

性能测试学习笔记(二)
1.性能指标综述
通常我们都从两个层面定义性能场景的需求指标:业务指标和技术指标。这两个层面需要有映射关系,技术指标不能脱离业务指标。
所有的技术指标都是在有业务场景的前提下制定的,而技术指标和业务指标之间也要有详细的换算过程。这样一来,技术指标就不会是一块飞地。同时,在回答了技术指标是否满足的同时,也能回答是否可以满足业务指标。
1.1常用的性能指标表示法
| 简写 | 英文全称 | 含义 |
| RT | Response Time | 响应时间,通常说的响应时间都是包括了Request Time和Response Time |
| HPS | Hits Per Second | 每秒点击数 |
| TPS | Transactions Per Second | 每秒事务数 |
| QPS | Queries Per Second | 在MySQL中指每秒SQL数 |
| RPS | Requests Per Second | 每秒请求数 |
| CPS | Codes Per Second | 在HTTP协议中,CPS偶有提及,指的是HTTP返回码每秒 |
| PV | Page View | 页面浏览量 |
| UV | Unique Vistor | 独立访问者 |
| IP | Internet Protocol | 本意是IP地址,在性能中一般指独立IP数 |
| Throughput | 吞吐量 | |
| IOPS | Input/Output Operations Per Second | 通常描述磁盘 |
1.2性能指标解读
TPS 是性能领域中一个关键的性能指标概念,它用来描述每秒事务数。TPS 在不同的行业、不同的业务中定义的粒度都是不同的。所以不管在哪里用 TPS,一定要有一个前提,就是所有相关的人都要知道 T 是如何定义的。
通常情况下,会根据场景的目的来定义 TPS 的粒度。如果是接口层性能测试,T 可以直接定义为接口级;如果业务级性能测试,T 可以直接定义为每个业务步骤和完整的业务。
在性能测试过程中,TPS之所以重要,是因为它可以反应出一个系统的处理能力。
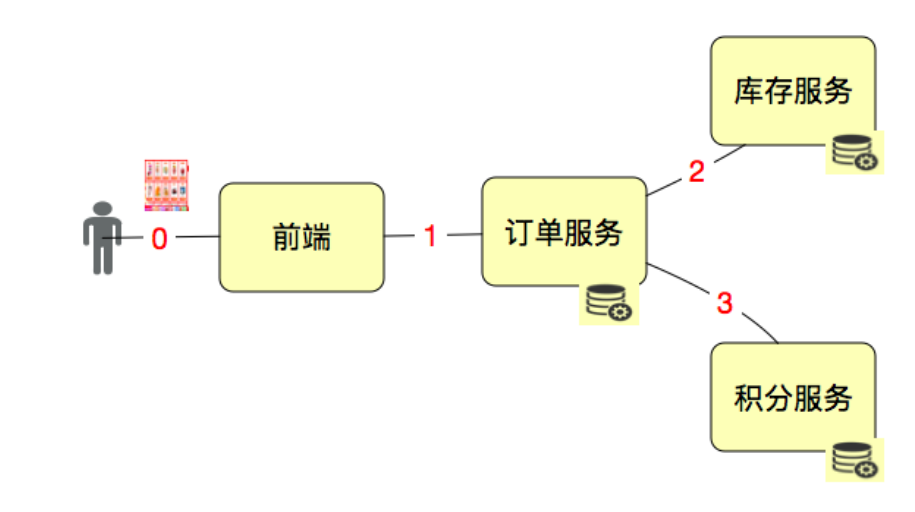
以上图为例,说明TPS中T的定义取决于场景的目标和T的作用。如果我们要单独测试接口 1、2、3,那 T 就是接口级的;如果我们要从用户的角度来下一个订单,那 1、2、3 应该在一个 T 中,这就是业务级的了。
接口级脚本:
| 事务 start(接口1) | 事务 start(接口2) | 事务 start(接口3) |
