摘要:
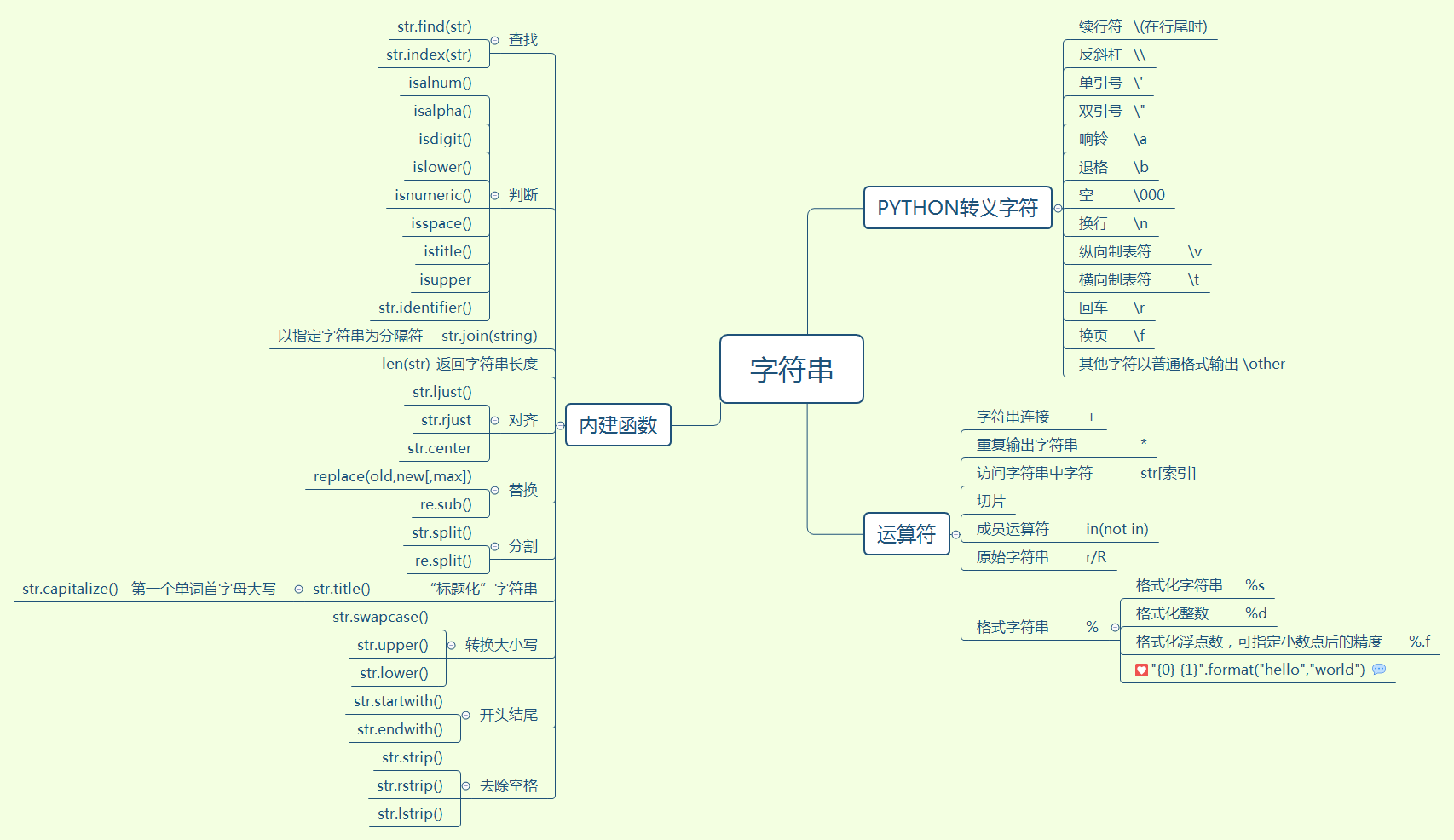 阅读全文
posted @ 2020-04-20 12:34
wsilj
阅读(117)
评论(0)
推荐(0)
摘要:
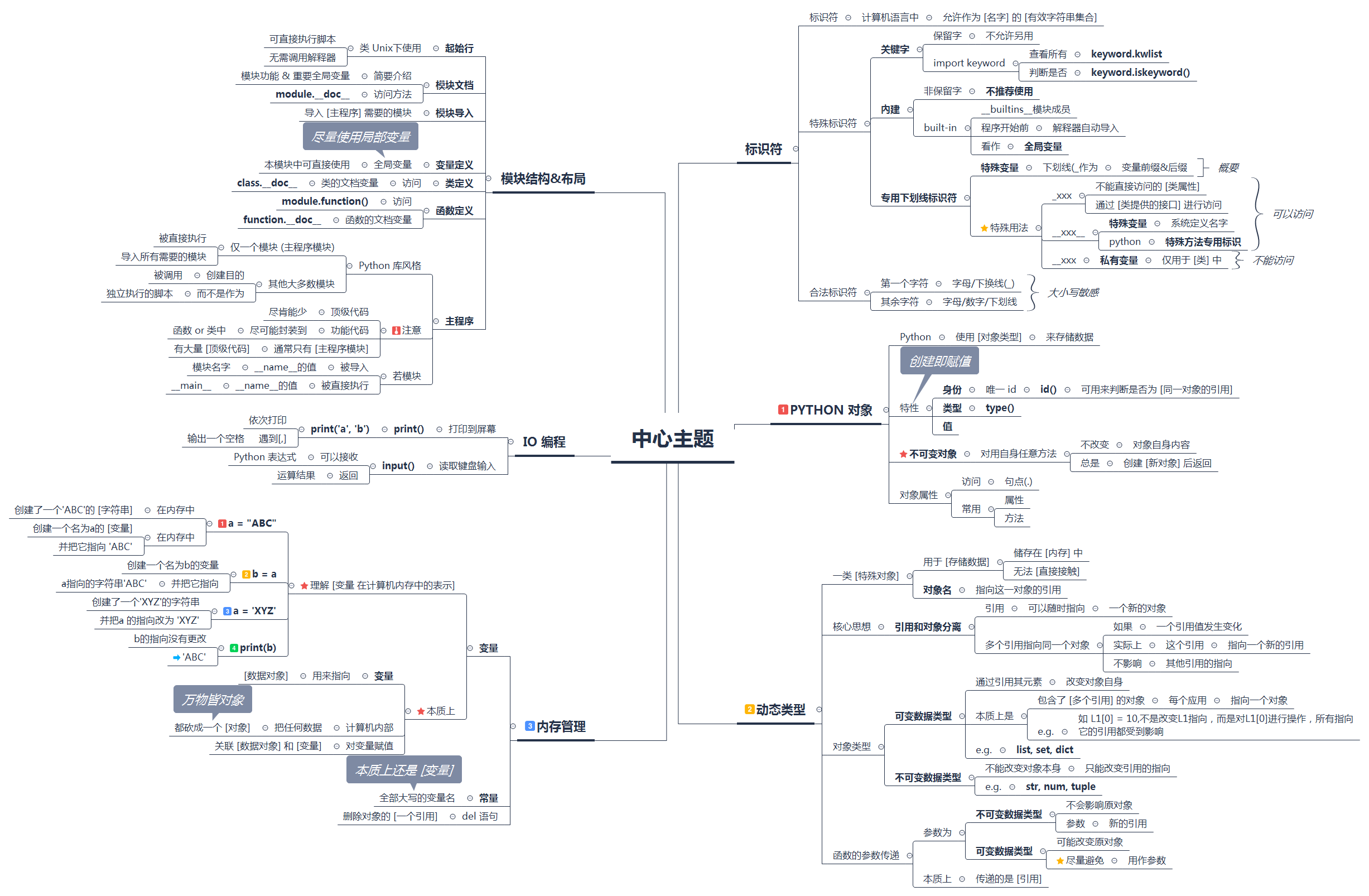 阅读全文
posted @ 2020-04-20 12:32
wsilj
阅读(114)
评论(0)
推荐(0)
摘要:
01. 查找文件 find 命令功能非常强大,通常用来在 特定的目录下 搜索 符合条件的文件 | 序号 | 命令 | 作用 | | : | : | : | | 01 | find [路径] name " .py" | 查找指定路径下拓展名是 .py 的文件,包括子目录 | 如果省略路径,表示在当前文 阅读全文
posted @ 2020-04-20 11:32
wsilj
阅读(172)
评论(0)
推荐(0)
摘要:
01. 时间和日期 | 序号 | 命令 | 作用 | | : | : | : | | 01 | date | 查看系统时间 | | 02 | cal | calendar 查看日历, y 选项可以查看一年的日历 | 02. 磁盘信息 | 序号 | 命令 | 作用 | | : | : | : | | 阅读全文
