MapReduce编程之初学概念篇
1 MapReduce概述
MapReduce是一种分布式并行编程框架,由Google提出,主要用于搜索领域,解决 海量数据的计算问题。
2.MapReduce数据处理能力提升的两条路线:
2.1单核cpu到双核到四核到八核
2.2分布式并行编程
2.2.1借助一个集群通过多台机器同时并行处理大规模数据集

3.MapReduce的模型简介:
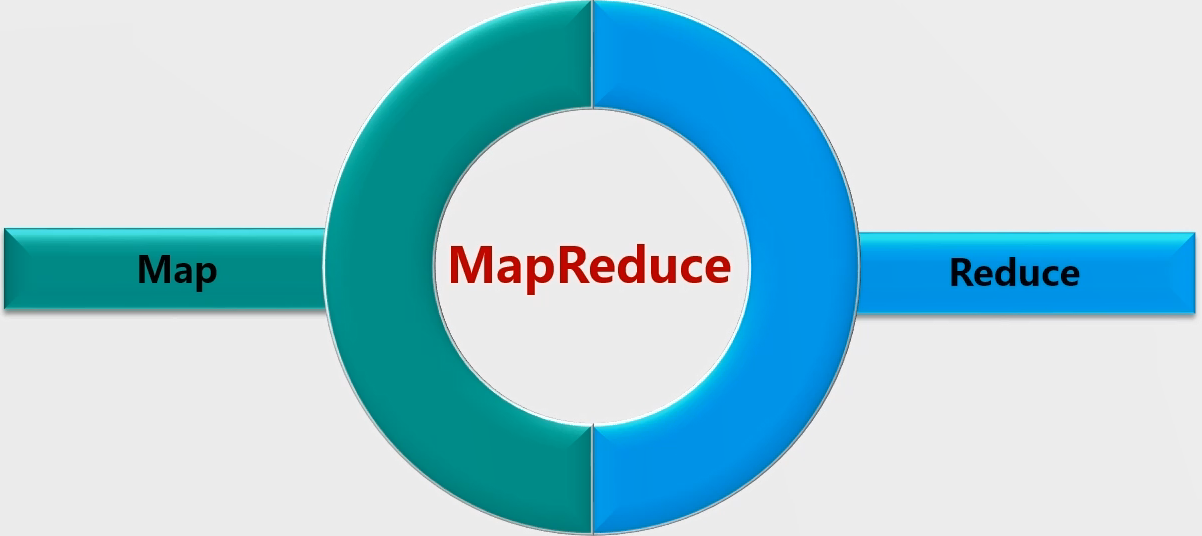
MR由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算。这两个函数的形参是key、value对,表 示函数的输入信息。下面是MR的执行流程: 
MapReduce的策略:
MapReduce采用分而治之,把非常庞大的数据集,切分成非常小的独立的小分片,然后每一个分片单独的启动一个map任务,最终通过多个map任务,并行地在多个机器上去处理
