





随笔分类 - Python/人工智能
摘要:python将知识图谱的节点关系(CSV或其他格式)转换成Echarts所需的json格式
阅读全文
摘要: python批量更改文件名并移动到新的文件夹
前言:
1. 这里的代码以批量命名如:
路径"E:\下载\1\xxxx.mp4"、"E:\下载\2\xxxx.mp4"......
为"E:\下载\1\1.mp4"、"E:\下载\2\2.mp4"
并移动到路径"E:\\download"的格式为例
2. 得学会举一反三
阅读全文
python批量更改文件名并移动到新的文件夹
前言:
1. 这里的代码以批量命名如:
路径"E:\下载\1\xxxx.mp4"、"E:\下载\2\xxxx.mp4"......
为"E:\下载\1\1.mp4"、"E:\下载\2\2.mp4"
并移动到路径"E:\\download"的格式为例
2. 得学会举一反三
阅读全文
python批量更改文件名并移动到新的文件夹
前言:
1. 这里的代码以批量命名如:
路径"E:\下载\1\xxxx.mp4"、"E:\下载\2\xxxx.mp4"......
为"E:\下载\1\1.mp4"、"E:\下载\2\2.mp4"
并移动到路径"E:\\download"的格式为例
2. 得学会举一反三
阅读全文
摘要: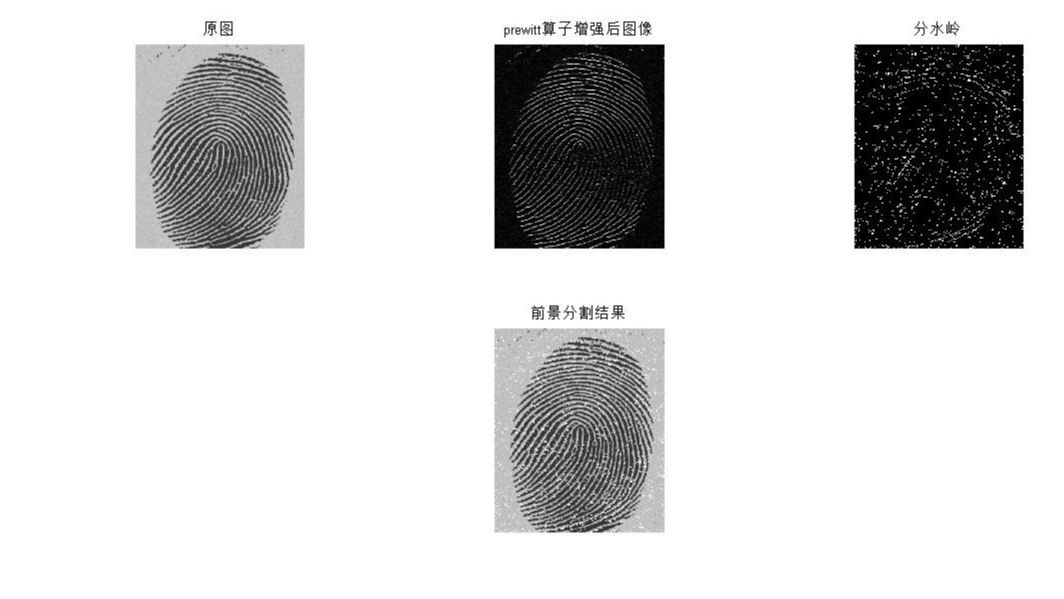 数字图像处理:图像分割
前言:1. 膨胀:将与目标区域的背景点合并到该目标物中,使目标物边界向外部扩张的处理,把二值图像各1像素连接成分的边界扩大一层。腐蚀:消除连通域的边界点,使边界向内收缩的处理。2. 开操作:先腐蚀再膨胀,可以去掉目标外的孤立点。闭操作:先膨胀再腐蚀,可以去掉目标内的孔。
一、实验目的
理解和掌握图像分割的基本理论和算法,练习使用形态学、区域、边界和阈值的方法结合图像增强复原的相关知识对图像进行分割处理。
二、实验内容
1.读入一幅图像,对图像进行如下操作:
(1) 用膨胀腐蚀等形态学方法对图像进行去噪、增强处理。改变结构元素,观察处理后的图像是否有明显的差别。
(2) 用开操作和闭操作等形态学方法去除指纹图像中的细小颗粒,连接断裂的指纹。
(3) 在上一步用形态学方法处理后的指纹图像基础上,运用全局阈值实现图像的二值化。
2.读入一幅图像,利用边缘检测和分水岭方法(watershed)对图像进行前景分割。在调用watershed函数前,利用prewitt算子或者全局阈值等方法增强图像边缘。
阅读全文
数字图像处理:图像分割
