

【原创】xenomai内核解析--双核系统调用(一)
版权声明:本文为本文为博主原创文章,转载请注明出处。如有错误,欢迎指正。博客地址:https://www.cnblogs.com/wsg1100/
xenomai 内核系统调用
解析系统调用是了解内核架构最有力的一把钥匙。
在Linux内核基础上加入xenomai实时系统内核后,在内核空间两个内核共存,实时任务需要xenomai内核来完成实时的服务,如果实时任务需要用到linux的服务,还可以调用linux内核的系统调用,你可能会好奇xenomai与linux两个内核共存后系统调用是如何实现的?
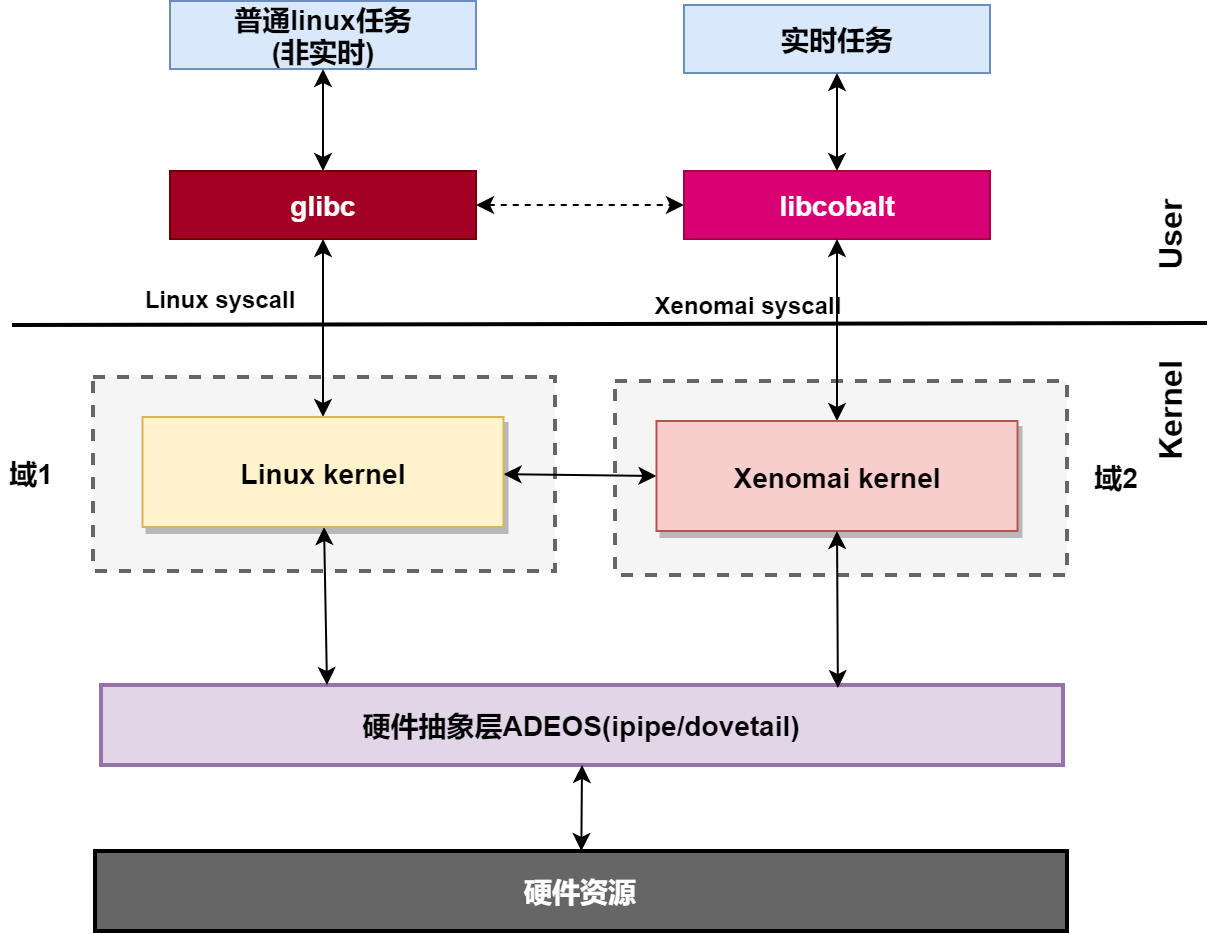
为什么需要系统调用?现代操作系统中,处理器的运行模式一般分为两个空间:内核空间和用户空间,大部分应用程序运行在用户空间,而操作系统内核和设备驱动程序运行在内核空间,如果应用程序需要访问硬件资源或者需要内核提供服务,该怎么办?
为了向用户空间上运行的应用程序提供服务,内核提供了一组接口。透过该接口,应用程序可以访问硬件设备和其他操作系统资源。这组接口在应用程序和内核之间扮演了使者的角色,应用程序发送各种请求,而内核负责满足这些请求,这些接口就是系统调用,它是用户空间和内核空间一个中间层。
系统调用层主要作用有三个:
- 它为用户空间提供了一种统一的硬件的抽象接口。比如当需要读些文件的时候,应用程序就可以不去管磁盘类型和介质,甚至不用去管文件所在的文件系统到底是哪种类型。
- 系统调用保证了系统的稳定和安全。应用程序要访问内核就必须通过系统调用层,内核可以在系统调用层对应用程序的访问权限、用户类型和其他一些规则进行过滤,这避免了应用不正确地访问内核,保证了系统和各个应用程序的安全性。
- 可移植性。可以让应用程序在不修改源代码的情况下,在不同的操作系统或拥有不同硬件架构的系统中重新编译运行。
回到本文开头的问题,该问题细分为如下两个问题:
- 双核共存时,如何区分应用发起的系统调用是xenomai内核调用还是linux内核调用?
