

爬虫实战(三) 用Python爬取拉勾网
0、前言
最近,博主面临着选方向的困难(唉,选择困难症患者 >﹏<),所以希望了解一下目前不同岗位的就业前景
这时,就不妨写个小爬虫,爬取一下 拉勾网 的职位数据,并用图形化的方法展示出来,一目了然
整体的 思路 是采用 selenium 模拟浏览器的行为,具体的步骤如下:
- 初始化
- 爬取数据,这里分为两个部分:一是爬取网页数据,二是进行翻页操作
- 保存数据,将数据保存到文件中
- 数据可视化
整体的 代码结构 如下:
class Lagou:
# 初始化
def init(self):
pass
# 爬取网页数据
def parse_page(self):
pass
# 进行翻页操作
def turn_page(self):
pass
# 爬取数据,调用 parse_page 和 turn_page
def crawl(self):
pass
# 保存数据,将数据保存到文件中
def save(self):
pass
# 数据可视化
def draw(self):
pass
if __name__ == '__main__':
obj = Lagou()
obj.init()
obj.crawl()
obj.save()
obj.draw()
好,下面我们一起来看一下整个爬虫过程的详细分析吧!!
1、初始化
在初始化的部分,我们完成的工作需要包括以下四个方面:
- 准备全局变量
- 启动浏览器
- 打开起始 URL
- 设置 cookie
(1)准备全局变量
所谓的全局变量,是指在整个爬虫过程中都需要用到的变量,这里我们定义两个全局变量:
- data:储存爬取下来的数据
- isEnd:判断爬取是否结束
(2)启动浏览器
启动浏览器的方式大致可以分为两种,一是普通启动,二是无头启动
在普通启动时,整个爬取过程可以可视化,方便调试的时候发现错误
from selenium import webdriver
self.browser = webdriver.Chrome()
而无头启动可以减少渲染时间,加快爬取过程,一般在正式爬取时使用
from selenium import webdriver
opt = webdriver.chrome.options.Options()
opt.set_headless()
self.browser = webdriver.Chrome(chrome_options = opt)
(3)打开起始 URL
首先,我们打开拉勾网的首页(URL:https://www.lagou.com/)
在输入框中输入【python】进行搜索,可以发现网页跳转到如下的 URL:
https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=
然后,我们再次尝试在输入框中输入【爬虫】进行搜索,网页跳转到如下 URL:
https://www.lagou.com/jobs/list_爬虫?labelWords=&fromSearch=true&suginput=
从中,我们不难发现规律,对 URL 进行泛化后可以得到下面的结果(这个也就是我们的起始 URL):
https://www.lagou.com/jobs/list_{position}?labelWords=&fromSearch=true&suginput=
其中,参数 position 就是我们在输入框中输入的内容(需要进行 URL 编码)
(4)设置 cookie
由于拉勾网对未登录用户的访问数量做了限制,所以在浏览一定数量的网页后,网页会自动跳转到登陆界面:
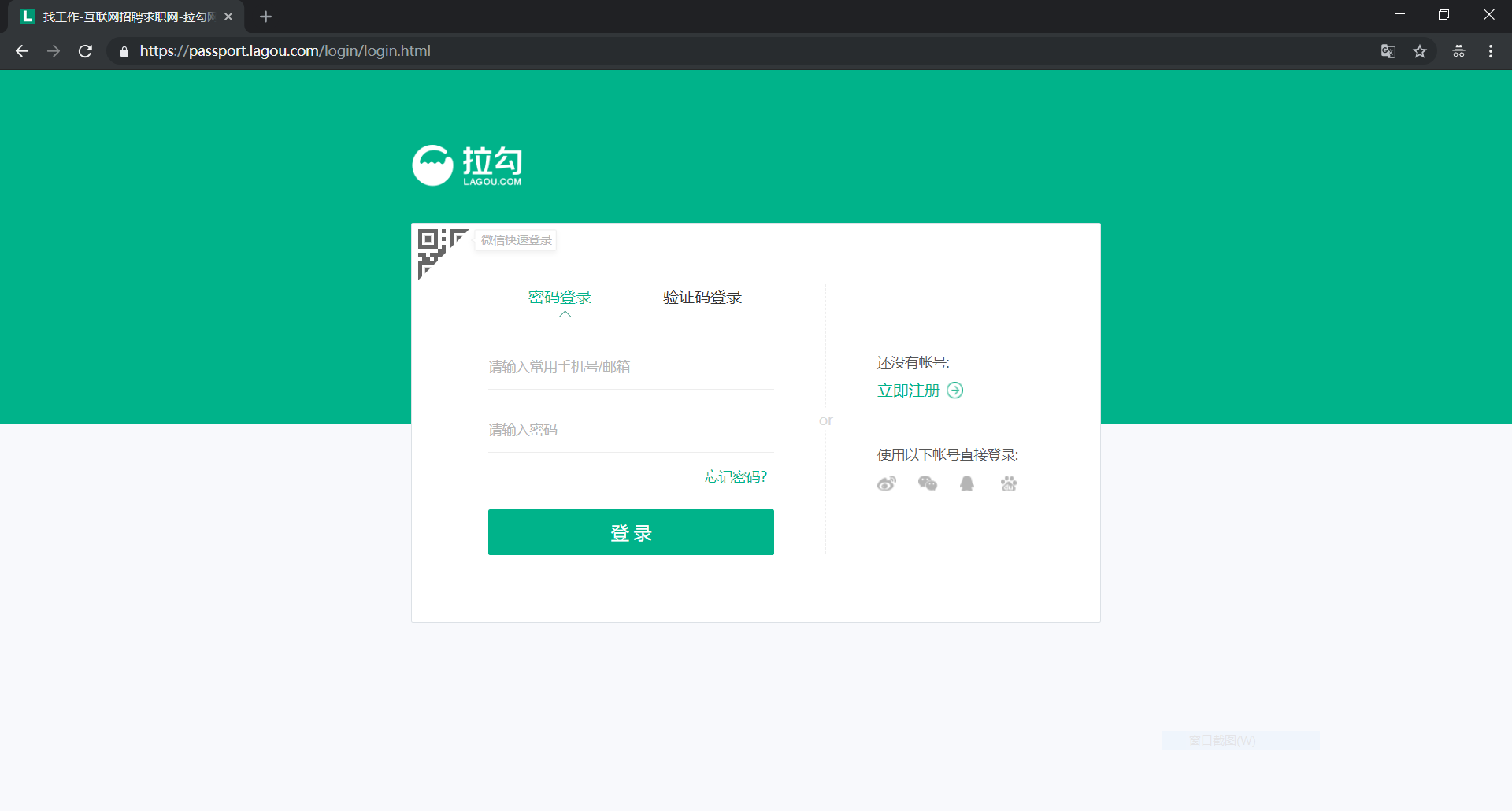
这时,爬虫就不能正常工作了(当时博主就是在这个地方卡了好久,一直没找出原因)
为了解决上面的问题,我们可以使用 cookie 进行模拟登陆
方便起见,可以直接在浏览器中手动获取 cookie,然后将 cookie 信息添加到 browser 中
(5)初始化部分完整代码
# 初始化
def init(self):
# 准备全局变量
self.data = list()
self.isEnd = False
# 启动浏览器、初始化浏览器
opt = webdriver.chrome.options.Options()
opt.set_headless()
self.browser = webdriver.Chrome(chrome_options = opt)
self.wait = WebDriverWait(self.browser,10)
# 打开起始 URL
self.position = input('请输入职位:')
self.browser.get('https://www.lagou.com/jobs/list_' + urllib.parse.quote(self.position) + '?labelWords=&fromSearch=true&suginput=')
# 设置 cookie
cookie = input('请输入cookie:')
for item in cookie.split(';'):
k,v = item.strip().split('=')
self.browser.add_cookie({'name':k,'value':v})
2、爬取数据
