

【原创】xenomai内核解析--xenomai与普通linux进程之间通讯XDDP(三)--实时与非实时数据交互
前面两篇文章我们看了xddp在xenomai内核里涉及的数据结构、RTDM对于协议类实时设备的管理方式,以及实时端创建一个XDDP通道后(xddp必须由实时端来创建),实时端与非实时端是如何联系起来的,本文从linux端打开创建好的xddp通道开始,来详细看整个通讯过程。
1.概述
【原创】实时IPC概述
【原创】xenomai与普通linux进程之间通讯XDDP(一)--实时端socket创建流程
【原创】xenomai与普通linux进程之间通讯XDDP(二)--实时与非实时关联(bind流程)
前面两篇文章我们看了xddp在xenomai内核里涉及的数据结构、RTDM对于协议类实时设备的管理方式,以及实时端创建一个XDDP通道后(xddp必须由实时端来创建),实时端与非实时端是如何联系起来的。
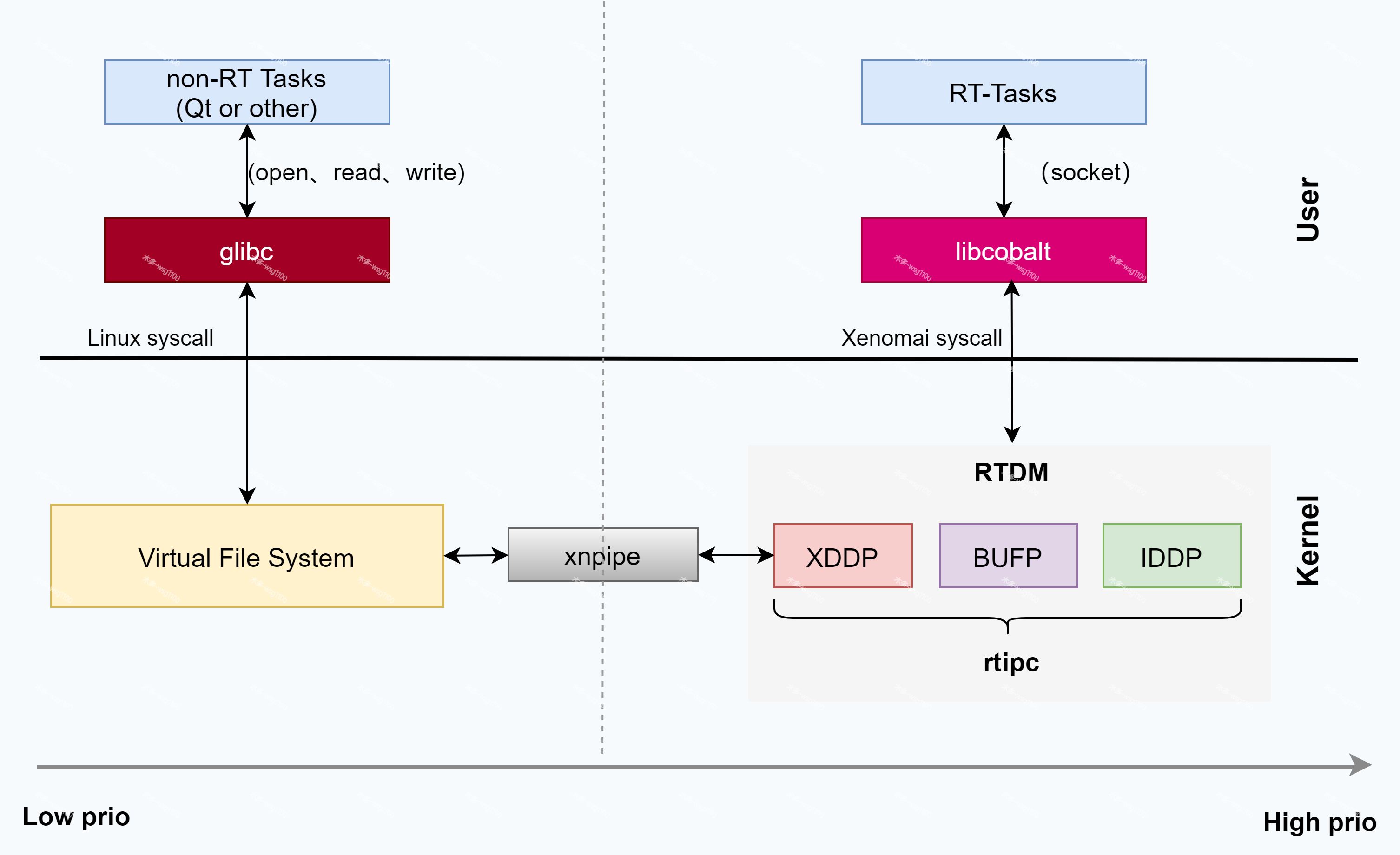
笔者在分析源码完后发现,XDDP过程就是这么个过程,下面的总结已经足够概括,所以先放总结,个人分析源码过程的粗糙记录可看后面部分。
以上工作做好后,下面可以进行数据交互了,本文从linux端打开创建好的xddp通道开始,来详细看整个通讯过程。
-
实时端创建xddp socket,通过bind指定socket使用的端口号,或者给socket设置一个label,端口号自动分配。实时与非实时通过socke使用的端口号来关联,在linux端,端口号即xnpip设备的次设备号。
-
通过指定端口通讯时,linux通过直接读写xnpipe设备(
/dev/rtpN,N为端口号)来通讯。使用label时,由于实时端端口号为自动分配,所以只能linux端只能通过读写文件/proc/xenomai/registry/rtipc/xddp/%s来通讯,%s为通讯使用的label。 -
非实时向实时端发送数据:通讯过程中,由于xnpipe可看做一个全双工设备,有两个数据链表,命名以实时端为主,
inq表示接收数据报链表(NRT->RT),outq为发送数据报链表(RT->NRT)。对于linux端,每次发送的数据都作为一个数据报节点插入到链表inq尾,实时端读取时从链表头取数据,符合FIFO。 -
实时向非实时发送数据,分三种数据:
- 不带标识的数据包会作为一个单独的数据报节点插入链表
outq尾。 - 使用MSG_OOB标识时,表示这是一个紧急的数据,需要优先被linux端读取,这时会作为一个单独的数据报节点插入链表
outq头。liunx端读取时从链表头取数据,所以除MSG_OOB标识的数据外,符合FIFO。 - 使用MSG_MORE标识时,表示还有数据要与该数据一起发送,暂时不作为单独数据包发送(不放到
outq),先积累到数据缓冲区,待缓冲区满或者发送的数据没有MSG_MORE时,将整个缓冲区作为一个大的数据包插入链表outq尾。
整个XDDP使用过程中:
- 建立xddp通道时,所有数据结构需要的内存均已申请。数据收发过程中,数据交互使用的内存从xnheap申请释放,同步、互斥、唤醒使用的是xenomai内核机制,所以整个通讯由xenomai内核管理,保证了xenomai的实时性;
- 对于linux向xenomai发送的数据,xenomai任务在xenomai的调度下能很快读取,看任务具体优先级等。
- 对于xenomai发送给linux的数据,如果非实时任务阻塞读,会使用ipip虚拟中断机制APC来通知linux唤醒该任务,待linux得到cpu时,自会处理虚拟中断APC,唤醒接收的非实时任务处理数据,整体框图如下。
- 不带标识的数据包会作为一个单独的数据报节点插入链表
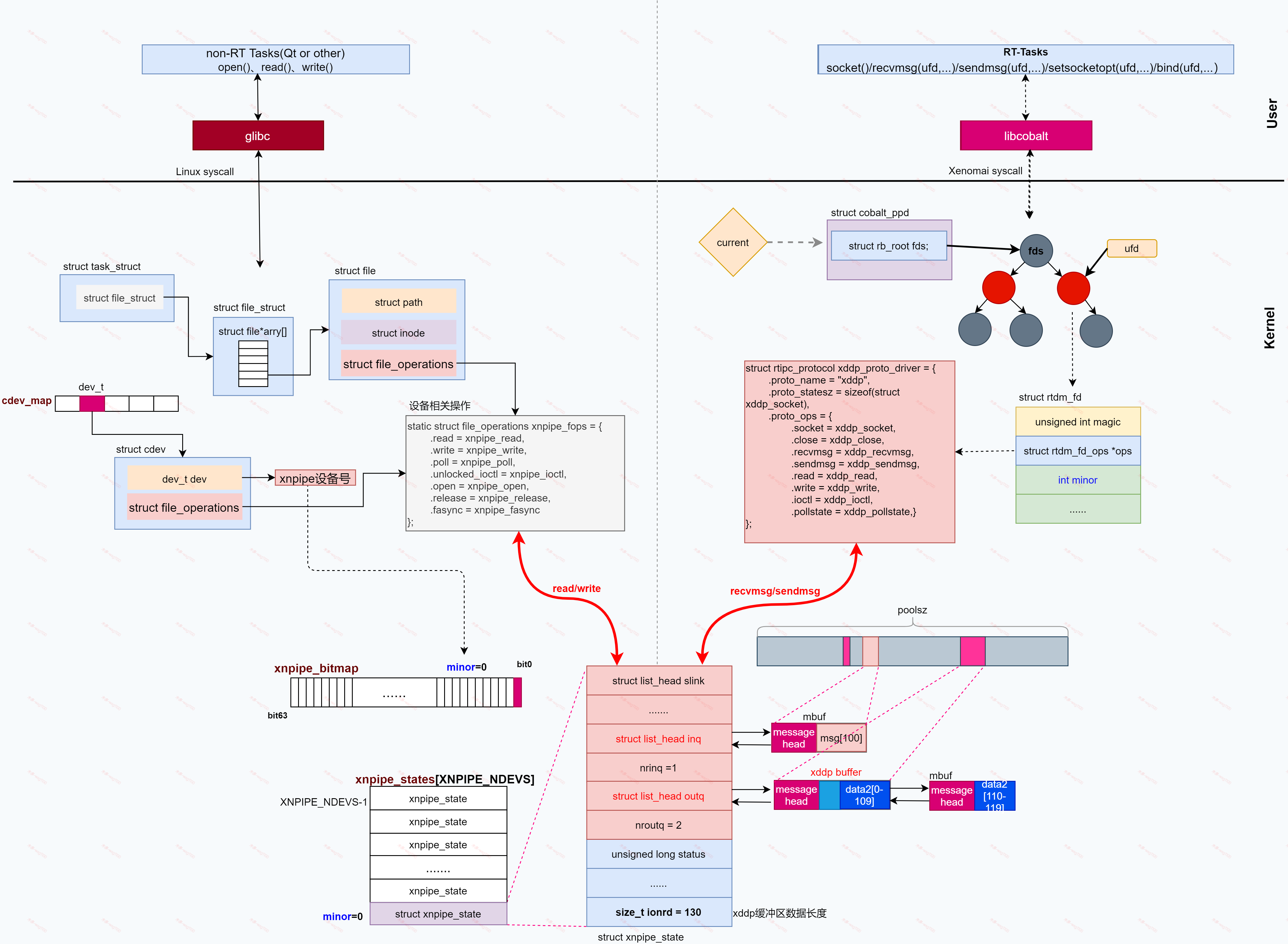
粗糙记录见下文,按需查看。
2.linux端设备节点创建
前面说到,通过指定端口通讯时,linux通过直接读写xnpipe设备(/dev/rtpN,N为端口号)来通讯。使用label时,由于实时端端口号为自动分配,所以只能linux端只能通过读写文件/proc/xenomai/registry/rtipc/xddp/%s来通讯,%s为通讯使用的label。
xnpipe设备(/dev/rtpN,N为端口号),创建流程如下:
前面说到注册XDDP字符设备的时候,会调用 register_chrdev_region, 然后,cdev_add 会将这个字符设备添加到内核中一个叫作 struct kobj_map *cdev_map 的结构,来统一管理所有字符设备。用户空间的udev守护进程会完成设备文件的创建。udev守护进程会完成设备文件的创建通过mknod系统调用来完成,mknod系统调用定义如下:
/*fs\namei.c*/
SYSCALL_DEFINE3(mknod, const char __user *, filename, umode_t, mode, unsigned, dev)
{
return sys_mknodat(AT_FDCWD, filename, mode, dev);
}
SYSCALL_DEFINE4(mknodat, int, dfd, const char __user *, filename, umode_t, mode,
unsigned, dev)
{
struct dentry *dentry;
struct path path;
......
