





摘要:
 Python调用有道api进行翻译 阅读全文
Python调用有道api进行翻译 阅读全文
Python调用有道api进行翻译 阅读全文
posted @ 2021-07-12 12:46
戈小戈
阅读(155)
评论(0)
推荐(0)
摘要:
解决Python写入CSV后中文乱码问题 阅读全文
posted @ 2021-07-12 12:44
戈小戈
阅读(88)
评论(0)
推荐(0)
摘要:
解决Python运行报错:UnicodeDecodeError: 'gbk' codec can't decode byte 0xb0 in position 166: illegal multibyte sequence 阅读全文
posted @ 2021-07-12 12:37
戈小戈
阅读(355)
评论(0)
推荐(0)
摘要: 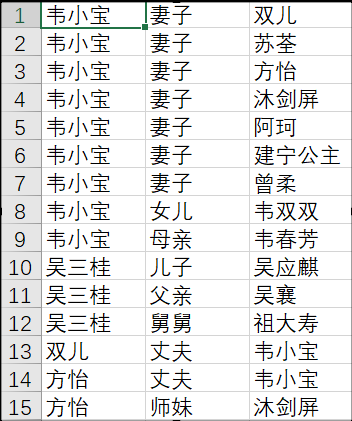 人工智能——爬取金庸小说人物关系
导语:人物数据来自于[金庸网](http://www.jinyongwuxia.cc/data/renwu/index.htm "金庸网"),为了便捷,人物姓名部分为手动复制到本地pachong.html文件中,最后的数据存在test2.csv中,人物关系数据来自百度百科。 阅读全文
人工智能——爬取金庸小说人物关系
导语:人物数据来自于[金庸网](http://www.jinyongwuxia.cc/data/renwu/index.htm "金庸网"),为了便捷,人物姓名部分为手动复制到本地pachong.html文件中,最后的数据存在test2.csv中,人物关系数据来自百度百科。 阅读全文
人工智能——爬取金庸小说人物关系
导语:人物数据来自于[金庸网](http://www.jinyongwuxia.cc/data/renwu/index.htm "金庸网"),为了便捷,人物姓名部分为手动复制到本地pachong.html文件中,最后的数据存在test2.csv中,人物关系数据来自百度百科。 阅读全文