前言:1. 膨胀:将与目标区域的背景点合并到该目标物中,使目标物边界向外部扩张的处理,把二值图像各1像素连接成分的边界扩大一层。腐蚀:消除连通域的边界点,使边界向内收缩的处理。2. 开操作:先腐蚀再膨胀,可以去掉目标外的孤立点。闭操作:先膨胀再腐蚀,可以去掉目标内的孔。
一、实验目的
理解和掌握图像分割的基本理论和算法,练习使用形态学、区域、边界和阈值的方法结合图像增强复原的相关知识对图像进行分割处理。
二、实验内容
1.读入一幅图像,对图像进行如下操作:
(1) 用膨胀腐蚀等形态学方法对图像进行去噪、增强处理。改变结构元素,观察处理后的图像是否有明显的差别。
(2) 用开操作和闭操作等形态学方法去除指纹图像中的细小颗粒,连接断裂的指纹。
(3) 在上一步用形态学方法处理后的指纹图像基础上,运用全局阈值实现图像的二值化。
2.读入一幅图像,利用边缘检测和分水岭方法(watershed)对图像进行前景分割。在调用watershed函数前,利用prewitt算子或者全局阈值等方法增强图像边缘。
阅读全文
数字图像处理:图像分割
前言:1. 膨胀:将与目标区域的背景点合并到该目标物中,使目标物边界向外部扩张的处理,把二值图像各1像素连接成分的边界扩大一层。腐蚀:消除连通域的边界点,使边界向内收缩的处理。2. 开操作:先腐蚀再膨胀,可以去掉目标外的孤立点。闭操作:先膨胀再腐蚀,可以去掉目标内的孔。
一、实验目的
理解和掌握图像分割的基本理论和算法,练习使用形态学、区域、边界和阈值的方法结合图像增强复原的相关知识对图像进行分割处理。
二、实验内容
1.读入一幅图像,对图像进行如下操作:
(1) 用膨胀腐蚀等形态学方法对图像进行去噪、增强处理。改变结构元素,观察处理后的图像是否有明显的差别。
(2) 用开操作和闭操作等形态学方法去除指纹图像中的细小颗粒,连接断裂的指纹。
(3) 在上一步用形态学方法处理后的指纹图像基础上,运用全局阈值实现图像的二值化。
2.读入一幅图像,利用边缘检测和分水岭方法(watershed)对图像进行前景分割。在调用watershed函数前,利用prewitt算子或者全局阈值等方法增强图像边缘。
阅读全文
摘要: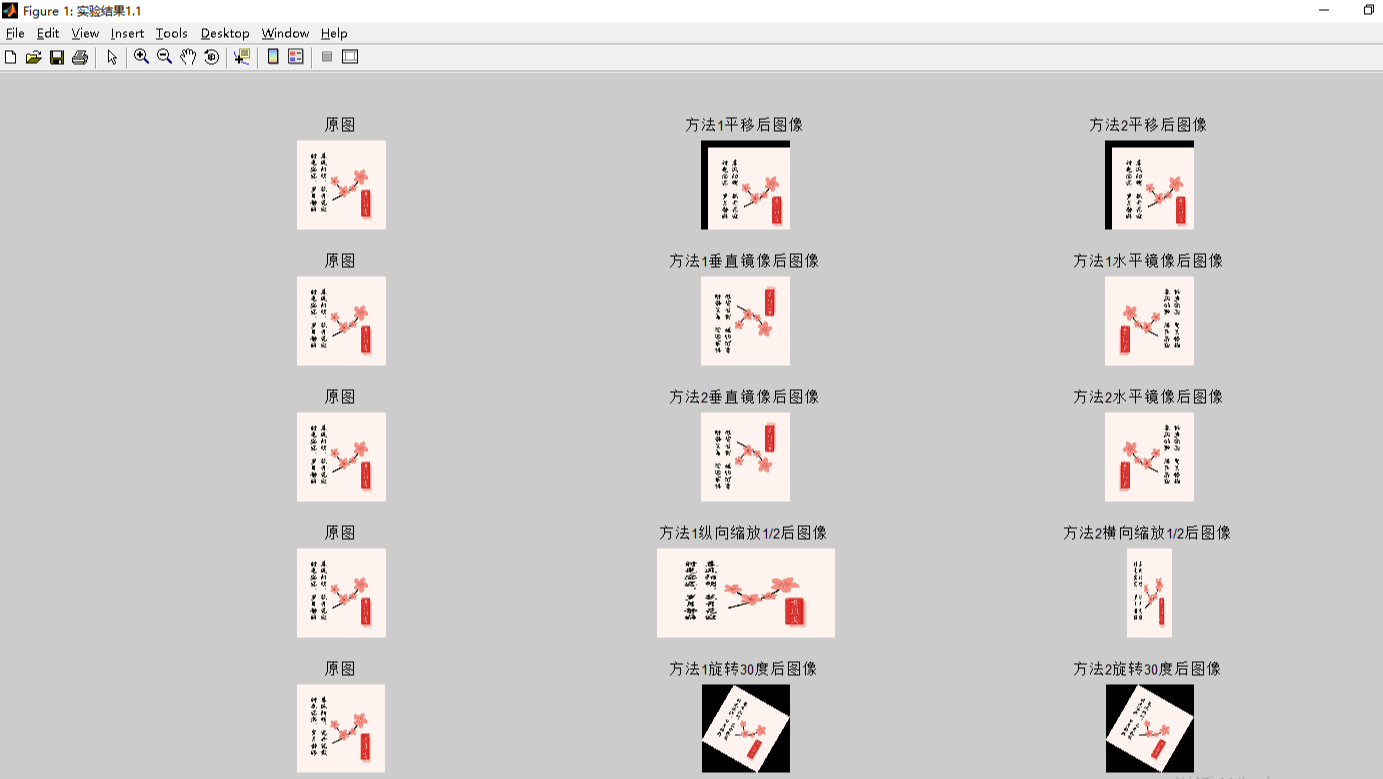 数字图像处理:空间域图像处理
前言:1. 在第一部分实验中,我均采用两种方法实现,分别是第一种方法通过二维矩阵加减平移 第二种方法通过空间变换矩阵平移2. 参考代码多为灰度图实现,对于三通道应用有问题,因此,我在编写代码时特意使用彩色图片,并且代码均为三通道写法。
