





人工智能——构建依存树——使用LTP分词
导语:此项目使用LTP分词,python版本为python3.6,windows平台,使用whl文件进行安装。项目完整文件见人工智能——构建依存树——使用LTP分词
ltp_data文件中为ltp分词所需模型,由于Gitee大小限制,所以这里的模型需要手动下载http://model.scir.yunfutech.com/model/ltp_data_v3.4.0.zip
点击即可下载,将文件解压到此文件夹
安装步骤:
将文件pyltp-0.2.1-cp36-cp36m-win_amd64.whl移至python3.6中Scripts文件夹下,
搜索框打开CMD,
输入命令pip3.6 install pyltp-0.2.1-cp36-cp36m-win_amd64.whl,安装成功。
句法分析与汉语文本切分:给定句子,比如“Look for the large barking dog by the door in a crate”,进行依存分析研究单词之间的依赖关系,将依存关系表示为依存树
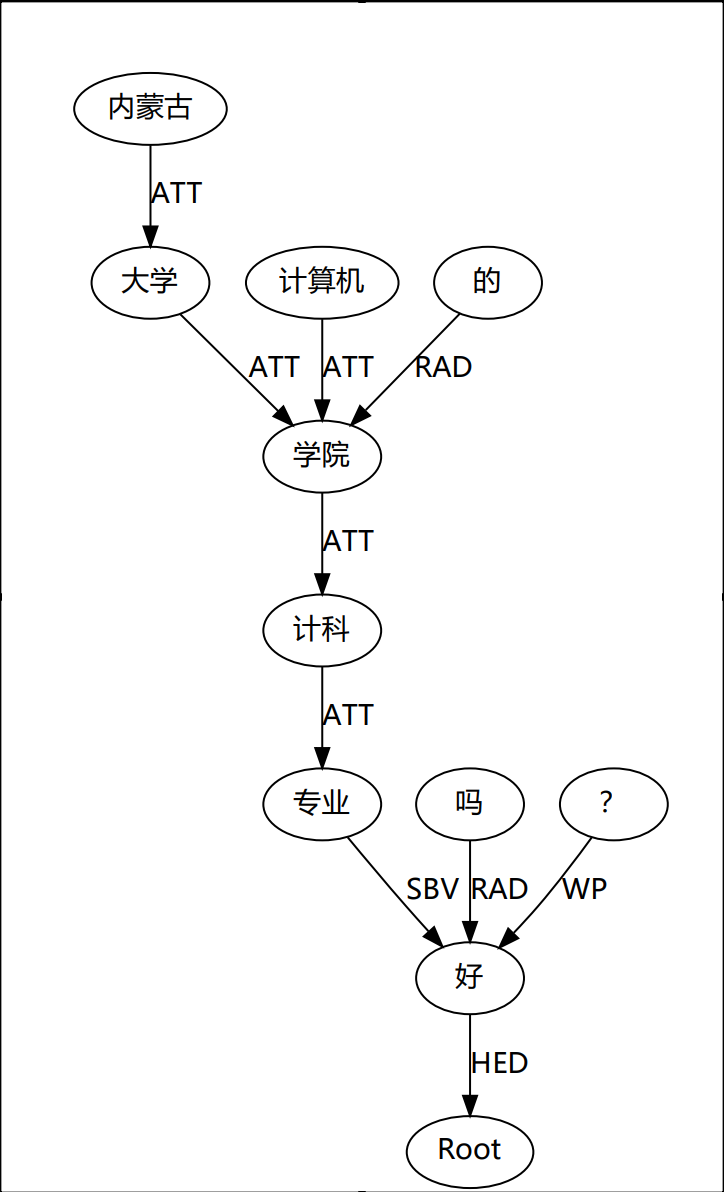
效果图:
代码
from pyltp import Segmentor
from pyltp import Postagger
from pyltp import Parser
from pyltp import NamedEntityRecognizer
relationch=[['定中关系', 'ATT'], ['数量关系', 'QUN'], ['并列关系', 'COO'], ['同位关系', 'APP'], ['前附加关系', 'LAD'], ['后附加关系', 'RAD'], ['动宾关系', 'VOB'], ['介宾关系', 'POB'], ['主谓关系', 'SBV'], ['比拟关系', 'SIM'], ['核心', 'HED'], ['连动结构', 'VV'], ['关联结构', 'CNJ'], ['语态结构', 'MT'], ['独立结构', 'IS'], ['状中结构', 'ADV'], ['动补结构', 'CMP'], ['“的”', 'DE'], ['“地”', 'DI'], ['“得”', 'DEI'], ['“把”', 'BA'], ['“被”', 'BEI'], ['独立分句', 'IC'], ['依存分句', 'DC']]
ldir = './ltp_data/cws.model' #分词模型
# dicdir = './ltp_data/lexicon.txt' #外部字典
# text = "内蒙古大学计算机学院的计科专业好吗?"杨过和小龙女什么关系
text = input("请输入需要处理的语句:")
#中文分词
segmentor = Segmentor() #初始化实例
segmentor.load_with_lexicon(ldir, './ltp_data/lexicon.txt') #加载模型
words = segmentor.segment(text) #分词
print(text)
print(' '.join(words)) #分词拼接
words = list(words) #转换list
print(u"分词:", words)
segmentor.release() #释放模型
#词性标注
pdir = './ltp_data/pos.model'
pos = Postagger() #初始化实例
pos.load(pdir) #加载模型
postags = pos.postag(words) #词性标注
postags = list(postags)
print(u"词性:", postags)
pos.release() #释放模型
data = {"words": words, "tags": postags}
print(data)
print(" ")
#命名实体识别
nermodel = './ltp_data/ner.model'
reg = NamedEntityRecognizer() #初始化命名实体实例
reg.load(nermodel) #加载模型
netags = reg.recognize(words, postags) #对分词、词性标注得到的数据进行实体标识
netags = list(netags)
print(u"命名实体识别:", netags)
#实体识别结果
data={"reg": netags,"words":words,"tags":postags}
print(data)
reg.release() #释放模型
print(" ")
#依存句法分析
parmodel = './ltp_data/parser.model'
parser = Parser() #初始化命名实体实例
parser.load(parmodel) #加载模型
arcs = parser.parse(words, postags) #句法分析
#输出结果
print(words)
print("\t".join("%d:%s" % (arc.head, arc.relation) for arc in arcs))
rely_id = [arc.head for arc in arcs] # 提取依存父节点id
relation = [arc.relation for arc in arcs] # 提取依存关系
heads = ['根' if id == 0 else words[id-1] for id in rely_id] # 匹配依存父节点词语
for i in range(len(words)):
for m in range(len(relationch)):
if(relation[i]==relationch[m][1]):
relation[i]=relationch[m][0]
print(relation[i] + '(' + words[i] + ', ' + heads[i] + ')')
parser.release() #释放模型
from graphviz import Digraph
#这里指定生成png图片,不加format属性则生成pdf文件
g = Digraph('fenciresult',format="png")
g.node(name='根', fontname="Microsoft YaHei")
for word in words:
g.node(name=word, fontname="Microsoft YaHei")
for i in range(len(words)):
if relation[i] not in ['HED']:
g.edge(words[i], heads[i], label=relation[i], fontname="Microsoft YaHei")
else:
if heads[i] == '根':
g.edge(words[i], '根', label=relation[i], fontname="Microsoft YaHei")
else:
g.edge(heads[i], '根', label=relation[i], fontname="Microsoft YaHei")
g.render(view=False)