- 一个xenomai实时任务既可以调用xenomai内核服务,也可以调用linux内核服务,这是如何做到的?
本文通过分析源代码为你解答问题1,对于问题2,涉及双核间的调度,本文暂不涉及,后面的文章(【原创】xenomai内核解析-xenomai实时线程创建流程)揭晓答案。
一、32位Linux系统调用
我们先来看没有ipipe和xenomai内核时的linux系统调用流程是怎样的。
linux操作系统的API通常以C标准库的方式提供,比如linux中的libc库。C标准库中提供了POSIX的绝大部分API实现,glibc为了提高应用程序的性能,还对一些系统调用进行了封装。此外,由于32位系统系统调用使用软中断int 0x80指令实现,应用程序也可以通过汇编直接进行系统调用。软中断属于异常的一种,通过执行该指令陷入(trap)内核,trap在整理的文档x86 Linux中断系统有说明。内核初始化过程中,通过函数tarp_init()设置IDT(Interrupt Descriptor Table 记录每个中断异常处理程序的地址的一张表),有关int 0x80的IDT表项如下:
static const __initconst struct idt_data def_idts[] = {
......
SYSG(IA32_SYSCALL_VECTOR, entry_INT80_32),
......
};
当产生系统调用时,硬件根据向量号在 IDT 中找到对应的表项,即中断描述符,进行特权级检查,发现 DPL = CPL = 3 ,允许调用。然后硬件将切换到内核栈 (tss.ss0 : tss.esp0)。接着根据中断描述符的 segment selector 在 GDT / LDT 中找到对应的段描述符,从段描述符拿到段的基址,加载到 cs 。将 offset 加载到 eip。最后硬件将 ss / sp / eflags / cs / ip / error code 依次压到内核栈。于是开始执行entry_INT80_32函数,该函数在entry_32.S定义:
ENTRY(entry_INT80_32)
ASM_CLAC
pushl %eax /* pt_regs->orig_ax */
SAVE_ALL pt_regs_ax=$-ENOSYS /* *存储当前用户态寄存器,保存在pt_regs结构里*/
/*
* User mode is traced as though IRQs are on, and the interrupt gate
* turned them off.
*/
TRACE_IRQS_OFF
movl %esp, %eax
call do_int80_syscall_32
.Lsyscall_32_done:
.......
.Lirq_return:
INTERRUPT_RETURN/*iret 指令将原来用户态保存的现场恢复回来,包含代码段、指令指针寄存器等。这时候用户态
进程恢复执行。*/
在内核栈的最高地址端,存放的是结构 pt_regs,首先通过 push 和 SAVE_ALL 将当前用户态的寄存器,保存在栈中 pt_regs 结构里面.保存完毕后,关闭中断,将当前栈指针保存到 eax,即do_int80_syscall_32的参数1。