一、实验目的
理解和掌握图像的平移、垂直镜像变换、水平镜像变换、缩放和旋转的原理和应用;熟悉图像几何变换的MATLAB操作和基本功能;掌握彩色图像处理的基本技术
二、实验内容
1.读入图像并对图像文件分别进行平移、垂直镜像变换、水平镜像变换、缩放和旋转操作
2.实验如下操作:
(1) 改变图像缩放比例
(2) 改变图像的旋转角度,
3. 读入一幅彩色图像,进行如下图像处理:
(1) 在RGB彩色空间中对图像进行模糊和锐化处理
(2) 在HSI彩色空间中,对H分量图像进行模糊和锐化处理,转换回RGB格式并观察效果
(3) 在HSI彩色空间中,对S分量图像进行模糊和锐化处理,转换回RGB格式并观察效果
(4) 在HSI彩色空间中,对I分量图像进行模糊和锐化处理,转换回RGB格式并观察效果
阅读全文
数字图像处理:空间域图像处理
前言:1. 在第一部分实验中,我均采用两种方法实现,分别是第一种方法通过二维矩阵加减平移 第二种方法通过空间变换矩阵平移2. 参考代码多为灰度图实现,对于三通道应用有问题,因此,我在编写代码时特意使用彩色图片,并且代码均为三通道写法。
一、实验目的
理解和掌握图像的平移、垂直镜像变换、水平镜像变换、缩放和旋转的原理和应用;熟悉图像几何变换的MATLAB操作和基本功能;掌握彩色图像处理的基本技术
二、实验内容
1.读入图像并对图像文件分别进行平移、垂直镜像变换、水平镜像变换、缩放和旋转操作
2.实验如下操作:
(1) 改变图像缩放比例
(2) 改变图像的旋转角度,
3. 读入一幅彩色图像,进行如下图像处理:
(1) 在RGB彩色空间中对图像进行模糊和锐化处理
(2) 在HSI彩色空间中,对H分量图像进行模糊和锐化处理,转换回RGB格式并观察效果
(3) 在HSI彩色空间中,对S分量图像进行模糊和锐化处理,转换回RGB格式并观察效果
(4) 在HSI彩色空间中,对I分量图像进行模糊和锐化处理,转换回RGB格式并观察效果
阅读全文
数字图像处理:空间域图像处理
前言:1. 在第一部分实验中,我均采用两种方法实现,分别是第一种方法通过二维矩阵加减平移 第二种方法通过空间变换矩阵平移2. 参考代码多为灰度图实现,对于三通道应用有问题,因此,我在编写代码时特意使用彩色图片,并且代码均为三通道写法。
一、实验目的
理解和掌握图像的平移、垂直镜像变换、水平镜像变换、缩放和旋转的原理和应用;熟悉图像几何变换的MATLAB操作和基本功能;掌握彩色图像处理的基本技术
二、实验内容
1.读入图像并对图像文件分别进行平移、垂直镜像变换、水平镜像变换、缩放和旋转操作