dentry = user_path_create(dfd, filename, &path, lookup_flags);
......
switch (mode & S_IFMT) {
......
case S_IFCHR: case S_IFBLK:
error = vfs_mknod(path.dentry->d_inode,dentry,mode,
new_decode_dev(dev));
break;
......
}
}
可以在这个系统调用里看到,在文件系统上,顺着路径找到 /dev/xxx 所在的文件夹,然后为这个新创建的设备文件创建一个 dentry。这是维护文件和 inode 之间的关联关系的结构。接下来,如果是字符文件 S_IFCHR 或者设备文件 S_IFBLK,我们就调用 vfs_mknod。
int vfs_mknod(struct inode *dir, struct dentry *dentry, umode_t mode, dev_t dev)
{
......
error = dir->i_op->mknod(dir, dentry, mode, dev);
......
}
这里需要调用对应的文件系统的 inode_operations。应该调用哪个文件系统呢?如果我们在 linux 下面执行 mount 命令,能看到下面这一行:
devtmpfs on /dev type devtmpfs (rw,nosuid,size=3989584k,nr_inodes=997396,mode=755)
也就是说,/dev 下面的文件系统的名称为 devtmpfs,可以在内核中找到它。
static struct dentry *dev_mount(struct file_system_type *fs_type, int flags,
const char *dev_name, void *data)
{
#ifdef CONFIG_TMPFS
return mount_single(fs_type, flags, data, shmem_fill_super);
#else
return mount_single(fs_type, flags, data, ramfs_fill_super);
#endif
}
static struct file_system_type dev_fs_type = {
.name = "devtmpfs",
.mount = dev_mount,
.kill_sb = kill_litter_super,
};
从这里可以看出,devtmpfs 在挂载的时候,有两种模式,一种是 ramfs,一种是 shmem 都是基于内存的文件系统。
static const struct inode_operations ramfs_dir_inode_operations = {
......
.mknod = ramfs_mknod,
};
static const struct inode_operations shmem_dir_inode_operations = {
#ifdef CONFIG_TMPFS
......
.mknod = shmem_mknod,
};
这两个 mknod 虽然实现不同,但是都会调用到同一个函数 init_special_inode。
void init_special_inode(struct inode *inode, umode_t mode, dev_t rdev)
{
inode->i_mode = mode;
if (S_ISCHR(mode)) {
inode->i_fop = &def_chr_fops;
inode->i_rdev = rdev;
} else if (S_ISBLK(mode)) {
inode->i_fop = &def_blk_fops;
inode->i_rdev = rdev;
} else if (S_ISFIFO(mode))
inode->i_fop = &pipefifo_fops;
else if (S_ISSOCK(mode))
; /* leave it no_open_fops */
}
显然这个文件是个特殊文件,inode 也是特殊的。这里这个 inode 可以关联字符设备、块设备、FIFO 文件、Socket 等。这里只看字符设备。
这里的 inode 的 file_operations 指向一个 def_chr_fops,这里面只有一个 open,就等着你打开它。另外,inode 的 i_rdev 指向这个设备的 dev_t。
通过这个 dev_t,可以找到我们刚在加载的字符设备 cdev。
const struct file_operations def_chr_fops = {
.open = chrdev_open,
};
到目前为止,只是创建了 /dev 下面的一个文件,并且和相应的设备号关联起来。但是,我们还没有打开这个 /dev 下面的设备文件。
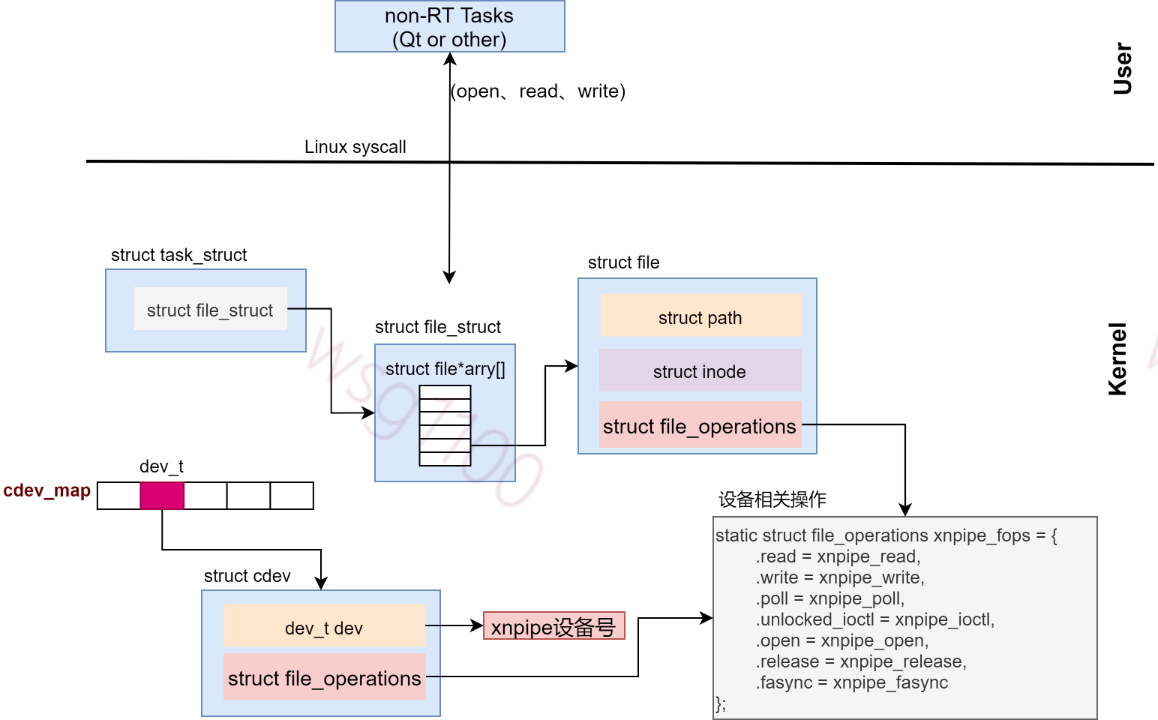
3.linux端打开设备
现在我们来打开它。打开文件的进程的 task_struct 里,有一个数组代表它打开的文件,下标就是文件描述符 fd,每一个打开的文件都有一个 struct file 结构,会指向一个 dentry 项。dentry 可以用来关联 inode。
这个 dentry 就是上面 mknod 的时候创建的。在进程里面调用 open 函数,最终会调用到这个特殊的 inode 的 open 函数,也就是 chrdev_open。
static int chrdev_open(struct inode *inode, struct file *filp)
{
const struct file_operations *fops;
struct cdev *p;
struct cdev *new = NULL;
int ret = 0;
p = inode->i_cdev;
if (!p) {
struct kobject *kobj;
int idx;
kobj = kobj_lookup(cdev_map, inode->i_rdev, &idx);
new = container_of(kobj, struct cdev, kobj);
p = inode->i_cdev;
if (!p) {
inode->i_cdev = p = new;
list_add(&inode->i_devices, &p->list);
new = NULL;
}
}
......
fops = fops_get(p->ops);
......
replace_fops(filp, fops);
if (filp->f_op->open) {
ret = filp->f_op->open(inode, filp);
......
}
......
}
在这个函数里面,首先看这个 inode 的 i_cdev,是否已经关联到 cdev。如果第一次打开,没有没关联,inode 里面有 i_rdev ,也就是有 dev_t。可以通过它在 cdev_map 中找 cdev。因为我们上面注册过了,所以能够找到。找到后就将 inode 的 i_cdev,关联到找到的 cdev new。
找到 cdev 后。cdev 里面有 file_operations,这是设备驱动程序自己定义的。可以通过它来操作设备驱动程序,把它付给 struct file 里面的 file_operations。这样以后操作文件描述符,就是直接操作设备了。
最后,我们需要调用设备驱动程序的 file_operations 的 open 函数,真正打开设备。
对于XDDP,最终会调用到 xnpipe_open。
4. 实时端发送
RT应用使用来向send/sendto/sendmsg NRT发送消息。
char *msg="hello world!";
int len=strlen(msg);
for (b = 0; b < len; b++) {
/*MSG_MORE表示:一字节一字节的将数据存到缓冲区*/
ret = sendto(s, msg + b, 1, MSG_MORE, NULL, 0);
.....
}
/*如果不使用MSG_MORE,每个字母将作为一个数据包。Linux端段每次读取只能读取到一个字母,且符合FIFO*/
ret = sendto(s, msg, len, 0, NULL, 0);
....
/*使用MSG_OOB 发送高优先级数据*/
ret = sendmsg(s, msg[n] + b, 1, MSG_OOB, NULL, 0);
....