posted @ 2021-07-12 12:30
戈小戈
阅读(513)
评论(0)
推荐(0)
摘要:  导语:人物数据来自于金庸网,为了便捷,人物姓名部分为手动复制到本地pachong.html文件中,最后的数据存在test.csv中,代码最后的停止3秒,非常有必要。 项目完整文件见 爬取金庸小说人物介绍 效果图: 代码: from bs4 import BeautifulSoup import ur 阅读全文
导语:人物数据来自于金庸网,为了便捷,人物姓名部分为手动复制到本地pachong.html文件中,最后的数据存在test.csv中,代码最后的停止3秒,非常有必要。 项目完整文件见 爬取金庸小说人物介绍 效果图: 代码: from bs4 import BeautifulSoup import ur 阅读全文
导语:人物数据来自于金庸网,为了便捷,人物姓名部分为手动复制到本地pachong.html文件中,最后的数据存在test.csv中,代码最后的停止3秒,非常有必要。 项目完整文件见 爬取金庸小说人物介绍 效果图: 代码: from bs4 import BeautifulSoup import ur 阅读全文
posted @ 2021-07-12 12:18
戈小戈
阅读(314)
评论(0)
推荐(0)
摘要: 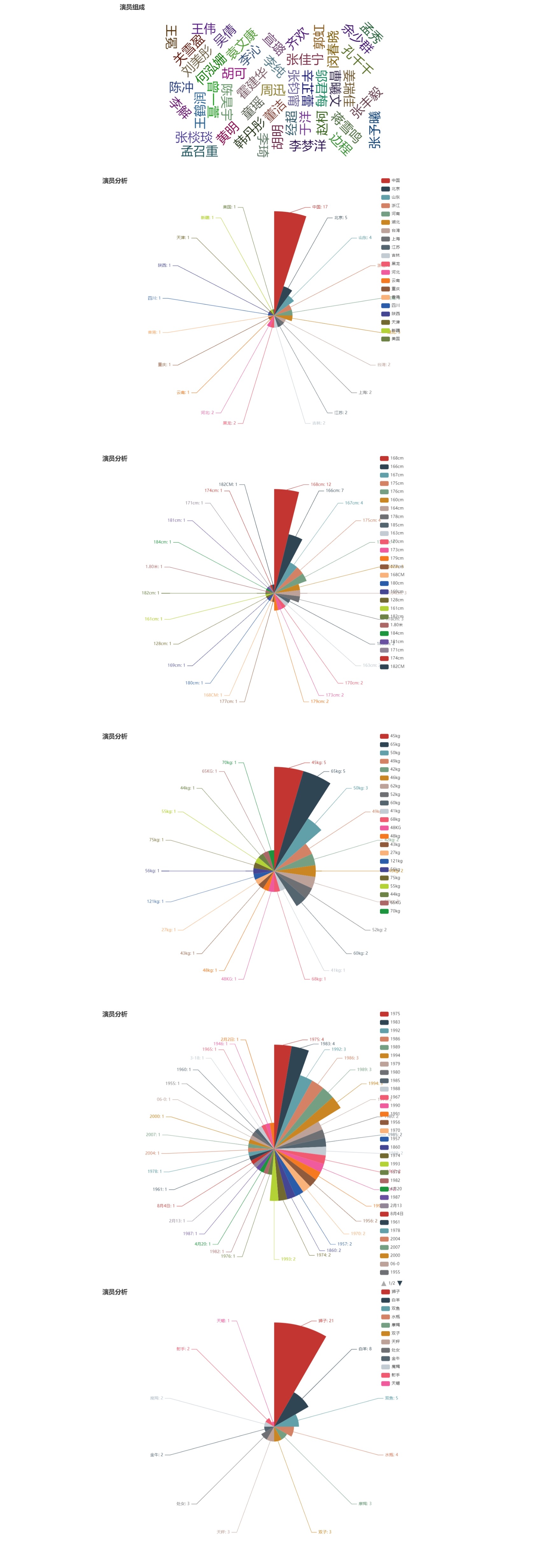 导语:自然语言处理可视化:利用爬虫抓取互联网上《如懿传》(或其他)电视剧中演员的部分数据,分析演员的姓名、星座、身高、体重和籍贯等信息,绘制词云和玫瑰图。 原题其实是《延禧攻略》,不过触类旁通后,我决定改成《如懿传》,此次爬取数据的网站为https://www.tvzn.com,在实际中发现此网站前 阅读全文