调用do_int80_syscall_32=>do_syscall_32_irqs_on。先看看没有ipipe时Linux实现如下:
__always_inline void do_syscall_32_irqs_on(struct pt_regs *regs)
{
struct thread_info *ti = pt_regs_to_thread_info(regs);
unsigned int nr = (unsigned int)regs->orig_ax;
.....
if (likely(nr < IA32_NR_syscalls)) {
nr = array_index_nospec(nr, IA32_NR_syscalls);
regs->ax = ia32_sys_call_table[nr]( /*根据系统调用号索引直接执行*/
(unsigned int)regs->bx, (unsigned int)regs->cx,
(unsigned int)regs->dx, (unsigned int)regs->si,
(unsigned int)regs->di, (unsigned int)regs->bp);
}
syscall_return_slowpath(regs);
}
在这里,将系统调用号从pt_reges中eax 里面取出来,然后根据系统调用号,在系统调用表中找到相应的函数进行调用,并将寄存器中保存的参数取出来,作为函数参数。如果仔细比对,就能发现,这些参数所对应的寄存器,和 Linux 的注释是一样的。ia32_sys_call_table系统调用表生成后面解析(此图来源于网络)。
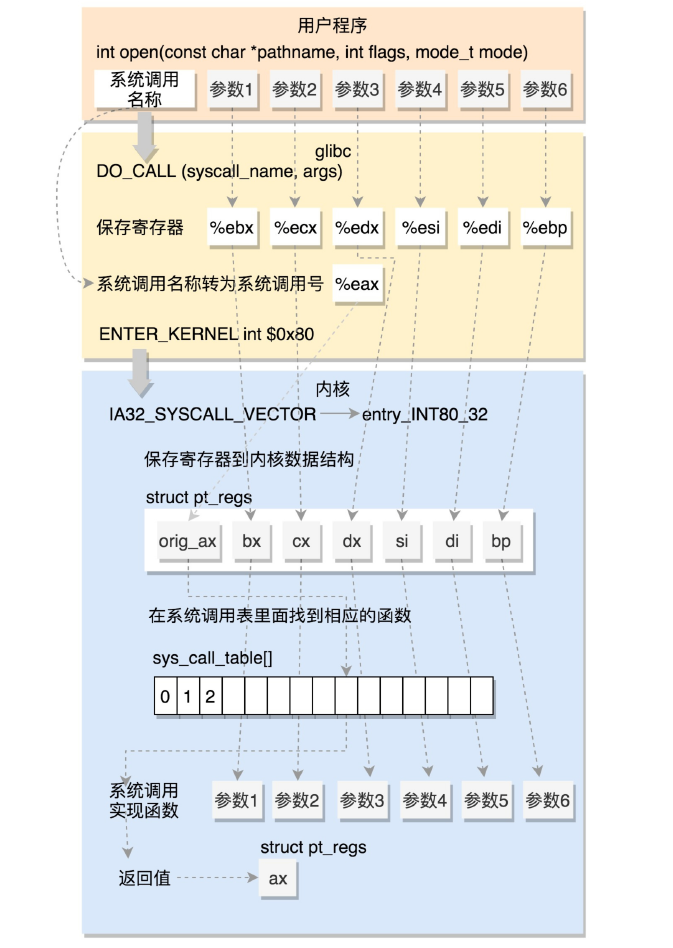
相关内核调用执行完后,一直返回到 do_syscall_32_irqs_on ,如果系统调用有返回值,会被保存到 regs->ax 中。接着返回 entry_INT80_32 继续执行,最后执行 INTERRUPT_RETURN 。 INTERRUPT_RETURN 在 arch/x86/include/asm/irqflags.h 中定义为 iret ,iret 指令将原来用户态保存的现场恢复回来,包含代码段、指令指针寄存器等。这时候用户态进程恢复执行。
系统调用执行完毕。
二、32位实时系统调用
xenomai+linux双内核架构下,通过I-pipe 拦截系统调用,并将系统调用定向到实现它们的系统。
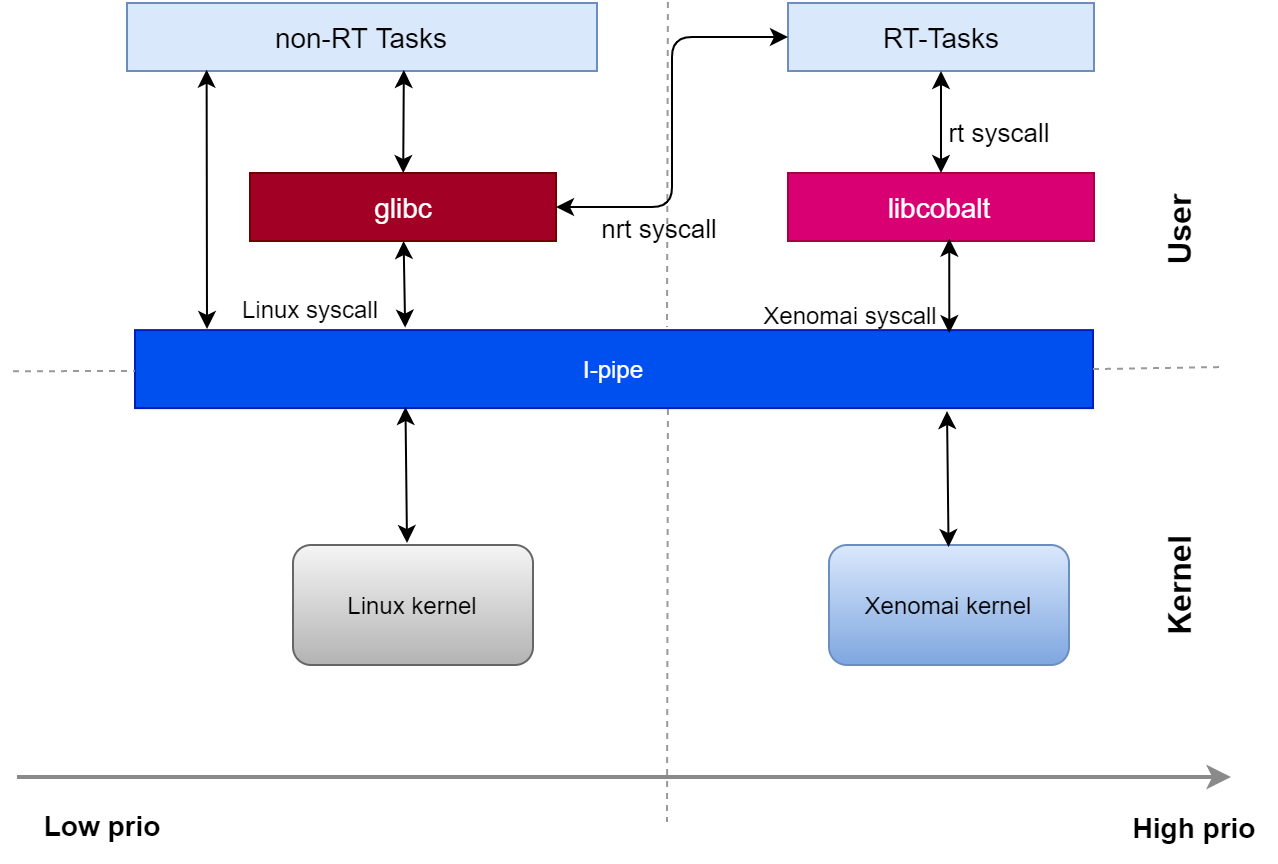
实时系统调用,除了直接通过汇编系统调用外,xenomai还实现了libcoblat实时库,相当于glibc,通过libcoblat进行xenomai系统调用,以libcoblat库函数sem_open为例,libcolat库中C函数实现如下:
COBALT_IMPL(sem_t *, sem_open, (const char *name, int oflags, ...))
