
【转载】DSP 缓存机制及影响测试
本文主要以DSP讲解cache原理,但原理与CPU是相通的,故转载,原文地址:https://blog.csdn.net/qq_39376747/article/details/112794096

DSP 缓存机制
注:本文说明的DSP基于TI c6000系列的C66x DSP
1.Cache基础
一般来说我们的代码往往是存放在我们的磁盘设备中(EMMC、SSD、Flash等),当我们运行程序的时候,我们需要将代码加载到我们的内存(DDR)中去运行,之后CPU再从内存中加载代码执行,但是相比较而言计算机CPU的运行速率与我们的DDR内存的运行速率,二者有着近百倍的速度差异,所以当我们实际运行一段代码的时候,CPU试图从内存中读取或写入一段数据的时候,往往会因为二者的速度差异而白白去等待造成性能上的浪费,所以为了解决这个问题,我们设计了缓存机制,即在CPU和内存之间增加一个速度极快但是容量极小的设备,我们称这段存储为Cache,CPU会首先从cache中查找对应地址的数据是否缓存在cache 中。如果其数据缓存在cache中,直接从cache中拿到数据并返回给CPU。
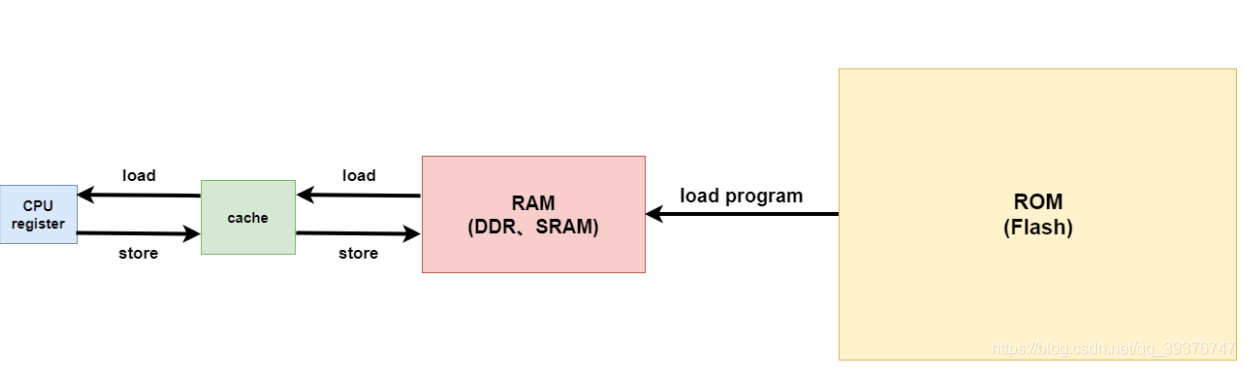

