
day01(跳过github登录、requests请求库)
什么是爬虫?
爬虫就是爬取数据
什么是数据?
电商平台的商品信息、12306票务信息、股票证券投资信息等
requests请求库的安装
在cmd窗口中输入python,然后输入 pip3 install requests
在检查网页的Network的Headers中各个标识的涵义
Request URL:https://www.baidu.com/ (请求url)
Request Method:GET (请求方式)
Status Code:200 OK (响应状态码)
Response Headers (提交到服务器的数据头)
Cookie (用户信息)
User-Agent (用户代理)
import time
import requests
import re
# 发送请求
def get_page(url):
response = requests.get(url)
return response
# 解析数据
def parse_index(html):
# findall匹配所有
# re.findall('正则匹配规则','匹配文本','匹配模式')
# re.S:对全部文本进行搜素匹配
detail_urls = re.findall('<div class="items"><a class="imglink" href="(.*?)"',
html,re.S)
return detail_urls
# 解析详情页
def parse_detail(html):
movie_url = re.findall('<source src="(.*?)">',html,re.S)
if movie_url:
return movie_url[0]
import uuid
# 保存数据
# uuid.uuid4()根据时间戳生成世界上唯一的字符串
def save_video(content):
with open(f'{uuid.uuid4()}.mp4','wb') as f :
f.write(content)
print("下载完毕!!")
# main + 回车键
if __name__ == '__main__':
for line in range(6):
url = f'http://www.xiaohuar.com/list-3-{line}.html'
# 发送请求
response = get_page(url)
print(response)
# 返回响应状态码
print(response.status_code)
# 返回响应文本
print(response.text)
# 解析主页页面
detail_urls = parse_index(response.text)
# 循环遍历详情页url
for detail_url in detail_urls:
# 往每一个详情页发送请求
detail_res=get_page(detail_url)
# 解析详情页获取视频url
movie_url = parse_detail(detail_res.text)
# 判断视频url是否存在
if movie_url:
print(movie_url)
# 往视频url发送请求获取视频二进制流
movie_res = get_page(movie_url)
# 把视频的二进制流传给save_video函数去保存到本地
save_video(movie_res.content)

2.Github
2.1 只有POST请求才会有请求体
2.2 在Network-->login--->Response-->Ctrl+F 然后就可以在下列搜索框中输入要查找的东西
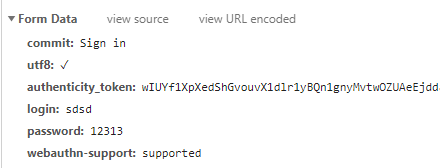
2.3请求体:
第一步:解析并提取token字符串
import requests import re login_url='https://github.com/login' # login页面的请求头信息 login_header={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'} login_res=requests.get(url=login_url,headers=login_header) # print(login_res.text) # 解析并提取token字符串 authenticity_token = re.findall('<input type="hidden" name="authenticity_token" value="(.*?)" />', login_res.text, re.S )[0] print(authenticity_token) login_cookies = login_res.cookies.get_dict()
实验结果:

第二步:登录
session_url = 'https://github.com/session' session_headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'} form_data={ "commit":"Sign in", "utf8":"√", "authenticity_token":authenticity_token, "login":"*******", "password":"********", "webauthn-support":"supported" } session_res=requests.post(url=session_url,headers=session_headers, cookies=login_cookies,data=form_data) with open('github1.html','w',encoding='utf-8') as f: f.write(session_res.text)
实验结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号