Data Pipelines with Apache Airflow机翻-5.复杂任务编排
5.复杂任务编排
本章内容包括:
- 研究如何区分Airflow DAG中的任务依赖顺序。
- 解释如何使用触发器规则在Airflow DAG 的特定点实现连接。
- 显示如何在Airflow DAG中执行条件任务,在某些条件下可以跳过该任务。
- 给出有关触发规则在Airflow中如何起作用以及如何影响您的任务执行的基本概念。
- 演示如何使用XCom在任务之间共享状态。
在之前的章节中,我们已经看到了如何构建一个基本的DAG并定义任务之间的简单依赖关系。在本章中,我们将进一步探索在Airflow中如何定义任务依赖关系,以及如何使用这些功能来实现更复杂的模式,包括条件任务,分支和联接。在本章的最后,我们还将深入探讨XComs,它允许在DAG运行中的不同任务之间传递数据,并讨论使用这种方法的优缺点。
5.1 基本依赖
在进入更复杂的任务依赖模式(如分支任务和条件任务)之前,让我们先花点时间研究一下我们在前几章中遇到的不同的任务依赖模式。这包括任务的线性链(一个接一个地执行的任务)和扇出/扇入模式(这涉及一个任务链接到多个下游任务,反之亦然)。为确保我们都在同一页面上,我们将在接下来的几节中简要介绍这些模式的含义。
5.1.1 线性依赖
到目前为止,我们主要集中于由单个线性任务链组成的DAG的示例。例如,我们从第2章(图5.1)获取火箭发射图片的 DAG 由三个任务组成: 一个用于下载发射元数据,一个用于下载映像,以及一个用于在整个过程完成后通知我们的任务:
Listing 5.1
download_launches = BashOperator(...)
get_pictures = PythonOperator(...)
notify = BashOperator(...)
图5.1。 我们从第2章中获取火箭图片的DAG包含三个任务,这些任务用于下载元数据,获取图片并发送通知。 最初如图2.3所示。
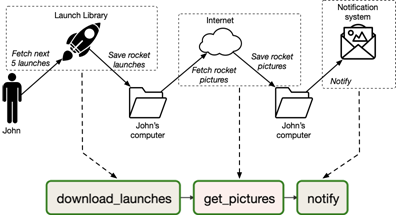
在这种DAG中,重要的是链中的每个前一个任务在继续执行下一个任务之前都已完成,因为前一个任务的结果需要作为下一个任务的输入。如我们所见,Airflow允许我们通过使用右移码运算符在两个任务之间创建依赖关系来指示两个任务之间的这种类型的关系:
Listing 5.2
# Set task dependencies one-by-one:
download_launches >> get_pictures
get_pictures >> notify
# Or in one go:
download_launches >> get_pictures >> notify
任务依存关系有效地告诉Airflow,只有在其(上游)依存关系成功完成执行后,它才可以开始执行给定任务。在上面的示例中,这意味着只有在download_launches成功运行后,get_pictures才能开始执行。 同样,只有在get_pictures任务完成且没有错误时,notify才能启动。
显式指定任务依赖关系的一个优点是,它清楚地定义了任务中的(隐式)顺序。顺序。 这使Airflow能够仅在满足其依赖关系时安排任务,这比(例如)使用cron逐个安排单个任务并希望在第二个任务开始时之前的任务已经完成要强得多(图5.2) )。而且,任何错误都将由Airflow传播到下游任务,从而有效地推迟了执行时间。 这意味着,在download_launches任务失败的情况下,除非解决了download_launches的问题,否则Airflow不会在当天尝试执行get_pictures任务。
5.1.2 扇入/扇出依赖关系
除了线性的任务链,Airflow的任务依赖关系还可用于在任务之间创建更复杂的依赖关系结构。
例如,让我们回顾第1章中的雨伞用例,在该用例中,我们希望训练一个机器学习模型,根据天气预报预测未来几周我们的雨伞的需求。
您可能还记得第一章,雨伞DAG的主要目的是每天从两个不同的来源获取天气和销售数据,并将这两组数据组合成一个数据集,以训练我们的模型。因此,DAG(图5.2)以两组任务开始,用于获取和清理输入数据,一组用于天气数据(fetch_weather和clean_weather),另一组用于销售数据(fetch_sales和clean_sales)。这些任务之后是一个任务(join_datasets),该任务获取清理后的销售和天气数据,并将这些数据集连接到一个组合数据集,以训练模型。 最后,此数据集用于训练模型(train_model),然后由最终任务(deploy_model)部署模型。
图5.2 第一章的雨伞用例DAG示意图