1.1 Cache命中和缺失
当CPU想要访问一段数据的时候,会先访问缓存,当我们需要的数据在cache中有被缓存到,我们就称为一次“命中(hit)”,反之当数据不存在的时候,我们称为一次”缺失(miss)“。当我们的计算机系统存在多级缓存的时候,计算机在进行数据访问的时候会逐级进行查找,即:CPU首先从 L1 cache 进行查找,当数据幸运躺在L1 cache时,我们就将数据返回给CPU(一次缓存命中),但是当L1 cache不存在这段数据的话,CPU会将这一次查找延伸到下一级缓存L2 cache,那么L1 cache的访问就是一次缓存缺失;CPU在L2 cache进行查找的时候,如果命中了就会将数据返回给CPU(数据给不给L1 cache是基于L1的分配策略的,后面讲),如果缺失就继续延伸到下一级缓存(如果不存在后续缓存就到内存中查找)
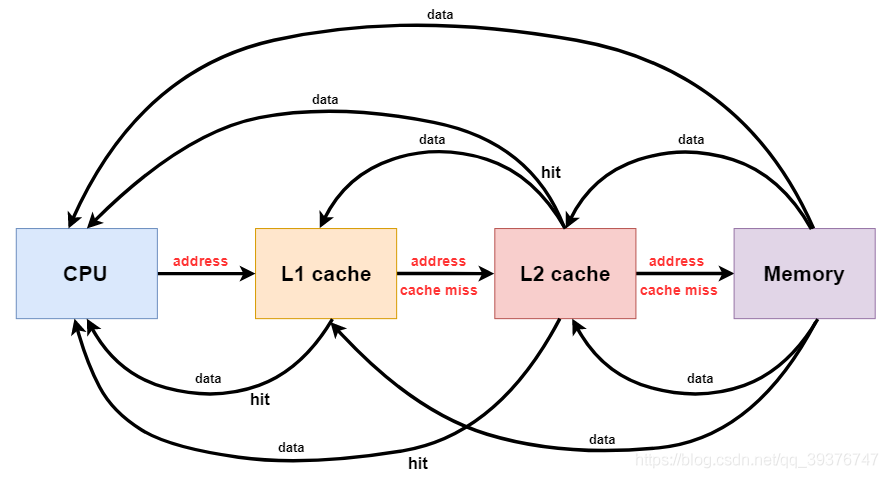
1.2 Cache line
我们在看一个芯片的属性的时候,往往会看到一条cache size,这个代表了我们的缓存的大小也表示缓存的数据容量,而cache line表示的就是缓存行,它的大小称为cache line size。cache line是操作cache的最小单位,这句话如何理解呢,假设我们的cache line是32字节,我们需要读取的数据的大小为4字节,当我们缓存这段数据的时候,cache不会只单单缓存4字节,而是一次缓存32字节(一行的数据量),这就好比缓存是一块蛋糕8斤,我们平均切了8刀,这每一块一斤就相当于一个缓存行,你想吃一小块二两,不可以,吃二两也给你一斤。所以cache每一次操作数据的最小单位名就是一个cache line size。
1.3 Cache分类
对于缓存的分类,从存储层次上来说,cache可以分为L1 cache、L2 cache、L3 cache,其中级数越靠后则速度越慢当容量越大;按照数据映射的方式不同,我们可以将缓存分为直接映射缓存、组相连缓存、全相连缓存。下面我们重点介绍一下这几种分类:
1.3.1 直接映射缓存(Direct-Mapped Caches)
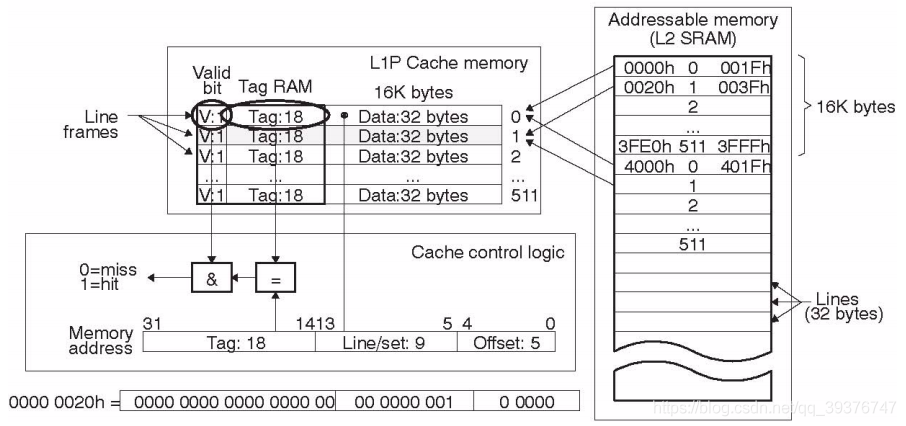
在了解什么是直接映射缓存之前我们需要先理解上面这一幅图的含义,我们上图的右边的L2 SRAM 可以理解为我们的一块存储区域,当CPU读取一个数据时会先从左边的L1 cache中去找,当没有找到我们想要的内容时即为一个Miss,就会去右边的SRAM中去找然后将SRAM中的这一块区域缓存到cache中。我们的地址是32位的,分成了三个部分:Offset(5位)、Line/set(9位)、Tag(18位)。其中Offset表示我们的偏移,大小为5表示我们的当前缓存一行可以存放2的5次方(32)字节大小的数据量,Offset与内存地址的对应关系如下图所示。
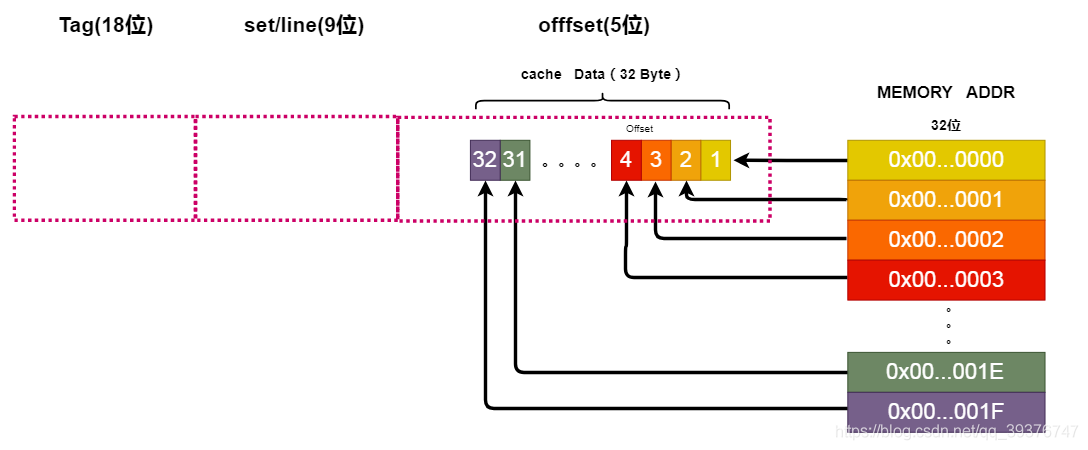
以此类推,当我们的地址的第6位为1时,表示进入了下一层Line。我们就在 Line/set 部分开始进行索引。当我们的 Line/set 部分与 Offset 部分全部索引完毕后,我们会对 Tag 部分和 标志位Valld 进行比较,当我们cache中的 Tag 部分与Memory address的 Tag 部分相等并且 标志位Valld 为1(即:缓存有效),这表示cache中存在当前Memory address的内容,视为一次命中(hit),否则视为一次未命中(miss)。
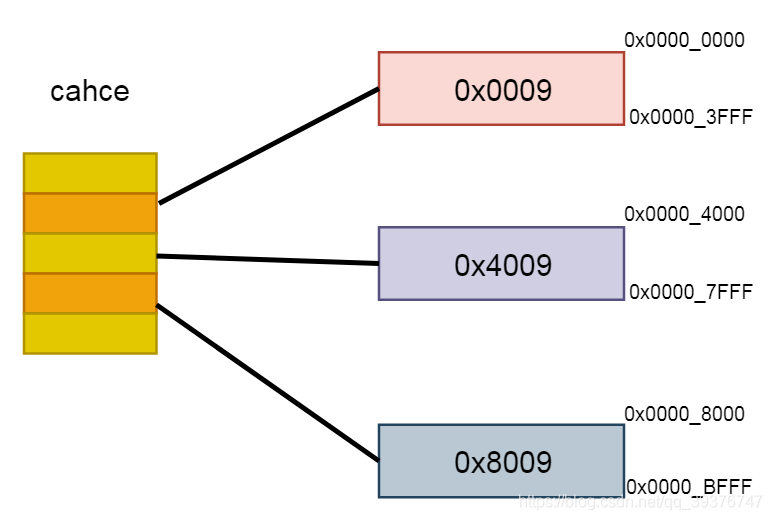
假设我们的cahce的大小是16K的,现在有三块内存区域,我们可以看到图中的这三块内存空间都全部覆盖了整个cache,当我们试图访问0x0009、0x4009、0x8009这三个地址的时候,我们会发现这三个地址空间的 Line/set 部分与 Offset 部分都相等,只有 Tag部分不同。因此,这3个地址对应的cache line是同一个。所以,当我们访问0x0009地址时,cache会缺失,然后数据会从主存中加载到cache中第0行cache line。当我们访问0x4009地址时,依然索引到cache中第0行cache line,由于此时cache line中存储的是地址0x0009地址对应的数据,所以此时依然会cache缺失。然后从主存中加载0x4009地址数据到第0行cache line中。同理,继续访问0x8009地址,依然会cache缺失。这就相当于每次访问数据都要从主存中读取,所以cache的存在并没有对性能有什么提升。访问0x4009地址时,就会把0x0009地址缓存的数据替换。这种现象叫做cache颠簸(cache thrashing)。而对于这种一对一缓存的方式的cache我们称为直接映射缓存。
