导语:自然语言处理可视化:利用爬虫抓取互联网上《如懿传》(或其他)电视剧中演员的部分数据,分析演员的姓名、星座、身高、体重和籍贯等信息,绘制词云和玫瑰图。
原题其实是《延禧攻略》,不过触类旁通后,我决定改成《如懿传》,此次爬取数据的网站为https://www.tvzn.com,在实际中发现此网站前后时间段的网页构成不同,所以触类旁通前观察好结构是否相同。
在此代码中,我使用了pyecharts进行了词云和玫瑰图的绘画,最终生成一个result.html文件,打开即可显示出效果
效果图:
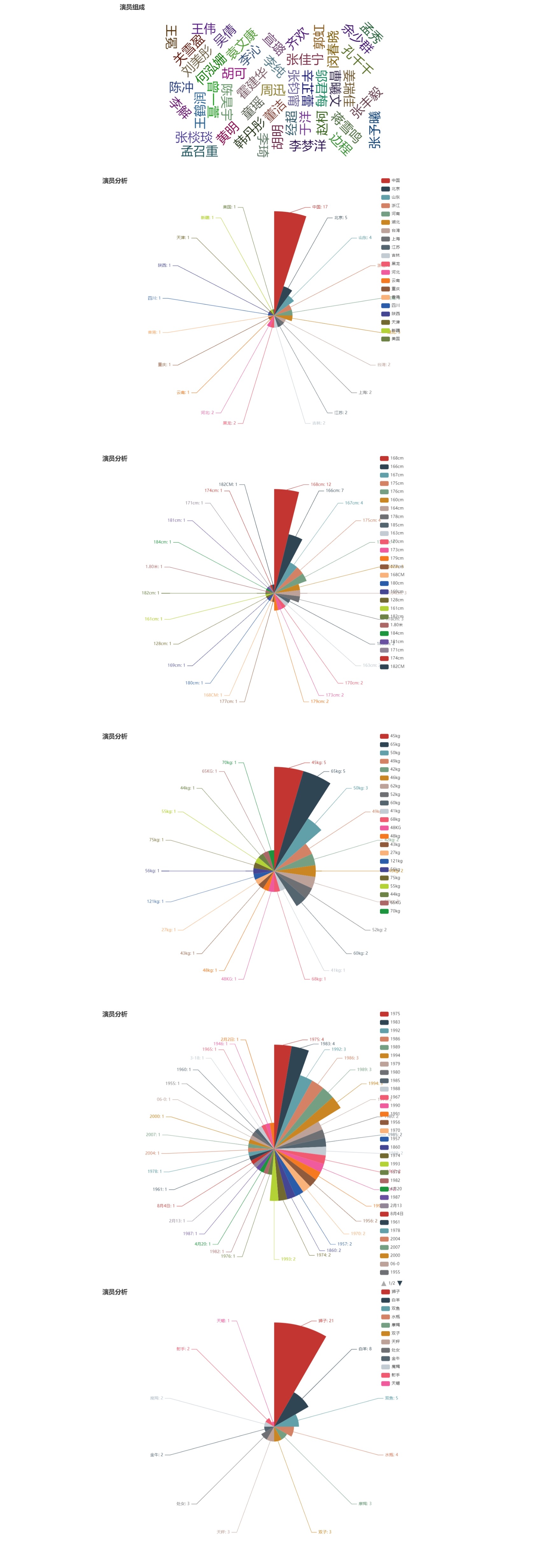
代码:
from bs4 import BeautifulSoup
import urllib.request
from collections import Counter
import operator
from pyecharts import options as opts
from pyecharts.charts import Pie, Page, WordCloud
def rmnull(list):
while '' in list:
list.remove('')#去除空字符串
#开始统计次数
def countsort(list):
while '' in list:
list.remove('')#去除空字符串
#进行统计
a = dict(Counter(list))
#进行排序
b= sorted(a.items(), key=operator.itemgetter(1),reverse=True)
return b
url = "https://www.tvzn.com/14729/yanyuanbiao.html"
response = urllib.request.urlopen(url) # 访问并打开url
html = response.read() # 创建html对象读取页面源代码
soup = BeautifulSoup(html, 'html.parser') # 创建soup对象,获取html代码
content = soup.find_all('a', class_="mh-actor")
surnamelist=list()
urllist=list()
for i in content:
name = i.string
url=i['href']
surnamelist.append(name)
urllist.append(url)
surnamelist=countsort(surnamelist)
print(surnamelist)
print(urllist)
jiguan=list()#籍贯
heigh=list()#身高
ton=list()#体重
age=list()#年龄
constellation=list()#星座
for i in urllist:
htmls=urllib.request.urlopen('http://www.tvzn.com'+i).read()
soups = BeautifulSoup(htmls, 'html.parser') # 创建soup对象,获取html代码
contents = soups.find('div',id='gaiyao').find(class_='tn-box-content tn-widget-content tn-corner-bottom').get_text().replace(" ", "").replace("生日:\n", "生日:")
contents=contents.splitlines()
rmnull(contents)#去除空字符串
# print(contents)
jiguan.append(contents[0].split(':')[1][0:2])
heigh.append(contents[1].split(':')[1].split('/')[0])
ton.append(contents[2].split( ':')[1].split('/')[0])
age.append(contents[4].split(':')[1][0:4])
constellation.append(contents[5].split(':')[1][0:2])
# jiguan.remove("本站")
jiguan=countsort(jiguan)#统计
heigh=countsort(heigh)#统计
ton=countsort(ton)#统计
age=countsort(age)#统计
constellation=countsort(constellation)#统计
print(jiguan)
print(heigh)
print(ton)
print(age)
print(constellation)
#开始绘制词云
def mapwordcloud(list) -> WordCloud:
c = (
WordCloud()
.add(
"",
# 系列数据项
data_pair=list,
shape='circle'
)
.set_global_opts(title_opts=opts.TitleOpts(title="演员组成"))
)
return c
#开始绘制玫瑰图
def mapmoviespie(list) -> Pie:
c = (
Pie(opts.InitOpts(width="1000px", height="800px"))
.add(
"",
# 系列数据项,格式为[(key1,value1),(key2,value2)]
data_pair=list,
# 饼图的圆心,第一项是相对于容器的宽度,第二项是相对于容器的高度
center=["50%", "50%"],
rosetype="area",
)
.set_global_opts(
title_opts=opts.TitleOpts(title="演员分析", subtitle=""),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
return c
page = Page(layout=Page.SimplePageLayout)
page.add(
mapwordcloud(surnamelist),
mapmoviespie(jiguan),
mapmoviespie(heigh),
mapmoviespie(ton),
mapmoviespie(age),
mapmoviespie(constellation),
)
page.render("result.html")