考虑到 DAG 的依赖性,在 fetch weather 和 clean weather 任务之间有一个线性依赖关系,因为我们需要在清理数据之前从远程数据源获取数据。但是,由于天气数据的获取/清除与销售数据无关,因此天气和销售数据任务之间没有依赖关系。总之,这意味着我们可以将获取和清理任务的依赖项定义为:
Listing 5.3
# Multiple linear dependencies.
fetch_weather >> clean_weather
fetch_sales >> clean_sales
在两个获取任务的上游,我们还可以添加一个虚拟的启动任务来表示 DAG 的开始。在这种情况下,这个任务并不是绝对必要的,但是它有助于说明在我们的 DAG 开始时所发生的隐式“扇出”,在这个 DAG 的开始启动了 fetch _ weather 和 fetch _ sales 任务。这种扇出依赖关系(将一个任务链接到多个下游任务可以定义为:
Listing 5.4
# Fan out (one-to-multiple).
start >> [fetch_weather, fetch_sales]
# Note that this is equivalent to:
# start >> fetch_weather
# start >> fetch_sales
与获取/清除任务的并行性相反,构建组合数据集需要来自天气和销售部门的输入。这样,join_datasets任务对clean_weather和clean_sales任务都具有依赖性,并且只能在两个上游任务都成功完成后才能运行。 这种类型的结构,其中一个任务依赖于多个上游任务通常被称为扇入结构,因为它由多个上游任务扇入到单个下游任务中。在Airflow中,扇入的依存关系可以定义如下:
Listing 5.5
# Fan in (multiple-to-one), defined in one go.
[clean_weather, clean_sales] >> join_datasets
# This notation is equivalent to defining the
# two dependencies in two separate statements:
clean_weather >> join_datasets
clean_sales >> join_datasets
在进入join_datasets任务之后,DAG的其余部分是用于训练模型和部署模型的线性任务链:
Listing 5.6
# Remaining steps are a single linear chain.
join_datasets >> train_model >> deploy_model
总的来说,这应该类似于图5.3所示的DAG。
图5.3。由气流的图形视图所呈现的雨伞DAG。这个DAG执行许多任务,包括获取和清理销售数据,将这些数据组合到一个数据集,并使用数据集来训练机器学习模型。请注意,销售/天气数据的处理发生在DAG的单独分支中,因为这些任务并不直接依赖于彼此。

那么,如果我们现在开始执行此DAG,您认为会发生什么? 哪些任务将首先开始运行? 您认为哪些任务将(而不是)并行运行?
如您所料,如果我们运行DAG,Airflow将首先运行启动任务来启动(图5.4)。 启动任务完成后,它将启动fetch_sales和fetch_weather任务,这些任务将并行运行(假设您的Airflow配置为具有多个工作程序)。完成这两个提取任务后,将启动相应的清理任务(clean_sales或clean_weather)。 只有两个清理任务都完成后,Airflow才能最终开始执行join_datasets任务。 最后,DAG的其余部分将线性执行,join_datasets完成后,train_model将立即运行,train_model完成后,deploy_model将运行。
图5.4。 雨伞DAG中任务的执行顺序,数字表示任务的运行顺序。Airflow通过执行启动任务开始,然后可以并行运行销售/天气获取和清洁任务(如后缀a / b所示)。注意,这意味着天气/销售路径是独立运行的,这意味着3b可以在2a之前开始执行。在完成两个清理任务之后,DAG 的其余部分继续线性地执行连接、训练和部署任务。