1.3.2 组相连缓存( Set-Associative Caches)
理解组相连缓存,我们需先要了解什么是路(Way),我们将cache平均分成多份,每一份就是一路。因此,两路组相连缓存就是将cache平均分成2份,四路组相连缓存就是将cache平均分成4份。在DSP C66X中,L1D cache 是两路组相连缓存,L2 cache是四路组相连缓存。
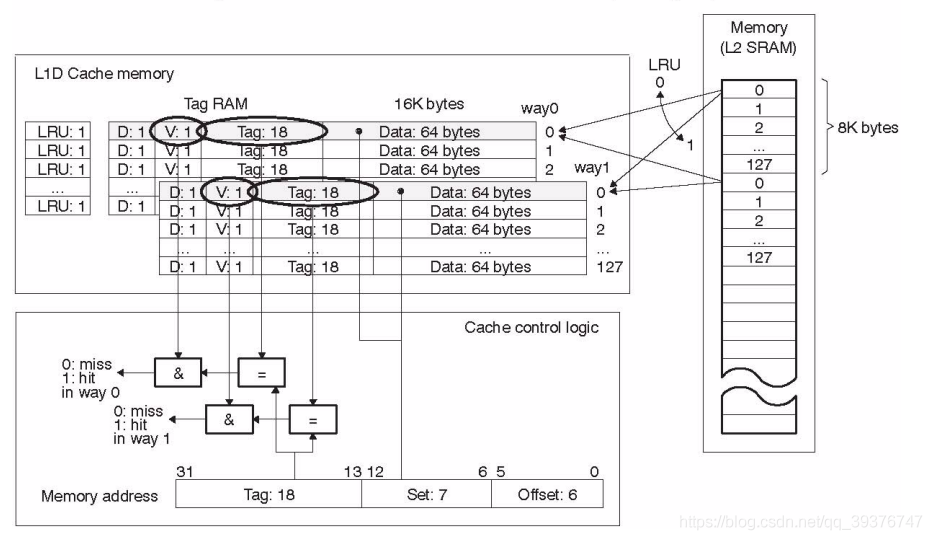
针对上一节我们分析的那个内存访问示例,当我们使用两路组相连缓存的时候,现在0x0009地址的数据可以被加载到way 0x4009可以被加载到way。这样就在一定程度上避免了直接映射缓存的尴尬境地。在两路组相连缓存的情况下,0x0009和0x4009地址的数据都缓存在cache中。如果我们是4路组相连缓存,后面继续访问0x8009,也可能被缓存。
1.3.3 全相连缓存(Full associative cache)
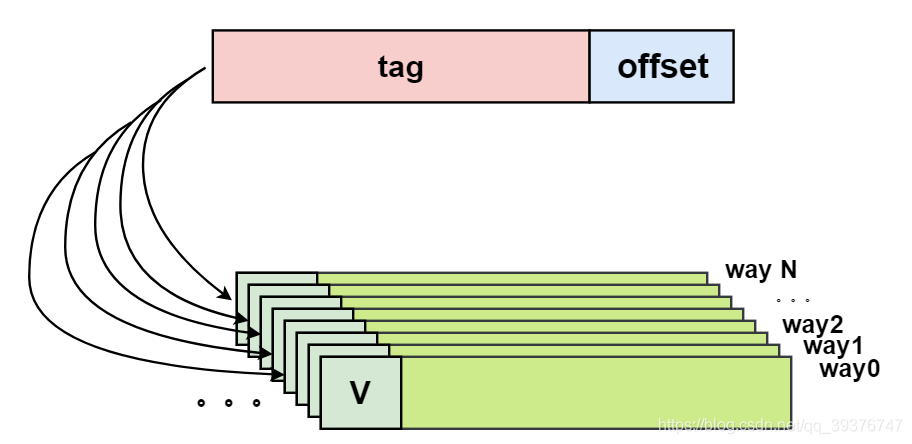
全相连缓存的cache line都在同一行,因此地址中不需要set/line部分,我们根据地址中的tag部分和所有的cache line对应的tag进行比较(硬件上可能并行比较也可能串行比较)。哪个tag比较相等,就意味着命中某个cache line。因此,在全相连缓存中,任意地址的数据可以缓存在任意的cache line中。所以,这可以最大程度的降低cache颠簸的频率。但是硬件成本较高。C66X中不存在这种缓存。
1.4 Cache更新策略(Cache update policy)
当我们的Cache在命中的时候,会涉及到cache的更新策略(当然命中也分读命中和写命中,读操作不涉及缓存更新,也就不存在什么更新策略),Cache的更新策略分为写直通和写回。
1.4.1 写直通(write through)
当CPU要写一个数据的时候并在Cache命中时,我们会更新cache中的数据并更新内存中的数据,这样cache和内存中的数据会始终保持一致,不会存在脏位。
1.4.2 写回(write back)
当CPU要写一个数据的时候并在Cache命中时,我们只会更新cache中的数据,除非我们cache line被替换或者说我们进行缓存同步操作,不然内存的数据不会更新,同时当我们更新cache中的数据时,我们还会将当前的cache line标记为“脏”,即 dirty bit 置一,表示当前缓存行内容更新过。在cache执行写回策略时,可能存在cache和内存不同的情况。所以我们需要注意缓存一致性的问题。
1.5 Cache分配策略(Cache allocation policy)
当CPU在访问cache时发生了缺失时,cache会依据当前缓存的分配策略来进行数据的缓存操作,一般分为读分配和写分配。
1.5.1 读分配(read allocation)
当我们的缓存支持读分配时,在发生cache缺失的时候,缓存会分配一个缓存行(cache line)来缓存源于下一次存储设备的数据。
1.5.2 写分配(write allocation)
当我们的缓存支持写分配时,我们首先从主存中加载数据到cache line中(相当于先做个读分配动作),然后会更新cache line中的数据。当是当我们不支持写分配时,写指令只会更新内存的数据。
2 一级程序内存和缓存
2.1. 一级程序(L1P)内存和缓存的用途
1级程序(L1P)存储器和缓存的目的是使代码执行的性能最大化。 L1P缓存的可配置性提供了许多系统所需的灵活性。L1P高速缓存对于促进以快速时钟速率获取程序代码是必要的,以便维持较大的系统内存。 高速缓存负责隐藏与读取和写入较慢的系统内存相关的延迟。
2.1.1 功能
L1P内存和缓存提供了使用C66x CorePac的设备所需的内存灵活性。可以将部分或全部L1P转换为缓存。 L1P支持4K,8K,16K和32K的缓存大小。L1P高速缓存通过从L1P内存映射的顶部开始向下进行工作,将内存从RAM转换为高速缓存。 解释一下,L1P存储器的最高地址首先成为高速缓存。
• 当配置为告诉缓存时,L2内存是具有32字节高速缓存线的直接映射高速缓存
• 可完全配置为高速缓存或SRAM
• L2 存储器控制器具有纠错码(ECC)和 ED 机制
• 不支持错误校正或检测
• L2内存的页大小为2K
2.1.2 L1P缓存架构
L1P高速缓存是直接映射的高速缓存,这意味着系统中的每个物理内存位置在其可能驻留的高速缓存中都有一个可能的位置。 当DSP尝试获取一段代码时,L1P必须检查所请求的地址是否位于L1P高速缓存中。 为此,将DSP提供的32位地址划分为三个字段(tag, set, and offset),如下图所示。