2.实验如下操作:
(1) 改变图像缩放比例
(2) 改变图像的旋转角度,
3. 读入一幅彩色图像,进行如下图像处理:
(1) 在RGB彩色空间中对图像进行模糊和锐化处理
(2) 在HSI彩色空间中,对H分量图像进行模糊和锐化处理,转换回RGB格式并观察效果
(3) 在HSI彩色空间中,对S分量图像进行模糊和锐化处理,转换回RGB格式并观察效果
(4) 在HSI彩色空间中,对I分量图像进行模糊和锐化处理,转换回RGB格式并观察效果
阅读全文
摘要: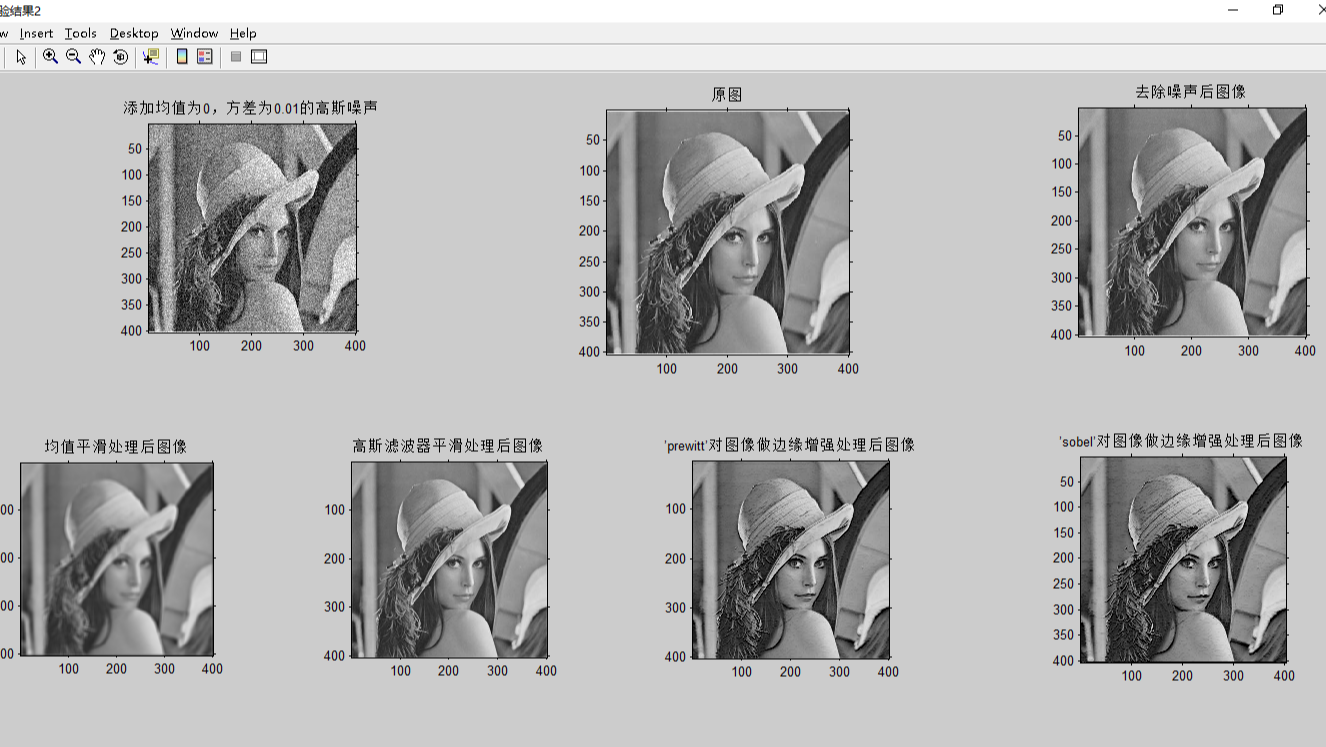 数字图像处理:空间域图像处理
一、实验目的
理解和掌握图像的线性变换和直方图均衡化的原理和应用;
了解平滑和锐化处理的算法和用途,学习使用平滑滤波器和边缘算子对图像进行平滑和锐化操作。
二、实验内容
1. 图像直方图
(1) 读入一幅图像,计算并绘制图像的直方图。
(2) 读入一幅低对比度图像,对图像进行直方图均衡化处理。
2. 编写程序,实现以下功能:
(1) 读入一幅图像,利用’imnoise’函数,添加高斯噪声;
(2) 通过100次相加求平均的方法去除噪声。
3. 图像的平滑和锐化滤波
(1) 读入一幅图像,分别采用均值和高斯滤波器对图像进行平滑处理。
(提示: 图像滤波首先使用fspecial()函数创建平滑或锐化滤波器,然后调用imfilter()函数实现相应的滤波操作)
(2) 分别采用’prewitt’和’sobel’边缘算子对图像做边缘增强处理。
阅读全文
数字图像处理:空间域图像处理
一、实验目的
理解和掌握图像的线性变换和直方图均衡化的原理和应用;
了解平滑和锐化处理的算法和用途,学习使用平滑滤波器和边缘算子对图像进行平滑和锐化操作。
二、实验内容
1. 图像直方图
(1) 读入一幅图像,计算并绘制图像的直方图。
(2) 读入一幅低对比度图像,对图像进行直方图均衡化处理。
2. 编写程序,实现以下功能:
(1) 读入一幅图像,利用’imnoise’函数,添加高斯噪声;
(2) 通过100次相加求平均的方法去除噪声。
3. 图像的平滑和锐化滤波
(1) 读入一幅图像,分别采用均值和高斯滤波器对图像进行平滑处理。
(提示: 图像滤波首先使用fspecial()函数创建平滑或锐化滤波器,然后调用imfilter()函数实现相应的滤波操作)
(2) 分别采用’prewitt’和’sobel’边缘算子对图像做边缘增强处理。
阅读全文
数字图像处理:空间域图像处理
一、实验目的
