
【原创】xenomai3 ipipe机制简述(基于X86)
 Xenomai是一个基于linux的硬实时操作系统(RTOS),在标准linux基础上添加一个实时内核Cobalt,与linux内核在内核空间共存,为了使Xenomai能够保持可预测的延迟(硬实时),必须阻止Linux内核直接处理中断,必须将中断先重定向通过Xenomai Cobalt处理,然后才是Linux内核。为此在底层增加一个微内核来实现。微内核充当虚拟可编程中断控制器,分离Linux和Xenomai Cobalt之间的中断掩码,该微内核称为中断管道(I-Pipe),I-Pipe基于ADEOS(Adaptive Domain Environment for Operating Systems)微内核,但是I-pipe更精简,并且只处理中断。
Xenomai是一个基于linux的硬实时操作系统(RTOS),在标准linux基础上添加一个实时内核Cobalt,与linux内核在内核空间共存,为了使Xenomai能够保持可预测的延迟(硬实时),必须阻止Linux内核直接处理中断,必须将中断先重定向通过Xenomai Cobalt处理,然后才是Linux内核。为此在底层增加一个微内核来实现。微内核充当虚拟可编程中断控制器,分离Linux和Xenomai Cobalt之间的中断掩码,该微内核称为中断管道(I-Pipe),I-Pipe基于ADEOS(Adaptive Domain Environment for Operating Systems)微内核,但是I-pipe更精简,并且只处理中断。
本文基于x86简单介绍ipipe的工作机制,ipipe是xenomai保证硬实时性的核心,本文是以前分析代码的一些流水记录,未经详细整理,希望对你认识xenomai原理有所帮助。
由于ipipe维护困难,跟不上主线内核的变化,为此xenomai社区2016年开始开发ipipe的替代品dovetail,自linux 5.4版本起,ipipe正式被更易维护的dovetail替代,伴随dovetail开发诞生的测试evl内核成为了今天的xenomai4内核,dovetail和ipipe本质工作没有变化,只是实现的差异,xenomai官方也给dovetail编写了完整的文档,详见https://v4.xenomai.org/dovetail/。
有了dovetail,让我们自己在linux内核开发属于自己的实时调度核成为可能,不仅如此,你完全可以将现有的RTOS诸如RT-Thread、uCOS、FreeRTOS等小型操作系统移植到linux内核来调度处理实时事件。
1.ipipe介绍
Xenomai是一个基于linux的硬实时操作系统(RTOS),在标准linux基础上添加一个实时内核Cobalt,与linux内核在内核空间共存,为了使Xenomai能够保持可预测的延迟(硬实时),必须阻止Linux内核直接处理中断,必须将中断先重定向通过Xenomai Cobalt处理,然后才是Linux内核。为此在底层增加一个微内核来实现。微内核充当虚拟可编程中断控制器,分离Linux和Xenomai Cobalt之间的中断掩码,该微内核称为中断管道(I-Pipe),I-Pipe基于ADEOS(Adaptive Domain Environment for Operating Systems)微内核,但是I-pipe更精简,并且只处理中断。
ipipe主要负责处理:
- IRQ与高分辨定时器
- 中断保护
- 系统事件(event)传播(虚拟中断)
- 支持是实时线程在linux域运行
- 共同优先级:当xenomai任务迁移到Linux域时,Linux域继承任务优先级(使用linux的软实时)。
- 保证程序执行时间的可预测性:当xenomai任务进入Linux域时,不能被Linux域中断抢占。
- 优先级倒置管理
- linux细粒度调度:当xenomai任务进入linux域需要尽快调度
2. x86中断处理和xenomai中断管理机制
2.1.x86中断机制
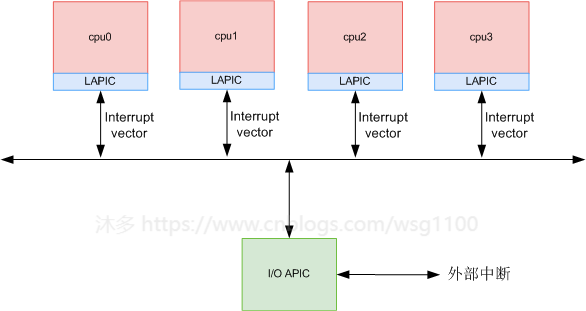
X86 系统中有256个vector,用来识别中断或异常的类型,vector 0-31处理器保留,有固定的用途, 从32到255的vector编号被指定为用户定义的中断,不被处理器保留。 这些中断通常分配给外部I / O设备(部分固定为APIC中断),以使这些设备能够将中断发送到处理器,每个vector的处理程序都保存在一个特殊的位置--IDT(中断描述符表),IDT的基地址保存在寄存器IDTR,在64位x86下IDT是一个16字节描述的数组(32位系统为8字节),当中断发生时CPU将vector乘以16(32位系统是乘以8)来找到IDT中的对应条目idt_data,然后根据条目信息跳转到处理入口执行中断和异常处理。
2.2.xenomai中断管理机制
(1)硬件中断
Xenomai是一个RTOS,与linux共存,为了使Xenomai能够保持可预测的延迟(硬实时),必须阻止Linux内核直接处理中断,先将中断重定给Xenomai处理,然后才是Linux内核。为此在底层增加一个微内核来实现。微内核充当虚拟可编程中断控制器,分离Linux和Xenomai之间的中断掩码,该微内核称为中断管道(I-Pipe),中断的分发和实时性由I-Pipe来保障,I-Pipe在系统中的位置如下所示。
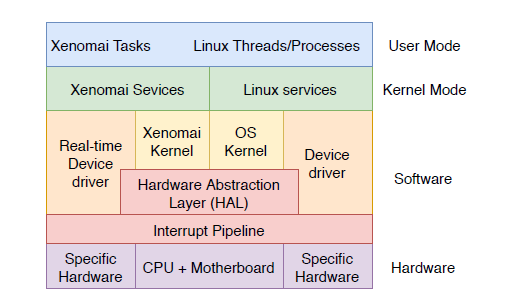
Linux和xenomai在I-ipipe上称为domain, I-Pipe将Linux和xenomai系统组织到两个域中,其中xenomai域的优先级高于Linux域。这两个域共享一个地址空间,允许来自xenomai的线程调用 Linux 内核域中的服务。 I-Pipe 以 domain 优先级顺序调度中断。 Xenomai 被设置为最高优先级域,并将首先接收中断。
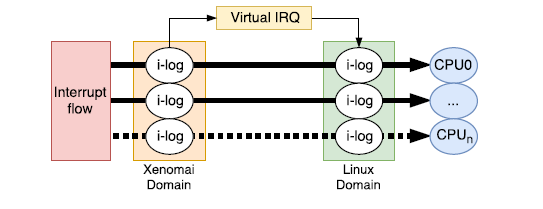
如上图所示,当cpu接收到一个中断后,通过IDT表中的中断入口进入I-Pipe处理逻辑,I-Pipe会先判断该中断是否是实时系统的中断(实时域中断),如果是,直接执行其中断服务函数。如果不是的话会将该中断保存到Linux域中断管理中记录,待xenomai 让出cpu后,Linux域执行时逐一从log中取出按Linux的中断入口去处理。
用于记录中断的log的是bitmap:
(2)虚拟中断
ipipe为了 xenomai 与 linux 之间交互时,如域切换调度、实时与非实时通讯等,为保证xenomai的实时性,引入了虚拟中断机制 。需要注意的是虚拟中断和常规 softirq 本质上不同,不能混淆 , softirq 只存在 linux 中,ipipe虚拟中断更近似于硬件中断,但不是硬件触发,由内核之间需要处理紧急任务时向另一个内核发送,除产生源不同外,ipipe将虚拟中断和硬件中断同等对待,ipipe处理虚拟中断与处理硬件中断流程一致。
虚拟中断注册和其他中断注册是一样的,只是这个中断号是通过函数ipipe_alloc_virq()来分配,由函数ipipe_free_virq()释放。比如__ipipe_printk_virq,当 xenomai 需要调用 linux 的打印输出时,只需要在 xenomai 中执行ipipe_post_irq_root(__ipipe_printk_virq)(给低优先级的 Linux 发送中断),然后就会在 Linux 上下文中执行__ipipe_flush_printk(),进行打印 xenomai 输出的内容,进而避免打印影响xenomai实时性。
相反,Linux可以通过虚拟中断触发 xenomai 上的一些活动,只需要在 Linux上下文中执行ipipe_post_irq_head(virq_xxx)(给 xenomai 发送中断),xenomai 就会很快执行相应操作。此外虚拟中断还可以本内核触发本内核虚拟中断。不管是虚拟中断还是硬件中断, xenomai 优先级都比 Linux 高。
3.ipipe domian管理
X86 linux异常处理与Ipipe接管中断/异常分析了ipipe通过在关键地方插入代码达到来接管中断,那ipipe是怎样来管理这些中断的呢?图中的head domain 与root Domain又是什么?