5位的偏移量说明L1P行大小为32个字节。 高速缓存控制逻辑忽略地址的位0到4。 set字段指示数据将驻留的L1P缓存行地址(如果已缓存)。 设置字段的宽度取决于配置为缓存的L1P的数量。 L1P使用set字段来查找并检查标签中是否有来自该地址的任何已缓存数据以及有效位,该有效位指示标签中的地址是否实际上表示缓存中保存的有效地址。标签字段是地址的上部,用于标识数据元素的真实物理位置。 在程序读取时,如果标签匹配并且设置了相应的有效位,则为“命中”,并且直接从L1P缓存位置读取数据并将其返回给DSP。 否则,这是一个“缺失”,请求将被发送到L2·,从系统中的位置获取数据。 遗漏可能会或可能不会直接导致DSP停顿。
2.2 一级数据(L1 D)内存和缓存的用途
L1D存储器和高速缓存的目的是使数据处理的性能最大化。 L1D存储器和高速缓存的可配置性提供了在系统中使用L1D高速缓存或L1D存储器的灵活性。C66x L1D存储器和高速缓存体系结构允许将L1D的部分或全部转换为读分配,回写,双向集关联高速缓存。 高速缓存对于促进以全DSP时钟速率读写数据是必需的,同时仍具有较大的系统内存。 隐藏与读取和写入较慢的系统内存相关的大部分延迟是缓存的责任。
2.2.1 特征
L1D内存和缓存提供以下功能:
• 当配置为告诉缓存时,L2内存是具有64字节高速缓存线的2路组关联高速缓存
• 可完全配置为高速缓存或SRAM
• L2 存储器控制器具有纠错码(ECC)和 ED 机制
• 不支持错误校正或检测
• L2内存的页大小为2K
2.2.2 L1 D缓存架构
L1D高速缓存是双向设置关联高速缓存,这意味着系统中的每个物理内存位置在高速缓存中可以驻留的位置都有两个可能的位置。 当DSP尝试访问一条数据时,L1D高速缓存必须检查请求的地址是否以L1D高速缓存的任何一种方式驻留。 为此,DSP提供的32位地址被分为六个字段,如下图所示。

