KMP !!终于看懂了
通过看一个老哥的 KMP 终于看明白了一些~
前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配。 这样可以使得,当出现字符串不匹配时,可以知道一部分之前已经匹配的文本内容,可以利用这些信息避免从头再去做匹配了。所以如何记录已经匹配的文本内容,是KMP的重点,也是next数组肩负的重任。
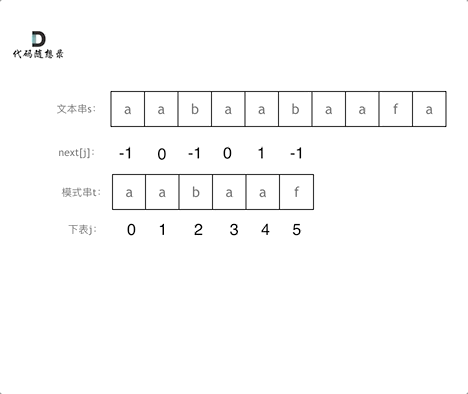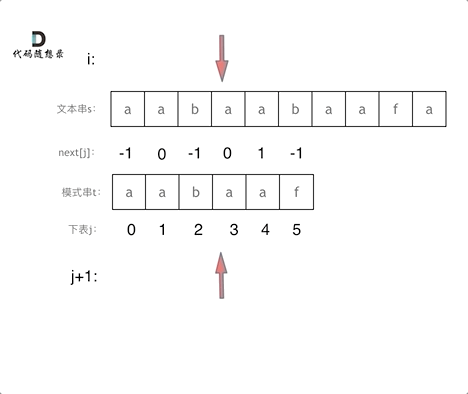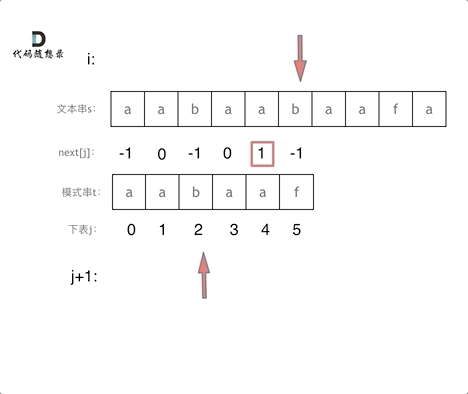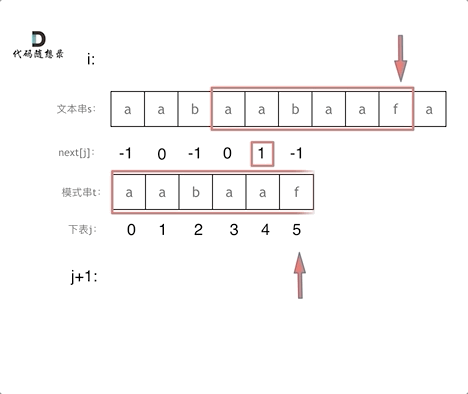
next 数组其实就是最长前后缀数组, 这里切记啊,后缀是啥意思!(之前我一直把这个后缀理解错了)
这个后缀其实与前缀一模一样,顺序也是从左往右的进行,我之前一直以为后缀的最初元素是在匹配字符串的最后以为,例如 "abba" 这种最长的公共前后缀就是"a"。长度为前5个字符的子串"aabaa",最长相同前后缀的长度为2,而不是5。
下面是做匹配的一个动画
构造next 数组其实分为三步:
- 初始化
- 处理前后缀不相同的情况
- 处理前后缀相同的情况
初始化
定义两个指针i和j,j指向前缀终止位置(严格来说是终止位置减一的位置),i指向后缀终止位置(与j同理)。
然后还要对next数组进行初始化赋值,如下:
int j = -1;
next[0] = j;
处理前后缀不相同的情况
因为j初始化为-1,那么i就从1开始,进行s[i] 与 s[j+1]的比较。
所以遍历模式串s的循环下表i 要从 1开始,代码如下:
for(int i = 1; i < s.size(); i++) {
如果 s[i] 与 s[j+1]不相同,也就是遇到 前后缀末尾不相同的情况,就要向前回溯。
怎么回溯呢?
next[j]就是记录着j(包括j)之前的子串的相同前后缀的长度。
那么 s[i] 与 s[j+1] 不相同,就要找 j+1前一个元素在next数组里的值(就是next[j])。
所以,处理前后缀不相同的情况代码如下:
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
j = next[j]; // 向前回溯
}
处理前后缀相同的情况
如果s[i] 与 s[j + 1] 相同,那么就同时向后移动i 和j 说明找到了相同的前后缀,同时还要将j(前缀的长度)赋给next[i], 因为next[i]要记录相同前后缀的长度。
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
}
next[i] = j;
最后整体构建next数组的函数代码如下:
void getNext(int* next, const string& s){
int j = -1;
next[0] = j;
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
j = next[j]; // 向前回溯
}
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
}
next[i] = j; // 将j(前缀的长度)赋给next[i]
}
}