ipipe保证实时性主要是将紧急的中断交给实时内核处理,保证实时系统的实时性。ipipe为了把两个内核中断处理区分开来,定义了一个结构ipipe_domain来抽象不同的内核,domain域,也就是范围的意思,每个内核处理各自范围内的中断。多个Domain可以注册同一个中断,也就是说同一个中断可以在多个Domain得到处理,哪个域先处理得看优先级。haed域优先级高于roo域,靠ipipe来保证。
typedef void (*ipipe_irq_ackfn_t)(struct irq_desc *desc);
typedef void (*ipipe_irq_handler_t)(unsigned int irq,
void *cookie);
struct ipipe_domain {
int context_offset;
struct ipipe_irqdesc {
unsigned long control;
ipipe_irq_ackfn_t ackfn;
ipipe_irq_handler_t handler;
void *cookie;
} ____cacheline_aligned irqs[IPIPE_NR_IRQS];
const char *name;
struct mutex mutex;
};
其中name即该Domain的名字;在ipipe层每个中断使用结构体ipipe_irqdesc来描述。要记录每个域的中断注册信息就要用多个ipipe_irqdesc来记录。所以,ipipe_domain中有一个大的ipipe_irqdesc数组,用来记录该域中需要处理的中断信息,数组大小IPIPE_NR_IRQS,IPIPE_NR_IRQS是系统能处理的最大中断数,ipipe处理时使用中断号irq作为该数组索引下标,对应的ipipe_irqdesc[irq]就是这个domain中中断irq的处理程序等信息。
control记录着该中断一些处理标志位,需要注意的是IPIPE_HANDLE_FLAG标志,它置位表示该irq有对应的handler,用于head域快速判断一个中断是不是head域注册的,中断没有注册,也就没有该标志,硬件产生了该中断,就会被ipipe直接扔给root域。
#define IPIPE_HANDLE_FLAG 0
#define IPIPE_STICKY_FLAG 1
#define IPIPE_LOCK_FLAG 2
#define IPIPE_HANDLE_MASK (1 << IPIPE_HANDLE_FLAG)
#define IPIPE_STICKY_MASK (1 << IPIPE_STICKY_FLAG)
#define IPIPE_LOCK_MASK (1 << IPIPE_LOCK_FLAG)
ackfn 该中断的清理回调函数,当中断产生后,ipipe会调用该函数清除中断,不是所有中断有;
handler该中断的处理函数,ipipe会执行该中断处理函数;
cookie用来给上面几个函数传递一些可能会用到的参数。
每个域有了ipipe_irqdesc[]后还不够,仅是知道了每个中断该调用什么处理函数。系统运行的时候每个CPU会产生或接收到不同的中断,并且ipipe是优先保证head域的优先的,如果此时是head域正在运行,来了一个硬件中断,但这个中断不是head注册的,是root域注册的,此时root域又得不到运行,怎么办?为此,每个domain还要记录和管理在该CPU上的中断处理情况。
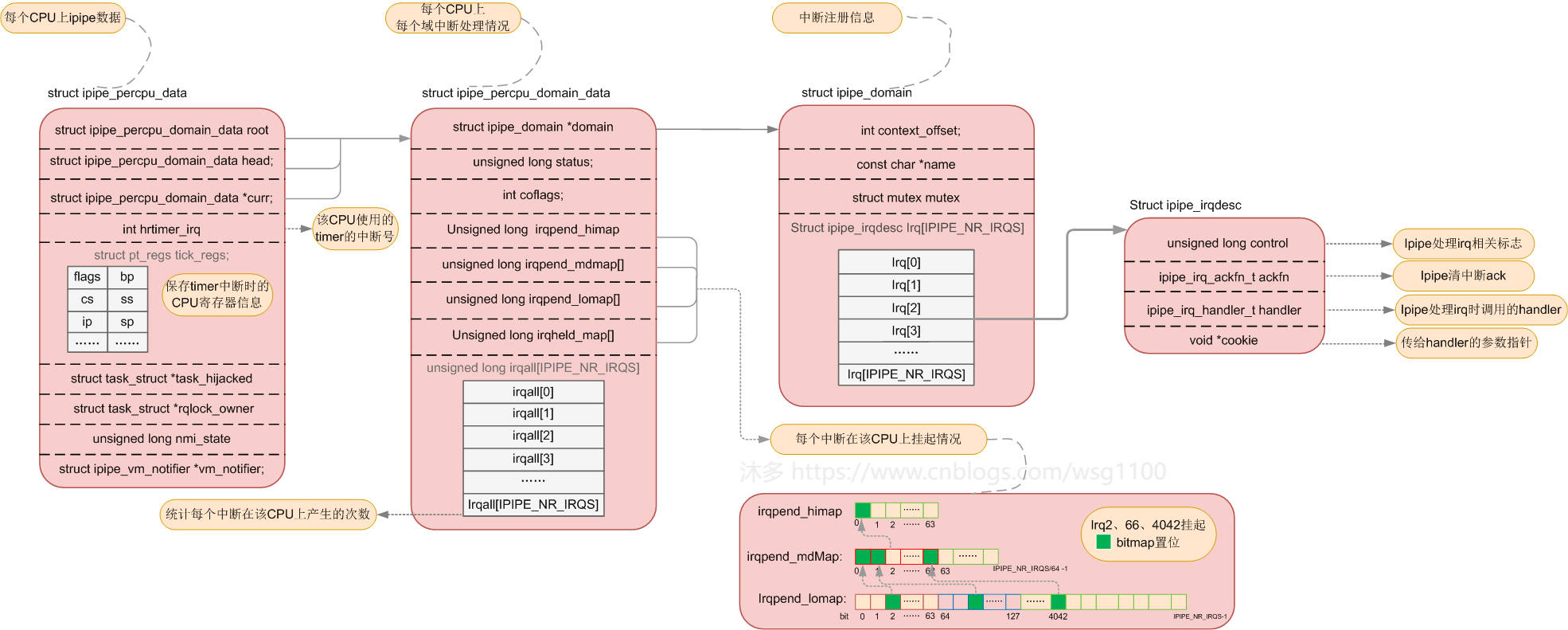
ipipe使用结构体ipipe_percpu_domain_data来记录管理不同domain在该CPU上的中断处理情况。
#define __bpl_up(x) (((x)+(BITS_PER_LONG-1)) & ~(BITS_PER_LONG-1))
/* Number of virtual IRQs (must be a multiple of BITS_PER_LONG) */
#define IPIPE_NR_VIRQS BITS_PER_LONG
/* First virtual IRQ # (must be aligned on BITS_PER_LONG) */
#define IPIPE_VIRQ_BASE __bpl_up(IPIPE_NR_XIRQS)
/* Total number of IRQ slots */
#define IPIPE_NR_IRQS (IPIPE_VIRQ_BASE+IPIPE_NR_VIRQS)
#define IPIPE_IRQ_LOMAPSZ (IPIPE_NR_IRQS / BITS_PER_LONG)
#define IPIPE_IRQ_LOMAPSZ (IPIPE_NR_IRQS / BITS_PER_LONG)
#if IPIPE_IRQ_LOMAPSZ > BITS_PER_LONG
/*
* We need a 3-level mapping. This allows us to handle up to 32k IRQ
* vectors on 32bit machines, 256k on 64bit ones.