2.3 总结
c66x的一级缓存分为一个可分配的32K的L1D cache和一个可分配的32K的L1P cache,其中L1P是一个直接映射缓存,支持读分配无写分配,Line size的大小为32字节;L1D是一个两路组相干缓存,支持读分配和写回操作,Line size的大小为64字节。
3 二级程序内存和缓存
3.1 二级程序(L2)内存和缓存的用途
L2存储器控制器在较快的1级存储器(L1D,L1P)和较慢的外部存储器之间提供了片上存储器解决方案。 其优点在于,它支持比L1存储器更大的存储器大小,同时提供比外部存储器更快的访问速度。与L1存储器类似,您可以将L2配置为同时提供缓存和非缓存(即可寻址)存储器。
3.2 特征
L2内存和缓存提供以下功能:
• 当配置为告诉缓存时,L2内存是具有128字节高速缓存线的4路组关联高速缓存
• 只有256KB的 L2 内存可以配置为cache或SRAM
• L2 存储器的32KB总是映射为SRAM
• L2 存储器控制器具有纠错码(ECC)和 ED 机制
• L2内存控制器支持硬件预取,还提供带宽管理、内存保护和掉电功能
• L2内存的页大小为16K
4 cache相关寄存器
4.1 L1P相关寄存器
AM 5728关于DSP C66x核心相关的控制寄存器分为3组,每一组寄存器控制一种类型的cache,其中L1P cache相关的寄存器如下:
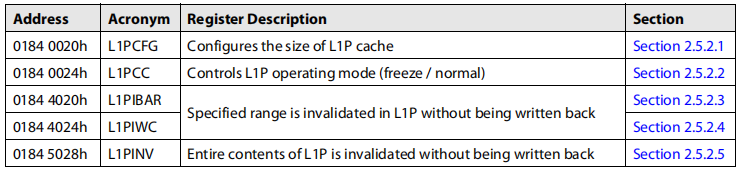
L1P配置寄存器(L1PCFG)
L1P配置寄存器(L1PCFG)控制L1P缓存的大小,如下图所示:
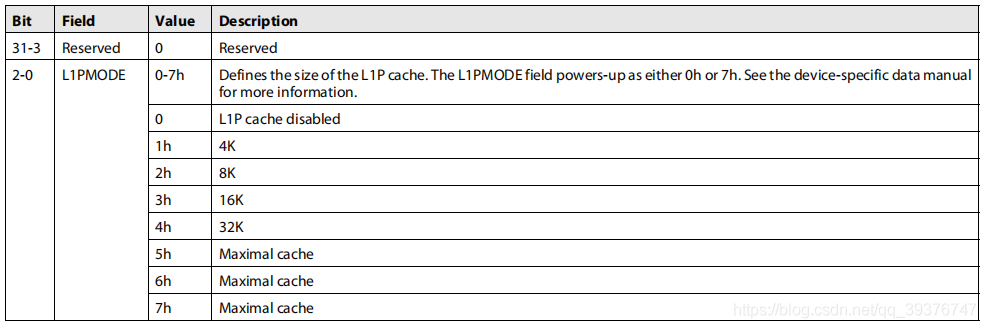
该寄存器可以设置L1Pcache的模式,当该寄存器的02位设置为0时表示该缓存不使能,设置为14表示不同大小的cache空间,设置为5~7表示最大的cache空间。
L1P缓存控制寄存器 (L1PCC)
L1PCC缓存控制寄存器(L1PCC)控制L1P是冻结还是未冻结。