示例中,MSG_MORE表示:将每次发送数据累积存到缓冲区作为一整个包,否则每次发送作为一个单独的数据包且,符合FIFO;MSG_OOB表示该数据包优先级高,优先被nrt任务读取(插队);
同样,这几个函数在libcobalt中实现:
/*库函数:xenomai-3.x.x\lib\cobalt\rtdm.c*/
COBALT_IMPL(ssize_t, sendto, (int fd, const void *buf, size_t len, int flags,
const struct sockaddr *to, socklen_t tolen))
{
struct iovec iov = {
.iov_base = (void *)buf,
.iov_len = len,
};
struct msghdr msg = {
.msg_name = (struct sockaddr *)to,
.msg_namelen = tolen,
.msg_iov = &iov,
.msg_iovlen = 1, /*msg_iov个数*/
.msg_control = NULL,
.msg_controllen = 0,
};
int ret;
ret = do_sendmsg(fd, &msg, flags);
if (ret != -EBADF && ret != -ENOSYS)
return set_errno(ret);
return __STD(sendto(fd, buf, len, flags, to, tolen));
}
COBALT_IMPL(ssize_t, sendmsg, (int fd, const struct msghdr *msg, int flags))
{
int ret;
ret = do_sendmsg(fd, msg, flags);
if (ret != -EBADF && ret != -ENOSYS)
return set_errno(ret);
return __STD(sendmsg(fd, msg, flags));
}
COBALT_IMPL(ssize_t, send, (int fd, const void *buf, size_t len, int flags))
{
struct iovec iov = {
.iov_base = (void *)buf,
.iov_len = len,
};
struct msghdr msg = {
.msg_name = NULL,
.msg_namelen = 0,
.msg_iov = &iov,
.msg_iovlen = 1,
.msg_control = NULL,
.msg_controllen = 0,
};
int ret;
ret = do_sendmsg(fd, &msg, flags);
if (ret != -EBADF && ret != -ENOSYS)
return set_errno(ret);
return __STD(send(fd, buf, len, flags));
}
它们都是socket发送数据的接口,区别在于sendmsg()使用struct msghdr,msg->msg_iovlen内保存着数据包数量,能一次性发送多条数据。sendto()与send()需要构造包含一个数据包的struct msghdr ,然后再调用do_sendmsg()发起实时系统调用发送。
static ssize_t do_sendmsg(int fd, const struct msghdr *msg, int flags)
{
int ret, oldtype;
pthread_setcanceltype(PTHREAD_CANCEL_ASYNCHRONOUS, &oldtype);
ret = XENOMAI_SYSCALL3(sc_cobalt_sendmsg, fd, msg, flags);
pthread_setcanceltype(oldtype, NULL);
return ret;
}
实时系统调用sc_cobalt_sendmsxg先将将用户空间数据拷贝到内核空间,然后调用rtdm_fd_sendmsg()如下:
COBALT_SYSCALL(sendmsg, handover,
(int fd, struct user_msghdr __user *umsg, int flags))
{
struct user_msghdr m;
int ret;
ret = cobalt_copy_from_user(&m, umsg, sizeof(m)); /*拷贝到内核空间*/
return ret ?: rtdm_fd_sendmsg(fd, &m, flags);
}
ssize_t rtdm_fd_sendmsg(int ufd, const struct user_msghdr *msg, int flags)
{
struct rtdm_fd *fd;
ssize_t ret;
fd = get_fd_fixup_mode(ufd);
......
if (fd->oflags & O_NONBLOCK)
flags |= MSG_DONTWAIT;
if (ipipe_root_p)
ret = fd->ops->sendmsg_nrt(fd, msg, flags);
else
ret = fd->ops->sendmsg_rt(fd, msg, flags);//xddp_sendmsg
......
return ret;
}
与前面解析一样,根据ufd取出rtdm_fd,然后调用xddp数据发送函数xddp_sendmsg()。
static ssize_t xddp_sendmsg(struct rtdm_fd *fd,
const struct user_msghdr *msg, int flags)
{
struct rtipc_private *priv = rtdm_fd_to_private(fd);
struct iovec iov_fast[RTDM_IOV_FASTMAX], *iov;
struct xddp_socket *sk = priv->state;
struct sockaddr_ipc daddr;//目标地址
ssize_t ret;
/*不能同时使用MSG_MORE、MSG_OOB标志*/
if ((flags & (MSG_MORE | MSG_OOB)) == (MSG_MORE | MSG_OOB))
return -EINVAL;
if (msg->msg_name) {
if (msg->msg_namelen != sizeof(struct sockaddr_ipc))
return -EINVAL;
/* Fetch the destination address to send to. */
if (rtipc_get_arg(fd, &daddr, msg->msg_name, sizeof(daddr)))
return -EFAULT;
if (daddr.sipc_port < 0 ||
daddr.sipc_port >= CONFIG_XENO_OPT_PIPE_NRDEV)
return -EINVAL;
} else {
......
daddr = sk->peer;
.....
}
if (msg->msg_iovlen >= UIO_MAXIOV)
return -EINVAL;
/* Copy I/O vector in */
ret = rtdm_get_iovec(fd, &iov, msg, iov_fast);
......
ret = __xddp_sendmsg(fd, iov, msg->msg_iovlen, flags, &daddr);/*发送iovlen个iov*/
......
/* Copy updated I/O vector back */
return rtdm_put_iovec(fd, iov, msg, iov_fast) ?: ret;
}
先检查参数,不能同时使用MSG_MORE、MSG_OOB标志,看struct user_msghdr有没有包含目标地址,如果没有则使用sk->peer,检查本次发送的数据包个数,如果大于1024则返回错误。
接着调rtdm_get_iovec()处理数据包,将每条数包信息保存到struct iovec iov_fast[16],如果数据条数大于16条,则不使用iov_fast[16],会向xenomai系统内存池Cobalt_heap分配更大的内存来保存这些信息。保存每条数据信息的struct iovec 如下。
struct iovec
{
void __user *iov_base; /* BSD uses caddr_t (1003.1g requires void *) */
__kernel_size_t iov_len; /* Must be size_t (1003.1g) */
};
其中iov_base保存着数据在用户空间的地址,iov_len为数据的长度。
得到本次发送每条数据的信息后,调用__xddp_sendmsg()进行发送,参数分别是执行发送的rtdm_fd,存储每条数据信息的iov指针,iovlen表示本次发送数据条数,flags发送flags,daddr目标地址信息。
static ssize_t __xddp_sendmsg(struct rtdm_fd *fd,
struct iovec *iov, int iovlen, int flags,
const struct sockaddr_ipc *daddr)
{
struct rtipc_private *priv = rtdm_fd_to_private(fd);
ssize_t len, rdlen, wrlen, vlen, ret, sublen;
struct xddp_socket *sk = priv->state;
struct xddp_message *mbuf;
struct xddp_socket *rsk;
struct rtdm_fd *rfd;
int nvec, to, from;
struct xnbufd bufd;
rtdm_lockctx_t s;
....
len = rtdm_get_iov_flatlen(iov, iovlen);
.....
from = sk->name.sipc_port;
to = daddr->sipc_port;
.....
rfd = portmap[to];
.....
rsk = rtipc_fd_to_state(rfd);
.....
if (flags & MSG_MORE) {
/*数据累积到缓冲区rsk->buffer*/
goto done;
}
mbuf = xnheap_alloc(rsk->bufpool, sublen + sizeof(*mbuf));
.....
/*
* Move "sublen" bytes to mbuf->data from the vector cells
*/
for (rdlen = sublen, wrlen = 0; nvec < iovlen && rdlen > 0; nvec++) {
/*处理每条数据,构造xnpipe数据包xddp_message*/
}
/*发送*/
ret = xnpipe_send(rsk->minor, &mbuf->mh,
sublen + sizeof(*mbuf),
(flags & MSG_OOB) ?
