spring boot 2(书籍摘录和部分纯洁的微笑博客)
一,Spring Boot 中的响应式编程和 WebFlux 入门
Spring 5.0 中发布了重量级组件 Webflux,拉起了响应式编程的规模使用序幕。
WebFlux 使用的场景是异步非阻塞的,使用 Webflux 作为系统解决方案,在大多数场景下可以提高系统吞吐量。Spring Boot 2.0 是基于 Spring5 构建而成,因此 Spring Boot 2.X 将自动继承了 Webflux 组件,本篇给大家介绍如何在 Spring Boot 中使用 Webflux 。
为了方便大家理解,我们先来了解几个概念。
在计算机中,响应式编程或反应式编程(英语:Reactive programming)是一种面向数据流和变化传播的编程范式。这意味着可以在编程语言中很方便地表达静态或动态的数据流,而相关的计算模型会自动将变化的值通过数据流进行传播。
例如,在命令式编程环境中,a=b+c 表示将表达式的结果赋给 a,而之后改变 b 或 c 的值不会影响 a 。但在响应式编程中,a 的值会随着 b 或 c 的更新而更新。
响应式编程是基于异步和事件驱动的非阻塞程序,只需要在程序内启动少量线程扩展,而不是水平通过集群扩展。
用大白话讲,我们以前编写的大部分都是阻塞类的程序,当一个请求过来时任务会被阻塞,直到这个任务完成后再返回给前端;响应式编程接到请求后只是提交了一个请求给后端,后端会再安排另外的线程去执行任务,当任务执行完成后再异步通知到前端。
Reactor
Java 领域的响应式编程库中,最有名的算是 Reactor 了。Reactor 也是 Spring 5 中反应式编程的基础,Webflux 依赖 Reactor 而构建。
Reactor 是一个基于 JVM 之上的异步应用基础库。为 Java 、Groovy 和其他 JVM 语言提供了构建基于事件和数据驱动应用的抽象库。Reactor 性能相当高,在最新的硬件平台上,使用无堵塞分发器每秒钟可处理 1500 万事件。
简单说,Reactor 是一个轻量级 JVM 基础库,帮助你的服务或应用高效,异步地传递消息。Reactor 中有两个非常重要的概念 Flux 和 Mono 。
Flux 和 Mono
Flux 和 Mono 是 Reactor 中的两个基本概念。Flux 表示的是包含 0 到 N 个元素的异步序列。在该序列中可以包含三种不同类型的消息通知:正常的包含元素的消息、序列结束的消息和序列出错的消息。当消息通知产生时,订阅者中对应的方法 onNext(), onComplete()和 onError()会被调用。
Mono 表示的是包含 0 或者 1 个元素的异步序列。该序列中同样可以包含与 Flux 相同的三种类型的消息通知。Flux 和 Mono 之间可以进行转换。对一个 Flux 序列进行计数操作,得到的结果是一个 Mono对象。把两个 Mono 序列合并在一起,得到的是一个 Flux 对象。
WebFlux 是什么?
WebFlux 模块的名称是 spring-webflux,名称中的 Flux 来源于 Reactor 中的类 Flux。Spring webflux 有一个全新的非堵塞的函数式 Reactive Web 框架,可以用来构建异步的、非堵塞的、事件驱动的服务,在伸缩性方面表现非常好。
非阻塞的关键预期好处是能够以小的固定数量的线程和较少的内存进行扩展。在服务器端 WebFlux 支持2种不同的编程模型:
-
基于注解的 @Controller 和其他注解也支持 Spring MVC
-
Functional 、Java 8 lambda 风格的路由和处理
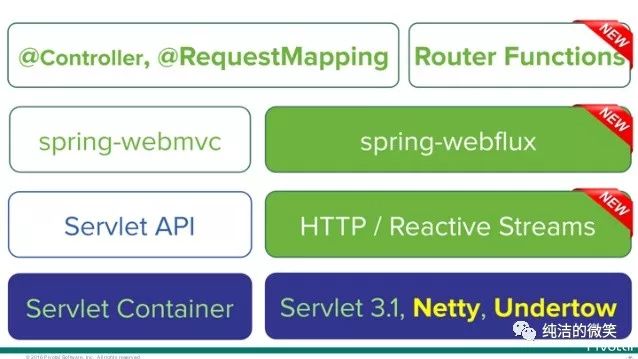
如图所示,WebFlux 模块从上到下依次是 Router Functions、WebFlux、Reactive Streams 三个新组件。
-
Router Functions 对标准的 @Controller,@RequestMapping 等的 Spring MVC 注解,提供一套 函数式风格的 API,用于创建 Router、Handler 和Filter。
-
WebFlux 核心组件,协调上下游各个组件提供 响应式编程 支持。
-
Reactive Streams 一种支持 背压 (Backpressure) 的 异步数据流处理标准,主流实现有 RxJava 和 Reactor,Spring WebFlux 集成的是 Reactor。
默认情况下,Spring Boot 2 使用 Netty WebFlux,因为 Netty 在异步非阻塞空间中被广泛使用,异步非阻塞连接可以节省更多的资源,提供更高的响应度。通过比较 Servlet 3.1 非阻塞 I / O 没有太多的使用,因为使用它的成本比较高,Spring WebFlux 打开了一条实用的通路。
值得注意的是:支持 reactive 编程的数据库只有 MongoDB, redis, Cassandra, Couchbase
Spring Webflux
Spring Boot 2.0 包括一个新的 spring-webflux 模块。该模块包含对响应式 HTTP 和 WebSocket 客户端的支持,以及对 REST,HTML 和 WebSocket 交互等程序的支持。一般来说,Spring MVC 用于同步处理,Spring Webflux 用于异步处理。
Spring Boot Webflux 有两种编程模型实现,一种类似 Spring MVC 注解方式,另一种是基于 Reactor 的响应式方式。
快速上手
添加 webflux 依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>

通过 IEDA 的依赖关系图我们可以发现spring-boot-starter-webflux依赖于spring-webflux、Reactor 和 Netty 相关依赖包。
创建 Controller
@RestController
public class HelloController {
@GetMapping("/hello")
public Mono<String> hello() {
return Mono.just("Welcome to reactive world ~");
}
}
通过上面的示例可以发现,开发模式和之前 Spring Mvc 的模式差别不是很大,只是在方法的返回值上有所区别。
-
just()方法可以指定序列中包含的全部元素。 -
响应式编程的返回值必须是 Flux 或者 Mono ,两者之间可以相互转换。
测试类
@RunWith(SpringRunner.class)
@WebFluxTest(controllers = HelloController.class)
public class HelloTests {
@Autowired
WebTestClient client;
@Test
public void getHello() {