{
......
err = XENOMAI_SYSCALL5(sc_cobalt_sem_open,
&rsem, name, oflags, mode, value);
if (err == 0) {
if (rsem != sem)
free(sem);
return &rsem->native_sem;
}
.......
return SEM_FAILED;
}
libcolat库调用系统调用使用宏XENOMAI_SYSCALL5,XENOAI_SYSCALL宏在\include\asm\xenomai\syscall.h中声明,XENOMAI_SYSCALL5中的'5'代表'该系统调用有五个参数:
#define XENOMAI_DO_SYSCALL(nr, op, args...) \
({ \
unsigned __resultvar; \
asm volatile ( \
LOADARGS_##nr \
"movl %1, %%eax\n\t" \
DOSYSCALL \
RESTOREARGS_##nr \
: "=a" (__resultvar) \
: "i" (__xn_syscode(op)) ASMFMT_##nr(args) \
: "memory", "cc"); \
(int) __resultvar; \
})
#define XENOMAI_SYSCALL0(op) XENOMAI_DO_SYSCALL(0,op)
#define XENOMAI_SYSCALL1(op,a1) XENOMAI_DO_SYSCALL(1,op,a1)
#define XENOMAI_SYSCALL2(op,a1,a2) XENOMAI_DO_SYSCALL(2,op,a1,a2)
#define XENOMAI_SYSCALL3(op,a1,a2,a3) XENOMAI_DO_SYSCALL(3,op,a1,a2,a3)
#define XENOMAI_SYSCALL4(op,a1,a2,a3,a4) XENOMAI_DO_SYSCALL(4,op,a1,a2,a3,a4)
#define XENOMAI_SYSCALL5(op,a1,a2,a3,a4,a5) XENOMAI_DO_SYSCALL(5,op,a1,a2,a3,a4,a5)
每个宏中,内嵌另一个宏DOSYSCALL,即实现系统调用的int指令:int $0x80。
#define DOSYSCALL "int $0x80\n\t"
系统调用过程硬件处理及中断入口上节一致,从do_syscall_32_irqs_on开始不同,有ipipe后变成下面这样子:
static __always_inline void do_syscall_32_irqs_on(struct pt_regs *regs)
{
struct thread_info *ti = current_thread_info();
unsigned int nr = (unsigned int)regs->orig_ax;/*取出系统调用号*/
int ret;
ret = pipeline_syscall(ti, nr, regs);/*pipeline 拦截系统调用*/
......
done:
syscall_return_slowpath(regs);
}
套路和ipipe接管中断类似,在关键路径上拦截系统调用,然后调用ipipe_handle_syscall(ti, nr, regs)让ipipe来接管处理:
int ipipe_handle_syscall(struct thread_info *ti,
unsigned long nr, struct pt_regs *regs)
{
unsigned long local_flags = READ_ONCE(ti->ipipe_flags);
int ret;
if (nr >= NR_syscalls && (local_flags & _TIP_HEAD)) {/*运行在head域且者系统调用号超过linux*/
ipipe_fastcall_hook(regs); /*快速系统调用路径*/
local_flags = READ_ONCE(ti->ipipe_flags);
if (local_flags & _TIP_HEAD) {
if (local_flags & _TIP_MAYDAY)
__ipipe_call_mayday(regs);
return 1; /* don't pass down, no tail work. */
} else {
sync_root_irqs();
return -1; /* don't pass down, do tail work. */
}
}
if ((local_flags & _TIP_NOTIFY) || nr >= NR_syscalls) {
ret =__ipipe_notify_syscall(regs);
local_flags = READ_ONCE(ti->ipipe_flags);
if (local_flags & _TIP_HEAD)
return 1; /* don't pass down, no tail work. */
if (ret)
return -1; /* don't pass down, do tail work. */
}
return 0; /* pass syscall down to the host. */
}
这个函数的处理逻辑是这样,怎样区分xenomai系统调用和linux系统调用?每个CPU架构不同linux系统调用总数不同,在x86系统中有300多个,用变量NR_syscalls表示,系统调用号与系统调用一一对应。首先获取到的系统调用号nr >= NR_syscalls,不用多想,那这个系统调用是xenomai内核的系统调用。
另外还有个问题,如果是Linux非实时任务触发的xenomai系统调用,或者xenomai 实时任务要调用linux的服务,这些交叉服务涉及实时任务与非实时任务在两个内核之间运行,优先级怎么处理等问题。这些涉及cobalt_sysmodes[].
首先看怎么区分一个任务是realtime还是no_realtime。在task_struct结构的头有一个成员结构体thread_info,存储着当前线程的信息,ipipe在结构体thread_info中增加了两个成员变量ipipe_flags和ipipe_data,ipipe_flags用来来标示一个线程是实时还是非实时,_TIP_HEAD置位表示已经是实时上下文。对于需要切换到xenomai上下文的系统调用_TIP_NOTIFY置位。
struct thread_info {
unsigned long flags; /* low level flags */
u32 status; /* thread synchronous flags */
#ifdef CONFIG_IPIPE
unsigned long ipipe_flags;
struct ipipe_threadinfo ipipe_data;
#endif
};
ipipe_handle_syscall处理逻辑:
1.对于已经在实时上下文的实时任务发起xenomai的系统调用,使用快速调用路径函数ipipe_fastcall_hook(regs);
2.需要切换到实时上下文或者非实时调用实时的,使用慢速调用路径:
__ipipe_notify_syscall(regs)
->ipipe_syscall_hook(caller_domain, regs)
快速调用ipipe_fastcall_hook(regs)内直接handle_head_syscall执行代码如下:
static int handle_head_syscall(struct ipipe_domain *ipd, struct pt_regs *regs)
{
....
code = __xn_syscall(regs);
nr = code & (__NR_COBALT_SYSCALLS - 1);
......
handler = cobalt_syscalls[code];
sysflags = cobalt_sysmodes[nr];
........
ret = handler(__xn_reg_arglist(regs));
.......
