MapReduce编程之实例分析:wordCount
1.WordCount程序任务
输入:一个包含大量单词的文本文件
输出:文件中没个单词及出现的次数(频数),并按照单词顺序排序每个单词和其频数占一行,单词和频数之间有间隔
2.WordCount程序设计思路
WordCount可以使用MapReduce去做
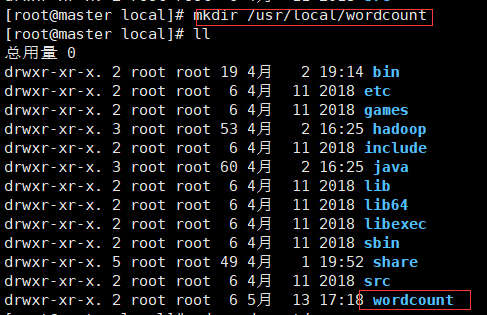
在/usr/local/目录下创建WordCount文件夹
mkdir /usr/local/wordcount
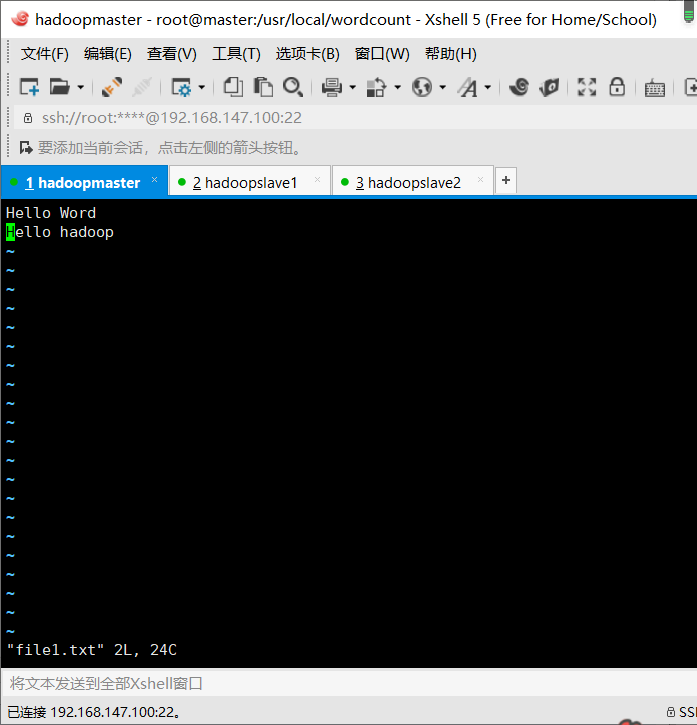
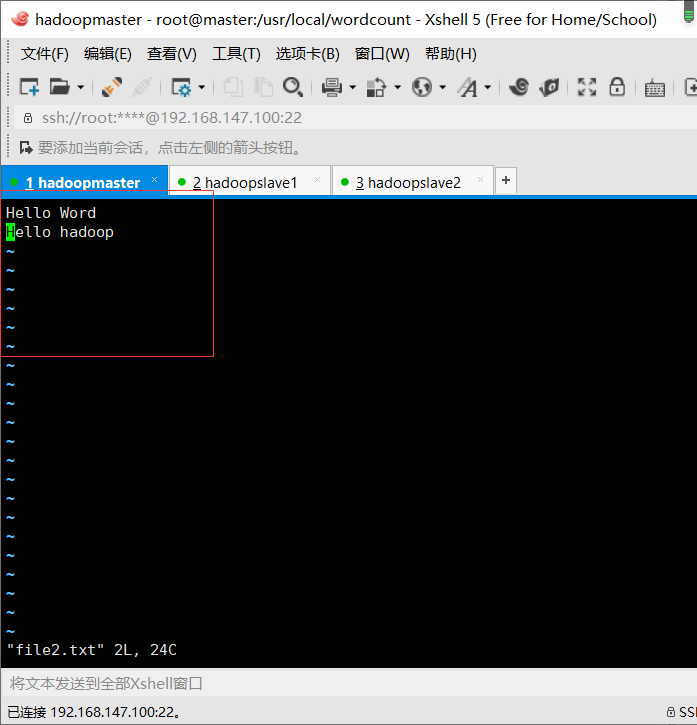
切换到指定文件夹,创建文件
vim file1.txt vim file2.txt
在Hdfs中创建一个input文件夹
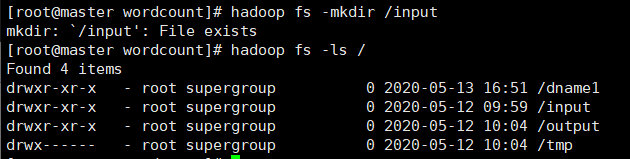
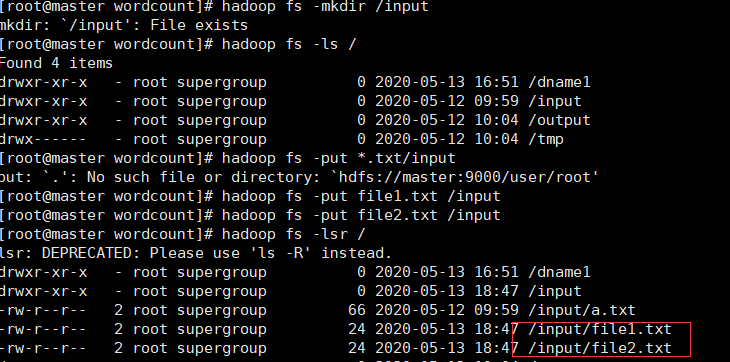
把刚才创建的两个文件上传到input里
hadoop fs -put *.txt /input
运用wordcount程序
在hadoop的jar文件中默认已帮助我们提供了wordcount程序,都位于/usr/local/hadoop/hadoop-2.8.0/share/hadoop/mapreduce下

#切换目录
cd /usr/local/hadoop/hadoop-2.8.0/share/hadoop/mapreduce
#运行jar包程序
hadoop jar hadoop-mapreduce-examples-2.8.0.jar wordcount /input/ /putout/
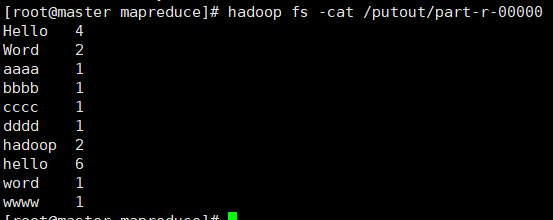
#查看运行结果
hadoop fs -cat /putout/part-r-00000