循环队列FIFO
这里的 FIFO 是先入先出的意思,即谁先进入队列,谁先出去。比如我们需要串口打印数据,当使用缓存将该数据保存的时候,在输出数据时必然是先进入的数据先出去,那么该如何实现这种机制呢?
首先就是建立一个缓存空间,这里假设为 7 个字节空间进行说明。
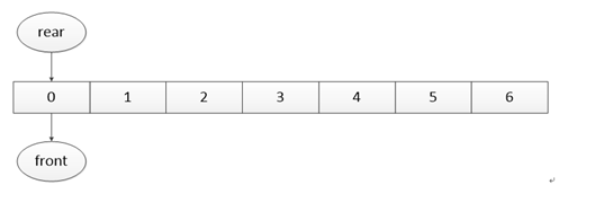
缓存一开始没有数据,并且用一个变量 rear 指示下一个存入缓存的索引地址,这里下一个存放的位置就是 0,用另一个变量 front 指示下一个存入缓存的索引地址,并且下一个读出数据的索引地址也是 0。目前队列中是没有数据的,也就是不能读出数据,队列为空的判断条件在这里就是两个索引值相同。
现在开始存放数据:
在这里可以看到队列中加入了 5 个数据,并且每加入一个数据后队尾索引加 1,队头不变,这就是数据加入队列的过程。但是缓存空间只有 7 个,如何判断队列已满呢?
如果只是先一次性加数据到队列中,然后再读出数据,那这里的判断条件显然是队尾索引为 6,但实际上是在加入数据的同时也可能出现有数据已出队的情况,比如: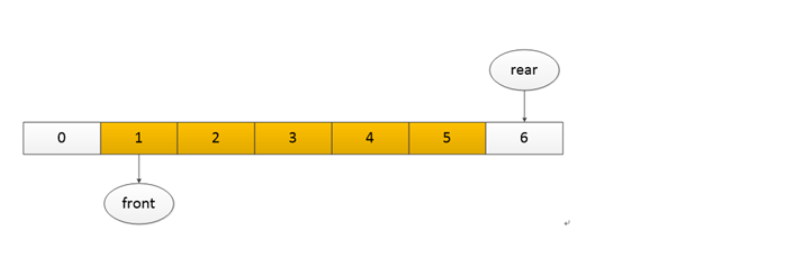
这个时候索引是 6,但是实际上还是有一个索引为 0 的位置是空的,也就是实际上还是可以再加入一个数据的。这个时候又该如何判断是否队列已满呢?
通过以下算法即可:
(rear + 1) % 7 == front
你可以发现这个算法的巧妙。通过%运算将索引又从 6 返回到了 0 处,这是实现循环队列的关键之处。通过该算法就能知道队列是否已满了。队列空的算法就是队头队尾索引相同。
front == rear
刚才说过通过%运算可以实现索引值的循环,所以当索引为 6 的时候,一般思维是通过 if 判断语句将其定位到下一个索引位置,而这里通过以下算法即可将其重新定位:
rear = (rear + 1) %7
这样当 rear 等于 6 的时候下一个索引就是 0 了。非常巧妙的实现了数值的循环。这个时候就出现了如下情况:
队尾索引跑到了队头索引的前头。并且周而复始,这就是循环队列了,充分的利用了空间。
但你有没有发现其实在有 7 个空间的情况下其实只能存放 6 个数据,另一个数据空间是没法使用的,为什么呢?看看以下两种情况:

这里一种为队列为空的情况,有一种队列已满的情况,这个时候到底是空还是满的单靠这两个变量是无法判断的,这个时候就需要增加一个变量指示队列已满的情况,并且需要加入判断语句,降低了运行效率,所以建议采用留空的方式进行统一处理。
这样入队出队操作都有了,也就算完成了基本操作,实际上有时候需要获取整个队列存放的数量,这时又涉及到了一个有意思的公式:
(rear – front + 7) % 7
来看一看这个公式的巧妙性。当出现如下 rear 在后,front 在前这种正常情况时,只要两种相减即可得到队列的长度。

但实际上对于循环队列来说 rear 在前,front 在后也是再正常不过的事情,如下:
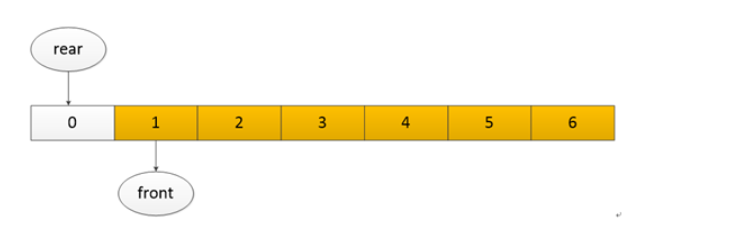
这个时候又该如何获取呢?就是利用上面的公式了。通过它就能适应这两种情况。
通过了解这个公式,感受它的巧妙,又可以想到利用这个公式干点其他的,比如在时间的获取上,不管你计时变量设置得多么大,总有一个限度,总会出现计时溢出的情况,但实际上你只要获取溢出时间内的时间即可,比如一个 16 位变量,每 1ms 自加 1,你想获取 100ms 的定时时间(小于 65535),正常情况下只需通过如下判断即可准确获取:
CurrentTime >= (Time + 100)
CurrentTime 是变化的时间,Time 是开始的时刻。但你开始的时刻是有可能是在 CurrentTime = 65435 的情况下的,CurrentTime 必然溢出,开始从零开始计时,这样你这个条件满足必须是 CurrentTime = 65535,也就是说你从 65435 – 0 - 65535,整整多了一个溢出周期时间。而如果你使用上面的公式就即使计数器溢出了,也能获取准确的定时时间。
(CurrentTime - Time + 65535) % 65535 >= 100
只要队列的每个元素设置一个标志,删除这个标志就代表这个队列元素已删除即可,而插入元素则就重新设置该标志,表明你已经存放了数据,并将数据写入对应的位置即可。当然这个标志其实还可以用于标志这个元素属于什么种类的数据,这样就是将两种功能结合了在一个标志内了,而你要做的就是实现他们之间的一一对应关系即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号