*/
#define __IPIPE_3LEVEL_IRQMAP 1
#define IPIPE_IRQ_MDMAPSZ (__bpl_up(IPIPE_IRQ_LOMAPSZ) / BITS_PER_LONG)
#else
/*
* 2-level mapping is enough. This allows us to handle up to 1024 IRQ
* vectors on 32bit machines, 4096 on 64bit ones.
*/
#define __IPIPE_2LEVEL_IRQMAP 1
#endif
struct ipipe_percpu_domain_data {
unsigned long status; /* <= Must be first in struct. */
unsigned long irqpend_himap;
#ifdef __IPIPE_3LEVEL_IRQMAP
unsigned long irqpend_mdmap[IPIPE_IRQ_MDMAPSZ];
#endif
unsigned long irqpend_lomap[IPIPE_IRQ_LOMAPSZ];
unsigned long irqheld_map[IPIPE_IRQ_LOMAPSZ];
unsigned long irqall[IPIPE_NR_IRQS];
struct ipipe_domain *domain;
int coflags;
};
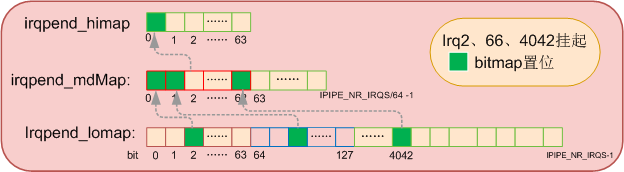
每个domain管理的中断很多,domain使用位图(bitmap)来记录中断处理情况,每一个中断对应一个bit,总的需要IPIPE_NR_IRQS个bit,为了方便管理,又将IPIPE_NR_IRQS个bit分成几部分,注释中已经很清楚了,当系统管理的中断向量数<=4096时,我们就将IPIPE_NR_IRQS分成两部分,irqpend_lomap和irqpend_himap,irqpend_lomap空间共占4096个bit,对应要管理的irq0-4095。而irqpend_lomap则是上级,将irqpend_lomap中的每64bit作为一个组,每组在irqpend_himap用一个bit用来表示。
当系统需要管理的中断向量大于4096时,irqpend_himap的64bit就不够用了,我们就增加一个irqpend_mdmap来增大bitmap,同样irqpend_lomap每64bit作为一个组,每组在irqpend_lomap用一个bit用来表示,irqpend_lomap再每64bit作为一个组,每组在irqpend_himap用一个bit用来表示。
当中断到来后,不是紧急的中断先挂起,在irqpend_lomap对应bit置位,同时置位所在第几个 64位中的irqpend_himap的bit,等后面有时间在来处理该中断。这样在处理挂起的中断时就可以快速索引到对应的irq。
bitmap只能记录该中断来了有没有被处理,当一个中断到来后ipipe先将它挂起,置位相应bit,但还没等这个挂起的中断被处理,这个中断又来了,irqall就是用来记录这个irq总的到来多少次的,irqall[irq]++;
status是否处理虚拟中断标志位。虚拟中断后面介绍。
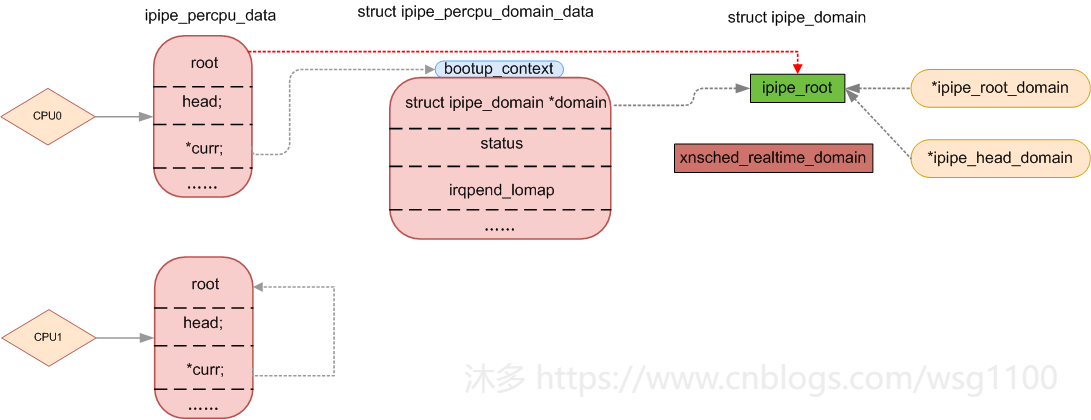
多CPU系统中每个CPU上都可以运行domain,为了更好的管理和调度每个domain在本CPU上运行的情况,使用ipipe_percpu_data来记录,记录着本CPU上root domain是谁,head domain (优先级最高)是谁和当前CPU执行的domain curr,如果当前CPU上运行的是linux,那curr==root,当前CPU上运行的是xenomai,那curr==head,并为每以个CPU预定义ipipe_percpu_data ipipe_percpu。
struct ipipe_percpu_data {
struct ipipe_percpu_domain_data root;
struct ipipe_percpu_domain_data head;
struct ipipe_percpu_domain_data *curr;
struct pt_regs tick_regs;/*寄存器*/
int hrtimer_irq;
struct task_struct *task_hijacked;
struct task_struct *rqlock_owner;
struct ipipe_vm_notifier *vm_notifier;
unsigned long nmi_state;
struct mm_struct *active_mm;
#ifdef CONFIG_IPIPE_DEBUG_CONTEXT
int context_check;
int context_check_saved;
#endif
};
DECLARE_PER_CPU(struct ipipe_percpu_data, ipipe_percpu);
root该CPU上的root域
head该CPU上的head域
curr当前CPU运行的域
tick_regstimer中断到来的时候保存CPU寄存器信息
hrtimer_irq该CPU使用的timer中断号,x86中一般都是lapic timer的中断号
ipipe_percpu初始化如下,root默认是ipipe_root,boot下文也是ipipe_root
static __initdata struct ipipe_percpu_domain_data bootup_context = {
.status = IPIPE_STALL_MASK,
.domain = &ipipe_root,
};
DEFINE_PER_CPU(struct ipipe_percpu_data, ipipe_percpu) = {
.root = {
.status = IPIPE_STALL_MASK,
.domain = &ipipe_root,
},
.curr = &bootup_context,
.hrtimer_irq = -1,
#ifdef CONFIG_IPIPE_DEBUG_CONTEXT
.context_check = 1,
#endif
};
完整的ipipe数据图如下:
4.ipipe初始化流程
现在我们知道了系统有两个domian分别是head和root,表示两个内核,head优先级高,优先处理中断,保证系统实时性,root优先级低,后处理中断。
/*\kernel\ipipe\core.c*/
#define ipipe_root_domain (&ipipe_root)
/*\include\linux\ipipe_domain.c*/
struct ipipe_domain *ipipe_head_domain = &ipipe_root;
root ** 即ipipe_root,宏ipipe_root_domain始终指向ipipe_root,head由全局指针*ipipe_head_domain表示,指向谁谁就是head域,*ipipe_head_domain初始化指向ipipe_root,其实这个ipipe_root表示linux**,它所管理的中断都是最终需要给linux处理的。ipipe初始化即初始化相应的domain,下面看ipipe初始化:

在start_kernel的时候,在__ipipe_init_early中进行ipipe早期初始化,主要初始化作为linux的ipipe_root。
void __init __ipipe_init_early(void)
{
struct ipipe_domain *ipd = &ipipe_root;/*LInux域*/
int cpu;
fixup_percpu_data();
ipd->name = "Linux";
ipd->context_offset = root_context_offset();
init_stage(ipd);
……
#ifdef CONFIG_PRINTK