| 接口1 脚本 | 接口2 脚本 | 接口3 脚本 |
|
事务end(接口1) |
事务 end(接口2) | 事务end(接口3) |
业务级接口层脚本(就是用接口拼接出一个完整的业务流):
| 事务 start(业务A) |
| 接口1脚本 - 接口2(同步调用) |
| 接口1脚本 - 接口3(异步调用) |
| 事务 end(业务A) |
用户级脚本:
| 事务 start(业务A) |
| 点击0 - 接口1脚本 - 接口2(同步调用) |
| 点击0 - 接口1脚本 - 接口3(异步调用 |
| 事务 end(业务A) |
你要创建什么级别的事务,完全取决于测试的目的是什么。一般情况下,会按从上到下的顺序一一地来测试,这样路径清晰地执行是容易定位问题的。
QPS,如果它描述的是数据库中的 Query Per Second,从上面的示意图中来看, 其实描述的是服务后面接的数据库中 SQL 的每秒执行条数。如果描述的是前端的每秒查询数,那就不包括插入、更新、删除操作了。显然这样的指标用来描述系统整体的性能是不够 全面的。所以不建议用 QPS 来描述系统整体的性能,以免产生误解。
在性能中,还有一个重要的概念就是响应时间(Response Time),指从客户端发起请求开启,到客户端接收到结果的总时间,包括服务器处理时间与网络传输时间。其中响应时间还可以根据服务架构使用链路监控工具和一些Metrics工具来分析在一个请求链路上,每个节点消耗的时间和请求的持续时间。对于响应时间来说,时间的拆分定位是性能瓶颈定位分析中非常重要的一节。
1.3压力工具中的线程数和用户数与 TPS
并发是需要具体的指标来承载的。你可以说,我的并发是1000TPS,或者1000RPS,或者1000HPS,这都随便去定义。但是在一个具体的项目中,当你说到并发1000这样没有单位的词时,一定要让大家都能理解这是什么。
因为用户有了业务含义,所以有些人认为一个系统如果有1万个用户在线,那就应该测试1万的并发线程,这种逻辑是不技术的。通常,会对在线的用户做并发度的分析,在很多业务中,并发度都会低于5%,甚至低于1%。
拿5%来计算,就是10000用户x5%=500(TPS),注意哦,这里是TPS,而不是并发线程数。如果这时响应时间是100ms,那显然并发线程数是500TPS/(1000ms/100ms)=50(并发线程)。
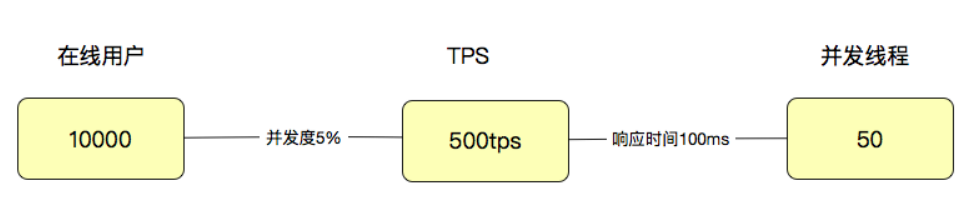
但是!响应时间肯定不会一直都是100ms的。所以通常情况下,上面的这个比例都不会固定,而是随着并发线程数的增加,会出现趋势上的关系。 所以,在性能分析中,要注意观察:趋势!