MapReduce的理念
计算向数据靠拢而不是数据向计算靠拢,
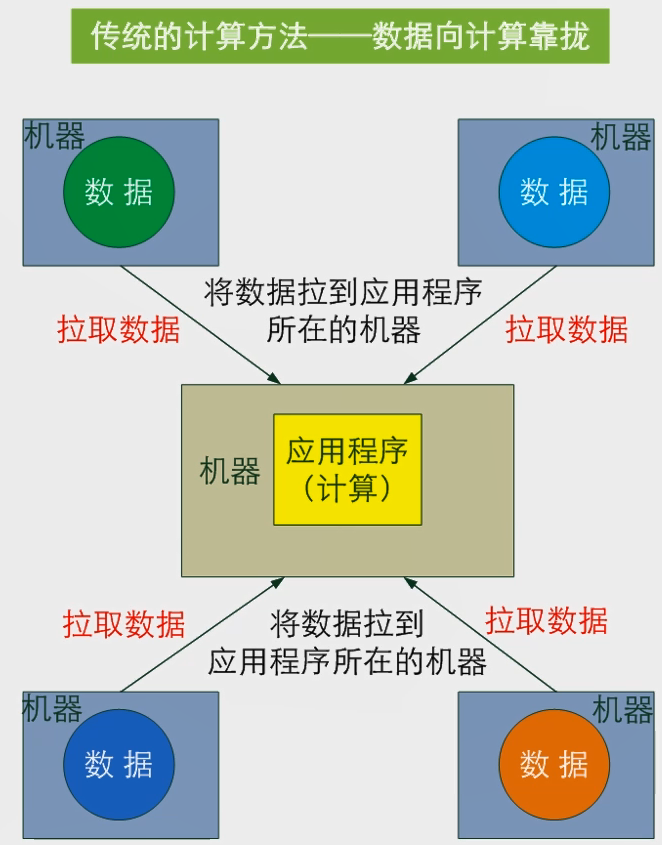
传统的计算方法--数据向计算靠拢这种计算是非常麻烦的 ,将所有的数据全部拉到一台机器上进行处理,这样是很容易崩溃的:
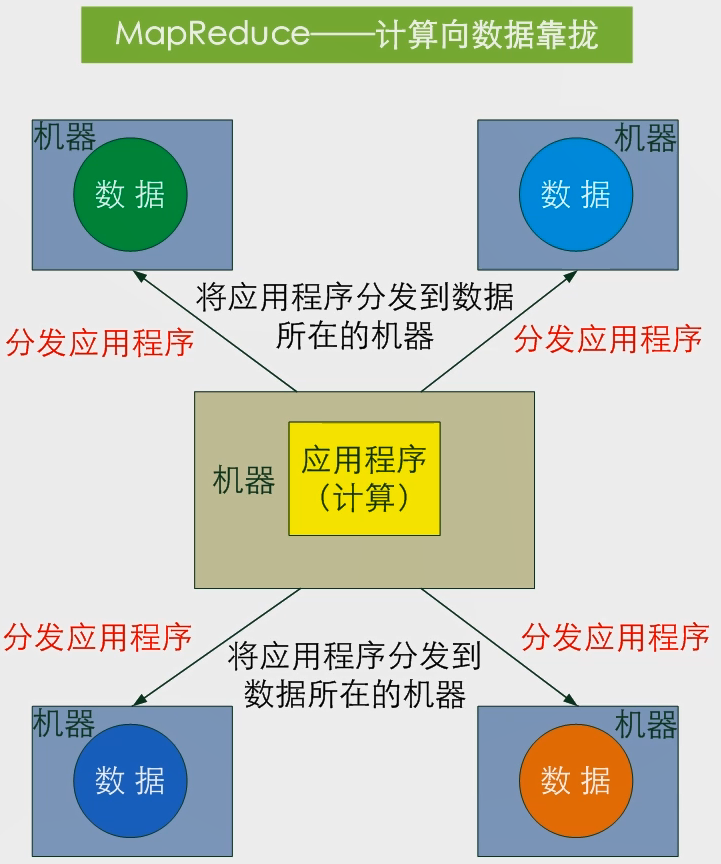
所以我们采用的另外一种策略,计算向数据靠拢
map任务处理
1.读取输入文件内容,解析成key、value对儿。对输入文件的每一行,解析成 key、value对。每一个键值对调用一次map函数。
2.写自己的逻辑,对输入的key、value处理,转换成新的key、value输出
3.对输出的key、value进行分区(hash)
4.对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集 合中.