理解和掌握图像的线性变换和直方图均衡化的原理和应用;
了解平滑和锐化处理的算法和用途,学习使用平滑滤波器和边缘算子对图像进行平滑和锐化操作。
二、实验内容
1. 图像直方图
(1) 读入一幅图像,计算并绘制图像的直方图。
(2) 读入一幅低对比度图像,对图像进行直方图均衡化处理。
2. 编写程序,实现以下功能:
(1) 读入一幅图像,利用’imnoise’函数,添加高斯噪声;
(2) 通过100次相加求平均的方法去除噪声。
3. 图像的平滑和锐化滤波
(1) 读入一幅图像,分别采用均值和高斯滤波器对图像进行平滑处理。
(提示: 图像滤波首先使用fspecial()函数创建平滑或锐化滤波器,然后调用imfilter()函数实现相应的滤波操作)
(2) 分别采用’prewitt’和’sobel’边缘算子对图像做边缘增强处理。
阅读全文
摘要:以Flask框架写的接口为例的AJAX的前后端交互的模板
默认已经引入axios或者jQuery的CDN
阅读全文
摘要:解决Python web框架(如Flask)与vue渲染变量的冲突(冲突会导致vue渲染报错,网页无法显示)
导语:现在主流的Python web框架中,模板的表达式声明常见的有{{ something }}这与Vue.js的语法冲突,导致在运行如Flask的Python web框架时,会报错,前端网页无法渲染。
解决方法:
1. 重新定义vue的插值的符号——delimiters选项。如下代码(在js中vue渲染时添加):
阅读全文
摘要:人工智能——python使用py2neo连接neo4j报错——ValueError: The following settings are not supported: {'username': 'neo4j'}的解决办法,人工智能——python使用py2neo连接neo4j报错——ValueError: The following settings are not supported: {'username': 'neo4j'}的解决办法
之前在使用py2neo连接neo4j数据库的时候出现了报错——ValueError: The following settings are not supported: {'username': 'neo4j'},我简直一头雾水
阅读全文
摘要:解决Python flask运行报错:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd2 in position 0: invalid continuation byte