该寄存器可以设置L1P cache的冻结模式,其中第0位(OPER)设置为1表示使能冻结模式,设置为0不使能;第16位是只读位,存储上一次OPER位的值。
L1P无效的基址寄存器(L1PIBAR)
L1P无效基地址寄存器(L1PIBAR)定义了相关操作将作用于的块无效的基地址。

L1P无效字数寄存器(L1PIWC)
L1P无效字计数寄存器(L1PIWC)定义了相干运算将要作用于的块无效的大小。 大小以32位字定义。

通过该寄存器我们可以设置块无效的字数。
L1P无效寄存器(L1PINV)
L1P失效寄存器(L1PINV)控制L1P缓存的全局失效,如下图所示。

该寄存器可以设置L1P cache line的失效,其中第0位设置为1表示所有缓存行失效,设置为0表示缓存行为正常模式。
4.2 L1D相关寄存器
L1D cache支持写回操作,所以L1D包含的寄存器会多几组,具体如下:
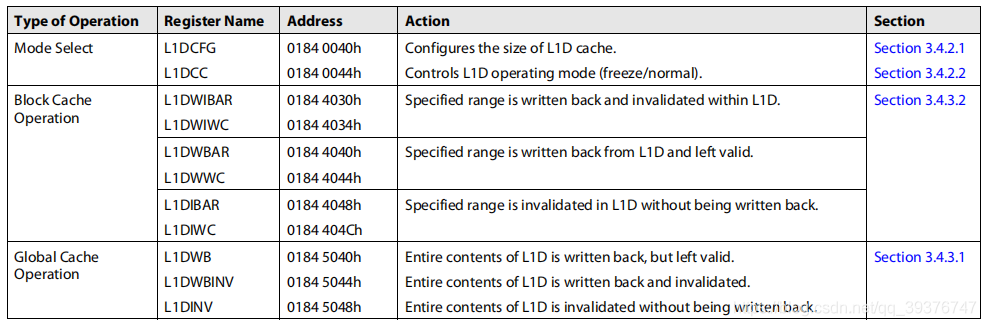
在这其中L1DCFG、L1DCC、L1DIBAR、L1DIWC、L1DINV的作用于L1P cache寄存器相似,所以在此不做说明。在此我说明一下剩下的6个寄存器.
L1D写回基地址寄存器(L1DWBAR)