__xn_status_return(regs, ret);
.......
}
这个函数很复杂,涉及xenomai与linux之间很多联系,代码是简化后的,先取出系统调用号,然后从cobalt_syscalls取出系统调用入口handler,然后执行handler(__xn_reg_arglist(regs))执行完成后将执行结果放到寄存器ax,后面的文章会详细分析ipipe如何处理系统调用。
三、 64位系统调用
我们再来看 64 位的情况,系统调用,不是用中断了,而是改用 syscall 指令。并且传递参数的寄存器也变了。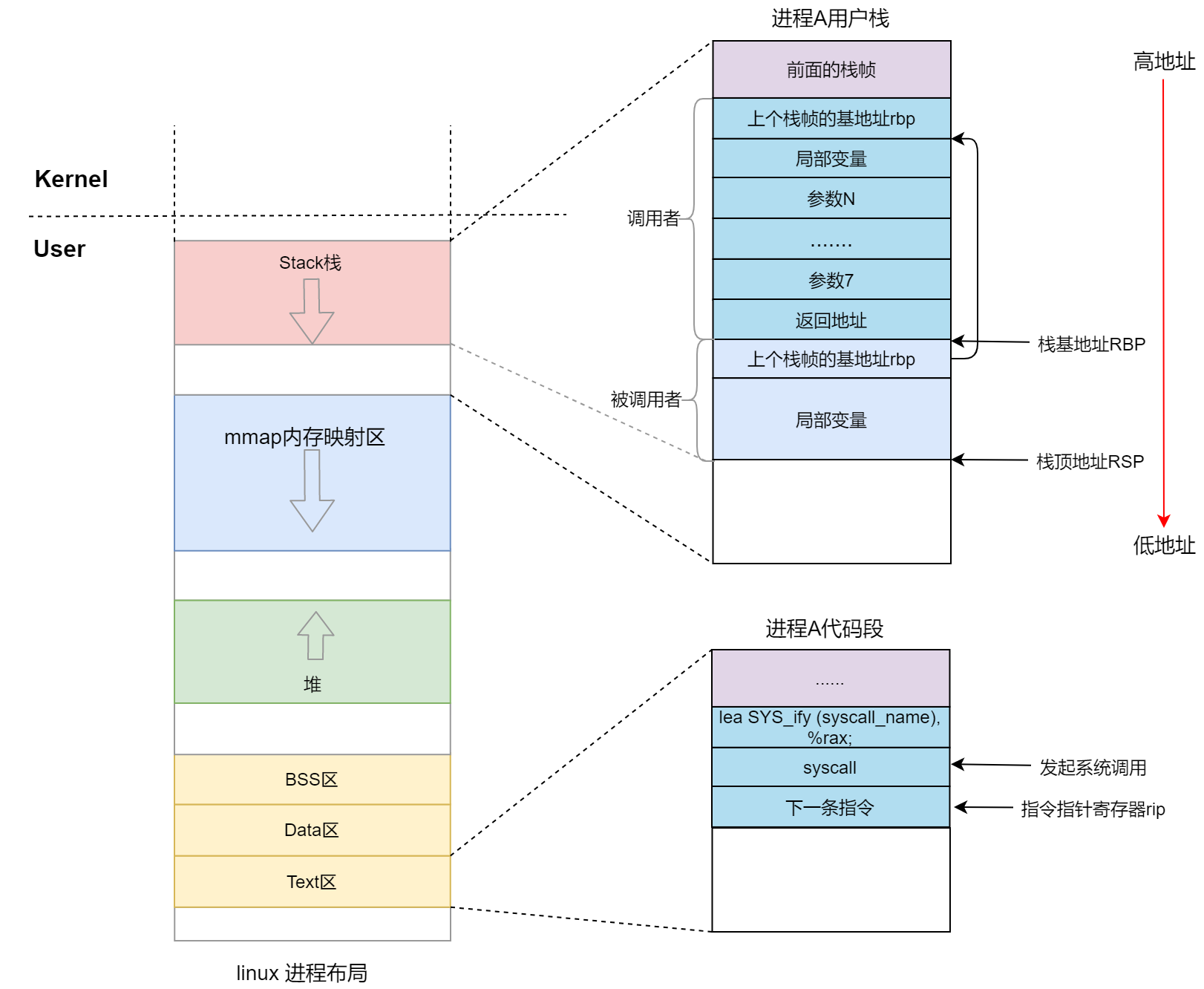
#define DO_SYSCALL(name, nr, args...) \
({ \
unsigned long __resultvar; \
LOAD_ARGS_##nr(args) \
LOAD_REGS_##nr \
asm volatile ( \
"syscall\n\t" \
: "=a" (__resultvar) \
: "0" (name) ASM_ARGS_##nr \
: "memory", "cc", "r11", "cx"); \
(int) __resultvar; \
})
#define XENOMAI_DO_SYSCALL(nr, op, args...) \
DO_SYSCALL(__xn_syscode(op), nr, args)
#define XENOMAI_SYSBIND(breq) \
XENOMAI_DO_SYSCALL(1, sc_cobalt_bind, breq)
这里将系统调用号使用__xn_syscode(op)处理了一下,把最高位置1,表示Cobalt系统调用,然后使用syscall 指令。
#define __COBALT_SYSCALL_BIT 0x10000000
#define __xn_syscode(__nr) (__COBALT_SYSCALL_BIT | (__nr))
syscall 指令还使用了一种特殊的寄存器,我们叫特殊模块寄存器(Model Specific Registers,简称 MSR)。这种寄存器是 CPU 为了完成某些特殊控制功能为目的的寄存器,其中就有系统调用。在系统初始化的时候,trap_init 除了初始化上面的中断模式,这里面还会调用 cpu_init->syscall_init。这里面有这样的代码:
wrmsrl(MSR_LSTAR, (unsigned long)entry_SYSCALL_64);
rdmsr 和 wrmsr 是用来读写特殊模块寄存器的。MSR_LSTAR 就是这样一个特殊的寄存器, 当 syscall 指令调用的时候,会从这个寄存器里面拿出函数地址来调用,也就是调entry_SYSCALL_64。
该函数在'entry_64.S'定义:
ENTRY(entry_SYSCALL_64)
UNWIND_HINT_EMPTY
......