client.get().uri("/hello").exchange().expectStatus().isOk();
}
}
运行测试类,测试用例通过表示服务正常。启动项目后,访问地址:http://localhost:8080/hello,页面返回信息:
Welcome to reactive world ~
证明 Webflux 集成成功。
以上便是 Spring Boot 集成 Webflux 最简单的 Demo ,后续我们继续研究 Webflux 的使用。
二,MyBatis-Plus
MyBatis-Plus(简称 MP)是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
官方愿景:成为 MyBatis 最好的搭档,就像 魂斗罗 中的 1P、2P,基友搭配,效率翻倍。
根据愿景甚至还设置了一个很酷的 Logo。
官网地址:https://mybatis.plus/,本文大部分内容参考自官网。
特性
官网说的特性太多了,挑了几个有特点的分享给大家。
-
无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
-
损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
-
强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
-
支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
-
支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer2005、SQLServer 等多种数据库
-
内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
快速上手
准备数据
我们首先设计一个这样的用户表,如下:
| ID | NAME | AGE | |
|---|---|---|---|
| 1 | neo | 18 | smile1@baomidou.com |
| 2 | keep | 36 | smile2@baomidou.com |
| 3 | pure | 28 | smile3@baomidou.com |
| 4 | smile | 21 | smile4@baomidou.com |
| 5 | it | 24 | smile5@baomidou.com |
我们要创建两个 Sql 文件,以便项目启动的时候,将表结构和数据初始化到数据库。
表结构文件(schema-h2.sql)内容:
DROP TABLE IF EXISTS user;
CREATE TABLE user
(
id BIGINT(20) NOT NULL COMMENT '主键ID',
name VARCHAR(30) NULL DEFAULT NULL COMMENT '姓名',
age INT(11) NULL DEFAULT NULL COMMENT '年龄',
email VARCHAR(50) NULL DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY (id)
);
表数据文件(data-h2.sql)内容:
INSERT INTO user (id, name, age, email) VALUES
(1, 'neo', 18, 'smile1@ityouknow.com'),
(2, 'keep', 36, 'smile2@ityouknow.com'),
(3, 'pure', 28, 'smile3@ityouknow.com'),
(4, 'smile', 21, 'smile4@ityouknow.com'),
(5, 'it', 24, 'smile5@ityouknow.com');
在示例项目的 resources 目录下创建 db 文件夹,将两个文件放入其中。
添加依赖
添加相关依赖包,pom.xml 中的相关依赖内容如下:
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.1.1</version>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
-
lombok,帮忙省略掉 Get/Set 方法,
-
mybatis-plus-boot-starter,MyBatis Plus 的依赖包
-
h2,本次测试我们使用内存数据库 h2 来演示。
-
spring-boot-starter-test,Spring Boot 的测试包
配置文件
# DataSource Config
spring:
datasource:
driver-class-name: org.h2.Driver
schema: classpath:db/schema-h2.sql
data: classpath:db/data-h2.sql
url: jdbc:h2:mem:test
username: root
password: test
# Logger Config
logging:
level:
com.neo: debug
配置了 h2 数据库,已经项目的日志级别。配置 schema 和 data 后,项目启动时会根据配置的文件地址来执行数据。
业务代码
创建 MybatisPlusConfig 类,指定 Mapper 地址,启用分页功能。
@Configuration
@MapperScan("com.neo.mapper")
public class MybatisPlusConfig {
/**
* 分页插件
*/
@Bean
public PaginationInterceptor paginationInterceptor() {
return new PaginationInterceptor();
}
}
创建实体类 User
@Data
public class User {
private Long id;
private String name;
private Integer age;
private String email;
}
@Data 为 lombok 语法,自动注入 getter/setter 方法。
接下来创建对象对于的 Mapper。
public interface UserMapper extends BaseMapper<User> {
}
以上业务代码就开发完成了,是不是很简单。
测试
创建 MyBatisPlusTest 类,注入上面创建的 UserMapper 类。
@RunWith(SpringRunner.class)
@SpringBootTest
public class MyBatisPlusTest {
@Autowired
private UserMapper userMapper;
}
测试查询单挑数据,并输出
@Test
public void testSelectOne() {