阅读全文
摘要:人工智能——LTP分词中外部词典的使用
阅读全文
 Python调用有道api进行翻译
Python调用有道api进行翻译
摘要:解决Python写入CSV后中文乱码问题
阅读全文
摘要:解决Python运行报错:UnicodeDecodeError: 'gbk' codec can't decode byte 0xb0 in position 166: illegal multibyte sequence
阅读全文
摘要: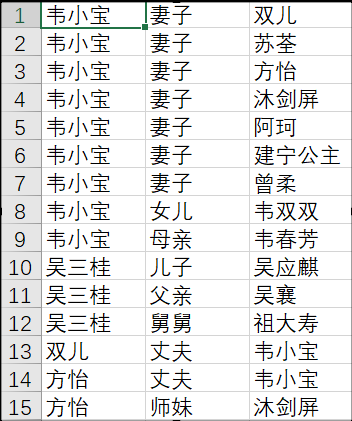 人工智能——爬取金庸小说人物关系
导语:人物数据来自于[金庸网](http://www.jinyongwuxia.cc/data/renwu/index.htm "金庸网"),为了便捷,人物姓名部分为手动复制到本地pachong.html文件中,最后的数据存在test2.csv中,人物关系数据来自百度百科。
阅读全文
人工智能——爬取金庸小说人物关系
导语:人物数据来自于[金庸网](http://www.jinyongwuxia.cc/data/renwu/index.htm "金庸网"),为了便捷,人物姓名部分为手动复制到本地pachong.html文件中,最后的数据存在test2.csv中,人物关系数据来自百度百科。
阅读全文
人工智能——爬取金庸小说人物关系
导语:人物数据来自于[金庸网](http://www.jinyongwuxia.cc/data/renwu/index.htm "金庸网"),为了便捷,人物姓名部分为手动复制到本地pachong.html文件中,最后的数据存在test2.csv中,人物关系数据来自百度百科。
阅读全文
摘要: 导语:人物数据来自于金庸网,为了便捷,人物姓名部分为手动复制到本地pachong.html文件中,最后的数据存在test.csv中,代码最后的停止3秒,非常有必要。 项目完整文件见 爬取金庸小说人物介绍 效果图: 代码: from bs4 import BeautifulSoup import ur
阅读全文
导语:人物数据来自于金庸网,为了便捷,人物姓名部分为手动复制到本地pachong.html文件中,最后的数据存在test.csv中,代码最后的停止3秒,非常有必要。 项目完整文件见 爬取金庸小说人物介绍 效果图: 代码: from bs4 import BeautifulSoup import ur
阅读全文