在这一部分,我们需要完成以下的两个工作:
- 爬取网页数据
- 进行翻页操作
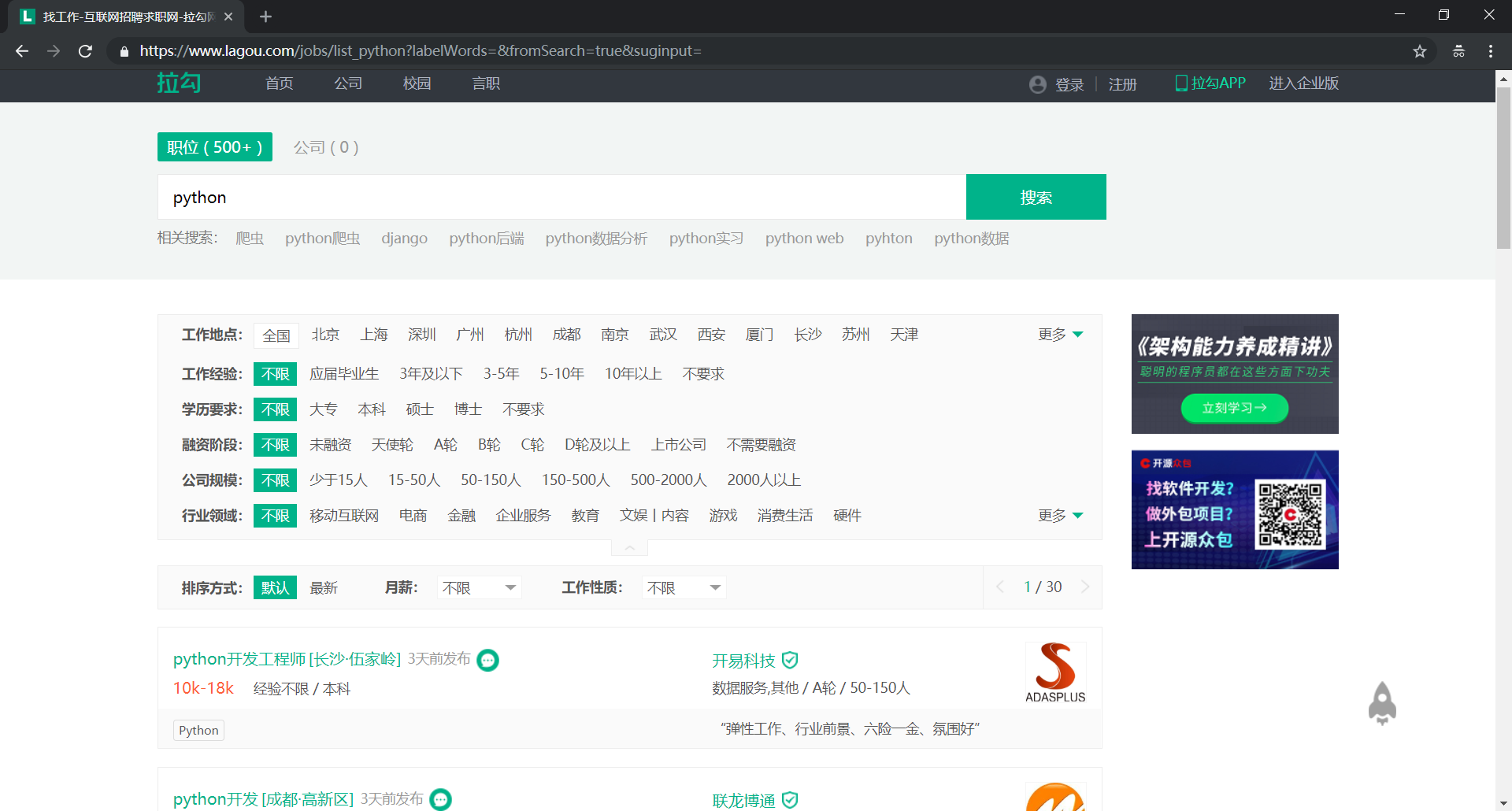
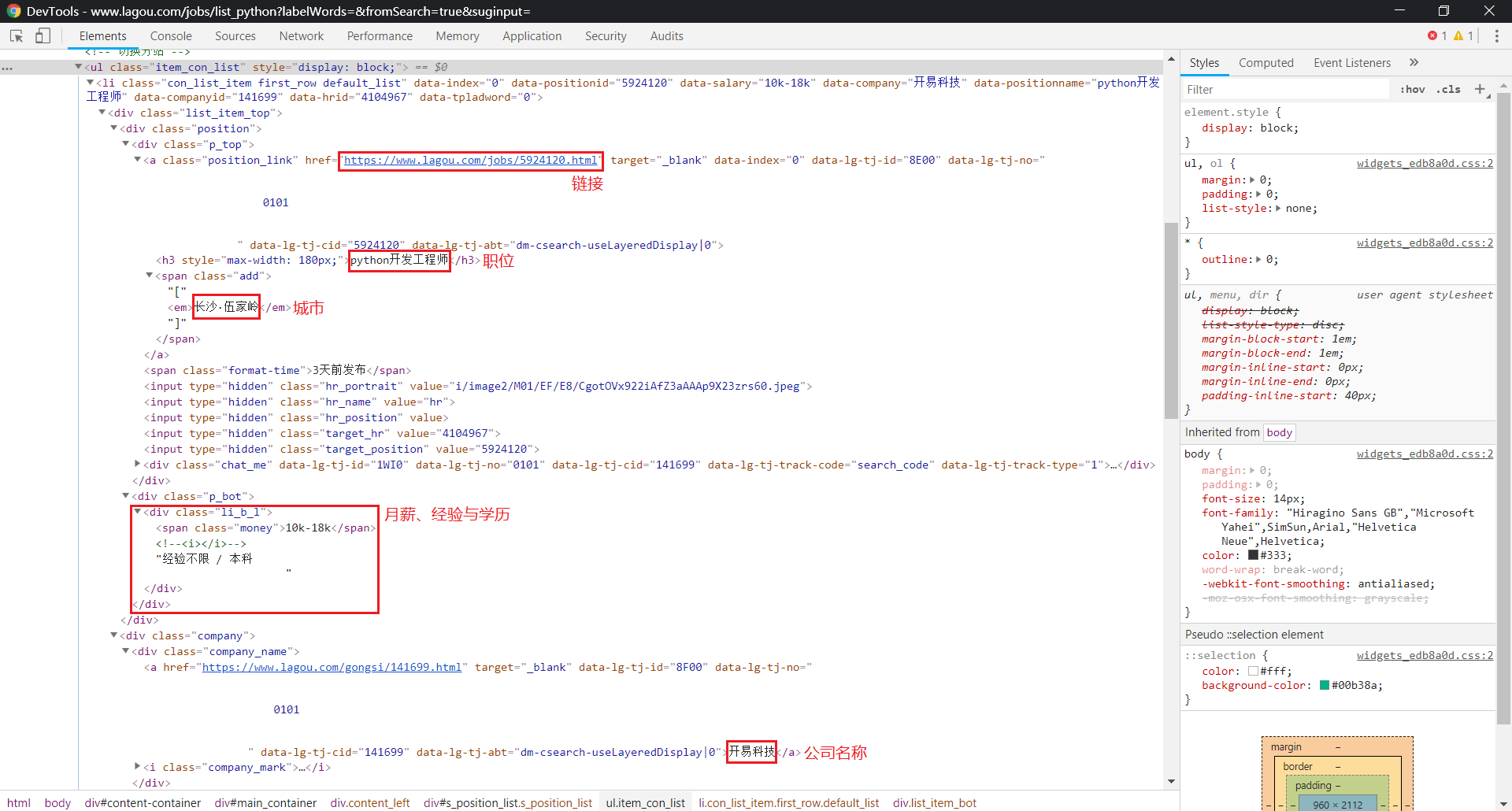
(1)爬取网页数据
在起始页面中,包含有我们需要的职位信息(可以使用 xpath 进行匹配):
-
链接:
//a[@class="position_link"] -
职位:
//a[@class="position_link"]/h3 -
城市:
//a[@class="position_link"]/span/em -
月薪、经验与学历:
//div[@class="p_bot"]/div[@class="li_b_l"] -
公司名称:
//div[@class="company_name"]/a
这里,我们需要使用 try - except - else 异常处理机制去处理异常,以保证程序的健壮性
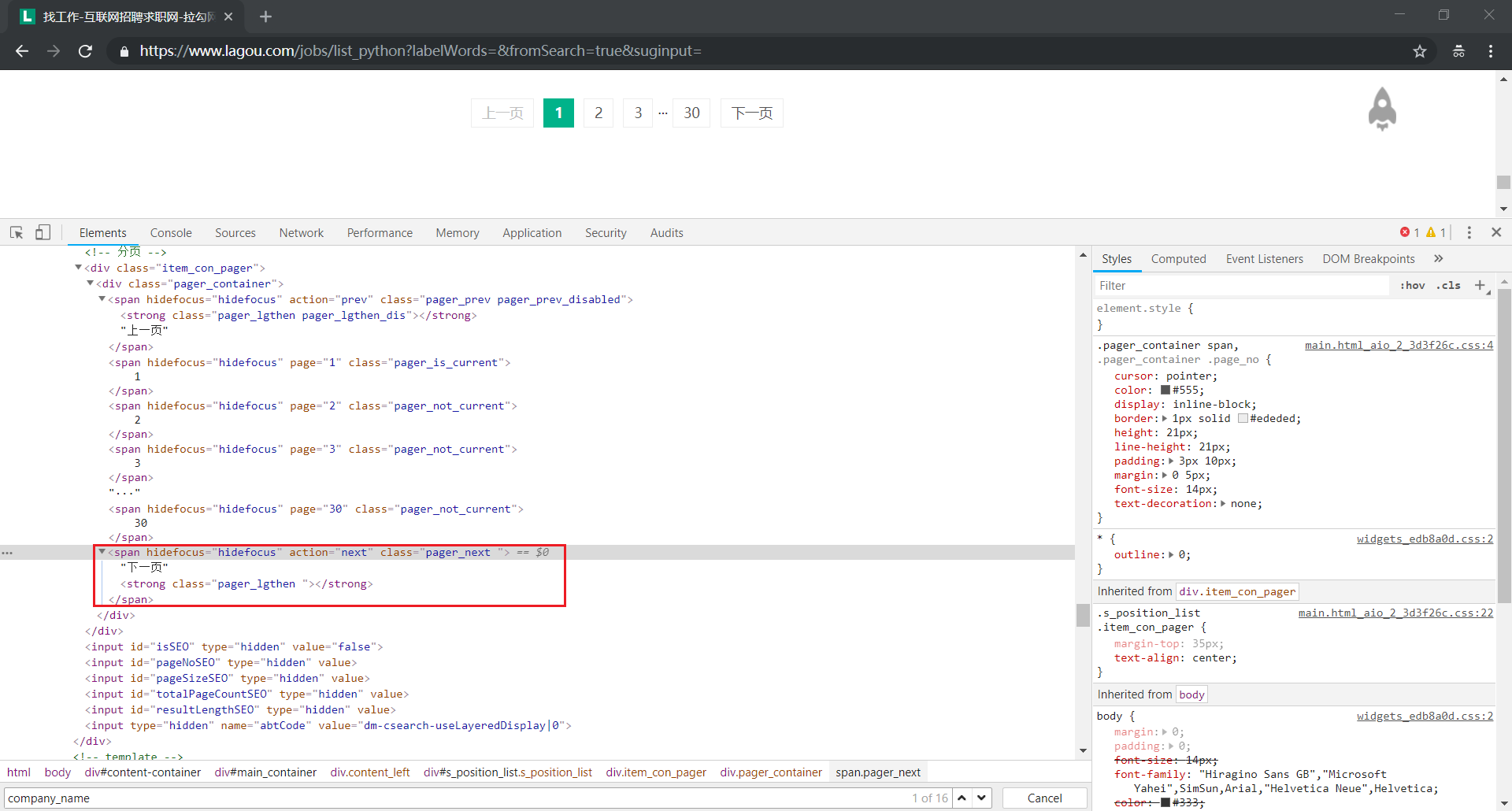
(2)进行翻页操作
我们通过模拟点击【下一页】按钮,进行翻页操作
这里,我们同样需要使用 try - except - else 去处理异常
(3)爬取数据部分完整代码
# 爬取网页数据
def parse_page(self):
try:
# 链接
link = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//a[@class="position_link"]')))
link = [item.get_attribute('href') for item in link]
# 职位
position = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//a[@class="position_link"]/h3')))
position = [item.text for item in position]
# 城市
city = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//a[@class="position_link"]/span/em')))
city = [item.text for item in city]
# 月薪、经验与学历
ms_we_eb = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//div[@class="p_bot"]/div[@class="li_b_l"]')))
monthly_salary = [item.text.split('/')[0].strip().split(' ')[0] for item in ms_we_eb]
working_experience = [item.text.split('/')[0].strip().split(' ')[1] for item in ms_we_eb]
educational_background = [item.text.split('/')[1].strip() for item in ms_we_eb]
# 公司名称
company_name = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//div[@class="company_name"]/a')))
company_name = [item.text for item in company_name]
except TimeoutException:
self.isEnd = True
except StaleElementReferenceException:
time.sleep(3)
self.parse_page()
else:
temp = list(map(lambda a,b,c,d,e,f,g: {'link':a,'position':b,'city':c,'monthly_salary':d,'working_experience':e,'educational_background':f,'company_name':g}, link, position, city, monthly_salary, working_experience, educational_background, company_name))
self.data.extend(temp)
# 进行翻页操作
def turn_page(self):
try:
pager_next = self.wait.until(EC.element_to_be_clickable((By.CLASS_NAME,'pager_next')))
except TimeoutException:
self.isEnd = True
else:
pager_next.click()
time.sleep(3)
# 爬取数据,调用 parse_page 和 turn_page 方法
def crawl(self):
count = 0
while not self.isEnd :
count += 1
print('正在爬取第 ' + str(count) + ' 页 ...')