User user = userMapper.selectById(1L);
System.out.println(user);
}
测试添加数据
@Test
public void testInsert() {
User user = new User();
user.setName("微笑");
user.setAge(3);
user.setEmail("neo@tooool.org");
assertThat(userMapper.insert(user)).isGreaterThan(0);
// 成功直接拿会写的 ID
assertThat(user.getId()).isNotNull();
}
assertThat() 是 Assert 的一个精通方法,用来比对返回结果,包来自import static org.assertj.core.api.Assertions.assertThat;。
测试删除数据
@Test
public void testDelete() {
assertThat(userMapper.deleteById(3L)).isGreaterThan(0);
assertThat(userMapper.delete(new QueryWrapper<User>()
.lambda().eq(User::getName, "smile"))).isGreaterThan(0);
}
QueryWrapper 是 MyBatis-Plus 内部辅助查询类,可以使用 lambda 语法,也可以不使用。利用 QueryWrapper 类可以构建各种查询条件。
测试更新数据
@Test
public void testUpdate() {
User user = userMapper.selectById(2);
assertThat(user.getAge()).isEqualTo(36);
assertThat(user.getName()).isEqualTo("keep");
userMapper.update(
null,
Wrappers.<User>lambdaUpdate().set(User::getEmail, "123@123").eq(User::getId, 2)
);
assertThat(userMapper.selectById(2).getEmail()).isEqualTo("123@123");
}
测试查询所有数据
@Test
public void testSelect() {
List<User> userList = userMapper.selectList(null);
Assert.assertEquals(5, userList.size());
userList.forEach(System.out::println);
}
测试非分页查询
@Test
public void testPage() {
System.out.println("----- baseMapper 自带分页 ------");
Page<User> page = new Page<>(1, 2);
IPage<User> userIPage = userMapper.selectPage(page, new QueryWrapper<User>()
.gt("age", 6));
assertThat(page).isSameAs(userIPage);
System.out.println("总条数 ------> " + userIPage.getTotal());
System.out.println("当前页数 ------> " + userIPage.getCurrent());
System.out.println("当前每页显示数 ------> " + userIPage.getSize());
print(userIPage.getRecords());
System.out.println("----- baseMapper 自带分页 ------");
}
查询大于 6 岁的用户,并且分页展示,每页两条数据,展示第一页。
总结
简单使用了一下 MyBatis-Plus 感觉是一款挺不错的 MyBatis 插件,使用 MyBatis-Plus 操作数据库确实可以少写一些代码,另外 MyBatis-Plus 的功能比较丰富,文中仅展示了常用的增删改查和分页查询,
三,异步.定时.邮件任务
异步任务,
1、创建一个service包
2、创建一个类AsyncService
异步处理还是非常常用的,比如我们在网站上发送邮件,后台会去发送邮件,此时前台会造成响应不动,直到邮件发送完毕,响应才会成功,所以我们一般会采用多线程的方式去处理这些任务。
编写方法,假装正在处理数据,使用线程设置一些延时,模拟同步等待的情况;
@Service
public class AsyncService {
public void hello(){
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("业务进行中....");
}
}
3、编写controller包
4、编写AsyncController类
我们去写一个Controller测试一下
@RestController
public class AsyncController {
@Autowired
AsyncService asyncService;
@GetMapping("/hello")
public String hello(){
asyncService.hello();
return "success";
}
}
5、访问http://localhost:8080/hello进行测试,3秒后出现success,这是同步等待的情况。
问题:我们如果想让用户直接得到消息,就在后台使用多线程的方式进行处理即可,但是每次都需要自己手动去编写多线程的实现的话,太麻烦了,我们只需要用一个简单的办法,在我们的方法上加一个简单的注解即可,如下:
6、给hello方法添加@Async注解;
//告诉Spring这是一个异步方法
@Async
public void hello(){
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("业务进行中....");
}
SpringBoot就会自己开一个线程池,进行调用!但是要让这个注解生效,我们还需要在主程序上添加一个注解@EnableAsync ,开启异步注解功能;
@EnableAsync //开启异步注解功能
@SpringBootApplication
public class SpringbootTaskApplication {
public static void main(String[] args) {
SpringApplication.run(SpringbootTaskApplication.class, args);
}
}
7、重启测试,网页瞬间响应,后台代码依旧执行!