导语:人物数据来自于金庸网,为了便捷,人物姓名部分为手动复制到本地pachong.html文件中,最后的数据存在test.csv中,代码最后的停止3秒,非常有必要。 项目完整文件见 爬取金庸小说人物介绍 效果图: 代码: from bs4 import BeautifulSoup import ur
阅读全文
摘要: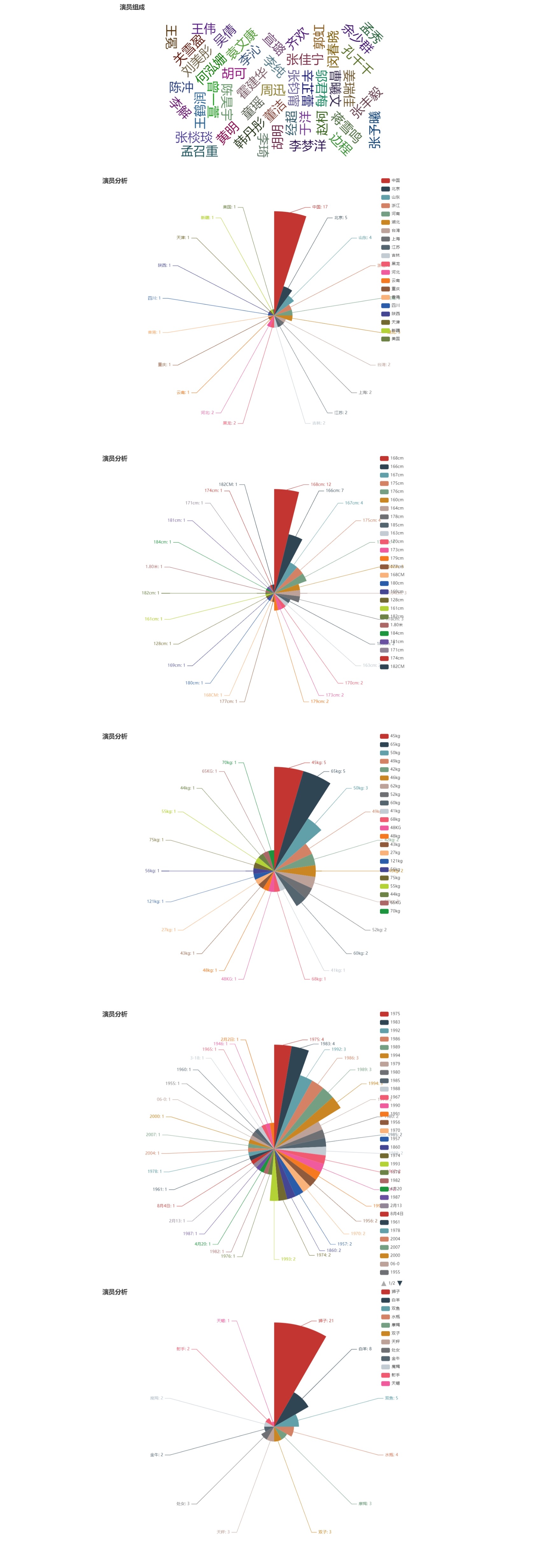 导语:自然语言处理可视化:利用爬虫抓取互联网上《如懿传》(或其他)电视剧中演员的部分数据,分析演员的姓名、星座、身高、体重和籍贯等信息,绘制词云和玫瑰图。 原题其实是《延禧攻略》,不过触类旁通后,我决定改成《如懿传》,此次爬取数据的网站为https://www.tvzn.com,在实际中发现此网站前
阅读全文
导语:自然语言处理可视化:利用爬虫抓取互联网上《如懿传》(或其他)电视剧中演员的部分数据,分析演员的姓名、星座、身高、体重和籍贯等信息,绘制词云和玫瑰图。 原题其实是《延禧攻略》,不过触类旁通后,我决定改成《如懿传》,此次爬取数据的网站为https://www.tvzn.com,在实际中发现此网站前
阅读全文
导语:自然语言处理可视化:利用爬虫抓取互联网上《如懿传》(或其他)电视剧中演员的部分数据,分析演员的姓名、星座、身高、体重和籍贯等信息,绘制词云和玫瑰图。 原题其实是《延禧攻略》,不过触类旁通后,我决定改成《如懿传》,此次爬取数据的网站为https://www.tvzn.com,在实际中发现此网站前
阅读全文
摘要: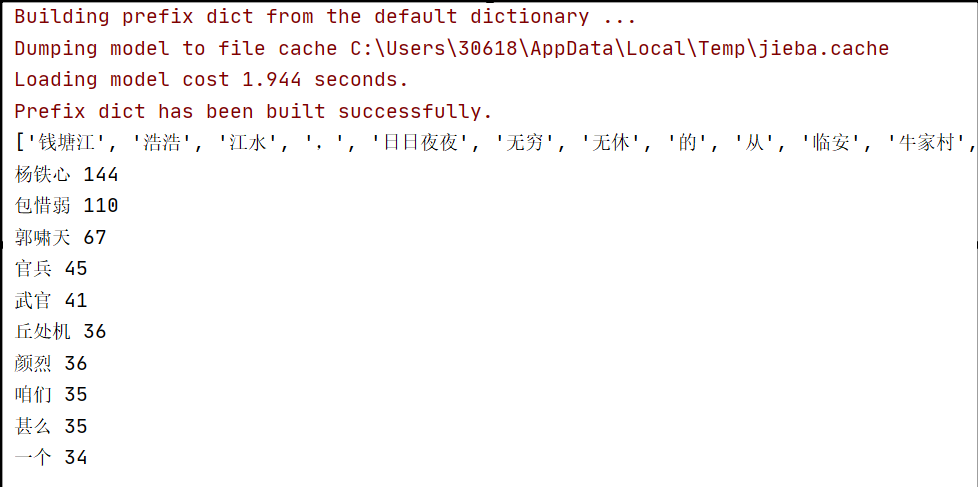 导语:给定一段文本,利用Jieba分词软件进行分词,分析Jieba分词的原理,展示样本分词效果,样本的topK(10)词:topK(10)是指排序前十,这里我使用了《射雕英雄传》第一回作为给定的文本,即代码中的eg.txt,项目完整文件见人工智能——jieba分词实例 效果图: 代码: # -*-
阅读全文
导语:给定一段文本,利用Jieba分词软件进行分词,分析Jieba分词的原理,展示样本分词效果,样本的topK(10)词:topK(10)是指排序前十,这里我使用了《射雕英雄传》第一回作为给定的文本,即代码中的eg.txt,项目完整文件见人工智能——jieba分词实例 效果图: 代码: # -*-
阅读全文
导语:给定一段文本,利用Jieba分词软件进行分词,分析Jieba分词的原理,展示样本分词效果,样本的topK(10)词:topK(10)是指排序前十,这里我使用了《射雕英雄传》第一回作为给定的文本,即代码中的eg.txt,项目完整文件见人工智能——jieba分词实例 效果图: 代码: # -*-
