

Doris数据模型简单介绍
一、基本概念
在 Doris 中,数据以表(Table)的形式进行逻辑上的描述。 一张表包括行(Row)和列(Column)。Row 即用户的一行数据。Column 用于描述一行数据中不同的字段。Column 可以分为两大类:Key 和 Value。Doris的key列是建表语句中指定的列,建表语句中的关键字'unique key'或'aggregate key'或'duplicate key'后面的列就是 Key 列,除了 Key 列剩下的就是 Value 列。
Doris 的数据模型主要分为3类:
- Aggregate
- Unique
- Duplicate
二、Aggregate 模型(聚合模型)
1、导入数据聚合
先看一个创建表结构的语句:

CREATE TABLE IF NOT EXISTS demo.example_tbl ( `user_id` LARGEINT NOT NULL COMMENT "用户id", `date` DATE NOT NULL COMMENT "数据灌入日期时间", `city` VARCHAR(20) COMMENT "用户所在城市", `age` SMALLINT COMMENT "用户年龄", `sex` TINYINT COMMENT "用户性别", `last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间", `cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费", `max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间", `min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间" ) AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`) DISTRIBUTED BY HASH(`user_id`) BUCKETS 1 PROPERTIES ( "replication_allocation" = "tag.location.default: 1" );
表中的列按照是否设置了 AggregationType,分为 Key (维度列) 和 Value(指标列)。没有设置 AggregationType 的,如 user_id、date、age ... 等称为 Key,而设置了 AggregationType 的称为 Value。
数据库中desc查看表详情是这样展示的。

当我们导入数据时,对于 Key 列相同的行会聚合成一行,而 Value 列会按照设置的 AggregationType 进行聚合。 AggregationType 目前有以下四种聚合方式:
- SUM:求和,多行的 Value 进行累加。
- REPLACE:替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。
- MAX:保留最大值。
- MIN:保留最小值。
测试一下,导入下面的数据在查看查询结果。
insert into demo.example_tbl values (10000,"2017-10-01","北京",20,0,"2017-10-01 06:00:00",20,10,10), (10000,"2017-10-01","北京",20,0,"2017-10-01 07:00:00",15,2,2), (10001,"2017-10-01","北京",30,1,"2017-10-01 17:05:45",2,22,22), (10002,"2017-10-02","上海",20,1,"2017-10-02 12:59:12",200,5,5), (10003,"2017-10-02","广州",32,0,"2017-10-02 11:20:00",30,11,11), (10004,"2017-10-01","深圳",35,0,"2017-10-01 10:00:15",100,3,3), (10004,"2017-10-03","深圳",35,0,"2017-10-03 10:20:22",11,6,6);