定时任务
项目开发中经常需要执行一些定时任务,比如需要在每天凌晨的时候,分析一次前一天的日志信息,Spring为我们提供了异步执行任务调度的方式,提供了两个接口。
-
TaskExecutor接口
-
TaskScheduler接口
两个注解:
-
@EnableScheduling
-
@Scheduled
cron表达式:
测试步骤:
1、创建一个ScheduledService
我们里面存在一个hello方法,他需要定时执行,怎么处理呢?
@Service
public class ScheduledService {
//秒 分 时 日 月 周几
//0 * * * * MON-FRI
//注意cron表达式的用法;
@Scheduled(cron = "0 * * * * 0-7")
public void hello(){
System.out.println("hello.....");
}
}
2、这里写完定时任务之后,我们需要在主程序上增加@EnableScheduling 开启定时任务功能
@EnableAsync //开启异步注解功能
@EnableScheduling //开启基于注解的定时任务
@SpringBootApplication
public class SpringbootTaskApplication {
public static void main(String[] args) {
SpringApplication.run(SpringbootTaskApplication.class, args);
}
}
3、我们来详细了解下cron表达式;
http://www.bejson.com/othertools/cron/
4、常用的表达式
(1)0/2 * * * * ? 表示每2秒 执行任务
(1)0 0/2 * * * ? 表示每2分钟 执行任务
(1)0 0 2 1 * ? 表示在每月的1日的凌晨2点调整任务
(2)0 15 10 ? * MON-FRI 表示周一到周五每天上午10:15执行作业
(3)0 15 10 ? 6L 2002-2006 表示2002-2006年的每个月的最后一个星期五上午10:15执行作
(4)0 0 10,14,16 * * ? 每天上午10点,下午2点,4点
(5)0 0/30 9-17 * * ? 朝九晚五工作时间内每半小时
(6)0 0 12 ? * WED 表示每个星期三中午12点
(7)0 0 12 * * ? 每天中午12点触发
(8)0 15 10 ? * * 每天上午10:15触发
(9)0 15 10 * * ? 每天上午10:15触发
(10)0 15 10 * * ? 每天上午10:15触发
(11)0 15 10 * * ? 2005 2005年的每天上午10:15触发
(12)0 * 14 * * ? 在每天下午2点到下午2:59期间的每1分钟触发
(13)0 0/5 14 * * ? 在每天下午2点到下午2:55期间的每5分钟触发
(14)0 0/5 14,18 * * ? 在每天下午2点到2:55期间和下午6点到6:55期间的每5分钟触发
(15)0 0-5 14 * * ? 在每天下午2点到下午2:05期间的每1分钟触发
(16)0 10,44 14 ? 3 WED 每年三月的星期三的下午2:10和2:44触发
(17)0 15 10 ? * MON-FRI 周一至周五的上午10:15触发
(18)0 15 10 15 * ? 每月15日上午10:15触发
(19)0 15 10 L * ? 每月最后一日的上午10:15触发
(20)0 15 10 ? * 6L 每月的最后一个星期五上午10:15触发
(21)0 15 10 ? * 6L 2002-2005 2002年至2005年的每月的最后一个星期五上午10:15触发
(22)0 15 10 ? * 6#3 每月的第三个星期五上午10:15触发
邮件任务
邮件发送,在我们的日常开发中,也非常的多,Springboot也帮我们做了支持
-
邮件发送需要引入spring-boot-start-mail
-
SpringBoot 自动配置MailSenderAutoConfiguration
-
定义MailProperties内容,配置在application.yml中
-
自动装配JavaMailSender
-
测试邮件发送
测试:
1、引入pom依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-mail</artifactId>
</dependency>
看它引入的依赖,可以看到 jakarta.mail
<dependency>
<groupId>com.sun.mail</groupId>
<artifactId>jakarta.mail</artifactId>
<version>1.6.4</version>
<scope>compile</scope>
</dependency>
2、查看自动配置类:MailSenderAutoConfiguration
这个类中存在bean,JavaMailSenderImpl
然后我们去看下配置文件
@ConfigurationProperties(
prefix = "spring.mail"
)
public class MailProperties {
private static final Charset DEFAULT_CHARSET;
private String host;
private Integer port;
private String username;
private String password;
private String protocol = "smtp";
private Charset defaultEncoding;
private Map<String, String> properties;
private String jndiName;
}
3、配置文件:
spring.mail.username=24736743@qq.com
spring.mail.password=你的qq授权码
spring.mail.host=smtp.qq.com
# qq需要配置ssl
spring.mail.properties.mail.smtp.ssl.enable=true
获取授权码:在QQ邮箱中的设置->账户->开启pop3和smtp服务
4、Spring单元测试
@Autowired
JavaMailSenderImpl mailSender;
@Test
public void contextLoads() {
//邮件设置1:一个简单的邮件
SimpleMailMessage message = new SimpleMailMessage();
