容都被包含在一个 <li> 标签中,我们可以使用正则表达式进行匹配,具体包括:
- 主题名称:
r'href="/p/\d+" title="(.+?)"'
- 主题作者:
r'title="主题作者: (.+?)"' - 链接地址:
r'href="/p/(\d+)"' - 回复数:
r'title="回复">(\d+)<' - 创建日期:
r'title="创建时间">(.+?)<'
核心代码如下:
import re
# 解析网页源代码,提取数据
def parse_page(html):
# 主题名称
titles = re.findall(r'href="/p/\d+" title="(.+?)"',html)
# 主题作者
authods = re.findall(r'title="主题作者: (.+?)"',html)
# 链接地址
nums = re.findall(r'href="/p/(\d+)"',html)
links = ['http://tieba.baidu.com/p/'+str(num) for num in nums]
# 回复数量
focus = re.findall(r'title="回复">(\d+)',html)
# 创建时间
ctimes = re.findall(r'title="创建时间">(.+?)<',html)
# 获得结果
data = zip(titles,authods,links,focus,ctimes)
# 返回结果
return data
(4)保存数据
下面将数据保存为 txt 文件、json 文件和 csv 文件
import json
import csv
# 打开文件
def openfile(fm,fileName):
fd = None
if fm == 'txt':
fd = open(fileName+'.txt','w',encoding='utf-8')
elif fm == 'json':
fd = open(fileName+'.json','w',encoding='utf-8')
elif fm == 'csv':
fd = open(fileName+'.csv','w',encoding='utf-8',newline='')
return fd
# 将数据保存到文件
def save2file(fm,fd,data):
if fm == 'txt':
for item in data:
fd.write('----------------------------------------\n')
fd.write('title:' + str(item[0]) + '\n')
fd.write('authod:' + str(item[1]) + '\n')
fd.write('link:' + str(item[2]) + '\n')
fd.write('focus:' + str(item[3]) + '\n')
fd.write('ctime:' + str(item[4]) + '\n')
if fm == 'json':
temp = ('title','authod','link','focus','ctime')
for item in data:
json.dump(dict(zip(temp,item)),fd,ensure_ascii=False)
if fm == 'csv':
writer = csv.writer(fd)
for item in data:
writer.writerow(item)
2、编码实现
完整代码如下,也很简单,还不到 100 行
import urllib.request
import urllib.parse
import re
import json
import csv
import time
import random
# 获取网页源代码
def get_page(url):
headers = {
'USER-AGENT':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
req = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
return html
# 解析网页源代码,提取数据
def parse_page(html):
titles = re.findall(r'href="/p/\d+" title="(.+?)"',html)
authods = re.findall(r'title="主题作者: (.+?)"',html)
nums = re.findall(r'href="/p/(\d+)"',html)
links = ['http://tieba.baidu.com/p/'+str(num) for num in nums]
focus = re.findall(r'title="回复">(\d+)',html)
ctimes = re.findall(r'title="创建时间">(.+?)<',html)
data = zip(titles,authods,links,focus,ctimes)
return data
# 打开文件
def openfile(fm,fileName):
if fm == 'txt':
return open(fileName+'.txt','w',encoding='utf-8')
elif fm == 'json':
return open(fileName+'.json','w',encoding='utf-8')
elif fm == 'csv':
return open(fileName+'.csv','w',encoding='utf-8',newline='')
else:
return None
# 将数据保存到文件
def save2file(fm,fd,data):
if fm == 'txt':
for item in data:
fd.write('----------------------------------------\n')
fd.write('title:' + str(item[0]) + '\n')
fd.write('authod:' + str(item[1]) + '\n')
fd.write('link:' + str(item[2]) + '\n')
fd.write('focus:' + str(item[3]) + '\n')
fd.write('ctime:' + str(item[4]) + '\n')
if fm == 'json':
temp = ('title','authod','link','focus','ctime')
for item in data:
json.dump(dict(zip(temp,item)),fd,ensure_ascii=False)
if fm == 'csv':
writer = csv.writer(fd)
for item in data:
writer.writerow(item)
# 开始爬取网页
def crawl():
kw = input('请输入主题贴吧名字:')
base_url = 'http://tieba.baidu.com/f?kw=' + urllib.parse.quote(kw) + '&ie=utf-8&pn={page}'
fm = input('请输入文件保存格式(txt、json、csv):')
while fm!='txt' and fm!='json' and fm!='csv':
fm = input('输入错误,请重新输入文件保存格式(txt、json、csv):')
fd = openfile(fm,kw)
page = 0
total_page = int(re.findall(r'共有主题数<span class="red_text">(\d+)</span>个',get_page(base_url.format(page=str(0))))[0])
print('开始爬取')
while page < total_page:
print('正在爬取第', int(page/50+1), '页.......')
html = get_page(base_url.format(page=str(page)))
data = parse_page(html)
save2file(fm,fd,data)
page += 50
time.sleep(random.random())
fd.close()
print('结束爬取')
if __name__ == '__main__':
crawl()
【爬虫系列相关文章】
版权声明:本博客属于个人维护博客,未经博主允许不得转载其中文章。