阅读全文
摘要: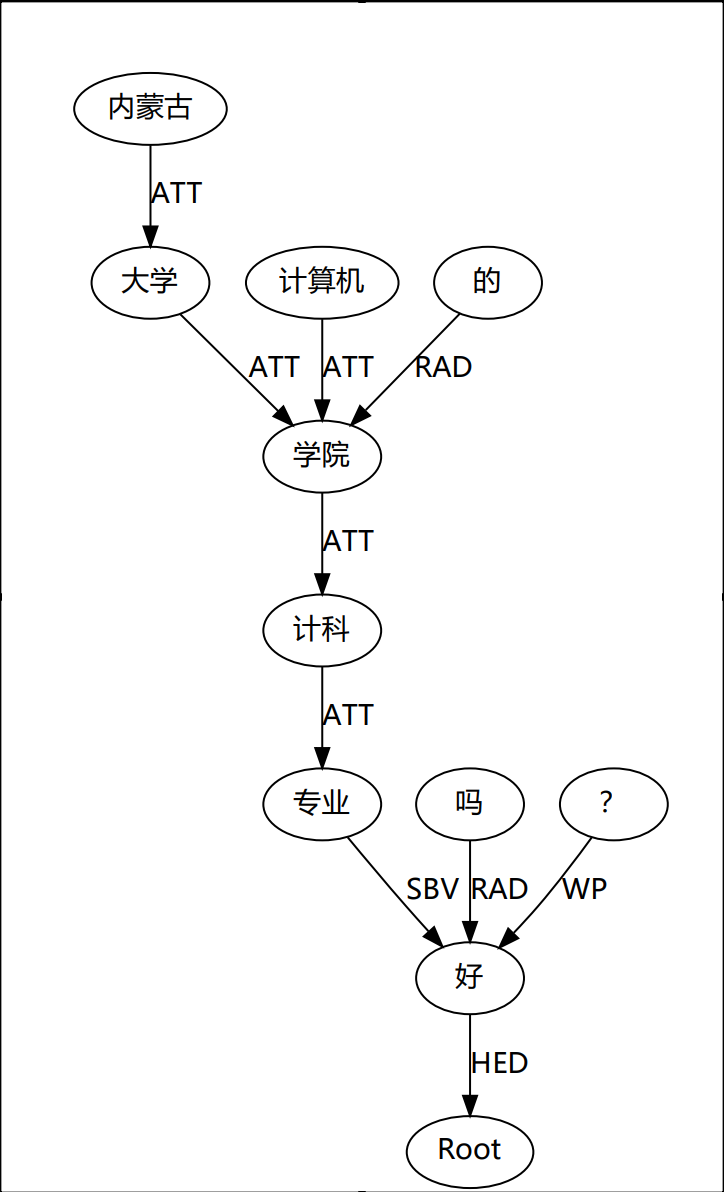 导语:此项目使用LTP分词,python版本为python3.6,windows平台,使用whl文件进行安装。项目完整文件见人工智能——构建依存树——使用LTP分词 ltp_data文件中为ltp分词所需模型,由于Gitee大小限制,所以这里的模型需要手动下载http://model.scir.yu
阅读全文
导语:此项目使用LTP分词,python版本为python3.6,windows平台,使用whl文件进行安装。项目完整文件见人工智能——构建依存树——使用LTP分词 ltp_data文件中为ltp分词所需模型,由于Gitee大小限制,所以这里的模型需要手动下载http://model.scir.yu
阅读全文
导语:此项目使用LTP分词,python版本为python3.6,windows平台,使用whl文件进行安装。项目完整文件见人工智能——构建依存树——使用LTP分词 ltp_data文件中为ltp分词所需模型,由于Gitee大小限制,所以这里的模型需要手动下载http://model.scir.yu
阅读全文
摘要: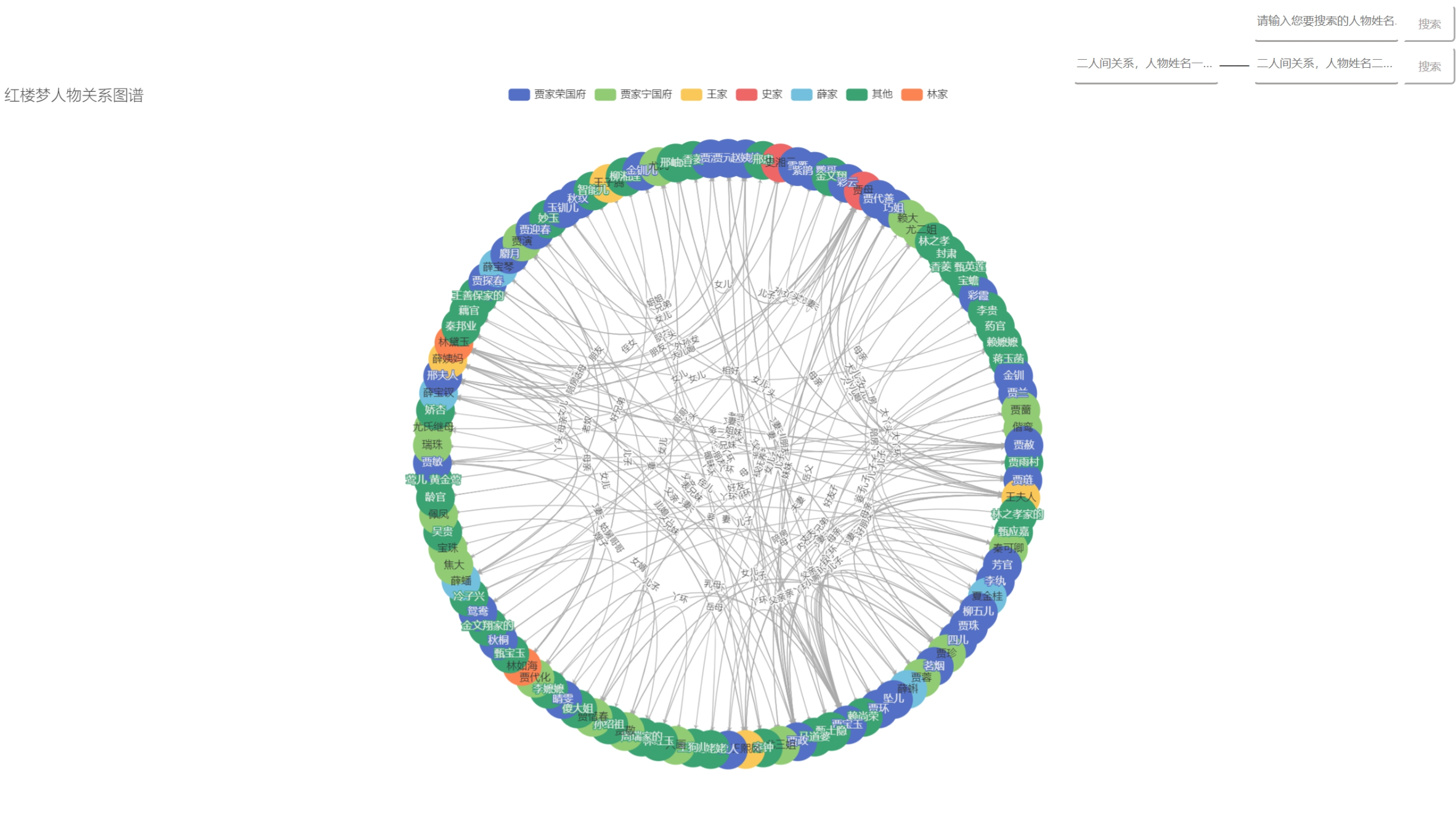 导语: 由于浏览器安全限制,浏览器并不能直接访问电脑本地文件,因此我在代码中访问本地json数据文件,直接打开HTML文件是不行的。我这里使用了VS code中的插件——Live Server,具体的用法可以参考vscode下关于Live Server的使用 ,在点击右下角的Go Live后即可自动
阅读全文
导语: 由于浏览器安全限制,浏览器并不能直接访问电脑本地文件,因此我在代码中访问本地json数据文件,直接打开HTML文件是不行的。我这里使用了VS code中的插件——Live Server,具体的用法可以参考vscode下关于Live Server的使用 ,在点击右下角的Go Live后即可自动
阅读全文
导语: 由于浏览器安全限制,浏览器并不能直接访问电脑本地文件,因此我在代码中访问本地json数据文件,直接打开HTML文件是不行的。我这里使用了VS code中的插件——Live Server,具体的用法可以参考vscode下关于Live Server的使用 ,在点击右下角的Go Live后即可自动
阅读全文