__ipipe_printk_virq = ipipe_alloc_virq();/*分配一个虚拟中断号*/
ipd->irqs[__ipipe_printk_virq].handler = __ipipe_flush_printk;
ipd->irqs[__ipipe_printk_virq].cookie = NULL;
ipd->irqs[__ipipe_printk_virq].ackfn = NULL;
ipd->irqs[__ipipe_printk_virq].control = IPIPE_HANDLE_MASK;
#endif /* CONFIG_PRINTK */
__ipipe_work_virq = ipipe_alloc_virq();
ipd->irqs[__ipipe_work_virq].handler = __ipipe_do_work;
ipd->irqs[__ipipe_work_virq].cookie = NULL;
ipd->irqs[__ipipe_work_virq].ackfn = NULL;
ipd->irqs[__ipipe_work_virq].control = IPIPE_HANDLE_MASK;
for_each_possible_cpu(cpu)
per_cpu(work_tail, cpu) = per_cpu(work_buf, cpu);
}
__ipipe_init_early()中 首先初始化我们上面说到的ipipe_percpu,设置每个cpu上的ipipe环境curr指向root,即ipipe_root,而且将0号cpu作为bootup_context,即引导启动上下文的CPU,这时候SMP还没初始化,只有引导CPU0在运行,代码必须在引导CPU上运行。
然后调用init_stage()注册一个中断IPIPE_CRITICAL_IPI到ipipe_root
往ipipe注册一个域很简单,就是填充上面说到的struct ipipe_domain中的irq_desc数组,填充以中断号IPIPE_CRITICAL_IPI作为数组下表的那一个irq_desc,IPIPE_CRITICAL_IPI产生时调用的handler,清中断函数ackfn,中断处理函数可能用到的参数cookie,中断标志位control,这样就往ipipe_root注册了一个中断,当中断到来后ipipeline就会按一定规则去调用处理(ipipeline中断传递)。
static void init_stage(struct ipipe_domain *ipd)
{
memset(&ipd->irqs, 0, sizeof(ipd->irqs));
mutex_init(&ipd->mutex);
__ipipe_hook_critical_ipi(ipd);
}
void __ipipe_hook_critical_ipi(struct ipipe_domain *ipd)
{
unsigned int ipi = IPIPE_CRITICAL_IPI;
ipd->irqs[ipi].ackfn = __ipipe_ack_apic;
ipd->irqs[ipi].handler = __ipipe_do_critical_sync;
ipd->irqs[ipi].cookie = NULL;
ipd->irqs[ipi].control = IPIPE_HANDLE_MASK|IPIPE_STICKY_MASK;
}
接下来注册虚拟中断__ipipe_printk_virq,ipipe_alloc_virq()分配一个虚拟中断号__ipipe_printk_virq,简单说用于内核打印信息,负责整个系统的printk,xenomai也是通过这个来打印的,注意,这里__ipipe_printk_virq明明是注册到ipipe_root的,xenomai是怎样能够通过__ipipe_printk_virq来打印的呢?这就是虚拟中断存在的意义了。
插一句,ipipe中的三种中断类型:
**外部中断 **
由外部硬件触发的中断,X86系统中的中断由apic(高级可编程中断控制器)来管理,之前已经分析过:
**软中断 **
由软件触发的中断比如常见的int指令,系统调用(后面说ipipe处理系统调用),软中断只存在linux(root domain)中。
虚拟中断
虚拟中断可用来从head触发root上的一些活动,同样也可以从root触发head上的一些活动,虚拟中断和常规softirq本质上不同,softirqz只存在linux(root domain)中。虚拟中断注册和其他中断注册是一样的,只是这个中断号是通过函数ipipe_alloc_virq()来分配,由函数ipipe_free_virq()释放。比如上面的__ipipe_printk_virq,当head需要触发__ipipe_flush_printk()执行的时候,只需要在head中执行ipipe_post_irq_root(__ipipe_printk_virq),然后就会在root上下文中执行·__ipipe_flush_printk():
ipipe_post_irq_root(__ipipe_printk_virq);
相反可以从root触发head上的一些活动,注册一个虚拟中断virq到head:
static void virq_oob_handler(unsigned int virq, void *cookie)
{
do_oob_work();
}
void install_virq(void)
{
unsigned int virq;
...
virq = ipipe_alloc_virq();
...
ipipe_request_irq(ipipe_head_domain, virq, virq_oob_handler,
handler_arg, NULL);
}
然后在任何root代码中执行,就能触发head上下文中执行virq_oob_handler():
ipipe_post_irq_head(virq);
接下来ipipe注册了一个虚拟中断__ipipe_work_virq,中断处理函数为__ipipe_do_work(),__ipipe_do_work()用来执行work_buf中的任务,work_buf是大小为2K的char数组,是一个precpu变量,根据任务类型里面存放相应的任务结构体, ipipe_work_header的结构体:
static void __ipipe_do_work(unsigned int virq, void *cookie)
{
struct ipipe_work_header *work;
unsigned long flags;
void *curr, *tail;
int cpu;
cpu = smp_processor_id();
curr = per_cpu(work_buf, cpu);/*获取当前CPU的 work_buf*/
/*执行work_buf中所有work*/
for (;;) {
flags = hard_local_irq_save();
tail = per_cpu(work_tail, cpu);
if (curr == tail) {
per_cpu(work_tail, cpu) = per_cpu(work_buf, cpu);
hard_local_irq_restore(flags);
return;
}
work = curr;
curr += work->size;
hard_local_irq_restore(flags);
work->handler(work);/*执行handler*/
}
}
__ipipe_init()中正式初始化管理Linux中断的ipipe_root_domain
void __init __ipipe_init(void)
{
/* Now we may engage the pipeline. */
__ipipe_enable_pipeline();
pr_info("Interrupt pipeline (release #%d)\n", IPIPE_CORE_RELEASE);
}
void __init __ipipe_enable_pipeline(void)
{
unsigned int irq;
#ifdef CONFIG_X86_LOCAL_APIC
/* Map the APIC system vectors.