XNPIPE_URGENT : XNPIPE_NORMAL);
done:
rtdm_fd_unlock(rfd);
return len;
}
__xddp_sendmsg()先调用rtdm_get_iov_flatlen()计算本次要发送的数据总长度len,取出源端口from,目标端口to,根据目标端口to从端口rtdm_fd映射表中取出接收端的rtdm_fd结构指针保存到rfd,再根据rfd得到对应的xddp对象xddp_socket,记得前面我们解析过,缓冲区是由xddp_socket管理着的,所以这里先判断本次发送有没有标志MSG_MORE,有的话那数据不能直接使用xnpipe发送出去,需要先在缓冲区中缓存。如果没有标志MSG_MORE,则构造xnpipe数据包,然后再调用xnpipe_send()执行发送操作。
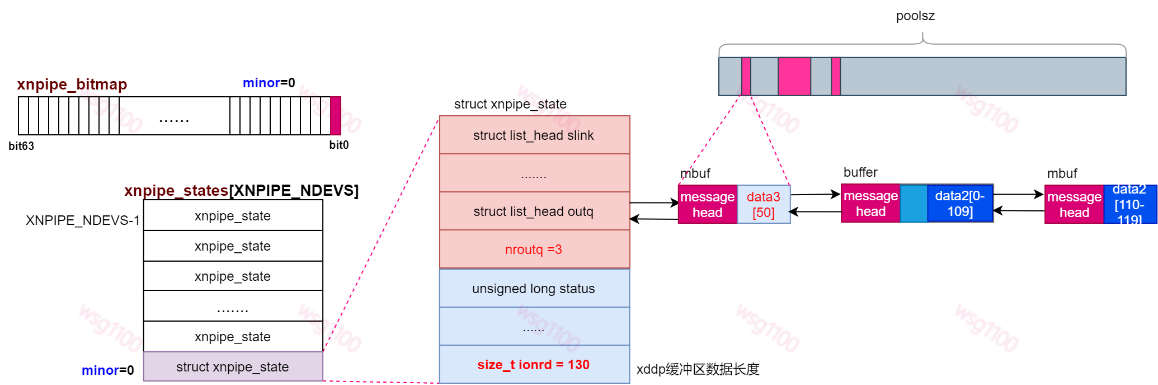
该流程使用一个示例来解释,假如xenomai任务通过sendmsg()发送data1、data2两条数据,且设置了falsg MSG_MORE,xddp缓冲区大小设置为130Byte,此时缓冲区内没有任何数据。解析到此如下所示:
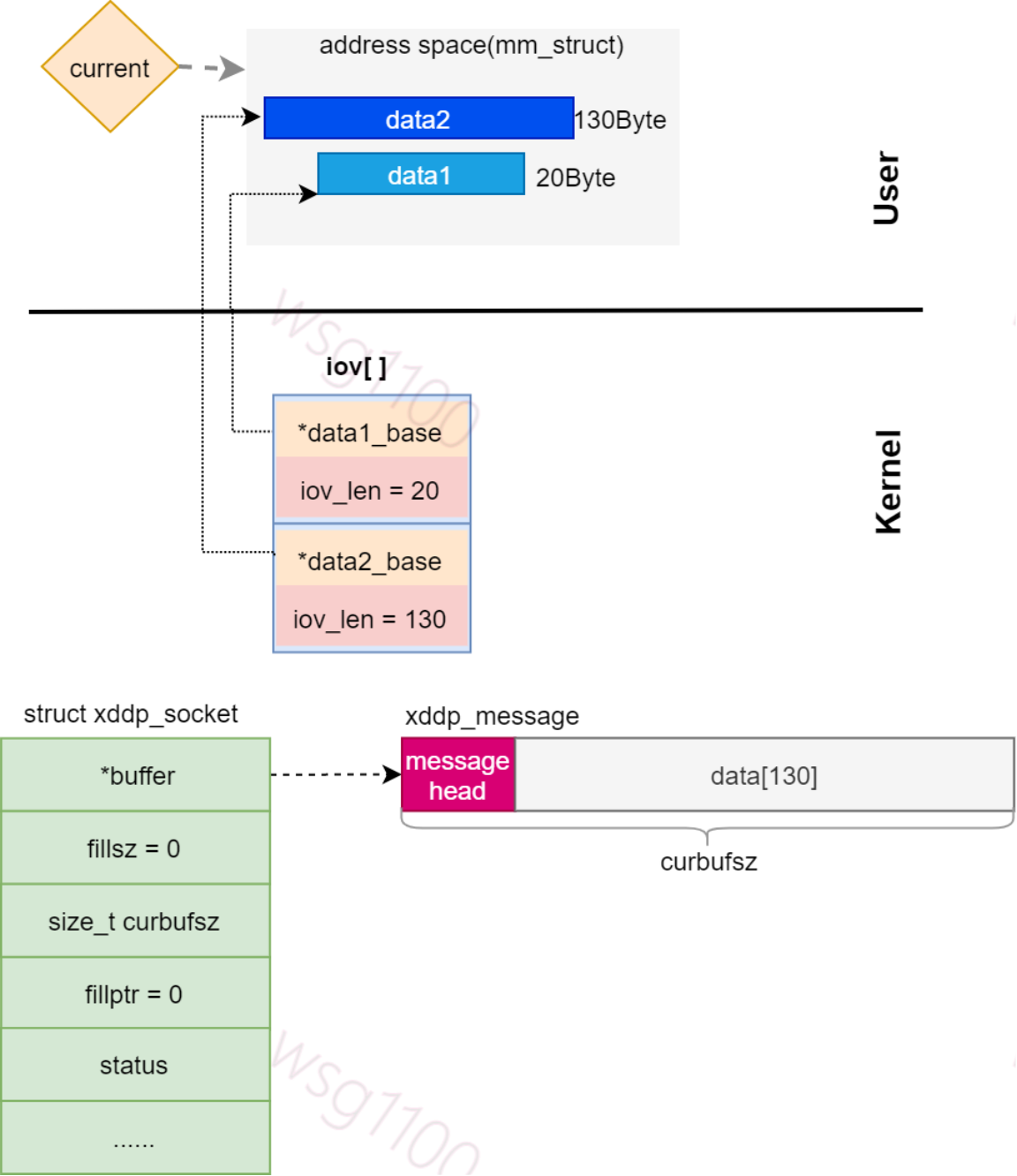
将数据积累到数据缓冲区处理代码如下。
static ssize_t __xddp_sendmsg(struct rtdm_fd *fd,
struct iovec *iov, int iovlen, int flags,
const struct sockaddr_ipc *daddr)
{
.......
sublen = len;
nvec = 0;
if (flags & MSG_MORE) {
for (rdlen = sublen, wrlen = 0;
nvec < iovlen && rdlen > 0; nvec++) {
if (iov[nvec].iov_len == 0)
continue;
vlen = rdlen >= iov[nvec].iov_len ? iov[nvec].iov_len : rdlen;
if (rtdm_fd_is_user(fd)) {/*用户空间程序使用的rtdm_fd*/
xnbufd_map_uread(&bufd, iov[nvec].iov_base, vlen);
ret = __xddp_stream(rsk, from, &bufd);
xnbufd_unmap_uread(&bufd);
} else {
xnbufd_map_kread(&bufd, iov[nvec].iov_base, vlen);
ret = __xddp_stream(rsk, from, &bufd);
xnbufd_unmap_kread(&bufd);
}
if (ret < 0)
goto fail_unlock;
wrlen += ret;
rdlen -= ret;
iov[nvec].iov_base += ret;
iov[nvec].iov_len -= ret;
/*
* In case of a short write to the streaming
* buffer, send the unsent part as a
* standalone datagram.
*/
if (ret < vlen) {/*缓冲区已满将剩余数据作为单独包发送*/
sublen = rdlen;
goto nostream;
}
}
len = wrlen;
goto done;
}
nostream:
..... /*单独包发送*/
done:
rtdm_fd_unlock(rfd);
return len;
}
对数组iov[]里的每个长度非0数据,先调用xnbufd_map_kread()构造一个缓冲区描述符struct xnbufd,然后通过函数__xddp_stream()从用户空间拷贝到缓冲区,并调整iov[nvec]里的信息,iov[nvec].iov_len减去已发送的数据信息。
struct xnbufd {
caddr_t b_ptr; /* 源/目标地址*/
size_t b_len; /* buffer总长度 */
off_t b_off; /* 读或写字节数*/
struct mm_struct *b_mm; /* 源或目标地址空间 */
caddr_t b_carry; /* pointer to carry over area*/
char b_buf[64]; /* fast carry over area */
};

对data1构造xnbufd后,调用__xddp_stream()将数据拷贝到缓冲区。
static ssize_t __xddp_stream(struct xddp_socket *sk,
int from, struct xnbufd *bufd)
{
struct xddp_message *mbuf;
size_t fillptr, rembytes;
rtdm_lockctx_t s;
ssize_t outbytes;
int ret;
if (sk->curbufsz == 0 ||
(sk->buffer_port >= 0 && sk->buffer_port != from)) {
/*This will end up into a standalone datagram. */
outbytes = 0;
goto out;
}
mbuf = sk->buffer;
rembytes = sk->curbufsz - sizeof(*mbuf) - sk->fillsz;
outbytes = bufd->b_len > rembytes ? rembytes : bufd->b_len;
if (likely(outbytes > 0)) {
repeat:
/* Mark the beginning of a should-be-atomic section. */
__set_bit(_XDDP_ATOMIC, &sk->status);
fillptr = sk->fillsz;
sk->fillsz += outbytes;
rtdm_lock_put_irqrestore(&sk->lock, s);
ret = xnbufd_copy_to_kmem(mbuf->data + fillptr,
bufd, outbytes);
rtdm_lock_get_irqsave(&sk->lock, s);
......
/* We haven't been atomic, let's try again. */
if (!__test_and_clear_bit(_XDDP_ATOMIC, &sk->status))
goto repeat;
if (__test_and_set_bit(_XDDP_SYNCWAIT, &sk->status))
outbytes = xnpipe_mfixup(sk->minor,
&mbuf->mh, outbytes);
else {
sk->buffer_port = from;
outbytes = xnpipe_send(sk->minor, &mbuf->mh,
outbytes + sizeof(*mbuf),
XNPIPE_NORMAL);
if (outbytes > 0)
outbytes -= sizeof(*mbuf);
}
}
out:
rtdm_lock_put_irqrestore(&sk->lock, s);
return outbytes;
}
先判断缓冲区大小,如果curbufsz等于0说明没有使用setsocketopt()为xddp设置缓冲区大小,则flag MSG_MORE无效,数据将作为一个单独的包发送出去,直接跳转至out。
然后计算缓冲区剩余大小rembytes,看剩余空间rembytes是否能存下本次数据,如果不能,缓冲区剩余空间多少就先拷贝多少,拷贝大小outbytes就是rembytes;反之,outbytes就是本次数据长度 bufd->b_len。
将用户空间数据拷贝到缓冲区之前,先计算缓冲区拷贝起始偏移量fillptr,拷贝后偏移量sk->fillsz(拷贝后缓冲区内数据的长度)。接着调用xnbufd_copy_to_kmem()进行数据拷贝。xnbufd_copy_to_kmem()根据bufd->b_mm判断数据位于内核空间(mm==NULL)还是用户空间,内核空间则直接拷贝,如果数据在用户空间则使用cobalt_copy_from_user()拷贝。
完成数据拷贝至缓冲区后,sk->status置位bit _XDDP_SYNCWAIT并返回原来的值,如果原值为0,则发生了以下情况之一,需要将缓冲区数据全部发送出去,调用xnpipe_send()完成发送。
- Linux域中接收器被唤醒接收数据,
- 不同的源端口尝试将数据发送到相同的目标端口,
- 发送标志中没有MSG_MORE,
- 缓冲区已满。
这里是第一次将数据保存到缓冲区,执行分支1:
if (__test_and_set_bit(_XDDP_SYNCWAIT, &sk->status))
outbytes = xnpipe_mfixup(sk->minor,
&mbuf->mh, outbytes);/**/
else {
......