swapgs
/*
* This path is only taken when PAGE_TABLE_ISOLATION is disabled so it
* is not required to switch CR3.
*/
movq %rsp, PER_CPU_VAR(rsp_scratch)
movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp
/* Construct struct pt_regs on stack */
pushq $__USER_DS /* pt_regs->ss */
pushq PER_CPU_VAR(rsp_scratch) /* pt_regs->sp */
pushq %r11 /* pt_regs->flags */
pushq $__USER_CS /* pt_regs->cs */
pushq %rcx /* pt_regs->ip *//*保存用户太指令指针寄存器*/
GLOBAL(entry_SYSCALL_64_after_hwframe)
pushq %rax /* pt_regs->orig_ax */
PUSH_AND_CLEAR_REGS rax=$-ENOSYS
TRACE_IRQS_OFF
/* IRQs are off. */
movq %rsp, %rdi
call do_syscall_64 /* returns with IRQs disabled */
TRACE_IRQS_IRETQ /* we're about to change IF */
/*
* Try to use SYSRET instead of IRET if we're returning to
* a completely clean 64-bit userspace context. If we're not,
* go to the slow exit path.
*/
movq RCX(%rsp), %rcx
movq RIP(%rsp), %r11
cmpq %rcx, %r11 /* SYSRET requires RCX == RIP */
jne swapgs_restore_regs_and_return_to_usermode
.......
testq $(X86_EFLAGS_RF|X86_EFLAGS_TF), %r11
jnz swapgs_restore_regs_and_return_to_usermode
/* nothing to check for RSP */
cmpq $__USER_DS, SS(%rsp) /* SS must match SYSRET */
jne swapgs_restore_regs_and_return_to_usermode
/*
* We win! This label is here just for ease of understanding
* perf profiles. Nothing jumps here.
*/
syscall_return_via_sysret:
/* rcx and r11 are already restored (see code above) */
UNWIND_HINT_EMPTY
POP_REGS pop_rdi=0 skip_r11rcx=1
/*
* Now all regs are restored except RSP and RDI.
* Save old stack pointer and switch to trampoline stack.
*/
movq %rsp, %rdi
movq PER_CPU_VAR(cpu_tss_rw + TSS_sp0), %rsp
pushq RSP-RDI(%rdi) /* RSP */
pushq (%rdi) /* RDI */
/*
* We are on the trampoline stack. All regs except RDI are live.