定义L1D块写回操作的基地址。
L1D写回寄存器(L1DWB)

该寄存器设置将cache里的内容写回到下一级内存中,当寄存器第0位设置为1时,则会将所有的脏行写回。
L1D写回无效寄存器(L1DWBINV)

该寄存器设置将cache里的内容写回到下一级内存中,并将该缓存行设置为失效,当寄存器第0位设置为1时,则会将所有的脏行写回,并使缓存行失效。
L1D写回基地址寄存器(L1DWBAR)
L1D回写基地址寄存器(L1DWBAR)定义了将回写的块的基地址。

定义L1D块写回操作的基地址。
L1D写回无效字计数寄存器(L1DWIWC)
L1D写回无效字计数寄存器(L1DWIWC)定义了将被写回并无效的块的大小。 大小以32位字定义,如下图所示。 L1DWIBAR地址和L1DW1WC字数的组合所触及的所有高速缓存行都将无效,而只回写指定的数据。

4.3 L2相关寄存器
L2寄存器组与L1D相似,具体如下:
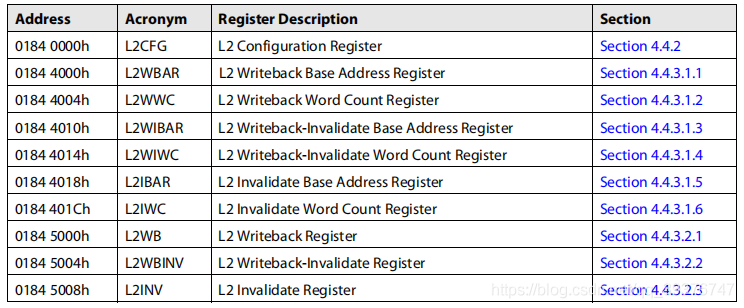
这里大部分寄存器与L1D的寄存器相似,在这里不做介绍,我们着重说明一个寄存器是L2CFG,该寄存器与L1DCFG和L1PCFG存在较大差异。具体如下。
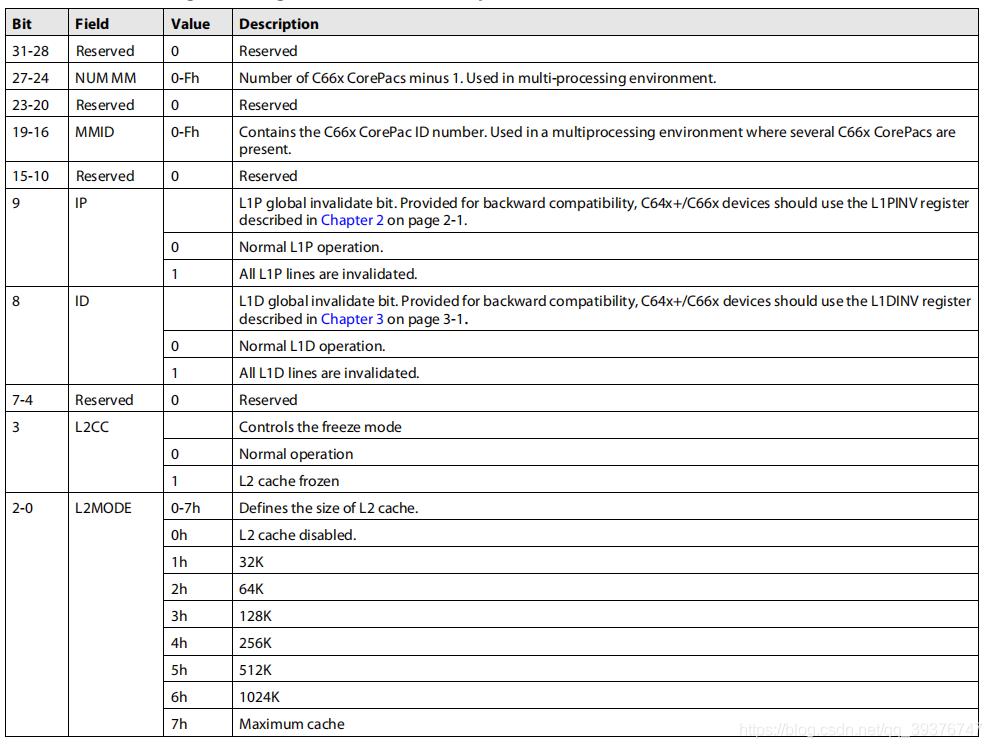
该寄存器除了配置L2缓存的一些属性,还可以操作L1D和L1P
4.4 MARn寄存器组
4.1~4.3介绍的寄存器均为设置cache本身的寄存器,但是若要使我们的内存能够真正缓存到cache中,除了需要设置我们的cache以外,还需配置我们需要缓存的内存段的可缓存性,只有当我们将内存段的可缓存性设置为缓存使能,我们这块内存中存储的内容才会被缓存至cache,MAR寄存器组就是完成内存段的属性设置。