}
xnpipe_mfixup()取出xnpipe对象,更新缓冲区数据长度ionrd。
ssize_t xnpipe_mfixup(int minor, struct xnpipe_mh *mh, ssize_t size)
{
struct xnpipe_state *state;
spl_t s;
.......
state = &xnpipe_states[minor];
.......
xnpipe_m_size(mh) += size;
state->ionrd += size;
xnlock_put_irqrestore(&nklock, s);
return (ssize_t) size;
}
返回__xddp_sendmsg()接着处理我们的iov[1],此时data1已保存到缓冲区,iov[0].b_len 为0 下次循环就会跳过,各结构数据如下所示:
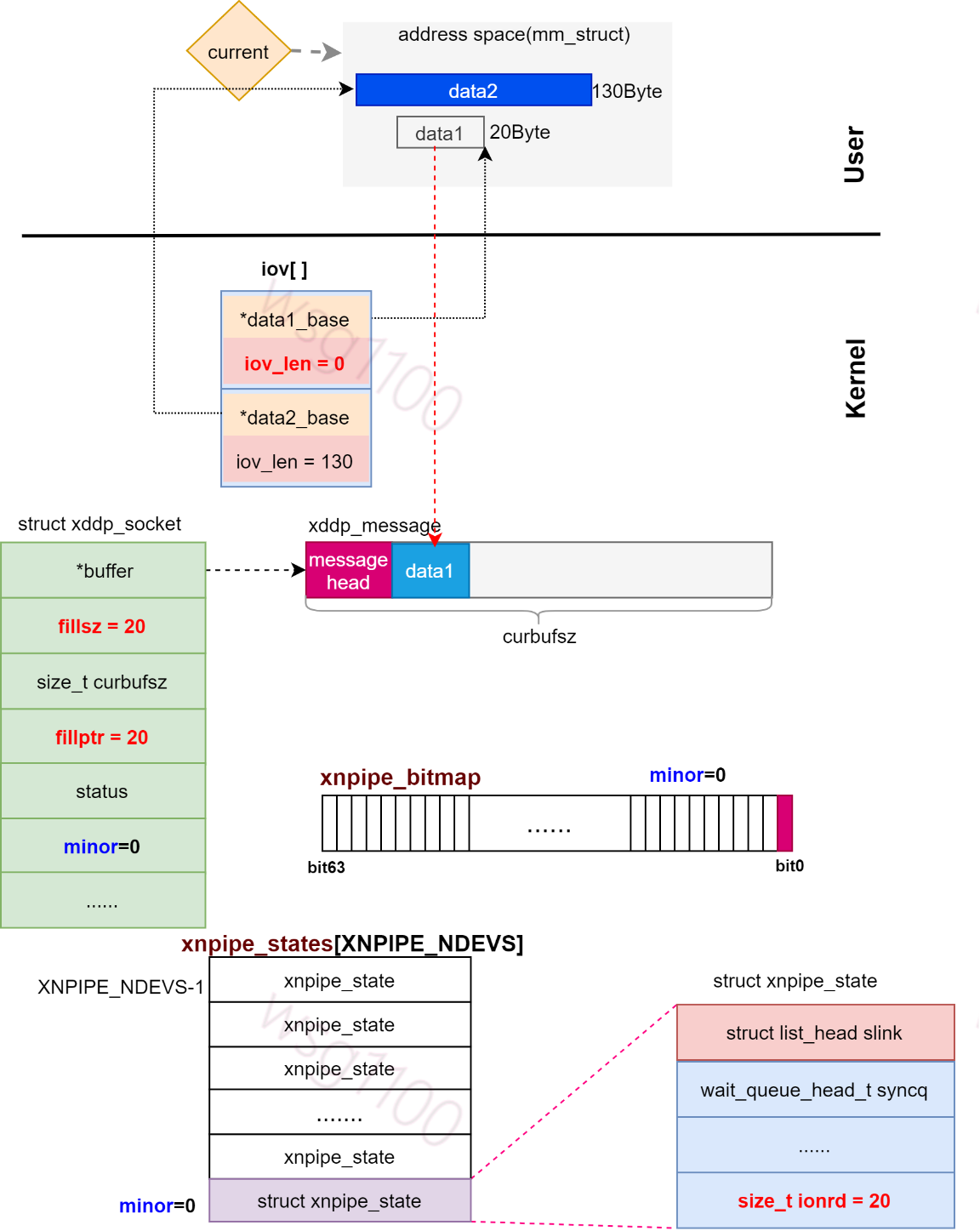
由于下面将data2保存到缓冲区,我们分配的缓冲区长度只有130Byte,目前data1占用了20Byte,缓冲区剩余空间110Byte,不能完全存下data2的数据。先将data2前110Byte数据存到缓冲区,剩余的20Byte数据作为单独包发送出去。
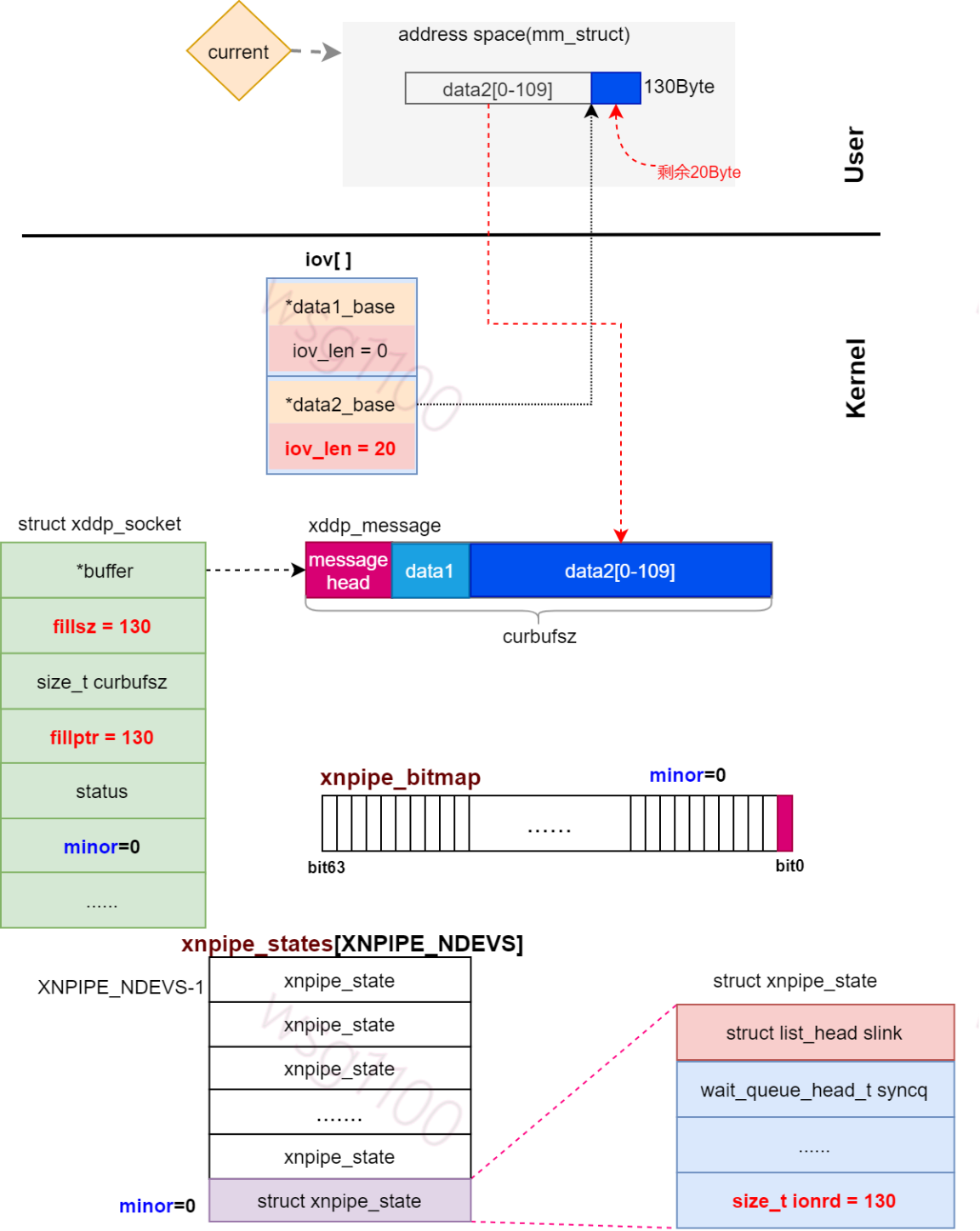
看数据作为单独包发送的流程:
static ssize_t __xddp_sendmsg(struct rtdm_fd *fd,
struct iovec *iov, int iovlen, int flags,
const struct sockaddr_ipc *daddr)
{
.......
sublen = len;
nvec = 0;
if (flags & MSG_MORE) { /*将数据累积到缓冲区*/
.......
if (ret < vlen) {/*缓冲区已满将剩余数据作为单独包发送*/
sublen = rdlen;
goto nostream;
}
}
len = wrlen;
goto done;
}
nostream:
/*单独包发送*/
mbuf = xnheap_alloc(rsk->bufpool, sublen + sizeof(*mbuf));/*从bufpool 分配*/
......
/*
* Move "sublen" bytes to mbuf->data from the vector cells
*/
for (rdlen = sublen, wrlen = 0; nvec < iovlen && rdlen > 0; nvec++) {
if (iov[nvec].iov_len == 0)
continue;
vlen = rdlen >= iov[nvec].iov_len ? iov[nvec].iov_len : rdlen;
if (rtdm_fd_is_user(fd)) {/*需要从用户空间拷贝*/
.....
ret = xnbufd_copy_to_kmem(mbuf->data + wrlen, &bufd, vlen);
.....
} else {
......
ret = xnbufd_copy_to_kmem(mbuf->data + wrlen, &bufd, vlen);
......
}
......
iov[nvec].iov_base += vlen;
iov[nvec].iov_len -= vlen;
rdlen -= vlen;
wrlen += vlen;
}
/*xnpipe发送*/
ret = xnpipe_send(rsk->minor, &mbuf->mh,
sublen + sizeof(*mbuf),
(flags & MSG_OOB) ?