* We can do future final exit work right here.
*/
SWITCH_TO_USER_CR3_STACK scratch_reg=%rdi
popq %rdi
popq %rsp
USERGS_SYSRET64
END(entry_SYSCALL_64)
这里先保存了很多寄存器到 pt_regs 结构里面,例如用户态的代码段、数据段、保存参数的寄存器.
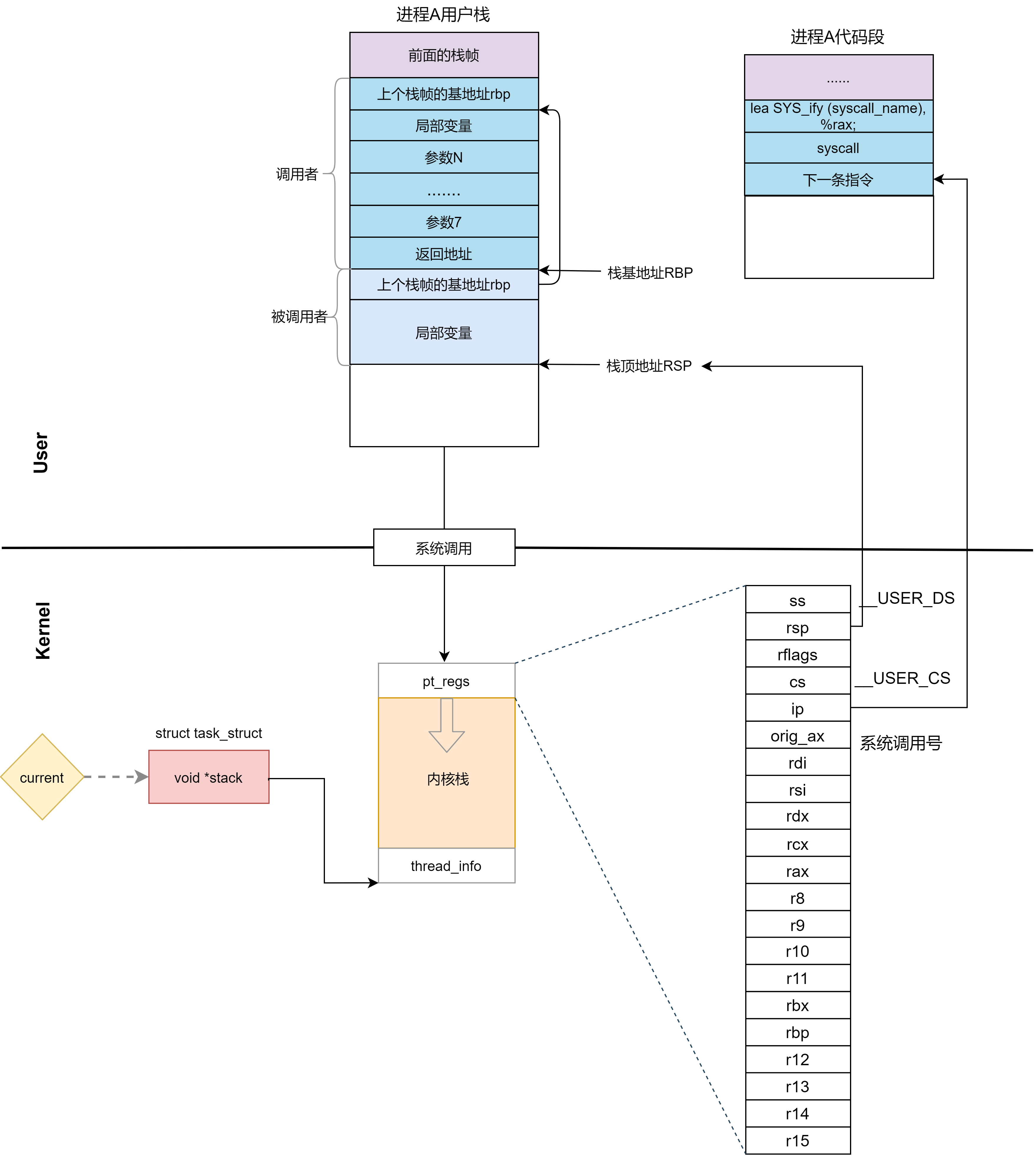
然后调用 entry_SYSCALL64_slow_pat->do_syscall_64。
__visible void do_syscall_64(struct pt_regs *regs)
{
struct thread_info *ti = current_thread_info();
unsigned long nr = regs->orig_ax; /*取出系统调用号*/
int ret;
enter_from_user_mode();
enable_local_irqs();
ret = ipipe_handle_syscall(ti, nr & __SYSCALL_MASK, regs);
if (ret > 0) {
disable_local_irqs();
return;
}
if (ret < 0)
goto done;
......
if (likely((nr & __SYSCALL_MASK) < NR_syscalls)) {
nr = array_index_nospec(nr & __SYSCALL_MASK, NR_syscalls);
regs->ax = sys_call_table[nr](
regs->di, regs->si, regs->dx,
regs->r10, regs->r8, regs->r9);
}
done:
syscall_return_slowpath(regs);
}
与32位一样,ipipe拦截了系统调用,后面的处理流程类似所以,无论是 32 位,还是 64 位,都会到linux系统调用表 sys_call_table和xenomai系统调用表cobalt_syscalls[] 这里来。
五、 实时系统调用表cobalt_syscalls
xenomai每个系统的系统系统调用号在\cobalt\uapi\syscall.h中:
#define sc_cobalt_bind 0
#define sc_cobalt_thread_create 1
#define sc_cobalt_thread_getpid 2
......
#define sc_cobalt_extend 96
bind()函数在内核代码中对应的声明和实现为:
/*声明*/
#define COBALT_SYSCALL_DECL(__name, __args) \
long CoBaLt_ ## __name __args
static COBALT_SYSCALL_DECL(bind, lostage,
(struct cobalt_bindreq __user *u_breq));
/*实现*/
#define COBALT_SYSCALL(__name, __mode, __args) \
long CoBaLt_ ## __name __args
static COBALT_SYSCALL(bind, lostage,
(struct cobalt_bindreq __user *u_breq)){......}
其中__name表示系统调用名对应bind、__mode表示该系统调用模式对应lostage。COBALT_SYSCALL展开定义的bind函数后如下:
long CoBaLt_bind(struct cobalt_bindreq __user *u_breq){......}
怎么将CoBaLt_bind与系统调用号sc_cobalt_bind联系起来后放入cobalt_syscalls[]的呢?