message.setSubject("通知-明天来狂神这听课");
message.setText("今晚7:30开会");
message.setTo("24736743@qq.com");
message.setFrom("24736743@qq.com");
mailSender.send(message);
}
@Test
public void contextLoads2() throws MessagingException {
//邮件设置2:一个复杂的邮件
MimeMessage mimeMessage = mailSender.createMimeMessage();
MimeMessageHelper helper = new MimeMessageHelper(mimeMessage, true);
helper.setSubject("通知-明天来狂神这听课");
helper.setText("<b style='color:red'>今天 7:30来开会</b>",true);
//发送附件
helper.addAttachment("1.jpg",new File(""));
helper.addAttachment("2.jpg",new File(""));
helper.setTo("24736743@qq.com");
helper.setFrom("24736743@qq.com");
mailSender.send(mimeMessage);
}
查看邮箱,邮件接收成功!
我们只需要使用Thymeleaf进行前后端结合即可开发自己网站邮件收发功能了
四,Dubbo和Zookeeper集成
*Dubbo文档*
随着互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,急需一个治理系统确保架构有条不紊的演进。
在Dubbo的官网文档有这样一张图
**单一应用架构****
当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。此时,用于简化增删改查工作量的数据访问框架(ORM)是关键。
适用于小型网站,小型管理系统,将所有功能都部署到一个功能里,简单易用。
缺点:
1、性能扩展比较难
2、协同开发问题
3、不利于升级维护
****垂直应用架构******
当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率。此时,用于加速前端页面开发的Web框架(MVC)是关键。
通过切分业务来实现各个模块独立部署,降低了维护和部署的难度,团队各司其职更易管理,性能扩展也更方便,更有针对性。
缺点:公用模块无法重复利用,开发性的浪费
******分布式服务架构********
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。此时,用于提高业务复用及整合的分布式服务框架(RPC)是关键。
********流动计算架构**********
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的资源调度和治理中心(SOA)[ Service Oriented Architecture]是关键。
什么是RPC
RPC【Remote Procedure Call】是指远程过程调用,是一种进程间通信方式,他是一种技术的思想,而不是规范。它允许程序调用另一个地址空间(通常是共享网络的另一台机器上)的过程或函数,而不用程序员显式编码这个远程调用的细节。即程序员无论是调用本地的还是远程的函数,本质上编写的调用代码基本相同。
也就是说两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的函数/方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。为什么要用RPC呢?就是无法在一个进程内,甚至一个计算机内通过本地调用的方式完成的需求,比如不同的系统间的通讯,甚至不同的组织间的通讯,由于计算能力需要横向扩展,需要在多台机器组成的集群上部署应用。RPC就是要像调用本地的函数一样去调远程函数;
推荐阅读文章:https://www.jianshu.com/p/2accc2840a1b
RPC基本原理
步骤解析:
RPC两个核心模块:通讯,序列化。
测试环境搭建
********Dubbo**********
Apache Dubbo |ˈdʌbəʊ| 是一款高性能、轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。
dubbo官网 http://dubbo.apache.org/zh-cn/index.html
1.了解Dubbo的特性
2.查看官方文档
dubbo基本概念
** 服务提供者**(Provider):暴露服务的服务提供方,服务提供者在启动时,向注册中心注册自己提供的服务。
** 服务消费者**(Consumer):调用远程服务的服务消费方,服务消费者在启动时,向注册中心订阅自己所需的服务,服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
** 注册中心**(Registry):注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者
** 监控中心**(Monitor):服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心
调用关系说明
l 服务容器负责启动,加载,运行服务提供者。
l 服务提供者在启动时,向注册中心注册自己提供的服务。
l 服务消费者在启动时,向注册中心订阅自己所需的服务。
l 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
l 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
l 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
********Dubbo环境搭建**********
点进dubbo官方文档,推荐我们使用Zookeeper 注册中心
什么是zookeeper呢?可以查看官方文档
********Window下安装zookeeper**********
1、下载zookeeper :地址 我们下载3.4.14 , 最新版!解压zookeeper
2、运行/bin/zkServer.cmd ,初次运行会报错,没有zoo.cfg配置文件;
可能遇到问题:闪退 !