XNPIPE_URGENT : XNPIPE_NORMAL);
done:
rtdm_fd_unlock(rfd);
return len;
}
先从xddp_socket.bufpool指向的内存池中分配数据包大小的内存mbuf(本次待发送数据大小sublen+消息头大小 sizeof(*mbuf)),mbuf与缓冲区ddp_socket.buffer不同,缓冲区是配置socket时分配的,数据区大小固定,只有一个,会伴随socket的整个生命周期。而这个mbuf是动态分配的,有多少个数据包发送就会分配多少个mbuf,直到数据被linux端读取后该内存就会被释放。
分配一个xddp_message空间后,与前面一样,将要发送的数据一个一个的拷贝到数据区,这里将data2剩余的20Byte数据拷贝到mbuf。
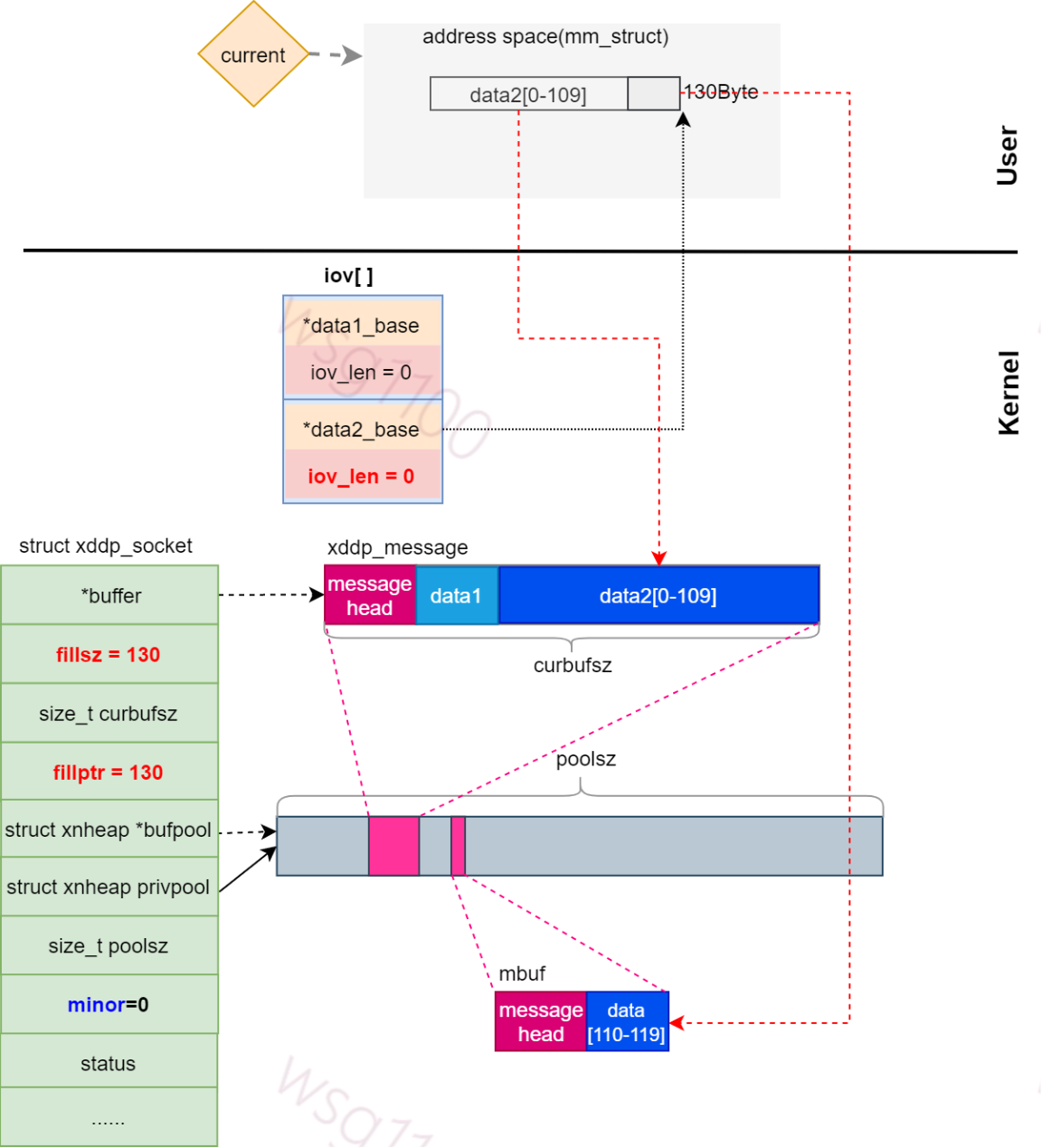
然后调用xnpipe_send()进行数据发送。
ssize_t xnpipe_send(int minor, struct xnpipe_mh *mh, size_t size, int flags)
{
struct xnpipe_state *state;
int need_sched = 0;
spl_t s;
......
state = &xnpipe_states[minor];
xnlock_get_irqsave(&nklock, s);
......
xnpipe_m_size(mh) = size - sizeof(*mh);/*该包数据区长度*/
xnpipe_m_rdoff(mh) = 0; /*该包已读数据偏移*/
state->ionrd += xnpipe_m_size(mh);/*更新链表数据总长度*/
if (flags & XNPIPE_URGENT)/*高优先级数据,添加到队列头*/
list_add(&mh->link, &state->outq);/*头插*/
else
list_add_tail(&mh->link, &state->outq);/*低优先级数据添加到链表尾*/
state->nroutq++;/*更新数据包数*/
if ((state->status & XNPIPE_USER_CONN) == 0) {/**/
xnlock_put_irqrestore(&nklock, s);
return (ssize_t) size;
}
if (state->status & XNPIPE_USER_WREAD) {/*如果LInux此时等待读*/
/*
* Wake up the regular Linux task waiting for input
* from the Xenomai side.
* 唤醒常规的Linux任务,以等待Xenomai方面的输入。
*/
state->status |= XNPIPE_USER_WREAD_READY;/*置位能读标志*/
need_sched = 1;
}
if (state->asyncq) { /* Schedule asynch sig.调度异步信号。 */
state->status |= XNPIPE_USER_SIGIO;
need_sched = 1;
}
if (need_sched)
xnpipe_schedule_request(); //xnpipe_wakeup_apc
xnlock_put_irqrestore(&nklock, s);
return (ssize_t) size;
}
根据minor,从xnpipe_states中该xddp使用的xnpipe对象xnpipe_state,初始化消息头mh的数据区长度size、已读偏移rdoff,当linux端应用来读取数据时,该数据包内的数据没有被完全读取时,会更新该成员变量。更新待发送数据总长度ionrd。
如果该数据具有XNPIPE_URGENT标识,也就是用户发送函数sendmsg使用了MSG_OOB,标识该数据包优先级高,需要优先被发送,mbuf就会插入链表头,linux端读取时就能优先读取该数据。否则,mbuf插入链表尾。链表节点数state->nroutq +1。
如果此时linux没有连接(没有打开设备节点/dev/rtpX),就直接返回。否则根据state->status状态判断linux端是否等待读数据,执行异步调用xnpipe_wakeup_apc,唤醒linux任务(apc工作原理查看ipipr虚拟中断小节)。
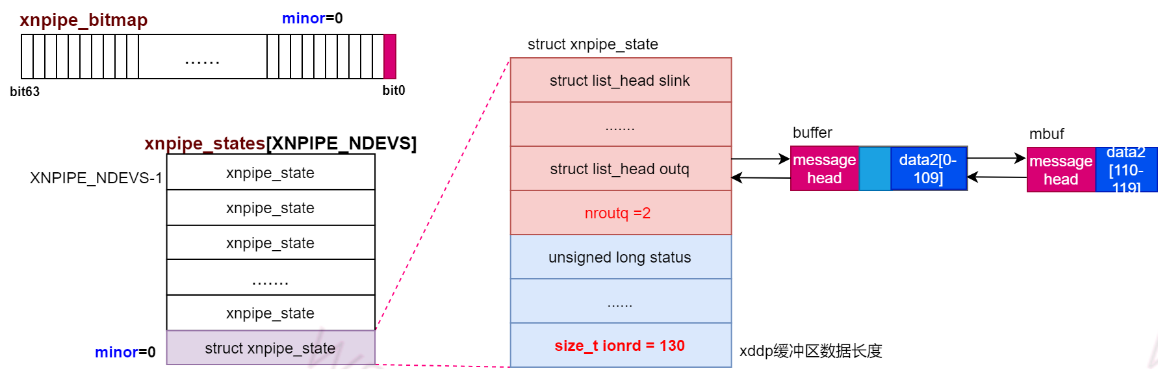
如果xenomai端再使用MSG_OOB标识发送了一个高优先级数据data3,长度50Byte,由于是高优先数据,插入发送链表头如下:
如果还没有linux读操作,xenomai端再使用MSG_OOB标识发送了一个高优先级数据data4,长度50Byte,由于是高优先数据,插入发送链表头,data4就会变成最先被linux任务读取的数据包。
5.linux端读
对于读字符设备,就是用文件系统的标准接口 read,参数文件描述符 fd,在内核里面调用的 sys_read,在 sys_read 里面根据文件描述符 fd 得到 struct file 结构。接下来再调用 vfs_write。最终会调用到xnpipe_read()。
static ssize_t xnpipe_read(struct file *file,
char *buf, size_t count, loff_t *ppos)
{
struct xnpipe_state *state = file->private_data;
int sigpending, err = 0;
size_t nbytes, inbytes;
struct xnpipe_mh *mh;
ssize_t ret;
spl_t s;
if (list_empty(&state->outq)) {
if (file->f_flags & O_NONBLOCK) {
xnlock_put_irqrestore(&nklock, s);
return -EWOULDBLOCK;
}
sigpending = xnpipe_wait(state, XNPIPE_USER_WREAD, s,
!list_empty(&state->outq));
......
}
mh = list_get_entry(&state->outq, struct xnpipe_mh, link);
state->nroutq--;
inbytes = 0;
for (;;) {
nbytes = xnpipe_m_size(mh) - xnpipe_m_rdoff(mh);
if (nbytes + inbytes > count)
nbytes = count - inbytes;
if (nbytes == 0)
break;
xnlock_put_irqrestore(&nklock, s);
/* More data could be appended while doing this:
*/
err = __copy_to_user(buf + inbytes,
xnpipe_m_data(mh) + xnpipe_m_rdoff(mh),
nbytes);
xnlock_get_irqsave(&nklock, s);
......
inbytes += nbytes;
xnpipe_m_rdoff(mh) += nbytes;
}
state->ionrd -= inbytes;
ret = inbytes;
if (xnpipe_m_size(mh) > xnpipe_m_rdoff(mh)) {
list_add(&mh->link, &state->outq);
state->nroutq++;
} else {
if (state->ops.output)
state->ops.output(mh, state->xstate);
xnlock_put_irqrestore(&nklock, s);
state->ops.free_obuf(mh, state->xstate);
xnlock_get_irqsave(&nklock, s);
if (state->status & XNPIPE_USER_WSYNC) {
state->status |= XNPIPE_USER_WSYNC_READY;
xnpipe_schedule_request();
}
}
.........
}
先看xnpipe outq链表是否为空,如果为空且设置了非阻塞,直接返回无,否则阻塞到wait_queue_head_t readq上等待,并置位status为XNPIPE_USER_WREAD。
取出outq上的第一个节点,节点数-1,循环拷贝节点内数据到缓冲区,inbytes记录着已拷贝到buf中的数据长度,nbytes表示该节点内未读的数据长度
- 如果数据包节点内数据不足要读取的长度,那数据包内有多少数据就拷贝多少,例如需要读取60Byte数据,但节点内未只有50Byte数据,那本次只能读取50Byte。
- 如果节点内的数据长度大于要读取的长度,会更新节点内消息头的已读偏移量rdoff,将该节点重新插入链表outq,下次读的时候从偏移量rdoff开始拷贝数据。
等节点内数据都被读取后,如果xenomai端设置了回调函数ops.output()则执行ops.output(),然后执行state->ops.free_obuf()来释放消息节点,释放时对于非缓冲区节点,直接free;对于缓冲区节点,不需要释放,清理统计量即可。
static void __xddp_free_handler(void *buf, void *skarg) /* nklock free */
{
struct xddp_socket *sk = skarg;
rtdm_lockctx_t s;
if (buf != sk->buffer) {
xnheap_free(sk->bufpool, buf);
return;
}
/* Reset the streaming buffer. */
rtdm_lock_get_irqsave(&sk->lock, s);
sk->fillsz = 0;
sk->buffer_port = -1;
__clear_bit(_XDDP_SYNCWAIT, &sk->status);
__clear_bit(_XDDP_ATOMIC, &sk->status);
.....