self.parse_page()
self.turn_page()
print('爬取结束')
3、保存数据
接下来,我们将数据储存到 JSON 文件中
# 将数据保存到文件中
def save(self):
with open('lagou.json','w',encoding='utf-8') as f:
for item in self.data:
json.dump(item,f,ensure_ascii=False)
这里,有两个需要注意的地方:
- 在使用
open()函数时,需要加上参数encoding='utf-8' - 在使用
dump()函数时,需要加上参数ensure_ascii=False
4、数据可视化
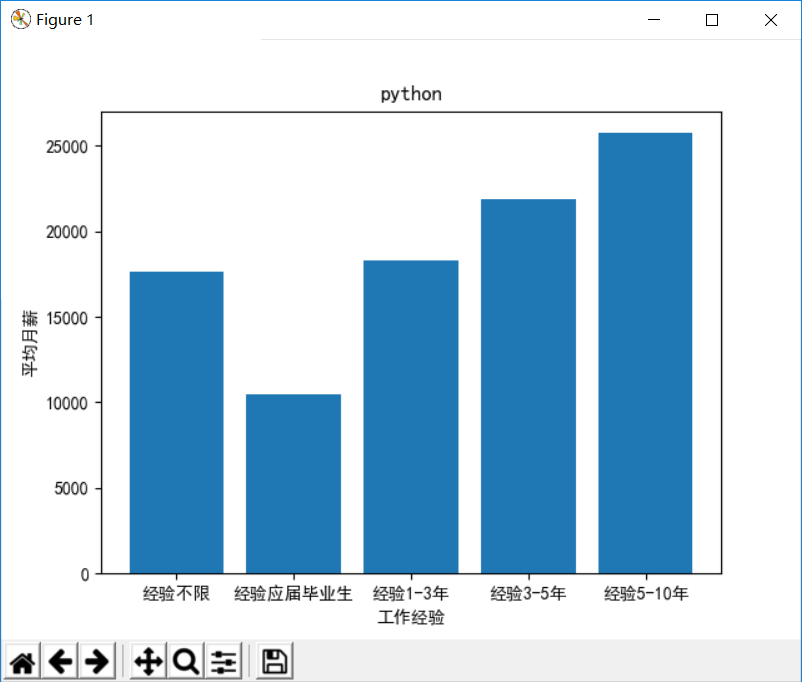
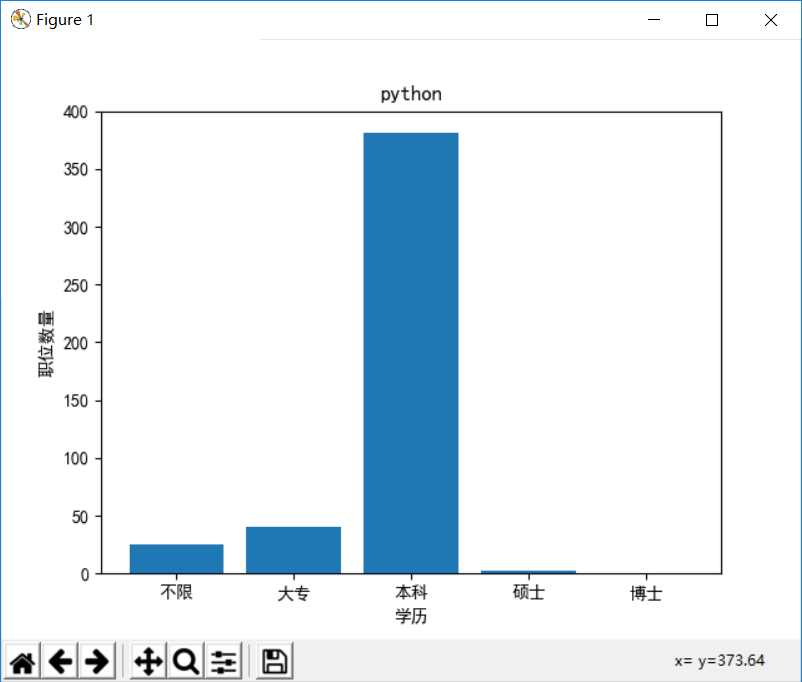
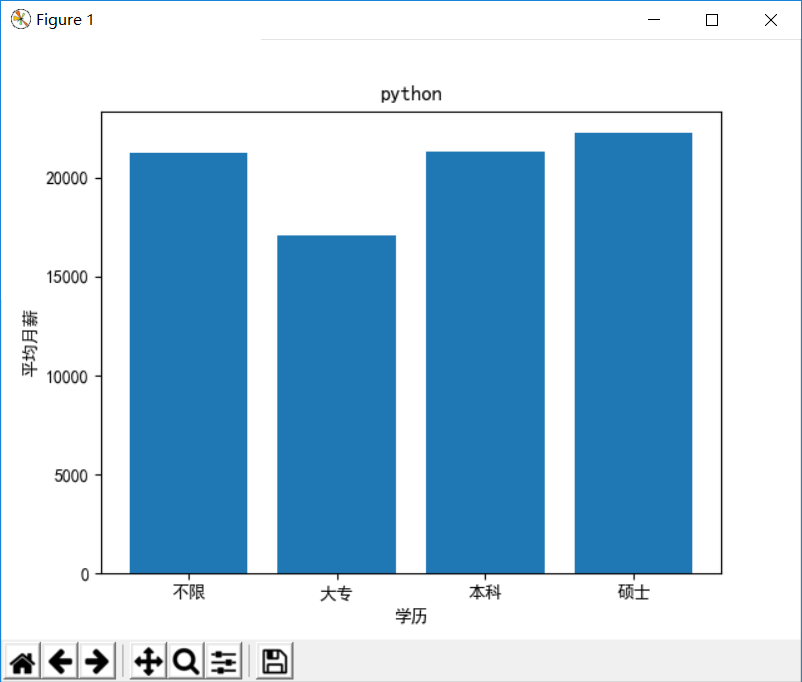
数据可视化有利于更直观地展示数据之间的关系,根据爬取的数据,我们可以画出如下 4 个直方图:
- 工作经验-职位数量
- 工作经验-平均月薪
- 学历-职位数量
- 学历-平均月薪
这里,我们需要用到 matplotlib 库,需要注意一个中文编码的问题,可以使用以下的语句解决:
plt.rcParams['font.sans-serif'] = ['SimHei']
# 数据可视化
def draw(self):
count_we = {'经验不限':0,'经验应届毕业生':0,'经验1年以下':0,'经验1-3年':0,'经验3-5年':0,'经验5-10年':0}
total_we = {'经验不限':0,'经验应届毕业生':0,'经验1年以下':0,'经验1-3年':0,'经验3-5年':0,'经验5-10年':0}
count_eb = {'不限':0,'大专':0,'本科':0,'硕士':0,'博士':0}
total_eb = {'不限':0,'大专':0,'本科':0,'硕士':0,'博士':0}
for item in self.data:
count_we[item['working_experience']] += 1
count_eb[item['educational_background']] += 1
try:
li = [float(temp.replace('k','000')) for temp in item['monthly_salary'].split('-')]
total_we[item['working_experience']] += sum(li) / len(li)
total_eb[item['educational_background']] += sum(li) / len(li)
except:
count_we[item['working_experience']] -= 1
count_eb[item['educational_background']] -= 1
# 解决中文编码问题
plt.rcParams['font.sans-serif'] = ['SimHei']
# 工作经验-职位数量
plt.title(self.position)
plt.xlabel('工作经验')
plt.ylabel('职位数量')
x = ['经验不限','经验应届毕业生','经验1-3年','经验3-5年','经验5-10年']
y = [count_we[item] for item in x]
plt.bar(x,y)
plt.show()
# 工作经验-平均月薪
plt.title(self.position)
plt.xlabel('工作经验')
plt.ylabel('平均月薪')
x = list()
y = list()
for item in ['经验不限','经验应届毕业生','经验1-3年','经验3-5年','经验5-10年']:
if count_we[item] != 0:
x.append(item)
y.append(total_we[item]/count_we[item])
plt.bar(x,y)
plt.show()
# 学历-职位数量
plt.title(self.position)
plt.xlabel('学历')
plt.ylabel('职位数量')
x = ['不限','大专','本科','硕士','博士']
y = [count_eb[item] for item in x]
plt.bar(x,y)
plt.show()
# 学历-平均月薪
plt.title(self.position)
plt.xlabel('学历')
plt.ylabel('平均月薪')
x = list()
y = list()
for item in ['不限','大专','本科','硕士','博士']:
if count_eb[item] != 0:
x.append(item)
y.append(total_eb[item]/count_eb[item])
plt.bar(x,y)
plt.show()
5、大功告成
(1)完整代码
至此,整个爬虫过程已经分析完毕,完整的代码如下:
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from selenium.common.exceptions import StaleElementReferenceException