*/
ipipe_request_irq(ipipe_root_domain,
ipipe_apic_vector_irq(LOCAL_TIMER_VECTOR), /*定时器中断向量*/
__ipipe_do_IRQ, smp_apic_timer_interrupt,/*APIC中断*/
__ipipe_ack_apic);
#ifdef CONFIG_HAVE_KVM
ipipe_request_irq(ipipe_root_domain,
ipipe_apic_vector_irq(POSTED_INTR_WAKEUP_VECTOR),
__ipipe_do_IRQ, smp_kvm_posted_intr_wakeup_ipi,
__ipipe_ack_apic);
ipipe_request_irq(ipipe_root_domain,
ipipe_apic_vector_irq(POSTED_INTR_VECTOR),
__ipipe_do_IRQ, smp_kvm_posted_intr_ipi,
__ipipe_ack_apic);
#endif
#if defined(CONFIG_X86_MCE_AMD) && defined(CONFIG_X86_64)
ipipe_request_irq(ipipe_root_domain,
ipipe_apic_vector_irq(DEFERRED_ERROR_VECTOR),
__ipipe_do_IRQ, smp_deferred_error_interrupt,
__ipipe_ack_apic);
#endif
#ifdef CONFIG_X86_UV
ipipe_request_irq(ipipe_root_domain,
ipipe_apic_vector_irq(UV_BAU_MESSAGE),
__ipipe_do_IRQ, uv_bau_message_interrupt,
__ipipe_ack_apic);
#endif /* CONFIG_X86_UV */
ipipe_request_irq(ipipe_root_domain,
ipipe_apic_vector_irq(SPURIOUS_APIC_VECTOR),
__ipipe_do_IRQ, smp_spurious_interrupt,
__ipipe_noack_apic);
ipipe_request_irq(ipipe_root_domain,
ipipe_apic_vector_irq(ERROR_APIC_VECTOR),
__ipipe_do_IRQ, smp_error_interrupt,
__ipipe_ack_apic);
#ifdef CONFIG_X86_THERMAL_VECTOR
ipipe_request_irq(ipipe_root_domain,
ipipe_apic_vector_irq(THERMAL_APIC_VECTOR),
__ipipe_do_IRQ, smp_thermal_interrupt,
__ipipe_ack_apic);
#endif /* CONFIG_X86_THERMAL_VECTOR */
#ifdef CONFIG_X86_MCE_THRESHOLD
ipipe_request_irq(ipipe_root_domain,
ipipe_apic_vector_irq(THRESHOLD_APIC_VECTOR),
__ipipe_do_IRQ, smp_threshold_interrupt,
__ipipe_ack_apic);
#endif /* CONFIG_X86_MCE_THRESHOLD */
ipipe_request_irq(ipipe_root_domain,
ipipe_apic_vector_irq(X86_PLATFORM_IPI_VECTOR),
__ipipe_do_IRQ, smp_x86_platform_ipi,
__ipipe_ack_apic);
/*
* We expose two high priority APIC vectors the head domain
* may use respectively for hires timing and SMP rescheduling.
* We should never receive them in the root domain.
*/
ipipe_request_irq(ipipe_root_domain,
ipipe_apic_vector_irq(IPIPE_HRTIMER_VECTOR),
__ipipe_do_IRQ, smp_spurious_interrupt,
__ipipe_ack_apic);
ipipe_request_irq(ipipe_root_domain,
ipipe_apic_vector_irq(IPIPE_RESCHEDULE_VECTOR),
__ipipe_do_IRQ, smp_spurious_interrupt,
__ipipe_ack_apic);
#ifdef CONFIG_IRQ_WORK
ipipe_request_irq(ipipe_root_domain,
ipipe_apic_vector_irq(IRQ_WORK_VECTOR),
__ipipe_do_IRQ, smp_irq_work_interrupt,
__ipipe_ack_apic);
#endif /* CONFIG_IRQ_WORK */
#endif /* CONFIG_X86_LOCAL_APIC */
#ifdef CONFIG_SMP
ipipe_request_irq(ipipe_root_domain,
ipipe_apic_vector_irq(RESCHEDULE_VECTOR),
__ipipe_do_IRQ, smp_reschedule_interrupt,
__ipipe_ack_apic);
ipipe_request_irq(ipipe_root_domain,
ipipe_apic_vector_irq(CALL_FUNCTION_VECTOR),
__ipipe_do_IRQ, smp_call_function_interrupt,
__ipipe_ack_apic);
ipipe_request_irq(ipipe_root_domain,
ipipe_apic_vector_irq(CALL_FUNCTION_SINGLE_VECTOR),
__ipipe_do_IRQ, smp_call_function_single_interrupt,
__ipipe_ack_apic);
ipipe_request_irq(ipipe_root_domain,
IRQ_MOVE_CLEANUP_VECTOR,
__ipipe_do_IRQ, smp_irq_move_cleanup_interrupt,
__ipipe_ack_apic);
ipipe_request_irq(ipipe_root_domain,
ipipe_apic_vector_irq(REBOOT_VECTOR),
__ipipe_do_IRQ, smp_reboot_interrupt,
__ipipe_ack_apic);
#endif /* CONFIG_SMP */
/*
* Finally, request the remaining ISA and IO-APIC
* interrupts. Interrupts which have already been requested
* will just beget a silent -EBUSY error, that's ok.
*
*/
for (irq = 0; irq < IPIPE_NR_XIRQS; irq++)
ipipe_request_irq(ipipe_root_domain, irq,
__ipipe_do_IRQ, do_IRQ,
NULL);
}
这时候实时内核xenomai还没有运行,linux需要处理系统中所有的中断,__ipipe_enable_pipeline()将所有的中断注册到ipipe_root_domain中,原来的中断入口被ipipe拦截了,ipipe换一种方式将它们在这里注册,让ipipe去处理它们。(cat /proc/ipipe/Linux 能看到注册到ipipe_root_domain的所有中断及对应handler),这里所有的中断handler都是__ipipe_do_IRQ(),__ipipe_do_IRQ()和ipipe_request_irq()源代码如下:
static void __ipipe_do_IRQ(unsigned int irq, void *cookie)
{
void (*handler)(struct pt_regs *regs);
struct pt_regs *regs;
regs = raw_cpu_ptr(&ipipe_percpu.tick_regs);
regs->orig_ax = ~__ipipe_get_irq_vector(irq);
handler = (typeof(handler))cookie;
handler(regs);
}
int ipipe_request_irq(struct ipipe_domain *ipd,
unsigned int irq,
ipipe_irq_handler_t handler,
void *cookie,
ipipe_irq_ackfn_t ackfn)
{
……
if (ackfn == NULL)
ackfn = ipipe_root_domain->irqs[irq].ackfn;
ipd->irqs[irq].handler = handler;
ipd->irqs[irq].cookie = cookie;