5.(可选)分组后的数据进行归约
Reduce任务处理
1.对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce 节点。
2.对多个map任务的输出进行合并、排序。写reduce函数增加自己的逻辑,对 输入的key、value处理,转换成新的key、value输出。
3.把reduce的输出保存到文件中(TextOutputFormat)
4.MapReduce的体系结构
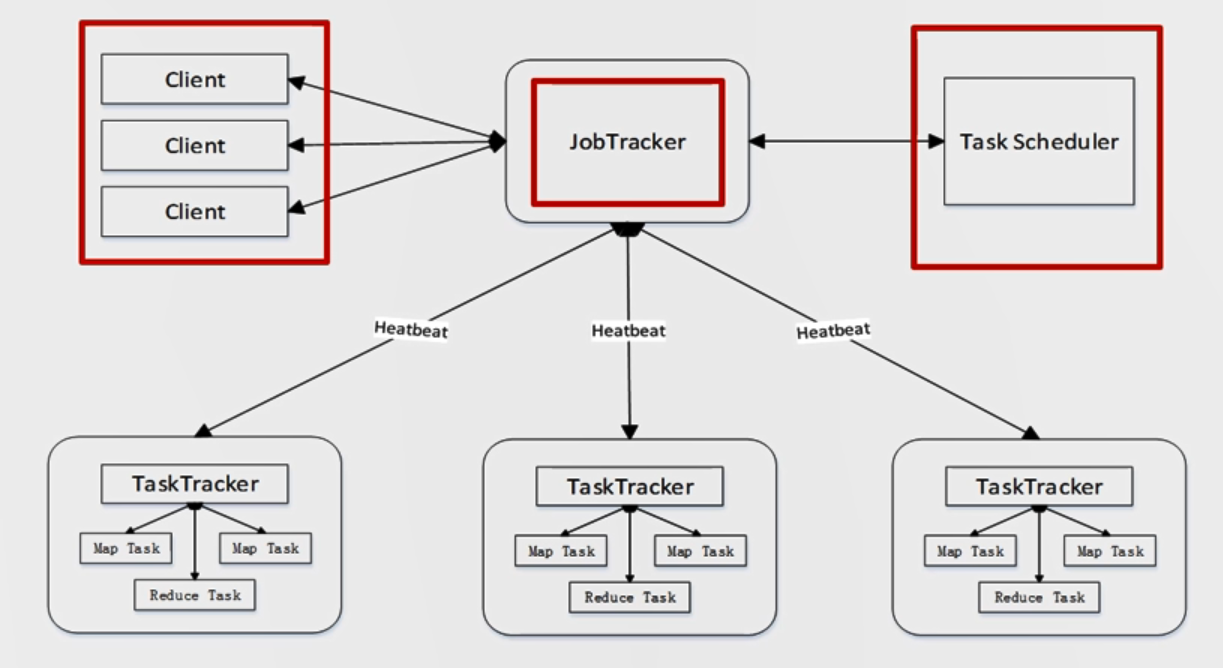
client(客户端):通过clent就可以提交用户编写的应用程序用户通过他将应用程序交到JobTracker端,同时通过这些client用户也可以通过它提供的一些接口去查看当前提交作业的运行状态
JobTracker(作业跟踪器):负责资源的监控,监控底层的其他的TaskTracker以及当前运行的Job健康状态,一旦探测到失败到情况就把这个任务转移到其他节点继续执行跟踪任务进度和资源使用量
TaskTracker(任务调度器):是负责执行具体的相关任务一般是接收JobTracker发送过来的命令,在运行当中会把一些自己的资源使用情况,以及任务的运行进度通过心跳的方式,也就是heartbeat发送给JobTacker


5.MapReduce的工作流程
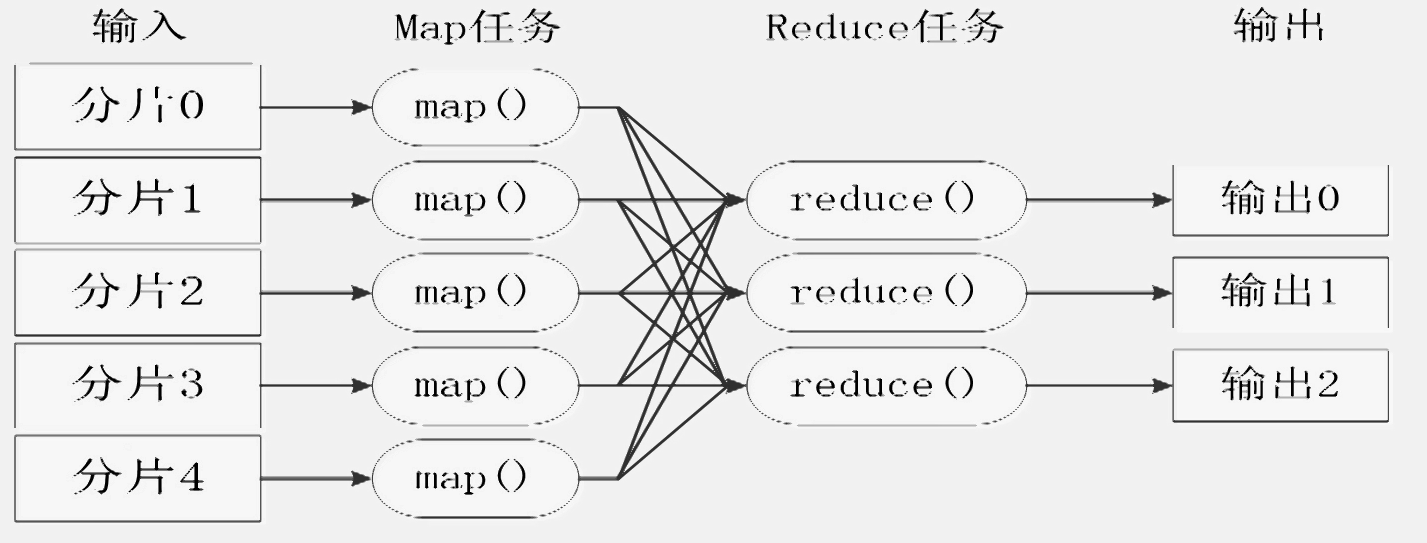
每个Mapper任务是一个java进程,它会读取HDFS中的文件,解析成很多的 键值对,经过我们覆盖的map方法处理后,转换为很多的键值对再输出。整个Mapper 任务的处理过程又可分为以下几个阶段:
1.第一阶段是把输入文件按照一定的标准分片(InputSplit),每个输入片的大小 是固定的。默认情况下,输入片(InputSplit)的大小与数据块(Block)的大小是相同的。 如果数据块(Block)的大小是默认值64MB,输入文件有两个,一个32MB,一个72MB。
那么小的文件是一个输入片(InputSplit),大文件会分为两个输入块也就是两个输入片。 一共产生三个输入片。每一个输入片由一个Mapper进程处理。这里的三个输入片, 会有三个Mapper进程处理。
