导语:给定一段文本,利用Jieba分词软件进行分词,分析Jieba分词的原理,展示样本分词效果,样本的topK(10)词:topK(10)是指排序前十,这里我使用了《射雕英雄传》第一回作为给定的文本,即代码中的eg.txt,项目完整文件见人工智能——jieba分词实例
效果图:
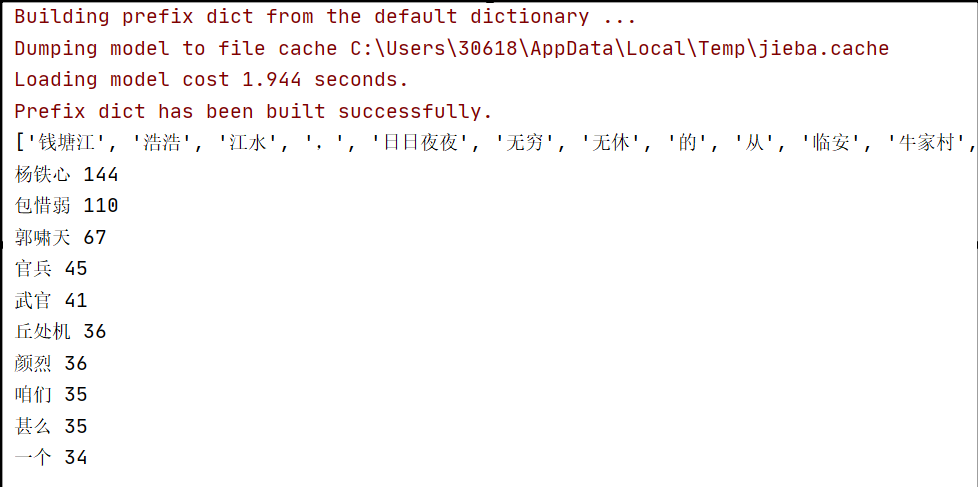
代码:
# -*- coding: utf-8 -*-
import jieba
import jieba.analyse
import codecs
import re
from collections import Counter
class WordCounter(object):
def count_from_file(self, file, top_limit=0):
with codecs.open(file, 'r', 'utf-8') as f:
content = f.read()
content = re.sub(r'\s+', r' ', content)
content = re.sub(r'\.+', r' ', content)
return self.count_from_str(content, top_limit=top_limit)
def count_from_str(self, content, top_limit=0):
if top_limit <= 0:
top_limit = 100
tags = jieba.analyse.extract_tags(content, topK=100)
words = list(jieba.cut(content))
print(words)
counter = Counter()
for word in words:
if word in tags:
counter[word] += 1
return counter.most_common(top_limit)#找出一个序列中出现次数最多的元素
if __name__ == '__main__':
counter = WordCounter()
result = counter.count_from_file(r'./eg.txt', top_limit=10)
for k, v in result:
print(k, v)