可以看到,用户 10000 只剩下了一行聚合后的数据。而其余用户的数据和原始数据保持一致。这里先解释下用户 10000 聚合后的数据:前5列没有变化,从第6列 last_visit_date 开始:
-
2017-10-01 07:00:00:因为last_visit_date列的聚合方式为 REPLACE,所以2017-10-01 07:00:00替换了2017-10-01 06:00:00保存了下来。注:在同一个导入批次中的数据,对于 REPLACE 这种聚合方式,替换顺序不做保证。如在这个例子中,最终保存下来的,也有可能是
2017-10-01 06:00:00。而对于不同导入批次中的数据,可以保证,后一批次的数据会替换前一批次。 -
35:因为cost列的聚合类型为 SUM,所以由 20 + 15 累加获得 35。 -
10:因为max_dwell_time列的聚合类型为 MAX,所以 10 和 2 取最大值,获得 10。 -
2:因为min_dwell_time列的聚合类型为 MIN,所以 10 和 2 取最小值,获得 2。
经过聚合,Doris 中最终只会存储聚合后的数据。换句话说,即明细数据会丢失,用户不能够再查询到聚合前的明细数据了。
2、导入数据与已有数据聚合
在example_tbl表中插入以下新数据,在查询数据。可以看到,用户 10004 的已有数据和新导入的数据发生了聚合。同时新增了 10005 用户的数据。
insert into demo.example_tbl values (10004,"2017-10-03","深圳",35,0,"2017-10-03 11:22:00",44,19,19), (10005,"2017-10-03","长沙",29,1,"2017-10-03 18:11:02",3,1,1);
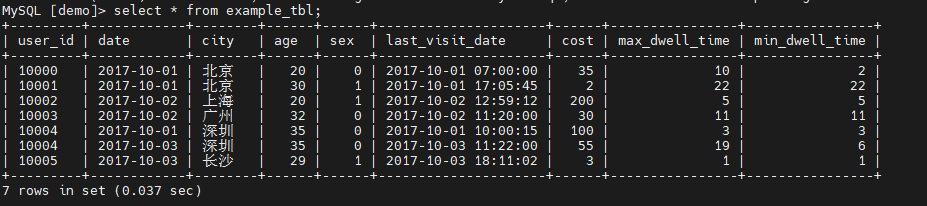
3、保留明细数据
创建一个如下结构的表:
CREATE TABLE IF NOT EXISTS demo.example_tbq
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
导入一下数据,后查询结果,可以看到存储的数据,和导入数据完全一样,没有发生任何聚合。这是因为,这批数据中,因为加入了timestamp列,所有行的Key都不完全相同。也就是说,只要保证导入的数据中,每一行的Key都不完全相同,那么即使在聚合模型下,Doris 也可以保存完整的明细数据。
insert into demo.example_tbq values
(10000,"2017-10-01","2017-10-01 08:00:05","北京",20,0,"2017-10-01 06:00:00",20,10,10),
(10000,"2017-10-01","2017-10-01 09:00:05","北京",20,0,"2017-10-01 07:00:00",15,2,2),
(10001,"2017-10-01","2017-10-01 18:12:10","北京",30,1,"2017-10-01 17:05:45",2,22,22),
(10002,"2017-10-02","2017-10-02 13:10:00","上海",20,1,"2017-10-02 12:59:12",200,5,5),
(10003,"2017-10-02","2017-10-02 13:15:00","广州",32,0,"2017-10-02 11:20:00",30,11,11),
(10004,"2017-10-01","2017-10-01 12:12:48","深圳",35,0,"2017-10-01 10:00:15",100,3,3),
(10004,"2017-10-03","2017-10-03 12:38:20","深圳",35,0,"2017-10-03 10:20:22",11,6,6);