5.2 分支
假设您刚刚在DAG中完成了销售数据的输入,这时您的同事带来了一些消息,管理层决定将更换ERP系统,这意味着我们的销售数据将在一到两周内来自不同的来源(当然也是不同的格式)。这个变化不能导致模型训练的任何中断。此外,他们希望我们的流程能够与新旧系统兼容,这样我们就可以在未来的分析中继续使用历史销售数据。
您将如何解决这个问题?
5.2.1 任务分支
一种方法是重写我们的销售提取任务,以检查当前执行日期,并使用它来决定两个单独的代码路径之间的提取和处理销售数据。 例如,我们可以将销售清理任务重写为以下内容:
Listing 5.7
def _clean_sales(**context):
if context['execution_date'] < ERP_CHANGE_DATE:
_clean_sales_old(**context)
else
_clean_sales_new(**context)
...
clean_sales_data = PythonOperator(
task_id="clean_sales",
python_callable=_clean_sales,
provide_context=True
)
在此示例中,clean_sales_old是对旧销售格式进行清理的函数,而 clean_sales_new对新格式进行清理。 只要这两个功能的结果是兼容的(在列、数据类型等方面) ,我们的 DAG 的其余部分就可以保持不变,不需要担心两个 ERP 系统之间的差异。
类似地,我们可以通过添加从两个系统中提取的代码路径,使我们的初始提取步骤与两个ERP系统都兼容:
Listing 5.8
def _fetch_sales(**context):
if context['execution_date'] < ERP_CHANGE_DATE:
_fetch_sales_old(**context)
else:
_fetch_sales_new(**context)
...
这些变化结合起来,将允许我们的DAG以一种相对透明的方式处理来自两个系统的数据,因为我们的初始获取/清理任务可确保销售数据以相同(已处理)的格式输出,而与相应的数据源无关。
这种方法的优势在于,它使我们能够在DAG中加入一些灵活性,而不必修改DAG本身的结构。但是,这种方法仅在代码中的分支包含相似任务的情况下才有效。例如,在这里,我们在代码中实际上有两个分支,它们都执行获取和清除操作,并且差异最小。但是,如果从新数据源加载数据需要一个非常不同的任务链怎么办?(图5.5)在这种情况下,最好将数据提取分为两组独立的任务。
图5.5。 两个ERP系统之间不同任务集的可能示例。如果不同的情况之间有很多共性,那么您可以使用一组任务和一些内部分支来解决问题。但是,如果两个流程之间有很多差异(如这里显示的两个ERP系统),您可能最好采取不同的方法。

这种方法的另一个缺点是,在特定的DAG运行期间,很难看到Airflow正在使用哪个代码分支。 例如,在图5.6中,您可以猜测此特定DAG运行使用的是哪个ERP系统吗?仅使用此视图就很难回答这个看似简单的问题,因为实际的分支隐藏在我们的任务中。解决此问题的一种方法是在我们的任务中包括更好的日志记录,但是正如我们将看到的,还有其他方法可以使DAG本身中的分支更加明确。
图5.6。在fetch_sales和clean_sales任务中的两个ERP系统之间运行DAG的示例。由于此分支发生在这两个任务中,因此无法从此视图查看在此DAG运行中使用了哪个ERP系统。 这意味着我们将需要检查我们的代码(或者可能是我们的日志),以识别使用了哪个ERP系统。

最后,我们只能依靠一般的Airflow运算符(例如PythonOperator)来将这种类型的灵活性编码到我们的任务中。这使我们无法利用更专业的Airflow operators 提供的功能,这些功能使我们能够以最少的编码工作来执行更复杂的工作。例如,如果我们的数据源之一恰好是SQL数据库,那么如果我们仅使用MysqlOperator来执行SQL查询,它将为我们节省很多工作,因为这允许我们将查询的实际执行(连同身份验证等)委托给提供的operators 。
幸运的是,检查任务中的条件并不是执行分支的唯一方法。在下一节中,我们将展示如何将分支编织到 DAG 结构中,这比基于任务的方法提供了更多的灵活性。
5.2.2 DAG中的分支
在单个DAG中支持两种不同的ERP系统的另一种方法是开发两组不同的任务(每个系统一组),并允许DAG选择是否执行任务以从旧的或新的ERP系统中获取数据( 图5.7)。
图5.7。 使用DAG中的分支支持两个ERP系统。使用DAG中的分支,我们可以通过为两个系统实施不同的任务集来支持两个ERP系统。 然后,我们可以通过在上游添加一个额外的任务(此处为“ Pick ERP system”)来允许Airflow在这两个分支之间进行选择,该任务会告诉Airflow要执行哪些下游任务集。