}
接上面的图示一次read()调用读取50Byte数据后如下:

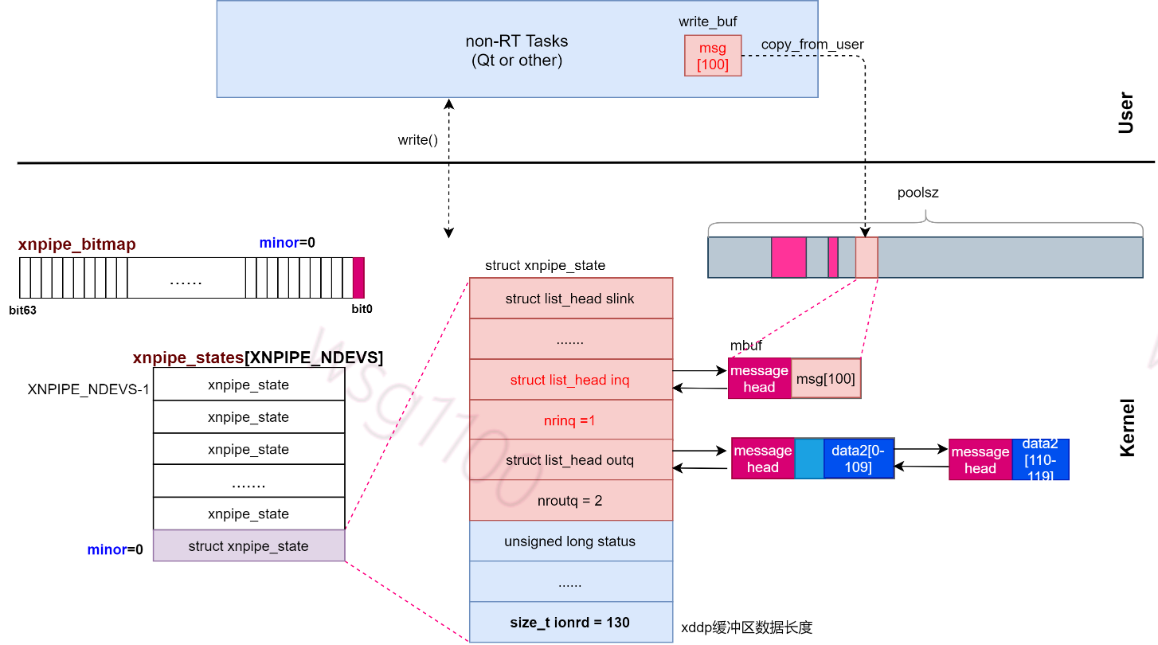
6.linux端写
接下来就是对XDDP设备的读写。写入一个字符设备,就是用文件系统的标准接口 write,参数文件描述符 fd,在内核里面调用的 sys_write,在 sys_write 里面根据文件描述符 fd 得到 struct file 结构。接下来再调用 vfs_write。
ssize_t __vfs_write(struct file *file, const char __user *p, size_t count, loff_t *pos)
{
if (file->f_op->write)
return file->f_op->write(file, p, count, pos);
else if (file->f_op->write_iter)
return new_sync_write(file, p, count, pos);
else
return -EINVAL;
}
可以看到,在 __vfs_write 里面,我们会调用 struct file 结构里的 file_operations 的 write 函数。上面我们打开字符设备的时候,已经将 struct file 结构里面的 file_operations 指向了设备驱动程序的 file_operations 结构,所以这里的 write 函数最终会调用到xnpipe_write()。
static ssize_t xnpipe_write(struct file *file,
const char *buf, size_t count, loff_t *ppos)
{
struct xnpipe_state *state = file->private_data;
struct xnpipe_mh *mh;
int pollnum, ret;
spl_t s;
......
retry:
......
pollnum = state->nrinq + state->nroutq;
xnlock_put_irqrestore(&nklock, s);
mh = state->ops.alloc_ibuf(count + sizeof(*mh), state->xstate);/*分配消息内存*/
.......
if (mh == NULL) {
if (file->f_flags & O_NONBLOCK)
return -EWOULDBLOCK;
xnlock_get_irqsave(&nklock, s);
if (xnpipe_wait(state, XNPIPE_USER_WSYNC, s,
pollnum > state->nrinq + state->nroutq)) {
xnlock_put_irqrestore(&nklock, s);
return -ERESTARTSYS;
}
goto retry;
}
xnpipe_m_size(mh) = count;
xnpipe_m_rdoff(mh) = 0;
if (copy_from_user(xnpipe_m_data(mh), buf, count)) {
....
}
xnlock_get_irqsave(&nklock, s);
list_add_tail(&mh->link, &state->inq);
state->nrinq++;
/* Wake up a Xenomai sleeper if any. 。*/
if (xnsynch_wakeup_one_sleeper(&state->synchbase))
xnsched_run();
if (state->ops.input) {
ret = state->ops.input(mh, 0, state->xstate);//__xddp_input_handler
if (ret)
count = (size_t)ret;
}
if (file->f_flags & O_SYNC) {/*等待对方收*/
if (!list_empty(&state->inq)) {
if (xnpipe_wait(state, XNPIPE_USER_WSYNC, s,
list_empty(&state->inq)))
count = -ERESTARTSYS;
}
}
xnlock_put_irqrestore(&nklock, s);
return (ssize_t)count;
}
向xenomai发送任务与xenomai向linux发类似。先计算xnpipe读和写未决数据总长度pollnum,然后为要发送的数据申请节点空间,如果申请失败表示xenomai内存池内存非配完了,此时,要么直接返回写入失败,要么调用xnpipe_wait阻塞到队列syncq,解阻塞条件为pollnum > state->nrinq + state->nroutq,也就是xnpipe有未决数据被处理,节点就被释放,尝试再次分配内存,比如上面xnpipe_read()函数中60-62行就是该作用。
分配节点mh后,设置消息头内数据长度mh.size,将用户空间数据拷贝到消息节点数据区,接着将消息节点mh挂到input链表inq,由linux写入的数据都是插入链表尾。更新input队列数nrinq;
完成消息节点挂接后,如果有xenomai任务阻塞等待数据,则开始xenomai调度。
如果xddp socket设置有hook函数ops.input(),则执行ops.input()。
接着如果用户设置了写同步标志O_SYNC,则阻塞等待直到实时任务将数据读取。
7. 实时端接收
xenomai任务接收数据,:
/*接收数据*/
ret = recvfrom(s, buf, sizeof(buf), 0, NULL, 0);
if (ret <= 0)
fail("recvfrom");
根据前面的分析一样,先进入libcobalt:
COBALT_IMPL(ssize_t, recvfrom, (int fd, void *buf, size_t len, int flags,
struct sockaddr *from, socklen_t *fromlen))
{
struct iovec iov = {
.iov_base = buf,
.iov_len = len,
};
struct msghdr msg = {
.msg_name = from,
.msg_namelen = from != NULL ? *fromlen : 0,
.msg_iov = &iov,
.msg_iovlen = 1,
.msg_control = NULL,
.msg_controllen = 0,
};
int ret;
ret = do_recvmsg(fd, &msg, flags);
if (ret != -EBADF && ret != -ENOSYS) {
......
return ret;
}
return __STD(recvfrom(fd, buf, len, flags, from, fromlen));
}
COBALT_IMPL(ssize_t, recv, (int fd, void *buf, size_t len, int flags))
{
struct iovec iov = {
.iov_base = (void *)buf,
.iov_len = len,
};
struct msghdr msg = {
.msg_name = NULL,
.msg_namelen = 0,
.msg_iov = &iov,
.msg_iovlen = 1,
.msg_control = NULL,
.msg_controllen = 0,
};
int ret;
ret = do_recvmsg(fd, &msg, flags);
if (ret != -EBADF && ret != -ENOSYS)
return set_errno(ret);
return __STD(recv(fd, buf, len, flags));
}
再由do_recvmsg()发起实时系统调用最终执行xddp_recvmsg().
static ssize_t xddp_recvmsg(struct rtdm_fd *fd,
struct user_msghdr *msg, int flags)
{
struct iovec iov_fast[RTDM_IOV_FASTMAX], *iov;
struct sockaddr_ipc saddr;
ssize_t ret;
......
/* Copy I/O vector in */
ret = rtdm_get_iovec(fd, &iov, msg, iov_fast);
.....
ret = __xddp_recvmsg(fd, iov, msg->msg_iovlen, flags, &saddr);
.......
/* Copy the updated I/O vector back */
if (rtdm_put_iovec(fd, iov, msg, iov_fast))
return -EFAULT;
/* Copy the source address if required. */
if (msg->msg_name) {
if (rtipc_put_arg(fd, msg->msg_name, &saddr, sizeof(saddr)))
return -EFAULT;
msg->msg_namelen = sizeof(struct sockaddr_ipc);
}
return ret;
}
与sendmsg()一样先调用rtdm_get_iovec()处理要读取的数据条数及每条数据长度,再调用__xddp_recvmsg()读取数据。
static ssize_t __xddp_recvmsg(struct rtdm_fd *fd,
struct iovec *iov, int iovlen, int flags,
struct sockaddr_ipc *saddr)
{
struct rtipc_private *priv = rtdm_fd_to_private(fd);
struct xddp_message *mbuf = NULL; /* Fake GCC */
struct xddp_socket *sk = priv->state;
ssize_t maxlen, len, wrlen, vlen;
nanosecs_rel_t timeout;
struct xnpipe_mh *mh;
int nvec, rdoff, ret;
struct xnbufd bufd;
spl_t s;
.....
maxlen = rtdm_get_iov_flatlen(iov, iovlen); /*要读取的长度*/
.......
timeout = (flags & MSG_DONTWAIT) ? RTDM_TIMEOUT_NONE : sk->timeout;
/* Pull heading message from the input queue. */
len = xnpipe_recv(sk->minor, &mh, timeout);
.......