三、Unique模型
如何保证 Key 的唯一性,即如何获得 Primary Key 唯一性约束,使用Unique 数据模型。Unique 数据模型在1.2版本之前是聚合模型的一个特例。由于聚合模型的实现方式是读时合并(merge on read),因此在一些聚合查询上性能不佳,在1.2版本我们引入了Unique模型新的实现方式,写时合并(merge on write),通过在写入时做一些额外的工作,实现了最优的查询性能。
1、读时合并(与聚合模型相同的实现方式)
这是一个典型的用户基础信息表。这类数据没有聚合需求,只需保证主键唯一性。(这里的主键为 user_id + username)
CREATE TABLE IF NOT EXISTS example_db.example_tbl ( `user_id` LARGEINT NOT NULL COMMENT "用户id", `username` VARCHAR(50) NOT NULL COMMENT "用户昵称", `city` VARCHAR(20) COMMENT "用户所在城市", `age` SMALLINT COMMENT "用户年龄", `sex` TINYINT COMMENT "用户性别", `phone` LARGEINT COMMENT "用户电话", `address` VARCHAR(500) COMMENT "用户地址", `register_time` DATETIME COMMENT "用户注册时间" ) UNIQUE KEY(`user_id`, `username`) DISTRIBUTED BY HASH(`user_id`) BUCKETS 1 PROPERTIES ( "replication_allocation" = "tag.location.default: 1" );
而这个表结构,完全同等于以下使用聚合模型描述的表结构,即Unique 模型的读时合并实现完全可以用聚合模型中的 REPLACE 方式替代
CREATE TABLE IF NOT EXISTS example_db.example_tbl ( `user_id` LARGEINT NOT NULL COMMENT "用户id", `username` VARCHAR(50) NOT NULL COMMENT "用户昵称", `city` VARCHAR(20) REPLACE COMMENT "用户所在城市", `age` SMALLINT REPLACE COMMENT "用户年龄", `sex` TINYINT REPLACE COMMENT "用户性别", `phone` LARGEINT REPLACE COMMENT "用户电话", `address` VARCHAR(500) REPLACE COMMENT "用户地址", `register_time` DATETIME REPLACE COMMENT "用户注册时间" ) AGGREGATE KEY(`user_id`, `username`) DISTRIBUTED BY HASH(`user_id`) BUCKETS 1 PROPERTIES ( "replication_allocation" = "tag.location.default: 1" );
2、写时合并
Unqiue模型的写时合并实现,与聚合模型就是完全不同的两种模型了,查询性能更接近于duplicate模型,在有主键约束需求的场景上相比聚合模型有较大的查询性能优势,尤其是在聚合查询以及需要用索引过滤大量数据的查询中。
其建表语句为:
CREATE TABLE IF NOT EXISTS example_db.example_tbl ( `user_id` LARGEINT NOT NULL COMMENT "用户id", `username` VARCHAR(50) NOT NULL COMMENT "用户昵称", `city` VARCHAR(20) COMMENT "用户所在城市", `age` SMALLINT COMMENT "用户年龄", `sex` TINYINT COMMENT "用户性别", `phone` LARGEINT COMMENT "用户电话", `address` VARCHAR(500) COMMENT "用户地址", `register_time` DATETIME COMMENT "用户注册时间" ) UNIQUE KEY(`user_id`, `username`) DISTRIBUTED BY HASH(`user_id`) BUCKETS 1 PROPERTIES ( "replication_allocation" = "tag.location.default: 1", "enable_unique_key_merge_on_write" = "true" );
注意:新的Merge-on-write实现默认关闭,且只能在建表时通过指定property的方式打开。
在开启了写时合并选项的Unique表上,数据在导入阶段就会去将被覆盖和被更新的数据进行标记删除,同时将新的数据写入新的文件。在查询的时候,所有被标记删除的数据都会在文件级别被过滤掉,读取出来的数据就都是最新的数据,消除掉了读时合并中的数据聚合过程,并且能够在很多情况下支持多种谓词的下推。因此在许多场景都能带来比较大的性能提升,尤其是在有聚合查询的情况下。
四、Duplicate 模型
在某些多维分析场景下,数据既没有主键,也没有聚合需求。因此引入 Duplicate 数据模型来满足这类需求。
CREATE TABLE IF NOT EXISTS example_db.example_tbl ( `timestamp` DATETIME NOT NULL COMMENT "日志时间", `type` INT NOT NULL COMMENT "日志类型", `error_code` INT COMMENT "错误码", `error_msg` VARCHAR(1024) COMMENT "错误详细信息", `op_id` BIGINT COMMENT "负责人id", `op_time` DATETIME COMMENT "处理时间" ) DUPLICATE KEY(`timestamp`, `type`, `error_code`) DISTRIBUTED BY HASH(`type`) BUCKETS 1 PROPERTIES ( "replication_allocation" = "tag.location.default: 1" );
这种数据模型区别于 Aggregate 和 Unique 模型。数据完全按照导入文件中的数据进行存储,不会有任何聚合。即使两行数据完全相同,也都会保留。 而在建表语句中指定的 DUPLICATE KEY,只是用来指明底层数据按照那些列进行排序。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通