构建这两组任务相对简单:我们可以使用适当的operators 分别为每个ERP系统创建任务,并将各自的任务连接在一起:
Listing 5.9
fetch_sales_old = PythonOperator(...)
clean_sales_old = PythonOperator(...)
fetch_sales_new = PythonOperator(...)
clean_sales_new = PythonOperator(...)
fetch_sales_old >> clean_sales_old
fetch_sales_new >> clean_sales_new
现在,我们仍然需要将这些任务连接到DAG的其余部分,并确保Airflow知道应在何时执行这些任务中的哪一个。
幸运的是,Airflow 提供了内置的支持,可以使用 BranchPythonOperator 在多组下游任务之间进行选择。该运算符(顾名思义)与PythonOperator相似,因为它将一个可调用的Python作为其主要参数之一:
Listing 5.10
def _pick_erp_system(**context):
...
pick_erp_system = BranchPythonOperator(
task_id='pick_erp_system',
provide_context=True,
python_callable=_pick_erp_system,
)
但是,与 PythonOperator 不同的是,传递给 BranchPythonOperator 的调用将返回下游任务的 ID 作为计算结果。 返回的ID确定分支任务完成后将执行哪些下游任务。 请注意,您还可以返回任务ID列表,在这种情况下,Airflow将执行所有引用的任务。
在这种情况下,我们可以根据DAG的执行日期使用callable返回适当的task_id,从而在两个ERP系统之间实现选择:
Listing 5.11
def _pick_erp_system(**context):
if context["execution_date"] < ERP_SWITCH_DATE:
return "fetch_sales_old"
else:
return "fetch_sales_new"
pick_erp_system = BranchPythonOperator(
task_id='pick_erp_system',
provide_context=True,
python_callable=_pick_erp_system,
)
pick_erp_system >> [fetch_sales_old, fetch_sales_new]
通过这种方式,Airflow 将在切换日期之前执行我们的一组“旧”ERP任务,同时在切换日期之后执行新任务。现在,剩下要做的就是将这些任务与我们DAG的其余部分联系起来!
为了将我们的分支任务连接到DAG的开始,我们可以在之前的开始任务和pick_erp_system任务之间添加一个依赖关系:
Listing 5.12
start_task >> pick_erp_system
同样,您可能希望连接两个清理任务就像在cleaning 任务和join_datasets任务之间添加依赖项一样简单(类似于我们之前将clean_sales连接到join_datasets的情况):
Listing 5.13
[clean_sales_old, clean_sales_new] >> join_datasets
但是,如果执行此操作,运行DAG将导致join_datasets任务及其所有下游任务被Airflow跳过。 (如果您愿意,可以尝试一下!)。
这是因为,在默认情况下,Airflow要求给定任务上游的所有任务都必须先成功完成,然后才能执行任务本身。 通过将我们的两个清理任务都连接到join_datasets任务,我们创建了一个永远都不会发生的情况,因为只执行了其中一个清理任务! 结果,join_datasets任务将永远无法执行,并且被Airflow跳过(图5.8)。
图5.8。 将分支与错误的触发规则结合使用将导致跳过下游任务。 在此示例中,由于sales_new分支而跳过了fetch_sales_old任务。 这导致fetch_sales_new任务下游的所有任务也被跳过,这显然不是我们想要的。

这种行为 执行任务的时间由Airflow中的所谓“触发规则”控制。 可以使用trigger_rule参数为单个任务定义触发规则,该参数可以传递给任何operator。 默认情况下,触发规则设置为“ all_success”,这意味着相应任务的所有父项都需要成功才能运行任务。当使用 BranchOperator 时,这种情况从来没有发生过,因为它会跳过任何没有被分支选择的任务,这说明了为什么Airflow也会跳过join_datasets任务及其所有下游任务。
为了解决这种情况,我们可以更改join_datasets的触发规则,以便在跳过其上游任务之一时仍可以触发。 实现此目标的一种方法是将触发规则更改为none_failed,该规则指定任务的所有父项都执行完毕且没有一个失败后,该任务应立即运行:
Listing 5.14
join_datasets = PythonOperator(
...,
trigger_rule="none_failed",
)
这样,join_datasets将在其所有父项完成执行而没有任何故障后立即开始执行,从而允许join_datasets在分支之后继续执行(图5.9)。
图5.9。 对join_datasets任务使用触发规则“ none_failed”在Umbrella DAG中进行分支。 通过将join_datasets的触发规则设置为“ none_failed”,任务(及其下游依赖项)仍在分支之后执行。