导语:自然语言处理可视化:利用爬虫抓取互联网上《如懿传》(或其他)电视剧中演员的部分数据,分析演员的姓名、星座、身高、体重和籍贯等信息,绘制词云和玫瑰图。 原题其实是《延禧攻略》,不过触类旁通后,我决定改成《如懿传》,此次爬取数据的网站为https://www.tvzn.com,在实际中发现此网站前 阅读全文
导语:自然语言处理可视化:利用爬虫抓取互联网上《如懿传》(或其他)电视剧中演员的部分数据,分析演员的姓名、星座、身高、体重和籍贯等信息,绘制词云和玫瑰图。 原题其实是《延禧攻略》,不过触类旁通后,我决定改成《如懿传》,此次爬取数据的网站为https://www.tvzn.com,在实际中发现此网站前 阅读全文
posted @ 2021-07-12 11:28
戈小戈
阅读(347)
评论(0)
推荐(0)
摘要: 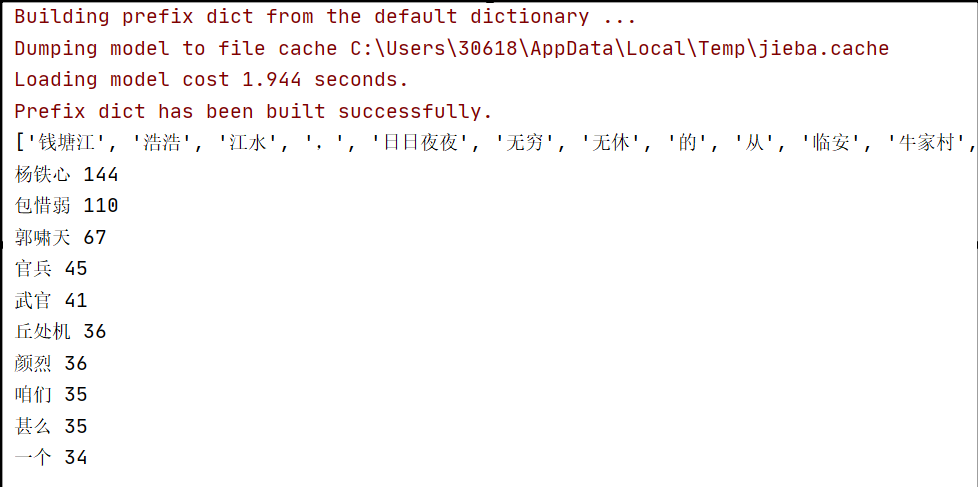 导语:给定一段文本,利用Jieba分词软件进行分词,分析Jieba分词的原理,展示样本分词效果,样本的topK(10)词:topK(10)是指排序前十,这里我使用了《射雕英雄传》第一回作为给定的文本,即代码中的eg.txt,项目完整文件见人工智能——jieba分词实例 效果图: 代码: # -*- 阅读全文
导语:给定一段文本,利用Jieba分词软件进行分词,分析Jieba分词的原理,展示样本分词效果,样本的topK(10)词:topK(10)是指排序前十,这里我使用了《射雕英雄传》第一回作为给定的文本,即代码中的eg.txt,项目完整文件见人工智能——jieba分词实例 效果图: 代码: # -*- 阅读全文
导语:给定一段文本,利用Jieba分词软件进行分词,分析Jieba分词的原理,展示样本分词效果,样本的topK(10)词:topK(10)是指排序前十,这里我使用了《射雕英雄传》第一回作为给定的文本,即代码中的eg.txt,项目完整文件见人工智能——jieba分词实例 效果图: 代码: # -*- 阅读全文