解决方案:编辑zkServer.cmd文件末尾添加pause 。这样运行出错就不会退出,会提示错误信息,方便找到原因。
3、修改zoo.cfg配置文件
将conf文件夹下面的zoo_sample.cfg复制一份改名为zoo.cfg即可。
注意几个重要位置:
dataDir=./ 临时数据存储的目录(可写相对路径)
clientPort=2181 zookeeper的端口号
修改完成后再次启动zookeeper
4、使用zkCli.cmd测试
ls /:列出zookeeper根下保存的所有节点
[zk: 127.0.0.1:2181(CONNECTED) 4] ls /
[zookeeper]
create –e /kuangshen 123:创建一个kuangshen节点,值为123
get /kuangshen:获取/kuangshen节点的值
我们再来查看一下节点
********window下安装dubbo-admin**********
dubbo本身并不是一个服务软件。它其实就是一个jar包,能够帮你的java程序连接到zookeeper,并利用zookeeper消费、提供服务。
但是为了让用户更好的管理监控众多的dubbo服务,官方提供了一个可视化的监控程序dubbo-admin,不过这个监控即使不装也不影响使用。
我们这里来安装一下:
1、下载dubbo-admin
地址 :https://github.com/apache/dubbo-admin/tree/master
2、解压进入目录
修改 dubbo-admin\src\main\resources \application.properties 指定zookeeper地址
server.port=7001
spring.velocity.cache=false
spring.velocity.charset=UTF-8
spring.velocity.layout-url=/templates/default.vm
spring.messages.fallback-to-system-locale=false
spring.messages.basename=i18n/message
spring.root.password=root
spring.guest.password=guest
dubbo.registry.address=zookeeper://127.0.0.1:2181
3、在项目目录下打包dubbo-admin
mvn clean package -Dmaven.test.skip=true
报错时也可以使用这个:
mvn package -Dmaven.test.skip=true
第一次打包的过程有点慢,需要耐心等待!直到成功!
4、执行 dubbo-admin\target 下的dubbo-admin-0.0.1-SNAPSHOT.jar
java -jar dubbo-admin-0.0.1-SNAPSHOT.jar
【注意:zookeeper的服务一定要打开!】
执行完毕,我们去访问一下 http://localhost:7001/ , 这时候我们需要输入登录账户和密码,我们都是默认的root-root;
登录成功后,查看界面
安装完成!
SpringBoot + Dubbo + zookeeper
********框架搭建**********
1. 启动zookeeper !
2. IDEA创建一个空项目;
3.创建一个模块,实现服务提供者:provider-server , 选择web依赖即可
4.项目创建完毕,我们写一个服务,比如卖票的服务;
编写接口
package com.kuang.provider.service;
public interface TicketService {
public String getTicket();
}
编写实现类
package com.kuang.provider.service;
public class TicketServiceImpl implements TicketService {
@Override
public String getTicket() {
return "《狂神说Java》";
}
}
5.创建一个模块,实现服务消费者:consumer-server , 选择web依赖即可
6.项目创建完毕,我们写一个服务,比如用户的服务;
编写service
package com.kuang.consumer.service;
public class UserService {
//我们需要去拿去注册中心的服务
}
需求:现在我们的用户想使用买票的服务,这要怎么弄呢 ?
********服务提供者**********
1、将服务提供者注册到注册中心,我们需要整合Dubbo和zookeeper,所以需要导包
我们从dubbo官网进入github,看下方的帮助文档,找到dubbo-springboot,找到依赖包
<!-- Dubbo Spring Boot Starter -->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-spring-boot-starter</artifactId>
<version>2.7.3</version>
</dependency>
zookeeper的包我们去maven仓库下载,zkclient;
<!-- https://mvnrepository.com/artifact/com.github.sgroschupf/zkclient -->
<dependency>
<groupId>com.github.sgroschupf</groupId>
<artifactId>zkclient</artifactId>
<version>0.1</version>
</dependency>
【新版的坑】zookeeper及其依赖包,解决日志冲突,还需要剔除日志依赖;
<!-- 引入zookeeper -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.14</version>
<!--排除这个slf4j-log4j12-->
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
2、在springboot配置文件中配置dubbo相关属性!
