大文件排序
设想你有一个20GB的文件,每行一个字符串,说明如何对这个文件进行排序。
内存肯定没有20GB大,所以不可能采用传统排序法。但是可以将文件分成许多块,每块xMB,针对每个快各自进行排序,存回文件系统。
然后将这些块逐一合并,最终得到全部排好序的文件。
外排序的一个例子是外归并排序(External merge sort),它读入一些能放在内存内的数据量,在内存中排序后输出为一个顺串(即是内部数据有序的临时文件),处理完所有的数据后再进行归并。[1][2]比如,要对900MB的数据进行排序,但机器上只有100 MB的可用内存时,外归并排序按如下方法操作:
- 读入100 MB的数据至内存中,用某种常规方式(如快速排序、堆排序、归并排序等方法)在内存中完成排序。
将排序完成的数据写入磁盘。 - 重复步骤1和2直到所有的数据都存入了不同的100 MB的块(临时文件)中。在这个例子中,有900 MB数据,单个临时文件大小为100 MB,所以会产生9个临时文件。
- 读入每个临时文件(顺串)的前10 MB( = 100 MB / (9块 + 1))的数据放入内存中的输入缓冲区,最后的10 MB作为输出缓冲区。(实践中,将输入缓冲适当调小,而适当增大输出缓冲区能获得更好的效果。)
- 执行九路归并算法,将结果输出到输出缓冲区。一旦输出缓冲区满,将缓冲区中的数据写出至目标文件,清空缓冲区。一旦9个输入缓冲区中的一个变空,就从这个缓冲区关联的文件,读入下一个10M数据,除非这个文件已读完。这是“外归并排序”能在主存外完成排序的关键步骤 -- 因为“归并算法”(merge algorithm)对每一个大块只是顺序地做一轮访问(进行归并),每个大块不用完全载入主存。
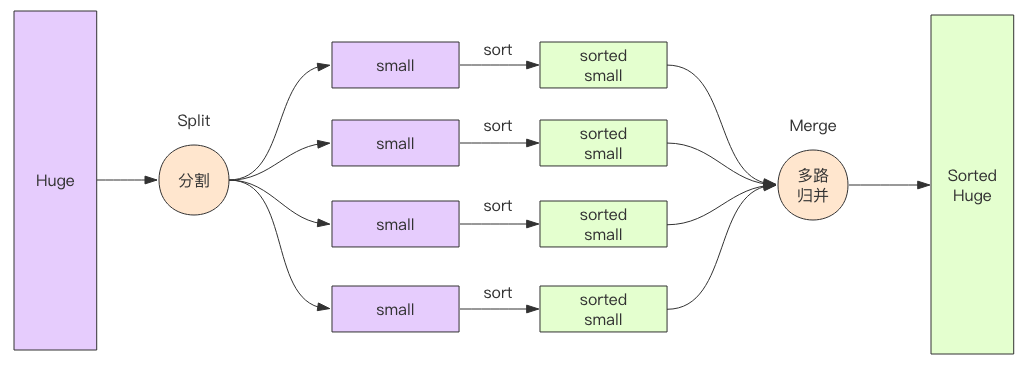
多路归并的思路主要是堆:
从 K 个序列中各取一个元素,并记录每个元素的来源数组,建立一个含 K 个元素的小根堆。此时堆顶就是最小的元素,取出堆顶元素,并从堆顶元素的来源序列中取下一个元素放入堆顶,然后向下调整。在向下调整过程中需要和其两个子结点比较,需要比较 2 次。
__EOF__
作 者:wsl-hitsz
出 处:https://www.cnblogs.com/wsl-hitsz/p/17700479.html
关于博主:编程路上的小学生,热爱技术,喜欢专研。评论和私信会在第一时间回复。或者直接私信我。
版权声明:署名 - 非商业性使用 - 禁止演绎,协议普通文本 | 协议法律文本。
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2021-09-13 【转】Linux内存中的 buffer 和 cache 到底是个什么东东?