}
计算本次读取的总长度maxlen,再调用xnpipe_recv()从xnpipe输入队列中取一个消息节点,取消息节点过程如下:
ssize_t xnpipe_recv(int minor, struct xnpipe_mh **pmh, xnticks_t timeout)
{
struct xnpipe_state *state;
struct xnpipe_mh *mh;
xntmode_t mode;
ssize_t ret;
int info;
spl_t s;
......
state = &xnpipe_states[minor];
......
/*
* If we received a relative timespec, rescale it to an
* absolute time value based on the monotonic clock.
*/
mode = XN_RELATIVE;
if (timeout != XN_NONBLOCK && timeout != XN_INFINITE) {
mode = XN_ABSOLUTE;
timeout += xnclock_read_monotonic(&nkclock);
}
for (;;) {
if (!list_empty(&state->inq))/*有数据*/
break;
if (timeout == XN_NONBLOCK) { /*非阻塞*/
ret = -EWOULDBLOCK;
goto unlock_and_exit;
}
info = xnsynch_sleep_on(&state->synchbase, timeout, mode); /*在xnsynch上睡眠*/
if (info & XNTIMEO) { /*超时*/
ret = -ETIMEDOUT;
goto unlock_and_exit;
}
if (info & XNBREAK) { /*被其他强制唤醒*/
ret = -EINTR;
goto unlock_and_exit;
}
if (info & XNRMID) { /*该资源已被不存在*/
ret = -EIDRM;
goto unlock_and_exit;
}
}
mh = list_get_entry(&state->inq, struct xnpipe_mh, link);/*从inq取下该消息节点*/
*pmh = mh;
state->nrinq--; /*统计减一*/
ret = (ssize_t)xnpipe_m_size(mh);/*数据长度*/
if (state->status & XNPIPE_USER_WSYNC) {/*如果linux线程正在等待SYNC*/
state->status |= XNPIPE_USER_WSYNC_READY;
xnpipe_schedule_request(); /*发送xnpipe_wakeup_apc,唤醒非实时任务*/
}
unlock_and_exit:
xnlock_put_irqrestore(&nklock, s);
return ret;
}
如果输入队列inq为空,说名没有消息可接收,用户如果设置的超时等待,则阻塞等待,否则直接返回。
从输入队列取出一个消息节点后,如果linux发送消息时使用写同步(O_SYNC)阻塞,需要调用xnpipe_schedule_request()发送xnpipe_wakeup_apc,告诉linux 阻塞的任务可以唤醒了,至于什么时候唤醒需要等到linux得到运行,然后返回该消息节点内数据长度len。
回到__xddp_recvmsg(),接着将消息节点内的数据拷贝到用户缓冲区iov[nvec].iov_base中,拷贝后释放。最后是异步io相关处理以后再说。
len = xnpipe_recv(sk->minor, &mh, timeout);
if (len < 0)
return len == -EIDRM ? 0 : len;
if (len > maxlen) {
ret = -ENOBUFS;
goto out;
}
....
mbuf = container_of(mh, struct xddp_message, mh);
if (saddr)
*saddr = sk->name;
/* Write "len" bytes from mbuf->data to the vector cells */
for (ret = 0, nvec = 0, rdoff = 0, wrlen = len;
nvec < iovlen && wrlen > 0; nvec++) {
if (iov[nvec].iov_len == 0)
continue;
vlen = wrlen >= iov[nvec].iov_len ? iov[nvec].iov_len : wrlen;
if (rtdm_fd_is_user(fd)) {/*用户空间应用发起的读*/
xnbufd_map_uread(&bufd, iov[nvec].iov_base, vlen);
ret = xnbufd_copy_from_kmem(&bufd, mbuf->data + rdoff, vlen);
xnbufd_unmap_uread(&bufd);
} else { /*内核空间应用发起的读*/
xnbufd_map_kread(&bufd, iov[nvec].iov_base, vlen);
ret = xnbufd_copy_from_kmem(&bufd, mbuf->data + rdoff, vlen);
xnbufd_unmap_kread(&bufd);
}
if (ret < 0)
goto out;
iov[nvec].iov_base += vlen;
iov[nvec].iov_len -= vlen;
wrlen -= vlen;
rdoff += vlen;
}
out:
xnheap_free(sk->bufpool, mbuf); /*释放节点*/
cobalt_atomic_enter(s);
if ((__xnpipe_pollstate(sk->minor) & POLLIN) == 0 &&
xnselect_signal(&priv->recv_block, 0))
xnsched_run();
cobalt_atomic_leave(s);
return ret ?: len;
}
8. 实时端关闭
用户空间程序:
/* 关闭套接字*/
close(s);
libcoblt:
COBALT_IMPL(int, close, (int fd))
{
int oldtype;
int ret;
pthread_setcanceltype(PTHREAD_CANCEL_ASYNCHRONOUS, &oldtype);
ret = XENOMAI_SYSCALL1(sc_cobalt_close, fd);
pthread_setcanceltype(oldtype, NULL);
if (ret != -EBADF && ret != -ENOSYS)
return set_errno(ret);
return __STD(close(fd));
}
实时调用sc_cobalt_close:
COBALT_SYSCALL(close, lostage, (int fd))
{
return rtdm_fd_close(fd, 0);
}
进一步调用rtdm_fd_close().
int rtdm_fd_close(int ufd, unsigned int magic)
{
struct rtdm_fd_index *idx;
struct cobalt_ppd *ppd;
struct rtdm_fd *fd;
spl_t s;
secondary_mode_only();
....
ppd = cobalt_ppd_get(0);
xnlock_get_irqsave(&fdtree_lock, s);
idx = fetch_fd_index(ppd, ufd);
.....
fd = idx->fd;
......
__fd_close(ppd, idx, s);
__close_fd(current->files, ufd);
return 0;
}
无论是内核线程还是用户线程,先得到cobalt_ppd,要关闭的ufd对应的rtdm_fd_index,接着调用__fd_close()释放ufd:
static void
__fd_close(struct cobalt_ppd *p, struct rtdm_fd_index *idx, spl_t s)
{
xnid_remove(&p->fds, &idx->id);
__put_fd(idx->fd, s);
kfree(idx);
}
__fd_close()中先将rdmt_fd对应的节点从cobalt_ppd管理任务所有rtdm_fd的红黑树fds上删除,接着调用__put_fd(idx->fd, s)。
static void __put_fd(struct rtdm_fd *fd, spl_t s)
{
int destroy;
destroy = --fd->refs == 0;
xnlock_put_irqrestore(&fdtree_lock, s);
if (!destroy)
return;
if (ipipe_root_p)
fd->ops->close(fd);/*rtipc_close*/
else {
struct lostage_trigger_close closework = {
.work = {
.size = sizeof(closework),
.handler = lostage_trigger_close,
},
};
xnlock_get_irqsave(&fdtree_lock, s);
list_add_tail(&fd->cleanup, &rtdm_fd_cleanup_queue);
xnlock_put_irqrestore(&fdtree_lock, s);
ipipe_post_work_root(&closework, work);
}
}
先将rtdm_fd引用计数减一,再决定是否释放该rtdm_fd。释放需要先判断当前所处域,如果现在就在root域直接调用fd->ops->close(fd),也就是rtipc_close();如果现在处于head域,则需要延迟到root在处理,先将该rtdm_fd挂载到rtdm_fd_cleanup_queue。向linux发送一个work---closework,通知linux对rtdm_fd_cleanup_queue上的所有rtdm_fd执行close操作,等linux得到运行的时候也就会调用fd->ops->close(fd),也就是rtipc_close();
不管所处域如何,最终都是rtipc_close()。
static void rtipc_close(struct rtdm_fd *fd)
{
struct rtipc_private *priv = rtdm_fd_to_private(fd);
priv->proto->proto_ops.close(fd);
xnselect_destroy(&priv->recv_block);
xnselect_destroy(&priv->send_block);
}
其中priv->proto->proto_ops.close(fd)是我们绑定的协议xddp对应的xddp_close()
static void xddp_close(struct rtdm_fd *fd)
{
struct rtipc_private *priv = rtdm_fd_to_private(fd);
struct xddp_socket *sk = priv->state;
rtdm_lockctx_t s;
sk->monitor = NULL;
if (!test_bit(_XDDP_BOUND, &sk->status))
return;
cobalt_atomic_enter(s);
portmap[sk->name.sipc_port] = NULL;
cobalt_atomic_leave(s);
if (sk->handle)
xnregistry_remove(sk->handle);
xnpipe_disconnect(sk->minor);
}
都是对xddp_socket成员变量的清理,最后调用xnpipe_disconnect()对XNPIPIE对象清零。
int xnpipe_disconnect(int minor)
{
struct xnpipe_state *state;
int need_sched = 0;
spl_t s;
.....
state = &xnpipe_states[minor];
.....
state->status &= ~XNPIPE_KERN_CONN;
state->ionrd -= xnpipe_flushq(state, outq, free_obuf, s);
.....
xnpipe_flushq(state, inq, free_ibuf, s);
if (xnsynch_destroy(&state->synchbase) == XNSYNCH_RESCHED)
xnsched_run();
if (state->status & XNPIPE_USER_WREAD) {
state->status |= XNPIPE_USER_WREAD_READY;
need_sched = 1;
}
if (state->asyncq) { /* Schedule asynch sig. 安排异步信号。*/
state->status |= XNPIPE_USER_SIGIO;
need_sched = 1;
}
cleanup:
/*
* If xnpipe_release() has not fully run, enter lingering
* close. This will prevent the extra state from being wiped
* out until then.
*/
if (state->status & XNPIPE_USER_CONN)
state->status |= XNPIPE_KERN_LCLOSE;
else {
xnlock_put_irqrestore(&nklock, s);
state->ops.release(state->xstate);
xnlock_get_irqsave(&nklock, s);
xnpipe_minor_free(minor);
}
if (need_sched)
xnpipe_schedule_request();
xnlock_put_irqrestore(&nklock, s);
return 0;
}
其中xnpipe_flushq()释放xnpipe上的未决消息节点,如果linux阻塞在xnpipe上,唤醒它让它给应用发送关闭信号。最后调用state->ops.release(state->xstate)即xnpipe_release()来完成底层xnpipe对象的清理.
回到rtdm_fd_close(),接着完成rtdm_fd相关清理后。执行__close_fd(current->files, ufd),关闭ufd对应的文件。ufd是创建socket时linux 在用户空间定义的[rtdm-socket]文件描述符。发出通知以后释放rtdm_fd_index。
版权声明:本文为本文为博主原创文章,转载请注明出处。如有问题,欢迎指正。博客地址:https://www.cnblogs.com/wsg1100/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号