ipd->irqs[irq].ackfn = ackfn;
ipd->irqs[irq].control = IPIPE_HANDLE_MASK;
……
return ret;
}
拿lapic定时中断LOCAL_TIMER_VECTOR来说,ipipe_request_irq()后
ipipe_root_domain->irqs[LOCAL_TIMER_VECTOR].handler = __ipipe_do_IRQ;
ipipe_root_domain->irqs[LOCAL_TIMER_VECTOR].cookie = smp_apic_timer_interrupt;
ipipe_root_domain->irqs[LOCAL_TIMER_VECTOR].ackfn = __ipipe_ack_apic;
ipipe_root_domain->irqs[LOCAL_TIMER_VECTOR].control = IPIPE_HANDLE_MASK;
当中断到来后由__ipipe_do_IRQ()调用执行handler(regs)即执行smp_apic_timer_interrupt(),这样和linux没有ipipe补丁时处理中断一样。实时内核还没有初始化,以前linux是怎样处理中断的现在还是怎样处理,没有改变。linux继续完成它的启动初始内存管理、进程等模块。等xenomai初始化的时候,ipipeline才会改变一些中断的处理方式,使它们的实时性得到保证。
那实时内核xenomai是什么时候初始化的?xenomai内核的初始化函数xenomai_init()在源码文件kernel/xenomai/init.c里,使用device_initcall宏声明如下:
device_initcall(xenomai_init);
和内核各种静态驱动一样,linux在start_kernel()最后会rest_init()来初始化各个驱动模块,从而会执行xenomai_init(),device_initcall宏怎样定义和rest_init()具体执行流程不展开说。
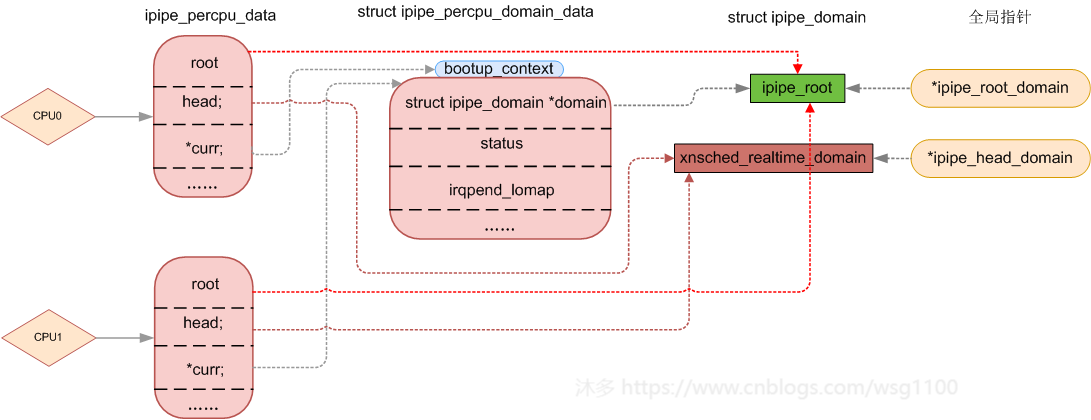
当xenomai初始化时,xenomai_init()调用mach_setup()来初始化xnsched_realtime_domain,设置name字段为"Xenomai",然后调用ipipe_register_head()将每个CPU上的pipe_percpu_data.head.domain指向xnsched_realtime_domain,并将全局指针*ipipe_head_domain指向xnsched_realtime_domain,此后xnsched_realtime_domain就是ipipe的head域了,具有最高优先级,中断到来后 __ipipe_dispatch_irq()就会按head优先的处理方式去处理中断,只是此时head域上还没有注册什么中断, 后面就是一个接一个的中断注册到head域,具体哪些中断,等特定场景用到再来分析。
static int __init xenomai_init(void)
{
……
ret = mach_setup(); /*xenomai域相关设置,中断,定时器,xnclock*/
if (ret)
goto cleanup_proc;
……
return ret;
}
static int __init mach_setup(void)
{
……
ipipe_register_head(&xnsched_realtime_domain, "Xenomai");
……
return ret;
}
void ipipe_register_head(struct ipipe_domain *ipd, const char *name)
{
BUG_ON(!ipipe_root_p || ipd == &ipipe_root);
ipd->name = name;
init_head_stage(ipd);/*初始化头域,设置Domain 设置context,将IPIPE_CRITICAL_IPI 中断交给head域*/
barrier();
ipipe_head_domain = ipd;/*重新指向 xnsched_realtime_domain*/
add_domain_proc(ipd);
pr_info("I-pipe: head domain %s registered.\n", name);
}
相反的,ipipe_unregister_head就是将ipipe_head_domain 指回作为linux的ipipe_root
void ipipe_unregister_head(struct ipipe_domain *ipd)
{
BUG_ON(!ipipe_root_p || ipd != ipipe_head_domain);
ipipe_head_domain = &ipipe_root;
smp_mb();
mutex_lock(&ipd->mutex);
remove_domain_proc(ipd);
mutex_unlock(&ipd->mutex);
pr_info("I-pipe: head domain %s unregistered.\n", ipd->name);
}
5.ipipeline中断传递
__ipipe_dispatch_irq(irq, flags)是ipipeline处理中断的关键,外部中断、软中断、虚拟中断都由它来分发处理,源代码如下:
void __ipipe_dispatch_irq(unsigned int irq, int flags) /* hw interrupts off */
{
struct ipipe_domain *ipd;
struct irq_desc *desc;
unsigned long control;
int chained_irq;
......
/*
* CAUTION: on some archs, virtual IRQs may have acknowledge
* handlers. Multiplex IRQs should have one too.
*/
if (unlikely(irq >= IPIPE_NR_XIRQS)) {
desc = NULL;
chained_irq = 0;
} else {
desc = irq_to_desc(irq);
chained_irq = desc ? ipipe_chained_irq_p(desc) : 0;
}
if (flags & IPIPE_IRQF_NOACK)
IPIPE_WARN_ONCE(chained_irq);
else {
ipd = ipipe_head_domain;
control = ipd->irqs[irq].control;
if ((control & IPIPE_HANDLE_MASK) == 0)
ipd = ipipe_root_domain;
if (ipd->irqs[irq].ackfn)
ipd->irqs[irq].ackfn(desc);
if (chained_irq) {
if ((flags & IPIPE_IRQF_NOSYNC) == 0)
/* Run demuxed IRQ handlers. */
goto sync;
return;
}
}
/*
* Sticky interrupts must be handled early and separately, so
* that we always process them on the current domain.
*/
ipd = __ipipe_current_domain;
control = ipd->irqs[irq].control;
if (control & IPIPE_STICKY_MASK)
goto log;
/*
* In case we have no registered head domain
* (i.e. ipipe_head_domain == &ipipe_root), we always go
* through the interrupt log, and leave the dispatching work
* ultimately to __ipipe_sync_pipeline().
*/
ipd = ipipe_head_domain;
control = ipd->irqs[irq].control;
if (ipd == ipipe_root_domain)
/*
* The root domain must handle all interrupts, so
* testing the HANDLE bit would be pointless.
*/
goto log;
if (control & IPIPE_HANDLE_MASK) {
if (unlikely(flags & IPIPE_IRQF_NOSYNC))
__ipipe_set_irq_pending(ipd, irq);
else
dispatch_irq_head(irq);
return;
}
ipd = ipipe_root_domain;
log:
__ipipe_set_irq_pending(ipd, irq);
if (flags & IPIPE_IRQF_NOSYNC)
return;
/*
* Optimize if we preempted a registered high priority head
* domain: we don't need to synchronize the pipeline unless
* there is a pending interrupt for it.