2.并发与用户数
绝对并发指的是同一时刻的并发数;相对并发指的是一个时间段内发生的事情。
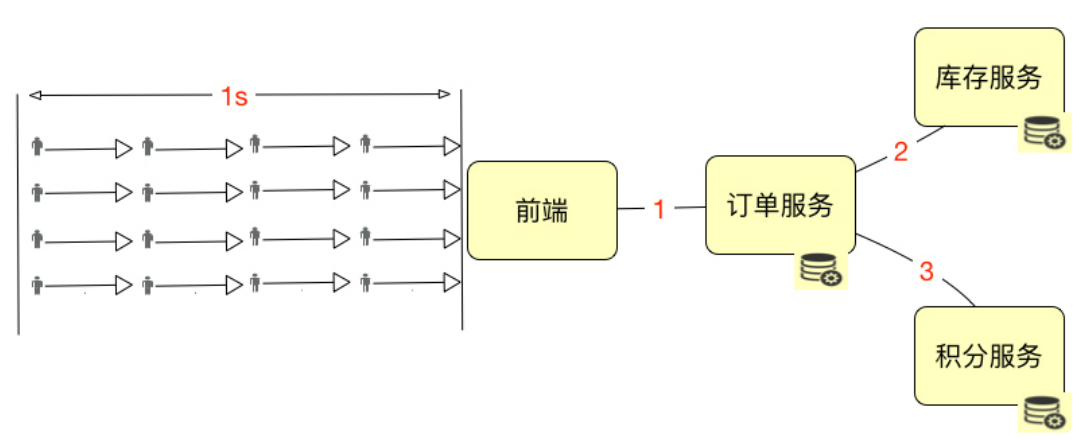
假设上图中的这些小人是严格按照这个逻辑到达系统的,那显然,系统的绝对并发用户 数是 4。如果描述 1 秒内的并发用户数,那就是 16。
但是,在实际的系统中,用户通常是这样分配的:
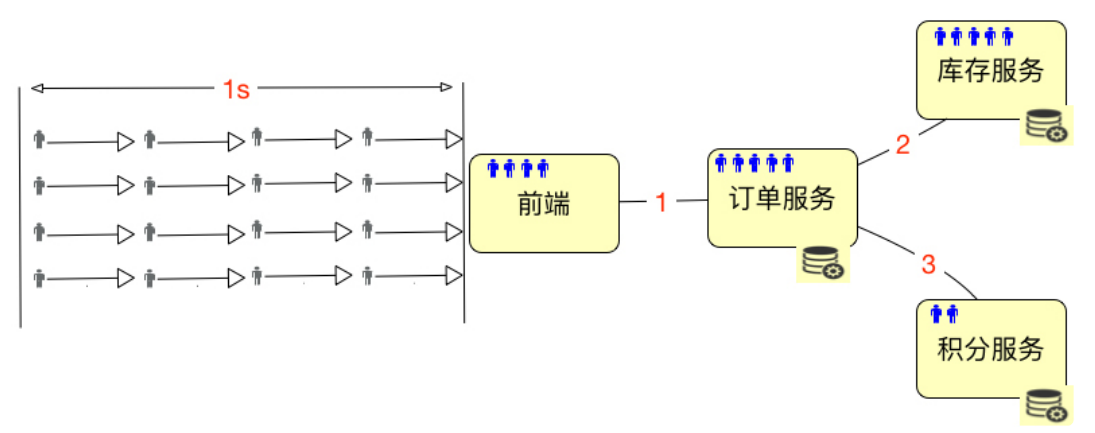
也就是说,这些用户会分布在系统中不同的服务、网络等对象中。这时候”绝对并发“这个 概念就难描述了,很难说是哪部分的绝对并发呢?所以“绝对并发”这个概念,不管是用来描述硬件细化的层面,还是用来描述业务逻辑的层面,都是没什么意义的。
我们只要描述并发就好了,不用有“相对”和“绝对”的概念,这样可以简化沟通,也不会出错。
如何来描述上面的并发用户数呢?建议用 TPS 来承载“并发”这个概念。并发数是 16TPS,就是 1 秒内整个系统处理了 16 个事务
2.1在线用户数与并发用户数
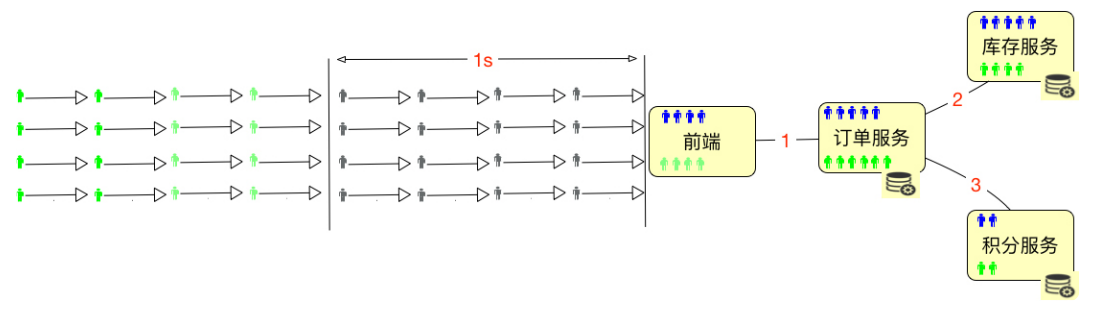
如上图所示,总共有 32 个用户进入了系统,但是绿色的用户并没有任何动作,那么显然, 在线用户数是 32 个,并发用户数是 16 个,这时的并发度就是 50%。
但在一个系统中,通常都是下面这个样子的。
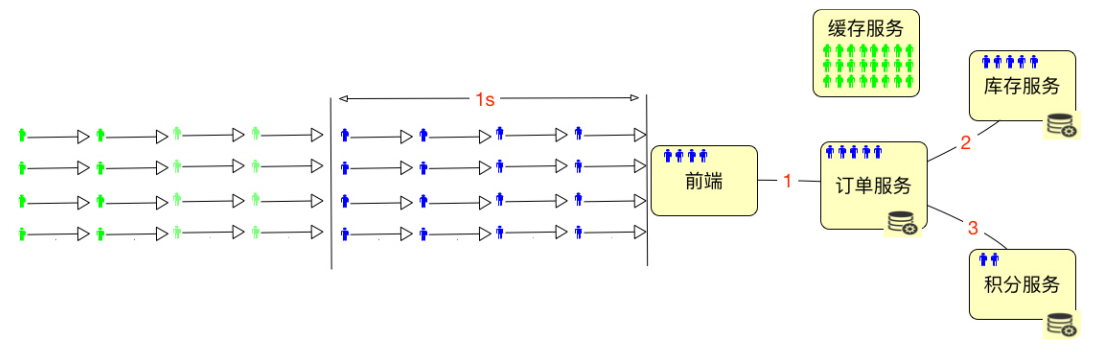
为了能 hold 住更多的用户,通常都会把一些数据放到 Redis 这样的缓存服务器中。所以在线用户数怎么算呢,如果仅从上面这种简单的图来看的话,其实就是缓存服务器能有多大,能 hold 住多少用户需要的数据。所以我们要是想知道在线的最大的用户数是多少,对于一个设计逻辑清晰的系统来说,不用测试就可以知道,直接拿缓存的内存来算就可以了。但是在实际的项目中,还会将超时放在一起来考虑。
要想计算并发用户和在线用户数之间的关系,都需要有并发度。