import urllib.parse
import time
import json
import matplotlib.pyplot as plt
class Lagou:
# 初始化
def init(self):
self.data = list()
self.isEnd = False
opt = webdriver.chrome.options.Options()
opt.set_headless()
self.browser = webdriver.Chrome(chrome_options = opt)
self.wait = WebDriverWait(self.browser,10)
self.position = input('请输入职位:')
self.browser.get('https://www.lagou.com/jobs/list_' + urllib.parse.quote(self.position) + '?labelWords=&fromSearch=true&suginput=')
cookie = input('请输入cookie:')
for item in cookie.split(';'):
k,v = item.strip().split('=')
self.browser.add_cookie({'name':k,'value':v})
# 爬取网页数据
def parse_page(self):
try:
link = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//a[@class="position_link"]')))
link = [item.get_attribute('href') for item in link]
position = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//a[@class="position_link"]/h3')))
position = [item.text for item in position]
city = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//a[@class="position_link"]/span/em')))
city = [item.text for item in city]
ms_we_eb = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//div[@class="p_bot"]/div[@class="li_b_l"]')))
monthly_salary = [item.text.split('/')[0].strip().split(' ')[0] for item in ms_we_eb]
working_experience = [item.text.split('/')[0].strip().split(' ')[1] for item in ms_we_eb]
educational_background = [item.text.split('/')[1].strip() for item in ms_we_eb]
company_name = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//div[@class="company_name"]/a')))
company_name = [item.text for item in company_name]
except TimeoutException:
self.isEnd = True
except StaleElementReferenceException:
time.sleep(3)
self.parse_page()
else:
temp = list(map(lambda a,b,c,d,e,f,g: {'link':a,'position':b,'city':c,'monthly_salary':d,'working_experience':e,'educational_background':f,'company_name':g}, link, position, city, monthly_salary, working_experience, educational_background, company_name))
self.data.extend(temp)
# 进行翻页操作
def turn_page(self):
try:
pager_next = self.wait.until(EC.element_to_be_clickable((By.CLASS_NAME,'pager_next')))
except TimeoutException:
self.isEnd = True
else:
pager_next.click()
time.sleep(3)
# 爬取数据
def crawl(self):
count = 0
while not self.isEnd :
count += 1
print('正在爬取第 ' + str(count) + ' 页 ...')