这种方法的一个缺点是我们现在在join_datasets任务中有3条边。 这并不能真正反映我们流程的本质,我们本质上是想要获取销售/天气数据(首先在两个ERP系统之间进行选择),然后将这两个数据源提供给join_datasets。因此,许多人选择在继续DAG之前通过添加连接不同分支的虚拟任务来使分支条件更加明确(图5.10)
图5.10。在分支之后添加一个额外的连接任务。为了使分支结构更加清晰,您可以在分支之后添加一个额外的“ join”任务,该任务将分支的谱系联系在一起,然后继续进行DAG的其余部分。 这项额外的任务还具有另一个优点,即您无需为DAG中的其他任务更改任何触发规则,因为您可以在联接任务上设置所需的触发规则。 (请注意,这意味着您不再需要为join_datasets任务设置触发规则。)

要将这样的虚拟任务添加到DAG中,我们可以使用Airflow提供的内置DummyOperator:
Listing 5.15
from airflow.operators.dummy_operator import DummyOperator
join_branch = DummyOperator(
task_id="join_erp_branch",
trigger_rule="none_failed"
)
[clean_sales_old, clean_sales_new] >> join_branch
join_branch >> join_datasets
此更改还意味着我们不再需要更改join_datasets任务的触发规则,从而使我们的分支比原始分支更独立。
5.3 条件任务
除了分支机构之外,Airflow还为您提供了其他机制,用于根据特定条件跳过DAG中的特定任务。 这使您可以使某些任务仅在某些数据集可用时才运行,或者仅在DAG在最近的执行日期执行时才运行。
例如,在我们的雨伞DAG中(图5.3),我们有一个任务,该任务将部署我们训练的每个模型。 但是,请考虑如果同事对清洗代码进行了一些更改并希望使用回填将这些更改应用于整个数据集时会发生什么。在这种情况下,回填DAG还会导致部署我们模型的许多旧实例,我们当然不希望将其部署到生产中。
5.3.1 任务中的条件
我们可以通过将DAG更改为仅针对最新的DAG运行部署模型来避免此问题,因为这可以确保我们仅部署模型的一个版本:在最新数据集上进行训练的版本。一种方法是使用PythonOperator实施部署,并在部署函数中显式检查DAG的执行日期:
Listing 5.15
def _deploy(**context):
if context["execution_date"] == ...:
deploy_model()
deploy = PythonOperator(
task_id="deploy_model",
python_callable=_deploy,
provide_context=True
)
尽管此实现应具有预期的效果,但它具有与相应的分支实现相同的缺点:它将部署逻辑与条件混淆,我们不能再使用除PythonOperator之外的任何其他内置运算符,并且无法在其中跟踪任务结果。 气流UI变得不太明确(图5.11)。
图5.11。 在deploy_model任务中有条件的情况下为Umbrella DAG运行的示例,该条件可确保仅针对最新运行执行部署。 由于条件是使用deploy_model任务在内部检查的,因此我们无法从该视图中看出模型是否已实际部署。

5.3.2 使任务有条件
实施条件部署的另一种方法是使部署任务本身具有条件,这意味着仅根据预定义的条件(在这种情况下DAG运行是否是最新的DAG运行)才执行实际的部署任务。 在Airflow中,您可以通过向DAG添加一个附加任务来使任务成为条件,该任务会测试该条件,并确保在条件失败时跳过所有下游任务。
遵循这个想法,我们可以通过添加一个检查当前执行是否是最新的DAG执行的任务并在该任务的下游添加部署任务来使部署成为条件部署:
Listing 5.16
def _latest_only(**context):
...
latest_only = PythonOperator(
task_id="latest_only",
python_callable=_latest_only,
provide_context=True,
dag=dag,
)
latest_only >> deploy_model
总的来说,这现在意味着我们的DAG看起来应该如图5.12所示,并且train_model现在已连接到我们的新任务,而deploy_model任务位于该新任务的下游。
图5.12。 带条件部署的雨伞DAG的替代实现,其中条件作为任务包含在DAG中。 与我们之前的实现相比,将条件作为DAG的一部分包含在内可使该条件更加明确。