MARn寄存器组是一组寄存器,这里n的取值为0~255,这256个寄存器每一个可以设置一块16M的内存空间的属性。如下:
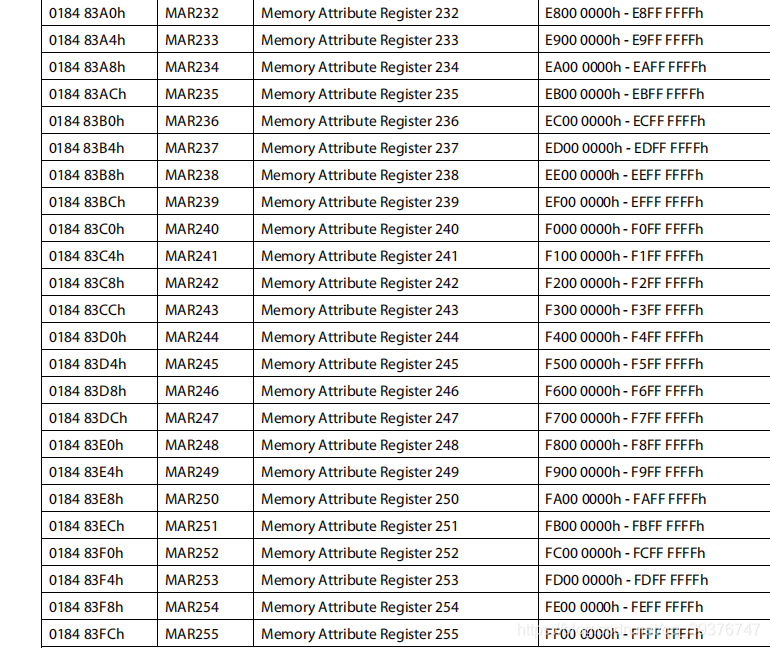
例如我们需要缓存的数据段是0xF800_0000 ~ F900_0000,则我们需要找到这段内存所对应的寄存器即 MAR248 ,之后我们只需将该寄存器的第0位(PC位)设置为1(可缓存使能)即可。
5.缓存的使用
在DSP复位的时候,默认会以最大缓存量使能L1 cache,L2cache则全部设置为SRAM,但这样我们内存中的内容实际上是不会缓存到cache中的,我们设置cache需要作出以下的几个步骤,由于c66x DSP支持CSL库,所以我们只需调用相应的API即可,无需直接设置寄存器:
1.初始化L1P,用户可按需求设置为4K 、8K 、16K 、32K
(API:static inline void CACHE_setL1PSize (CACHE_L1Size newSize).
2.初始化L1D,用户可按需求设置为4K 、8K 、16K 、32K
(API:static inline void CACHE_setL1DSize (CACHE_L1Size newSize))
3.初始化L2,用户可按需求设置为32K 、64K 、128K 、256K、512K、1024K、
(API:static inline void CACHE_setL2Size (CACHE_L1Size newSize))
4.设置内存段的可缓存属性
(API:static inline void CACHE_enableCaching (Uint8 mar))
5.使缓存失效,并等待缓存失效操作完成
6.测试
我们在内存(DDR)中设置一个4KB大小的数组,我们对该数组进行读写来模拟4K的数据量交互,通过对比读写相同4K数据量的所耗时间来比较 cache对于性能的影响:
通过使用CCS 我们可以知道代码运行的所消耗的时钟周期,所以我们只需对比测试代码中两个for循环的耗时即可得出4K数据读写的总耗时。
注意:本测试进行与DSP c66x 裸机环境
6.1 测试一: 开启cache;

耗时:37402个时钟周期
6.2 测试二: 不开启 cache

耗时:1305155个时钟周期。
6.3 4K数据量的完整测试结果
总结:我们可以看出cache对于内存的读写会存在较大的影响,读写相同的数据量,使用缓存的耗时远远小于不使用缓存的,cache对性能的提升有较大作用。
参考资料:
《sprugy8 – TMS320C66x DSP Cache User Guide》
《高速缓存与一致性专栏 – 知乎》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号