#当前应用名字
dubbo.application.name=provider-server
#注册中心地址
dubbo.registry.address=zookeeper://127.0.0.1:2181
#扫描指定包下服务
dubbo.scan.base-packages=com.kuang.provider.service
3、在service的实现类中配置服务注解,发布服务!注意导包问题
import org.apache.dubbo.config.annotation.Service;
import org.springframework.stereotype.Component;
@Service //将服务发布出去
@Component //放在容器中
public class TicketServiceImpl implements TicketService {
@Override
public String getTicket() {
return "《狂神说Java》";
}
}
逻辑理解 :应用启动起来,dubbo就会扫描指定的包下带有@component注解的服务,将它发布在指定的注册中心中!
********服务消费者**********
1、导入依赖,和之前的依赖一样;
<!--dubbo-->
<!-- Dubbo Spring Boot Starter -->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-spring-boot-starter</artifactId>
<version>2.7.3</version>
</dependency>
<!--zookeeper-->
<!-- https://mvnrepository.com/artifact/com.github.sgroschupf/zkclient -->
<dependency>
<groupId>com.github.sgroschupf</groupId>
<artifactId>zkclient</artifactId>
<version>0.1</version>
</dependency>
<!-- 引入zookeeper -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.14</version>
<!--排除这个slf4j-log4j12-->
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
2、配置参数
#当前应用名字
dubbo.application.name=consumer-server
#注册中心地址
dubbo.registry.address=zookeeper://127.0.0.1:2181
3. 本来正常步骤是需要将服务提供者的接口打包,然后用pom文件导入,我们这里使用简单的方式,直接将服务的接口拿过来,路径必须保证正确,即和服务提供者相同;
4. 完善消费者的服务类
package com.kuang.consumer.service;
import com.kuang.provider.service.TicketService;
import org.apache.dubbo.config.annotation.Reference;
import org.springframework.stereotype.Service;
@Service //注入到容器中
public class UserService {
@Reference //远程引用指定的服务,他会按照全类名进行匹配,看谁给注册中心注册了这个全类名
TicketService ticketService;
public void bugTicket(){
String ticket = ticketService.getTicket();
System.out.println("在注册中心买到"+ticket);
}
}
5. 测试类编写;
@RunWith(SpringRunner.class)
@SpringBootTest
public class ConsumerServerApplicationTests {
@Autowired
UserService userService;
@Test
public void contextLoads() {
userService.bugTicket();
}
}
********启动测试**********
1. 开启zookeeper
2. 打开dubbo-admin实现监控【可以不用做】
3. 开启服务者
4. 消费者消费测试,结果:
ok , 这就是SpingBoot + dubbo + zookeeper实现分布式开发的应用,其实就是一个服务拆分的思想;
五,什么是Nginx?
Nginx (engine x) 是一个高性能的HTTP和反向代理web服务器,同时也提供了IMAP/POP3/SMTP服务。Nginx是由伊戈尔·赛索耶夫为俄罗斯访问量第二的Rambler.ru站点(俄文:Рамблер)开发的,第一个公开版本0.1.0发布于2004年10月4日。2011年6月1日,nginx 1.0.4发布。
其特点是占有内存少,并发能力强,事实上nginx的并发能力在同类型的网页服务器中表现较好,中国大陆使用nginx网站用户有:百度、京东、新浪、网易、腾讯、淘宝等。在全球活跃的网站中有12.18%的使用比率,大约为2220万个网站。Nginx 是一个安装非常的简单、配置文件非常简洁(还能够支持perl语法)、Bug非常少的服务。
Nginx 启动特别容易,并且几乎可以做到7*24不间断运行,即使运行数个月也不需要重新启动。你还能够不间断服务的情况下进行软件版本的升级。
Nginx代码完全用C语言从头写成。官方数据测试表明能够支持高达 50,000 个并发连接数的响应。
Nginx作用? Http代理,反向代理:作为web服务器最常用的功能之一,尤其是反向代理。
正向代理
反向代理
Nginx提供的负载均衡策略有2种:内置策略和扩展策略。内置策略为轮询,加权轮询,Ip hash。 扩展策略,就天马行空,只有你想不到的没有他做不到的.