接下来,我们需要填写_latest_only函数,以确保如果execute_date不属于最新运行,则跳过下游任务。为此,我们需要
(a)检查执行日期
(b)需要时从函数中引发AirflowSkipException
这是 Airflow 的方式,允许我们指示应该跳过条件和所有下游任务,从而跳过部署。
总而言之,这为我们的条件提供了以下实现:
Listing 5.17
from airflow.exceptions import AirflowSkipException
def _latest_only(**context):
# Find the boundaries for our execution window.
left_window = context['dag'].following_schedule(context['execution_date'])
right_window = context['dag'].following_schedule(left_window)
# Check if our current time is within the window.
now = pendulum.utcnow()
if not left_window < now <= right_window:
raise AirflowSkipException("Not the most recent run!")
我们可以通过执行几天的DAG来检查它是否有效! 这应该显示类似于图5.13的内容,在该图中我们看到在所有DAG运行中,除最新运行外,我们的部署任务已被跳过。
图5.13。 我们的Umbrella DAG运行了3次的“ latest_only”条件的结果。 我们的伞形DAG的树状图显示,我们的部署任务仅在最近的执行窗口中运行,因为在先前的执行中跳过了部署任务。 这表明我们的情况确实按预期运行。

那么这是如何工作的呢?
本质上,发生的情况是,当我们的条件任务(latest_only)引发AirflowSkipException时,该任务已完成,并且由Airflow分配了“已跳过”状态。 接下来,Airflow查看任何下游任务的触发规则,以确定是否应触发这些任务。 在这种情况下,我们只有一个下游任务(部署任务),该任务使用默认的触发规则“ all_success”,表明该任务仅在其所有上游任务均成功时才执行。在这种情况下,这是不正确的,因为其父项(条件任务)具有“已跳过”状态而不是“成功”状态,因此跳过了部署。
相反,如果条件任务没有引发AirflowSkipException,则条件任务成功完成,并被赋予“成功”状态。 这样,由于部署任务的所有父项都已成功完成,因此触发了部署任务,我们进行了部署。
5.3.3 使用内置运算符
由于只有最近一次DAG运行的运行任务是一个常见用例,因此Airflow还提供了内置的LatestOnlyOperator类。该Operator有效地执行与基于PythonOperator的自定义构建实现相同的工作。 使用LatestOnlyOperator,我们还可以像这样实现条件部署,省去了编写自己复杂的逻辑的麻烦:
Listing 5.18
from airflow.operators.latest_only_operator import LatestOnlyOperator
latest_only = LatestOnlyOperator(
task_id='latest_only',
dag=dag,
)
train_model >> latest_only >> deploy_model
当然,对于更复杂的情况,基于PythonOperator的路由为实现自定义条件提供了更大的灵活性。
5.4 有关触发规则的更多信息
在前面的部分中,我们看到了Airflow如何允许我们构建动态行为DAG,这允许我们将分支或条件语句直接编码到DAG中。 这种行为在很大程度上受Airflow所谓的触发规则支配,该规则确定了Airflow何时执行任务。由于我们在上一节中相对较快地跳过了触发规则,因此我们将在这里更详细地探讨它们,以使您了解触发规则代表什么以及如何使用它们。
要了解触发规则,我们首先必须检查Airflow如何在DAG运行中执行任务。 本质上,当Airflow执行DAG时,它将连续检查您的每个任务以查看是否可以执行它。 一旦某个任务被视为“准备执行”,该任务就会被调度程序拾取并安排执行。 因此,一旦Airflow有可用的执行插槽,便会立即执行任务。
那么,Airflow如何确定何时可以执行任务? 这就是触发规则出现的地方。
5.4.1 什么是触发规则?
触发规则本质上是Airflow应用于任务的条件,取决于它们的依赖性(= DAG中的先前任务),以确定它们是否准备好执行。 Airflow的默认触发规则是“ all_success”,该规则指出,必须先成功完成所有任务的依赖关系,然后才能执行任务本身。
要了解这是什么意思,让我们回到最初的Umbrella DAG实现(图5.4),除了默认的“ all_success”规则外,它还没有使用任何触发规则。 如果我们要开始执行此DAG,Airflow将开始循环执行其任务以确定可以执行哪些任务,即哪些任务没有依赖关系,尚未成功完成。
A

B
图5.14。使用默认触发器规则“all_success”跟踪基本的Umbrella DAG的执行(图5.4)。(A)气流开始执行DAG时,首先运行唯一一个之前没有成功完成的任务:start任务。(B)成功完成启动任务后,其他任务将准备好执行并由Airflow接管。

