跳表的数据结构
调表的核心思想
跳表的核心思想是“剪枝”,具体是如下方式实现
如果是一个简单的链表,那么我们知道在链表中查找一个元素I的话,需要将整个链表遍历一次。

如果是说链表是排序的,并且节点中还存储了“跳跃”的指向后续节点的指针的话,那么在查找一个节点时,仅仅需要遍历N/2个节点即可。

从上图中已经可以看到"层"的出现使得时间复杂度降为原来的一半。
一次典型的调表查询
skiplist上的查找路径展示
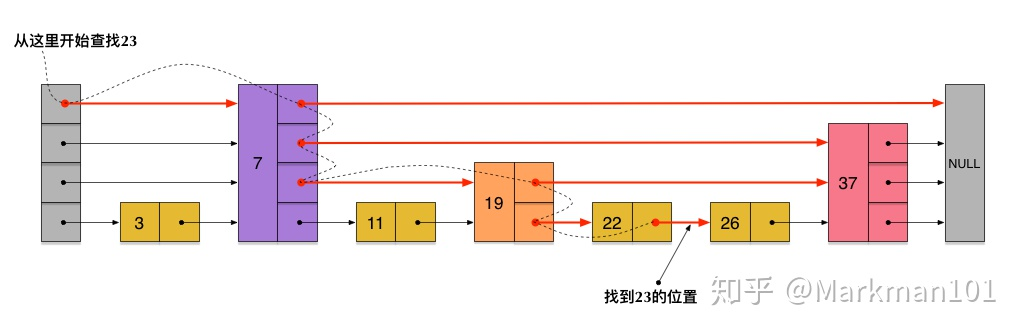
skiplist正是受这种多层链表的想法的启发而设计出来的。实际上,按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的1/P(redis中P为0.25),这样查找过程就非常类似于一个二分查找,使得查找的时间复杂度可以降低到O(log n)。
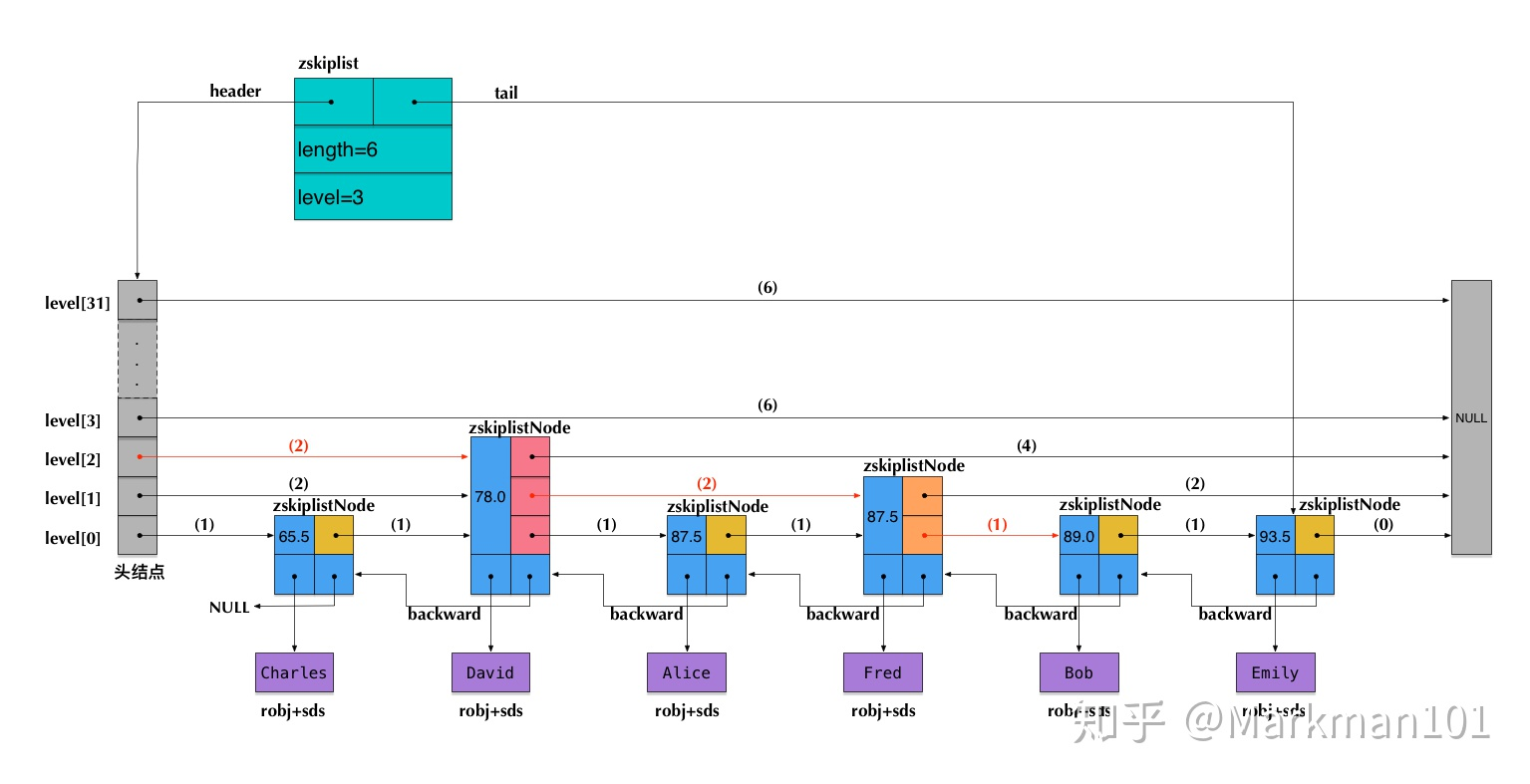
核心数据结构
#define ZSKIPLIST_MAXLEVEL 32 //最大层数
#define ZSKIPLIST_P 0.25 //P
typedef struct zskiplistNode {
robj *obj;
double score;
struct zskiplistNode *backward; //后向指针
struct zskiplistLevel {
struct zskiplistNode *forward;//每一层中的前向指针
unsigned int span;//x.level[i].span 表示节点x在第i层到其下一个节点需跳过的节点数。注:两个相邻节点span为1
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;//节点总数
int level;//总层数
} zskiplis