*/
if (!__ipipe_root_p &&
!__ipipe_ipending_p(ipipe_this_cpu_head_context()))
return;
sync:
__ipipe_sync_pipeline(ipipe_head_domain);
}
__ipipe_dispatch_irq()处理分两种情况:
1.只有root,没有head,(pipe_head_domain == ipipe_root_domain ==&ipipe_root就是xenomai还没启动、xenomai启动失败,或者只打了ipipe补丁没有打xenomai补丁等情况),__ipipe_dispatch_irq()仅在每个 CPU log(ipipe_percpu_domain_data中的bitmap)中设置为挂起,然后保留中断帧,后面由__ipipe_sync_pipeline()从挂起的bitmap中取出一个个中断,然后执行irq handler。
2.只有root,也注册了head,这时候head的中断通过 fast dispatcher通道处理;root中断还是通过 CPU log方式处理。
当一个中断到来后,先取出中断描述符desc,然后判断head Domain有没有注册了这个中断,没有的话去root域看看又没有这个中断的ack函数,有的话,先调用ackfn()把中断清了再说。
接下来,如果ipipe_head_domain与ipipe_root_domain相等,即没有注册实时内核,中断通过log处理,跳转到log执行,将中断在ipipe_root_domain中挂起,以便稍后将它们提供给Linux,ipipe domian管理说到挂起步骤,先将irqpend_lomap中第irq个bit置位,irqpend_lomap中的第irq/64这个bit置位,irqpend_himap中的第irq/64/64这一个bit置位,然后all[irq]++,这就完成了一个中断的挂起。log中完成中断挂起操作后看看head中有没有中断挂起,如果没有就直接返回,中断处理结束,如果head中有中断挂起那就必须尽快处理,接着调用__ipipe_sync_pipeline(ipipe_head_domain)处理head中的中断。
如果ipipe_head_domain与ipipe_root_domain不相等,看head域中这个中断有没有对应的IPIPE_HANDLE_MASK标志,有说明这个中断是需要head调用handler处理的,然后再看这个中断有没有IPIPE_IRQF_NOSYNC标志,有的话说明这个中断在head域不紧急,先在head挂起以后处理。不然的话立刻调用dispatch_irq_head(irq)通过快速通道让head域执行head->irqs[irq].handler,整个执行流程图如下:
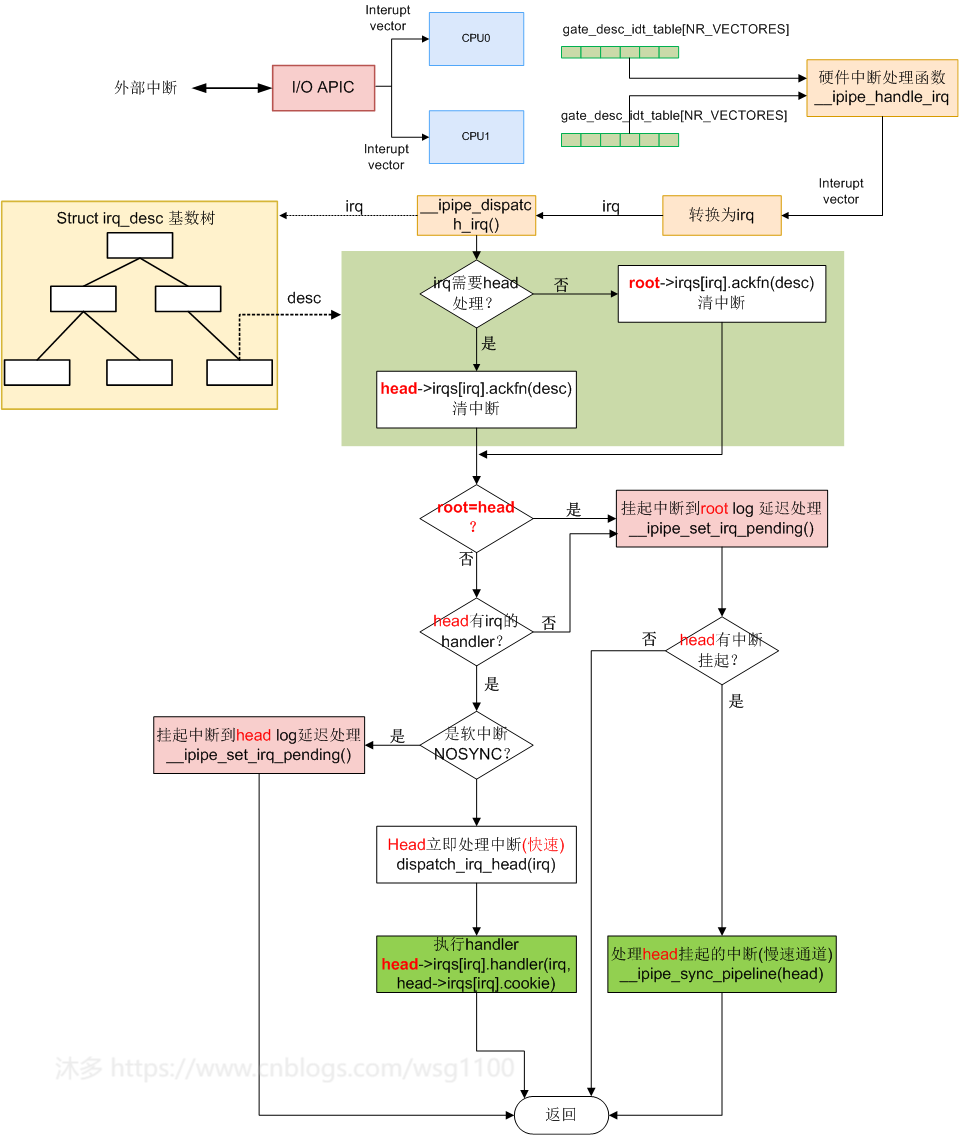
流程图中判断一个域有没有中断挂起就是判断irqpend_himap有没有哪个bit置位,等于0,说明没有有中断挂起。
static inline int __ipipe_ipending_p(struct ipipe_percpu_domain_data *pd)
{
return pd->irqpend_himap != 0;
}
5.1 head慢速路径中断处理
root域或者head的中断由函数__ipipe_set_irq_pending()挂起后什么时候处理呢?流程图中当检测到head有挂起的中断就调用 __ipipe_sync_pipeline(head)(慢速处理通道)来处理挂起的中断。
static inline void __ipipe_sync_pipeline(struct ipipe_domain *top)
{
if (__ipipe_current_domain != top) {
__ipipe_do_sync_pipeline(top);
return;
}
if (!test_bit(IPIPE_STALL_FLAG, &ipipe_this_cpu_context(top)->status))
__ipipe_sync_stage();
}
如果CPU上运行着root的任务,此时__ipipe_current_domain是root,这时,一个外部中断到来,经过上面的流程处理到 __ipipe_sync_pipeline(head),这时候由于执行上下文__ipipe_current_domain不是head就会调用__ipipe_do_sync_pipeline(top)继续处理head中断。
如果中断到来时CPU执行上下文的是head任务,会先判断head->status中IPIPE_STALL_FLAG有没有置位,为什么要判断?因为可能一个中断到来后,head去处理中断,中断还没处理完,又来一个head域的中断,head的中断又很重要,不能丢弃,这时候就会出现问题,所以需要判断head有没有在处理中断中。IPIPE_STALL_FLAG没有置位就调用__ipipe_sync_stage()处理当前域(head)上的中断.
void __ipipe_do_sync_pipeline(struct ipipe_domain *top)
{
struct ipipe_percpu_domain_data *p;
struct ipipe_domain *ipd;
......
if (__ipipe_ipending_p(p)) {
if (ipd == ipipe_root_domain)
__ipipe_sync_stage();
else {
/* Switching to head. */
p->coflags &= ~__IPIPE_ALL_R;
__ipipe_set_current_context(p);//切换上下文
__ipipe_sync_stage();
__ipipe_set_current_domain(ipipe_root_domain);
}
}
......