posted @ 2020-04-20 11:06
wsilj
阅读(121)
评论(0)
推荐(0)
摘要:
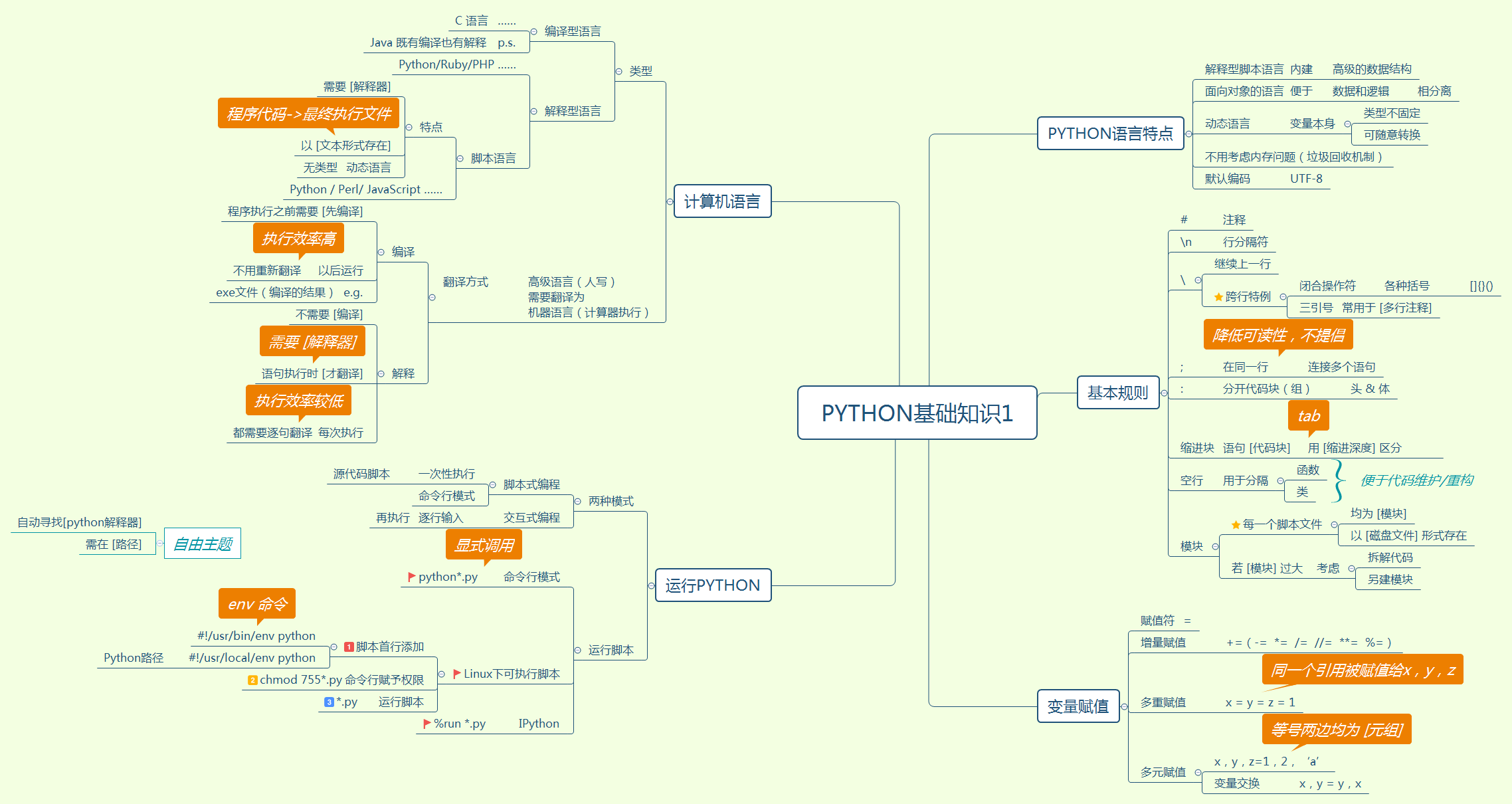 阅读全文
posted @ 2020-04-20 10:52
wsilj
阅读(110)
评论(0)
推荐(0)
摘要:
正则表达式 P = re.compile(regex, re.S) P.findall("str") P.sub("_", "str") re.findall(regex, "str") re.sub(regex,"_", str) 原始字符串r 在正则中忽略转义带来的影响 re.findall(" 阅读全文
posted @ 2020-04-20 10:47
wsilj
阅读(122)
评论(0)
推荐(0)
摘要:
定位js 使用chrome eventlistener search all file中所有关键词 分析js 添加断点的方式,浏览器会在断点处暂停 console中尝试js的执行结果 requests小技巧 requests.utils.dict_from_cookiejar cookie转化为字典 阅读全文
posted @ 2020-04-20 10:16
wsilj
阅读(100)
评论(0)
推荐(0)
摘要:
headers 形式 字典 User Agent,Cookies 使用User Agent能够模拟浏览器 如果因为参数问题爬取不到数据,添加更多参数 params 形式 字典 键是=前面的内容,值是=后面的内容 字符串格式化:'wenshao{}'.format('dashuabi') post 发 阅读全文
posted @ 2020-04-20 10:13
wsilj
阅读(95)
评论(0)
推荐(0)
摘要:
html 爬虫基础 概念 模拟浏览器发送网络请求,获取响应 分类 通用爬虫 搜索引擎的爬虫,面对整个互联网上所有的网站 聚焦爬虫 针对特定网站的爬虫 分类标准:爬虫爬取的范围 流程 1.url 2.发送请求,获取响应 (提取url地址,发送下一次请求) 3.提取数据 保存 rebots协议 道德层面 阅读全文
posted @ 2020-04-20 00:25
wsilj
阅读(162)
评论(0)
推荐(0)
 浙公网安备 33010602011771号
浙公网安备 33010602011771号