posted @ 2021-07-12 11:16
戈小戈
阅读(324)
评论(0)
推荐(0)
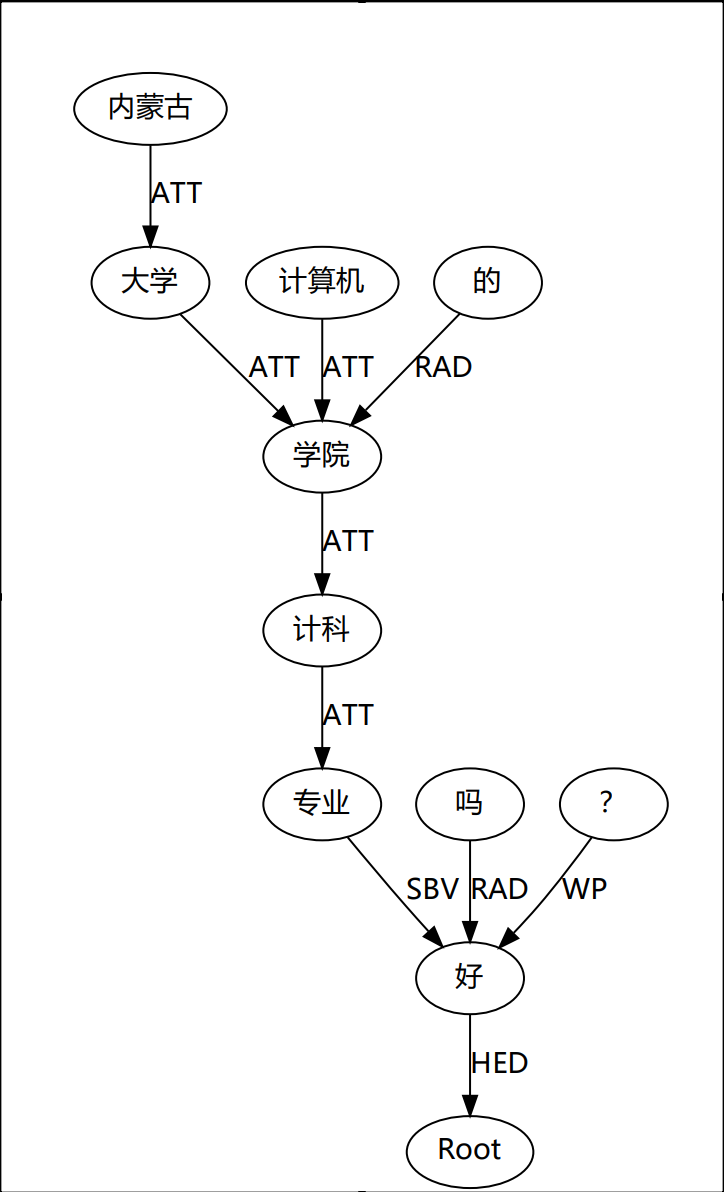 导语:此项目使用LTP分词,python版本为python3.6,windows平台,使用whl文件进行安装。项目完整文件见人工智能——构建依存树——使用LTP分词 ltp_data文件中为ltp分词所需模型,由于Gitee大小限制,所以这里的模型需要手动下载http://model.scir.yu
导语:此项目使用LTP分词,python版本为python3.6,windows平台,使用whl文件进行安装。项目完整文件见人工智能——构建依存树——使用LTP分词 ltp_data文件中为ltp分词所需模型,由于Gitee大小限制,所以这里的模型需要手动下载http://model.scir.yu 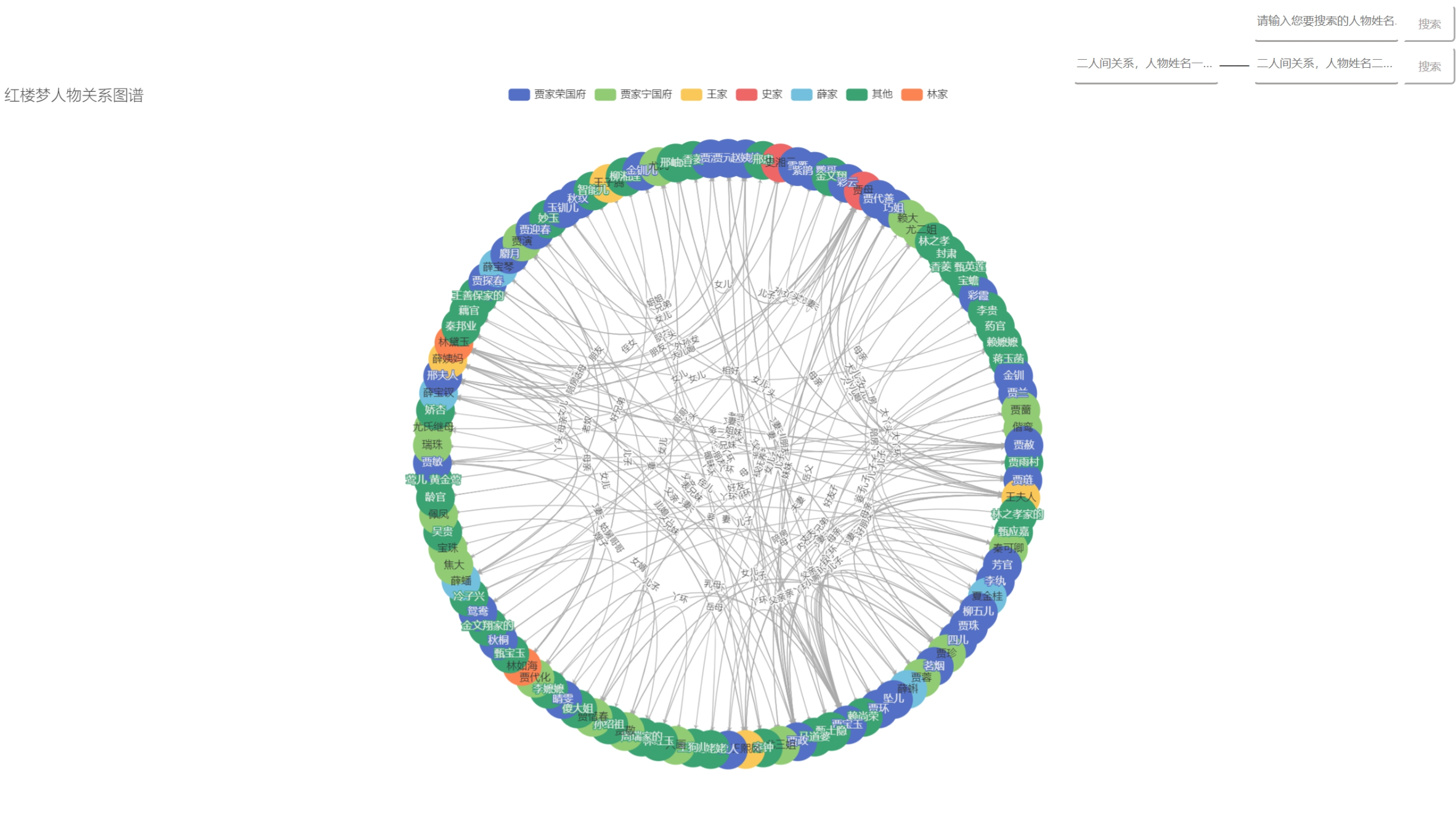 导语: 由于浏览器安全限制,浏览器并不能直接访问电脑本地文件,因此我在代码中访问本地json数据文件,直接打开HTML文件是不行的。我这里使用了VS code中的插件——Live Server,具体的用法可以参考vscode下关于Live Server的使用 ,在点击右下角的Go Live后即可自动
导语: 由于浏览器安全限制,浏览器并不能直接访问电脑本地文件,因此我在代码中访问本地json数据文件,直接打开HTML文件是不行的。我这里使用了VS code中的插件——Live Server,具体的用法可以参考vscode下关于Live Server的使用 ,在点击右下角的Go Live后即可自动  人工智能——知识图谱表示法——使用Echarts关系图展示《红楼梦》人物关系图谱
人工智能——知识图谱表示法——使用Echarts关系图展示《红楼梦》人物关系图谱  浙公网安备 33010602011771号
浙公网安备 33010602011771号