}
__ipipe_do_sync_pipeline()和__ipipe_sync_stage()都是处理head中挂起的中断的,具体调用谁是根据CPU执行上下文__ipipe_current_domain来决定,如果__ipipe_current_domain是root那就调用__ipipe_do_sync_pipeline(),__ipipe_do_sync_pipeline()中会先将CPU上下文__ipipe_current_domain从root切换到head然后再调用__ipipe_sync_stage()处理;如果__ipipe_current_domain本来就是head,那就不用切换当前域直接调用__ipipe_sync_stage()处理。(这里说的上下文切换只是将ipipe_percpu中的curr指向head)
static inline void __ipipe_sync_stage(void)
{
if (likely(__ipipe_sync_check))
__ipipe_do_sync_stage();
}
void __ipipe_do_sync_stage(void)
{
struct ipipe_percpu_domain_data *p;
struct ipipe_domain *ipd;
int irq;
p = __ipipe_current_context;
respin:
ipd = p->domain;
__set_bit(IPIPE_STALL_FLAG, &p->status);
......
for (;;) {
irq = __ipipe_next_irq(p);
if (irq < 0)
break;
barrier();
if (test_bit(IPIPE_LOCK_FLAG, &ipd->irqs[irq].control))
continue;
if (ipd != ipipe_head_domain)
hard_local_irq_enable();
if (likely(ipd != ipipe_root_domain)) {
ipd->irqs[irq].handler(irq, ipd->irqs[irq].cookie);
__ipipe_run_irqtail(irq);
hard_local_irq_disable();
} else if (ipipe_virtual_irq_p(irq)) {
irq_enter();
ipd->irqs[irq].handler(irq, ipd->irqs[irq].cookie);
irq_exit();
root_stall_after_handler();
hard_local_irq_disable();
} else {
ipd->irqs[irq].handler(irq, ipd->irqs[irq].cookie);
root_stall_after_handler();
hard_local_irq_disable();
}
p = __ipipe_current_context;
if (p->domain != ipd) {
IPIPE_BUG_ON(ipd == ipipe_root_domain);
if (test_bit(IPIPE_STALL_FLAG, &p->status))
return;
goto respin;
}
}
if (ipd == ipipe_root_domain)
trace_hardirqs_on();
__clear_bit(IPIPE_STALL_FLAG, &p->status);
}
首先设置状态标志IPIPE_STALL_FLAG,然后是一个大的for循环,不断的__ipipe_next_irq()取出挂起的中断irq,在ipipe domian管理说过中断挂起的步骤,先将irqpend_lomap中第irq个bit置位,irqpend_lomap中的第irq/64这个bit置位,irqpend_himap中的第irq/64/64这一个bit置位,然后all[irq]++.
static inline int __ipipe_next_irq(struct ipipe_percpu_domain_data *p)
{
int l0b, l1b, l2b;
unsigned long l0m, l1m, l2m;
unsigned int irq;
l0m = p->irqpend_himap;
if (unlikely(l0m == 0))
return -1;
l0b = __ipipe_ffnz(l0m);
l1m = p->irqpend_mdmap[l0b];
if (unlikely(l1m == 0))
return -1;
l1b = __ipipe_ffnz(l1m) + l0b * BITS_PER_LONG;
l2m = p->irqpend_lomap[l1b];
if (unlikely(l2m == 0))
return -1;
l2b = __ipipe_ffnz(l2m);
irq = l1b * BITS_PER_LONG + l2b;
__clear_bit(irq, p->irqpend_lomap);
if (p->irqpend_lomap[l1b] == 0) {
__clear_bit(l1b, p->irqpend_mdmap);
if (p->irqpend_mdmap[l0b] == 0)
__clear_bit(l0b, &p->irqpend_himap);
}
return irq;
}
从挂起bitmap中取出irq就是先判断irqpend_himap,如果irqpend_himap==0说明没有中断挂起,直接返回-1,例如ipipe domian管理中的挂起图,取出irqpend_himap使用__ipipe_ffnz函数获取irqpend_himap中第0bit置位l0b=0,然后索引irqpend_mdmap[l0b]得到\(l1m=0x40000003\),使用__ipipe_ffnz函数获取irqpend_himap中第0bit置位$ temp=0 \(,然后计算\)l1b = temp + l0b* 64 =0\(,\)l2m =$ p->irqpend_lomap[l1b] = p->irqpend_lomap[0] \(=0x00000004\), 使用__ipipe_ffnz函数获取irqpend_lomap中第2bit置位\(l2b=2\),最后得到\(irq = l1b * BITS\_PER\_LONG + l2b = 0*64+2 =2\),这样就得到挂起的irq 2,得到irq后将irq从bitmap中清除,用irq去索引注册到head域的中断处理项(ipipe初始化流程),然后调用handler: ipd->irqs[2].handler(irq, ipd->irqs[2].cookie);同样继续调用__ipipe_next_irq()就会取到66,4042...
取出irq后,先判断irq的类型如果是虚拟中断,需要先进入中断上下文,然后再调用中断处理函数,处理完成后退出中断上下文,这里注意xenomai作为head安装后,Linux内核无法屏蔽CPU中的中断,root只能虚拟地禁用中断,head通过在CPU的状态寄存器中禁用它们来防止中断才是真正的禁止中断。
46行,执行中断handler返回时,由于中断handler具体做了什么操作我们不知道,可能是进程切换、重新调度等,当前CPU上下文可能已经从head降级到了root,或者移到了不同的CPU上运行。这时候需要重新获取当前CPU上下文__ipipe_current_context,如果是head域降级到了root域就处理root域挂起的中断。否者继续处理新CPU上的head中断,或返回。
5.2 head快速路径中断处理
快速路径直接执行head->irqs[irq].handler(irq, head->irqs[irq].cookie),同样执行玩handler后需要判断当前执行上下文,当前CPU head有米有挂起的中断需要处理,保证head域的实时性;
static void dispatch_irq_head(unsigned int irq) /* hw interrupts off */
{
struct ipipe_percpu_domain_data *p = ipipe_this_cpu_head_context(), *old;
struct ipipe_domain *head = p->domain;
.......
head->irqs[irq].handler(irq, head->irqs[irq].cookie);/*执行handler*/
.......
if (likely(__ipipe_current_context == p)) {
if (old->domain == head) {
if (__ipipe_ipending_p(p))
__ipipe_sync_stage();
return;
}
__ipipe_set_current_context(ipipe_this_cpu_root_context());/*切换回root*/
}
/*
* We must be running over the root domain, synchronize
* the pipeline for high priority IRQs (slow path).
*/
__ipipe_do_sync_pipeline(head);
}
6.RTDM驱动的中断注册流程
实时驱动的中断由head处理,那就应该注册到xnsched_realtime_domain,通过驱动API层层调用,最后还是调用ipipe_request_irq将中断处理函数注册到xnsched_realtime_domain,调用流程如下。
RT Driver:
rtdm_irq_request()
->nintr_attach(irq_handle, arg);
->intr_irq_attach(intr);
->ret = ipipe_request_irq(&xnsched_realtime_domain,
intr->irq, handler, intr,
(ipipe_irq_ackfn_t)intr->iack);
7. Dovetail
以上就是xenomai ipipe工作机制,由于ipipe维护困难,跟不上主线内核的变化,为此xenomai社区2016年开始开发ipipe的替代品dovetail,自linux 5.4版本起被更易维护的dovetail替代,伴随dovetail开发诞生的测试evl内核成为了今天的xenomai4内核,dovetail和ipipe本质工作没有变化,只是实现的差异,xenomai官方也给dovetail编写了完整的文档,详见https://v4.xenomai.org/dovetail/。
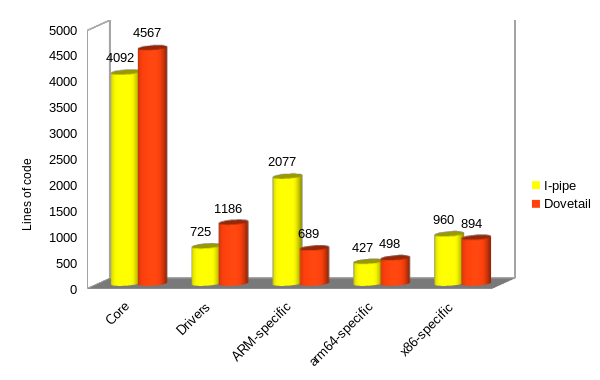
有了dovetail,让我们自己在linux内核编写属于自己的实时调度核成为可能,不仅如此,你完全可以将现有的RTOS诸如RT-Thread、uCOS、FreeRTOS等小型操作系统移植到linux内核使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号