通过这个示例图可以得出:
- 如果有 10000 个在线用户数,同时并发度是 1%,那显然并发用户数就是 100。
- 如果每个线程的 20TPS,显然只需要 5 个线程就够了(请注意,这里说的线程指的是压 力机的线程数)。
- 这时对 Server 来说,它处理的就是 100TPS,平均响应时间是 50ms。50ms 就是根据 1000ms/20TPS 得来的(请注意,这里说的平均响应时间会在一个区间内浮动,但只要 TPS 不变,这个平均响应时间就不会变)。
- 如果有两个 Server 线程来处理,那么一个线程就是 50TPS,这个很直接吧。 请注意,这里有一个转换的细节,那就是并发用户数到压力机的并发线程数。
而通常说的“并发”这个词,依赖 TPS 来承载的时候,指的都是 Server 端的处理能力,并不是压力工具上的并发线程数。在上面的例子中,说的并发就是指服务器上 100TPS 的处理能力,而不是指 5 个压力机的并发线程数。
TPS = 1000ms/响应时间(单位ms) * 压力机线程数
对于压力工具来说,只要不报错,我们就关心 TPS 和响应时间就可以了,因为 TPS 反应出来的是和服务器对应的处理能力,至少压力线程数是多少,并不关键。
服务端有多少个线程,就可以支持多少个压力机上的并发线程。但是这取决于 TPS 有多少,如果服务端处理的快,那压力机的并发线程就可以更多一些。这个逻辑看似很合理,但是通常服务端都是有业务逻辑的,既然有业务逻辑,显然不会比压力机快。 应该说,服务端需要更多的线程来处理压力机线程发过来的请求。所以我们用几台压力机就可以压几十台服务端的性能了。
- 通常所说的并发都是指服务端的并发,而不是指压力机上的并发线程数,因为服务端的并发才是服务器的处理能力。
- 性能中常说的并发,是用 TPS 这样的概念来承载具体数值的。
- 压力工具中的线程数、响应时间和 TPS 之间是有对应关系的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通