在编译过程中Makefile使用脚本gen-syscall-entries.sh处理各个.c文件中的COBALT_SYSCALL宏,生成一个头文件syscall_entries.h,里面是对每个COBALT_SYSCALL宏处理后后的项,以上面COBALT_SYSCALL(bind,...)为例syscall_entries.h中会生成如下两项,第一项为系统调用入口,第二项为系统调用的模式:
#define __COBALT_CALL_ENTRIES __COBALT_CALL_ENTRY(bind)
#define __COBALT_CALL_MODES __COBALT_MODE(lostage)
实时系统调用表cobalt_syscalls[]定义在文件kernel\cobalt\posix\syscall.c中:
#define __syshand__(__name) ((cobalt_syshand)(CoBaLt_ ## __name))
#define __COBALT_NI __syshand__(ni)
#define __COBALT_CALL_NI \
[0 ... __NR_COBALT_SYSCALLS-1] = __COBALT_NI, \
__COBALT_CALL32_INITHAND(__COBALT_NI)
#define __COBALT_CALL_NFLAGS \
[0 ... __NR_COBALT_SYSCALLS-1] = 0, \
__COBALT_CALL32_INITMODE(0)
#define __COBALT_CALL_ENTRY(__name) \
[sc_cobalt_ ## __name] = __syshand__(__name), \
__COBALT_CALL32_ENTRY(__name, __syshand__(__name))
#define __COBALT_MODE(__name, __mode) \
[sc_cobalt_ ## __name] = __xn_exec_##__mode,
#include "syscall_entries.h" /*该头文件由脚本生成*/
static const cobalt_syshand cobalt_syscalls[] = {
__COBALT_CALL_NI
__COBALT_CALL_ENTRIES
};
static const int cobalt_sysmodes[] = {
__COBALT_CALL_NFLAGS
__COBALT_CALL_MODES
};
__COBALT_CALL_NI宏表示数组空间大小为__NR_COBALT_SYSCALLS(128),每一项由__COBALT_CALL_ENTRIES定义,即脚本头文件syscall_entries.h中生成的每一项来填充:
#define __COBALT_CALL_ENTRY(__name) \
[sc_cobalt_ ## __name] = __syshand__(__name), \
__COBALT_CALL32_ENTRY(__name, __syshand__(__name))
__COBALT_CALL32_ENTRY是定义兼容的系统调用,宏展开如下,相当于在数组的多个位置定义包含了同一项CoBaLt_bind:
#define __COBALT_CALL32_ENTRY(__name, __handler) \
__COBALT_CALL32x_ENTRY(__name, __handler) \
__COBALT_CALL32emu_ENTRY(__name, __handler)
#define __COBALT_CALL32emu_ENTRY(__name, __handler) \
[sc_cobalt_ ## __name + 256] = __handler,
#define __COBALT_CALL32x_ENTRY(__name, __handler) \
[sc_cobalt_ ## __name + 128] = __handler,
最后bind系统调用在cobalt_syscalls[]中如下
static const cobalt_syshand cobalt_syscalls[] = {
[sc_cobalt_bind] = CoBaLt_bind,
[sc_cobalt_bind + 128] = CoBaLt_bind, /*x32 support */
[sc_cobalt_bind + 256] = CoBaLt_bind, /*ia32 emulation support*/
.....
};
相应的数组cobalt_sysmodes[]中的内容如下:
static const int cobalt_sysmodes[] = {
[sc_cobalt_bind] = __xn_exec_bind,
[sc_cobalt_bind + 256] = __xn_exec_lostage, /*x32 support */
[sc_cobalt_bind + 128] = __xn_exec_lostage, /*ia32 emulation support*/
......
};
六、实时系统调用权限控制cobalt_sysmodes
上面说到,ipipe管理应用的系统调用时需要分清该系统调用是否合法,是否需要域切换等等。cobalt_sysmodes[]就是每个系统调用对应的模式,控制着每个系统调用的调用路径。系统调用号为下标,值为具体模式。每个系统调用的sysmode如何生成见上一节,还是以实时应用的bind系统调用为例:
static const int cobalt_sysmodes[] = {
[sc_cobalt_bind] = __xn_exec_bind,
[sc_cobalt_bind + 256] = __xn_exec_lostage, /*x32 support */
[sc_cobalt_bind + 128] = __xn_exec_lostage, /*ia32 emulation support*/
......
};
xenomai中所有的系统调用模式定义如下:
/*xenomai\posix\syscall.c*/
#define __xn_exec_lostage 0x1 /*必须在linux域运行该系统调用*/
#define __xn_exec_histage 0x2 /*必须在Xenomai域运行该系统调用*/
#define __xn_exec_shadow 0x4 /*影子系统调用:必须映射调用方*/
#define __xn_exec_switchback 0x8 /*切换回切换; 调用者必须返回其原始模式*/
#define __xn_exec_current 0x10 /*在不管域直接执行。*/
#define __xn_exec_conforming 0x20 /*在兼容域(Xenomai或Linux)中执行*/
#define __xn_exec_adaptive 0x40 /* 先直接执行如果返回-ENOSYS,则尝试在相反的域中重新执行系统调用 */
#define __xn_exec_norestart 0x80 /*收到信号后不要重新启动syscall*/
/*Shorthand初始化系统调用的简写*/
#define __xn_exec_init __xn_exec_lostage
/*Xenomai空间中shadow系统调用的简写*/
#define __xn_exec_primary (__xn_exec_shadow|__xn_exec_histage)
/*Linux空间中shadow系统调用的简写*/
#define __xn_exec_secondary (__xn_exec_shadow|__xn_exec_lostage)
/*Linux空间中syscall的简写,如果有shadow则切换回linux*/
#define __xn_exec_downup (__xn_exec_lostage|__xn_exec_switchback)
/* 主域系统不可重启调用的简写 */
#define __xn_exec_nonrestartable (__xn_exec_primary|__xn_exec_norestart)
/*域探测系统调用简写*/
#define __xn_exec_probing (__xn_exec_conforming|__xn_exec_adaptive)
/*将模式选择移交给syscall。*/
#define __xn_exec_handover (__xn_exec_current|__xn_exec_adaptive)
使用一个无符号32 位数的每一位来表示一种模式,各模式注释已经很清楚,不在解释,后面文章解析ipipe是如何根据mode来处理的。
参考
英特尔® 64 位和 IA-32 架构软件开发人员手册第 3 卷 :系统编程指南
极客时间专栏-趣谈Linux操作系统
《linux内核源代码情景分析》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号