self.parse_page()
self.turn_page()
print('爬取结束')
# 保存数据
def save(self):
with open('lagou.json','w',encoding='utf-8') as f:
for item in self.data:
json.dump(item,f,ensure_ascii=False)
# 数据可视化
def draw(self):
count_we = {'经验不限':0,'经验应届毕业生':0,'经验1年以下':0,'经验1-3年':0,'经验3-5年':0,'经验5-10年':0}
total_we = {'经验不限':0,'经验应届毕业生':0,'经验1年以下':0,'经验1-3年':0,'经验3-5年':0,'经验5-10年':0}
count_eb = {'不限':0,'大专':0,'本科':0,'硕士':0,'博士':0}
total_eb = {'不限':0,'大专':0,'本科':0,'硕士':0,'博士':0}
for item in self.data:
count_we[item['working_experience']] += 1
count_eb[item['educational_background']] += 1
try:
li = [float(temp.replace('k','000')) for temp in item['monthly_salary'].split('-')]
total_we[item['working_experience']] += sum(li) / len(li)
total_eb[item['educational_background']] += sum(li) / len(li)
except:
count_we[item['working_experience']] -= 1
count_eb[item['educational_background']] -= 1
# 解决中文编码问题
plt.rcParams['font.sans-serif'] = ['SimHei']
# 工作经验-职位数量
plt.title(self.position)
plt.xlabel('工作经验')
plt.ylabel('职位数量')
x = ['经验不限','经验应届毕业生','经验1-3年','经验3-5年','经验5-10年']
y = [count_we[item] for item in x]