5.4.2 失败的影响
当然,这仅描绘了“快乐”流程的情况,在此情况下,我们的所有任务均成功完成。 例如,如果我们的任务之一在执行过程中遇到错误,该怎么办?
我们可以通过模拟其中一项任务中的故障来轻松地对此进行测试。 例如,通过模拟fetch_sales任务中的失败,我们可以看到Airflow将为fetch_sales分配“失败”状态而不是为成功执行使用的“成功”状态来记录失败(图5.15)。 这意味着下游的process_sales任务无法执行,因为它要求fetch_sales成功。 结果,clean_sales任务被分配了状态“ upstream_failed”,这表明它由于上游故障而无法继续进行。
图5.15。 上游故障会阻止使用默认触发规则“ all_success”执行下游任务,该规则要求所有上游任务都必须成功。 请注意,Airflow会继续执行与失败的任务无关的任务(fetch_weather和process_weather)

上游任务的结果也会影响下游任务的这种行为通常称为“传播”,因为在这种情况下,上游故障会“传播”到下游任务。 除了失败之外,默认触发规则还可以将已跳过任务的影响传播到下游,从而导致已跳过任务下游的所有任务也被跳过。
这种传播是“ all_success”触发规则定义的直接结果,该规则要求所有依赖项都必须成功完成。 这样,如果它在依赖项中遇到跳过或失败,则除了以类似方式失败以外,别无选择,从而传播了跳过或失败。
5.4.3 其他触发规则
除了默认触发规则外,Airflow还支持许多其他触发规则。 这些规则允许响应成功,失败或跳过的任务时出现不同类型的行为。
例如,让我们回顾一下第5.2节中两个ERP系统之间的分支模式。 在这种情况下,我们必须调整加入分支的任务的触发规则(由join_datasets或join_erp_branch任务完成),以避免下游任务由于分支而被跳过。 原因是,使用默认触发规则,通过仅选择两个分支之一在DAG中引入的跳过将被传播到下游,从而导致该分支之后的所有任务也被跳过。 相反,“ none_failed”触发规则仅检查是否所有上游任务均已完成而没有失败。 这意味着它可以容忍成功和跳过的任务,同时仍然等待所有上游任务完成再继续执行,从而使触发规则适合于加入两个分支。 请注意,就传播而言,这意味着规则不会传播跳过。 但是,它仍然会传播故障,这意味着获取/处理任务中的任何故障仍将停止下游任务的执行。
同样,其他触发规则可用于处理其他类型的情况。 例如,触发规则“ all_done”可用于定义任务完成依赖关系后立即执行的任务,而不管其结果如何。例如,这可以用于执行清理代码(例如,关闭计算机或清理资源) ,无论发生什么情况,您都希望运行这些代码。 另一类触发规则包括渴望规则,例如“ one_failed”或“ one_success”,它们不等待所有上游任务在触发之前完成,而是仅需要一个上游任务来满足其条件才可以触发。 这样,这些规则可用于表示任务的早期失败或一旦一组任务中的一个任务成功完成就迅速做出响应。
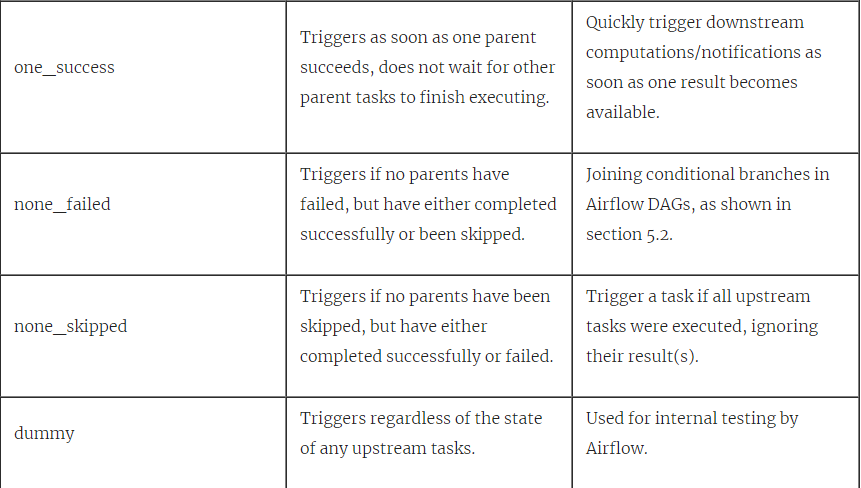
尽管这里我们不会更深入地介绍触发规则,但是我们希望这能使您对触发规则在Airflow中的作用以及如何将其用于将更复杂的行为引入DAG的想法有所了解。 有关触发规则和一些潜在用例的完整概述,请参考表5.1。
表5.1。 Airflow支持的不同触发规则的概述。

