
课后作业3
https://gitee.com/wsj0823/homework_3
2017*****7035
王诗佳
2.
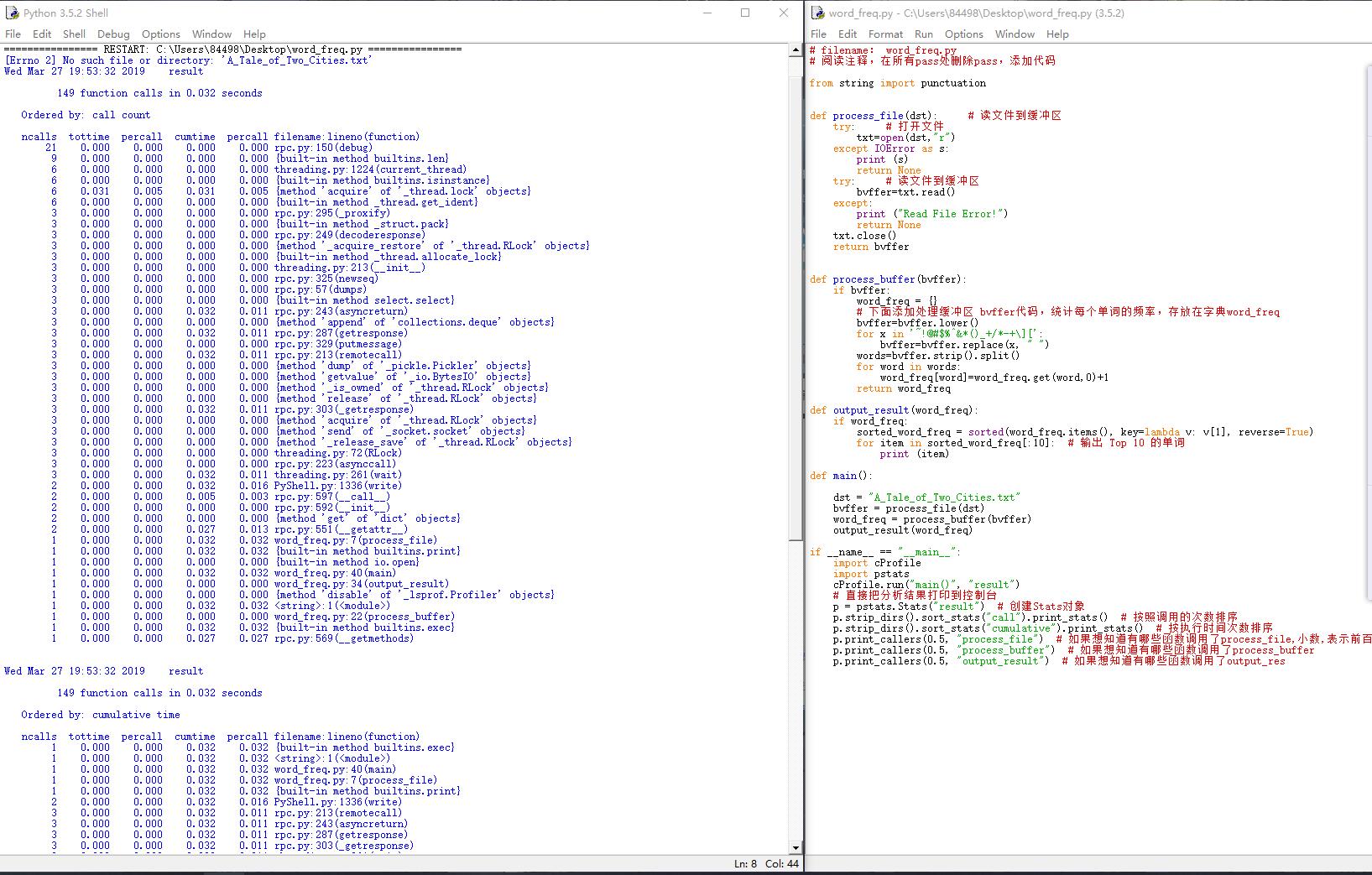
from string import punctuation def process_file(dst): # 读文件到缓冲区 try: # 打开文件 txt=open(dst,"r") except IOError as s: print (s) return None try: # 读文件到缓冲区 bvffer=txt.read() except: print ("Read File Error!") return None txt.close() return bvffer def process_buffer(bvffer): if bvffer: word_freq = {} # 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq bvffer=bvffer.lower() for x in '~!@#$%^&*()_+/*-+\][': bvffer=bvffer.replace(x, " ") words=bvffer.strip().split() for word in words: word_freq[word]=word_freq.get(word,0)+1 return word_freq def output_result(word_freq): if word_freq: sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) for item in sorted_word_freq[:10]: # 输出 Top 10 的单词 print (item) def main(): dst = "A_Tale_of_Two_Cities.txt" bvffer = process_file(dst) word_freq = process_buffer(bvffer) output_result(word_freq) if __name__ == "__main__": import cProfile import pstats cProfile.run("main()", "result") # 直接把分析结果打印到控制台 p = pstats.Stats("result") # 创建Stats对象 p.strip_dirs().sort_stats("call").print_stats() # 按照调用的次数排序 p.strip_dirs().sort_stats("cumulative").print_stats() # 按执行时间次数排序 p.print_callers(0.5, "process_file") # 如果想知道有哪些函数调用了process_file,小数,表示前百分之几的函数信息 p.print_callers(0.5, "process_buffer") # 如果想知道有哪些函数调用了process_buffer p.print_callers(0.5, "output_result") # 如果想知道有哪些函数调用了output_res
3.运行结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号