plt.bar(x,y)
plt.show()
# 工作经验-平均月薪
plt.title(self.position)
plt.xlabel('工作经验')
plt.ylabel('平均月薪')
x = list()
y = list()
for item in ['经验不限','经验应届毕业生','经验1-3年','经验3-5年','经验5-10年']:
if count_we[item] != 0:
x.append(item)
y.append(total_we[item]/count_we[item])
plt.bar(x,y)
plt.show()
# 学历-职位数量
plt.title(self.position)
plt.xlabel('学历')
plt.ylabel('职位数量')
x = ['不限','大专','本科','硕士','博士']
y = [count_eb[item] for item in x]
plt.bar(x,y)
plt.show()
# 学历-平均月薪
plt.title(self.position)
plt.xlabel('学历')
plt.ylabel('平均月薪')
x = list()
y = list()
for item in ['不限','大专','本科','硕士','博士']:
if count_eb[item] != 0:
x.append(item)
y.append(total_eb[item]/count_eb[item])
plt.bar(x,y)
plt.show()
if __name__ == '__main__':
obj = Lagou()
obj.init()
obj.crawl()
obj.save()
obj.draw()
(2)运行过程
下面,我们一起来运行代码看看!
在运行代码时,程序会要求输入【职位】和【cookie】,其中,cookie 的获取方法如下:
进入 拉勾网首页,并登陆
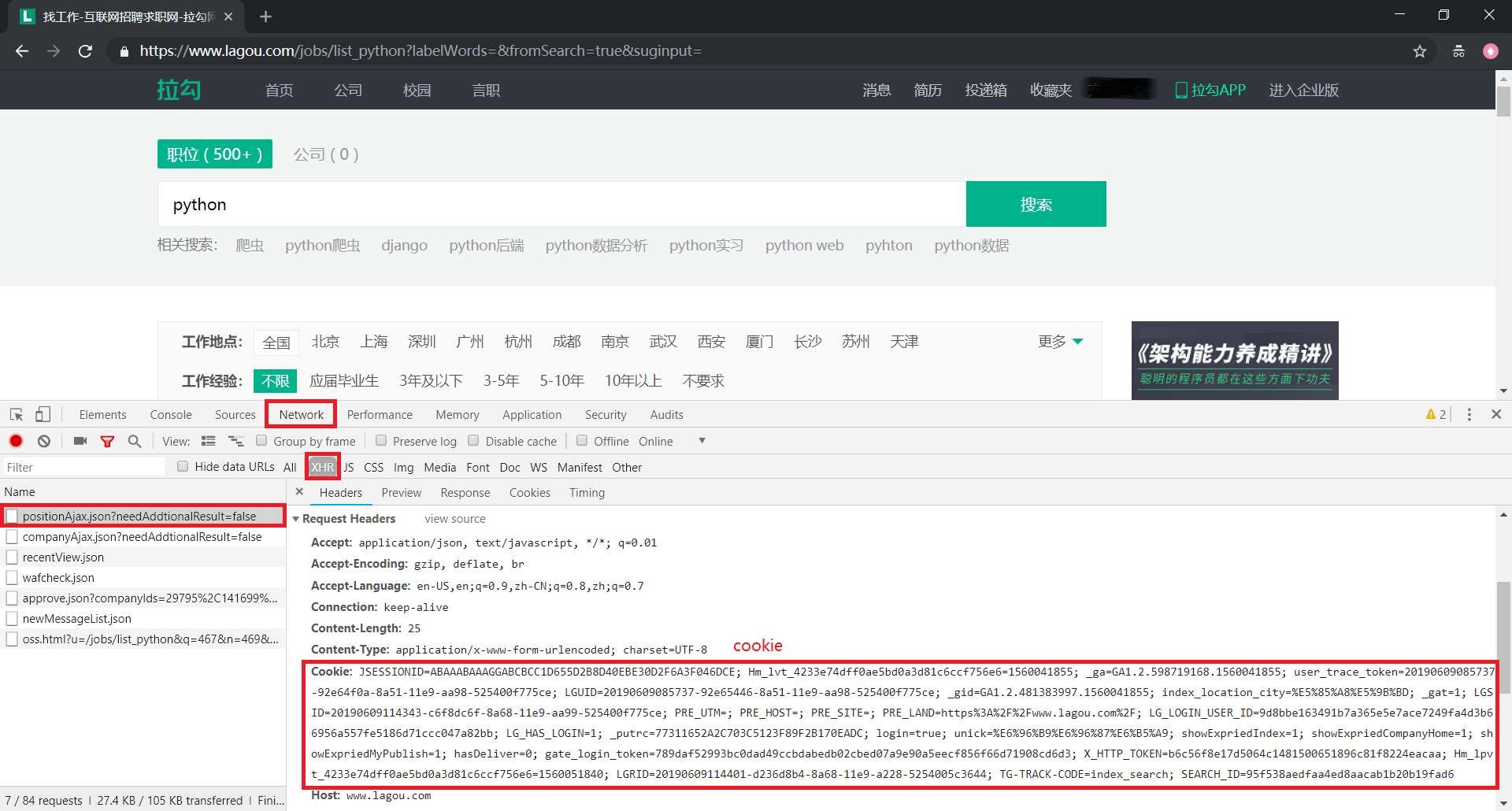
使用快捷键 Ctrl+Shift+I 或 F12 打开开发者工具
在输入框中输入【职位(这里的示例为 python)】进行搜索,抓包分析,可以看到 cookie 信息就包含在其中
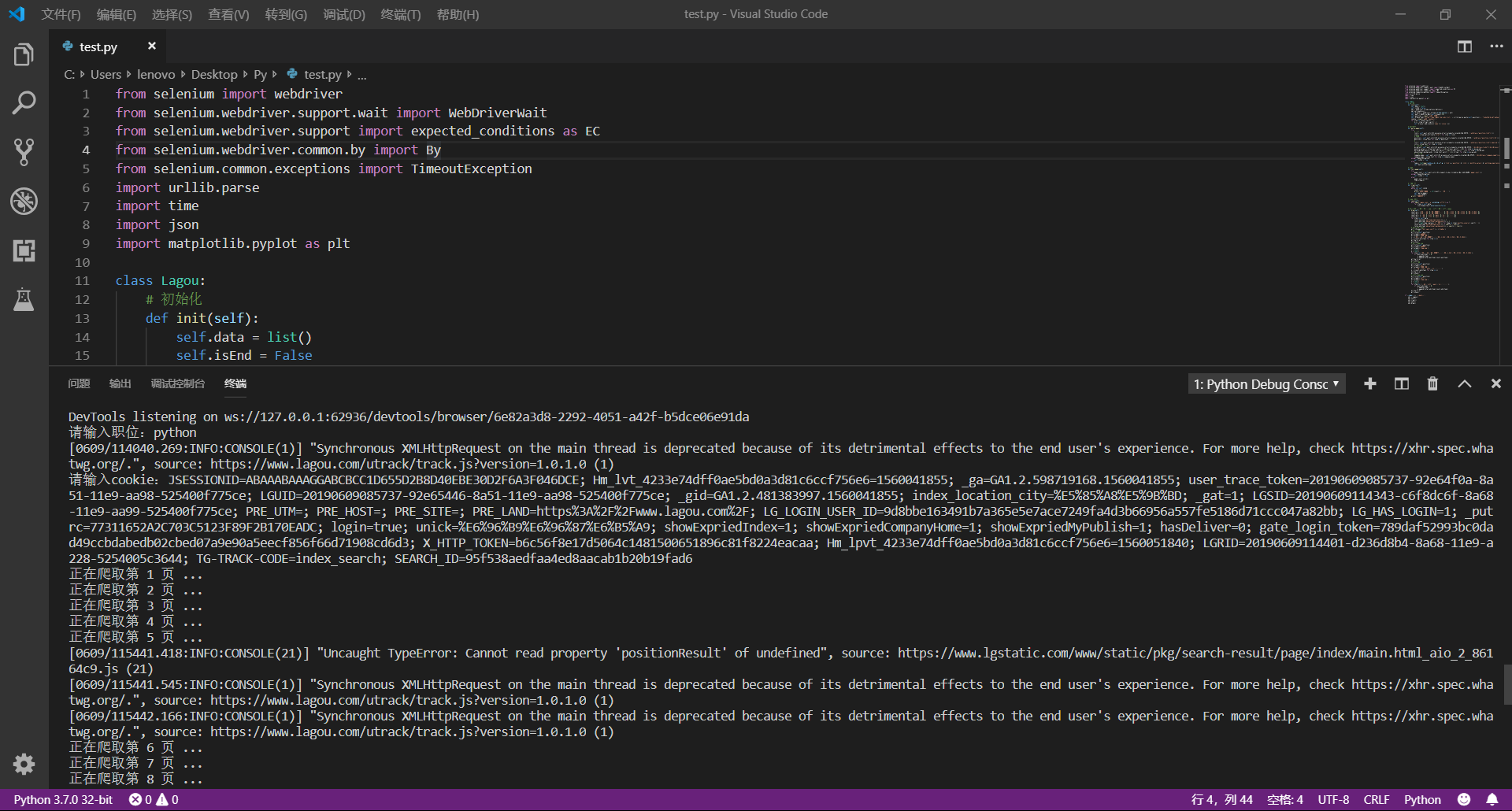
完整的运行过程如下:
(3)运行结果

注意:本项目代码仅作学习交流使用!!!