2.第二阶段是对输入片中的记录按照一定规则解析成键值对。有个默认规则是把 每一行文本内容解析成键值对。“键”是每一行的起始位置(单位是字节),“值”是本 行的文本内容。
3.第三阶段是调用Mapper类中的map方法。第二阶段中解析出来的每一个键值对,调用一次map方法。如果有1000个键值对,就会调用1000次map方法。每一次调用map方法会输出0个或多个键值对。Map具体的工作由我们自己来决定, 我们要对map函数进行覆盖,封装我们要进行的操作来实现我们的最终目的。
4.第四阶段是按照一定的规则对第三阶段的每个Mapper任务输出的键值对进 行分区。比较是基于键进行的。比如我们的键表示省份(如北京、上海),那么就可以 按照不同省份进行分区,同一个省份的键值对划分到一个区中。默认是只有一个区。分区的数量就是Reducer任务运行的数量。默认只有一个Reducer任务。
5.第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>,<1,3>,<2,1>,键和值分别是 整数。那么排序后的结果是<1,3>,<2,1>,<2,2>。如果有第六阶段,那么进入第六阶 段;如果没有,直接输出到本地的linux文件中。
6.第六阶段是对数据进行归约处理,也就是reduce处理。对于键相等的键值对 才会调用一次reduce方法。经过这一阶段,数据量会减少。归约后的数据输出到本地 的linux文件中。本阶段默认没有该代码,需要用户自己添加这一阶段。
6.Reducer执行过程
每个Reducer任务都是Java进程,Reducer接受Mapper任务输出的结果合并 归约到HDFS中

1.第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对。 Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。
2.第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合 并成一个大的数据。再对合并后的数据排序。
3.第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次 reduce方法,每次调用会产生0个或者多个键值对。最后把这些输出的键值对写入到 HDFS文件中。