轮询
加权轮询
iphash对客户端请求的ip进行hash操作,然后根据hash结果将同一个客户端ip的请求分发给同一台服务器进行处理,可以解决session不共享的问题。
动静分离,在我们的软件开发中,有些请求是需要后台处理的,有些请求是不需要经过后台处理的(如:css、html、jpg、js等等文件),这些不需要经过后台处理的文件称为静态文件。让动态网站里的动态网页根据一定规则把不变的资源和经常变的资源区分开来,动静资源做好了拆分以后,我们就可以根据静态资源的特点将其做缓存操作。提高资源响应的速度。
目前,通过使用Nginx大大提高了我们网站的响应速度,优化了用户体验,让网站的健壮性更上一层楼!
Nginx的安装
windows下安装
1、下载nginx http://nginx.org/en/download.html 下载稳定版本。 以nginx/Windows-1.16.1为例,直接下载 nginx-1.16.1.zip。
2、启动nginx有很多种方法启动nginx
直接双击nginx.exe,双击后一个黑色的弹窗一闪而过
打开cmd命令窗口,切换到nginx解压目录下,输入命令nginx.exe,回车即可
3、检查nginx是否启动成功直接在浏览器地址栏输入网址 http://localhost:80 回车,出现以下页面说明启动成功!
4、配置监听nginx的配置文件是conf目录下的nginx.conf, 默认配置的nginx监听的端口为80,如果80端口被占用可以修改为未被占用的端口即可。
当我们修改了nginx的配置文件nginx.conf 时,不需要关闭nginx后重新启动nginx,只需要执行命令 nginx -s reload 即可让改动生效
5、关闭nginx如果使用cmd命令窗口启动nginx, 关闭cmd窗口是不能结束nginx进程的,可使用两种方法关闭nginx
输入nginx命令== nginx -s stop==(快速停止nginx) 或 nginx -s quit(完整有序的停止nginx)
使用taskkill taskkill /f /t /im nginx.exe
taskkill是用来终止进程的. /f是强制终止 . /t终止指定的进程和任何由此启动的子进程。 /im示指定的进程名称
linux下安装
1、安装gcc 安装 nginx 需要先将官网下载的源码进行编译,编译依赖 gcc 环境,如果没有 gcc 环境,则需要安装: yum install gcc-c++
2、PCRE pcre-devel 安装 PCRE(Perl Compatible Regular Expressions) 是一个Perl库,包括 perl 兼容的正则表达式库。nginx 的 http 模块使用 pcre 来解析正则表达式,所以需要在 linux 上安装 pcre库,pcre-devel 是使用 pcre 开发的一个二次开发库。nginx也需要此库。命令: yum install -y pcre pcre-devel
3、zlib 安装 zlib 库提供了很多种压缩和解压缩的方式, nginx 使用 zlib 对 http 包的内容进行 gzip ,所以需要在 Centos 上安装 zlib 库。 yum install -y zlib zlib-devel
4、OpenSSL 安装OpenSSL 是一个强大的安全套接字层密码库,囊括主要的密码算法、常用的密钥和证书封装管理功能及 SSL 协议,并提供丰富的应用程序供测试或其它目的使用。 nginx 不仅支持 http 协议,还支持 https(即在ssl协议上传输http),所以需要在 Centos安装 OpenSSL 库。 yum install -y openssl openssl-devel
5、下载安装包手动下载.tar.gz安装包,地址:https://nginx.org/en/download.html
下载完毕上传到服务器上 /root
6、解压
tar -zxvf nginx-1.18.0.tar.gz cd nginx-1.18.0
7、配置使用默认配置,在nginx根目录下执行
-
./configure
-
make
-
make install
查找安装路径: whereis nginx
Nginx常用命令
cd /usr/local/nginx/sbin/
./nginx 启动
./nginx -s stop 停止
./nginx -s quit 安全退出
./nginx -s reload 重新加载配置文件
ps aux|grep nginx 查看nginx进程启动成功访问 服务器ip:80注意:
如何连接不上,检查阿里云安全组是否开放端口,或者服务器防火墙是否开放端口! 相关命令:
1. #开启
2. service firewalld start
3. #重启
4. service firewalld restart
5. #关闭
6. service firewalld stop
7. #查看防火墙规则
8. firewall-cmd --list-all
9. #查询端口是否开放
10. firewall-cmd --query-port=8080/tcp
11. #开放80端口
12. firewall-cmd --permanent --add-port=80/tcp
13. #移除端口1
14. firewall-cmd --permanent --remove-port=8080/tcp
15.
16. #重启防火墙(修改配置后要重启防火墙)
17. firewall-cmd --reload
18.
19. #参数解释
20. 1、firwall-cmd:是Linux提供的操作firewall的一个工具;
21. 2、--permanent:表示设置为持久;
22. 3、--add-port:标识添加的端口;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号