5.5 在任务之间共享数据
除了定义任务之间的依赖关系外,Airflow还允许您使用XComs [14]在任务之间共享小数据。 XComs背后的思想是,它们本质上允许您在任务之间交换消息,从而在任务之间实现某种程度的共享状态。
5.5.1 使用XComs共享数据
为了了解其工作原理,让我们回顾一下我们的总体用例(图5.3)。 想象一下,在训练模型时(在train_model任务中),使用随机生成的标识符将训练后的模型注册到模型注册表中。 为了部署经过训练的模型,我们需要以某种方式将此标识符传递给deploy_model任务,以便它知道应该部署哪个版本的模型。
解决这个问题的一种方法是使用xcom在train_model和deploy_model任务之间共享模型标识符。在本例中,train_model任务负责“推送”XCom值,这实际上发布了该值,并使其可用于其他任务。 我们可以使用xcom_push方法在任务中显式发布XCom值,该方法在Airflow上下文中的任务实例上可用:
Listing 5.19
def _train_model(**context):
model_id = str(uuid.uuid4())
context["task_instance"].xcom_push(key="model_id", value=model_id)
train_model = PythonOperator(
task_id="train_model", python_callable=_train_model, provide_context=True,
)
对xcom_push的此调用有效地告诉Airflow将我们的model_id值注册为相应任务(train_model)以及相应DAG和执行日期的XCom值。运行此任务后,您可以在Web界面中的Admin> XComs部分中查看此已发布的XCom值(图5.16),其中显示了所有已发布的XCom值的概述。
图5.16。 已注册的XCom值概述(在Web界面中的Admin> XComs下)。

您可以使用xcom_pull方法(与xcom_push相反)来在其他任务中检索XCom值:
Listing 5.20
def _deploy_model(**context):
model_id = context["task_instance"].xcom_pull(
task_ids="train_model", key="model_id"
)
print(f"Deploying model {model_id}")
deploy_model = PythonOperator(
task_id="deploy_model", python_callable=_deploy_model, provide_context=True,
)
这告诉Airflow从“ train_model”任务中使用键“ model_id”获取XCom值,该值与我们之前在train_model任务中推送的model_id相匹配。 请注意,xcom_pull还允许您在获取XCom值时定义dag_id和执行日期。 默认情况下,这些参数设置为当前DAG和执行日期,因此xcom_pull仅获取当前DAG运行发布的值[15]。
我们可以通过运行DAG来验证这项工作是否有效,这应该为我们提供类似于deploy_model任务的以下结果:
Listing 5.21
[2020-07-29 20:23:03,581] {python_operator.py:105} INFO - Exporting the following env vars:
AIRFLOW_CTX_DAG_ID=chapter5_08_xcoms
AIRFLOW_CTX_TASK_ID=deploy_model
AIRFLOW_CTX_EXECUTION_DATE=2020-07-28T00:00:00+00:00
AIRFLOW_CTX_DAG_RUN_ID=scheduled__2020-07-28T00:00:00+00:00
[2020-07-29 20:23:03,584] {logging_mixin.py:95} INFO - Deploying model f323fa68-8b47-4e21-a687-7a3d9b6e105c
[2020-07-29 20:23:03,584] {python_operator.py:114} INFO - Done. Returned value was: None
除了从任务中调用xcom_pull之外,还可以在模板中引用XCom变量:
Listing 5.22
def _deploy_model(templates_dict, **context):
model_id = templates_dict["model_id"]
print(f"Deploying model {model_id}")
deploy_model = PythonOperator(
task_id="deploy_model",
python_callable=_deploy_model,
templates_dict={
"model_id": "{{task_instance.xcom_pull(task_ids='train_model', key='model_id')}}"
},
provide_context=True,
)
最后,一些operators 还提供了对自动推送XCom值的支持。 例如,BashOperator有一个xcom_push选项,当设置为True时,它告诉操作员将bash命令写入stdout的最后一行作为XCom值推送。 同样,PythonOperator会将从Python调用返回的任何值发布为XCom值。 这意味着您还可以按如下所示编写我们的以上示例:
Listing 5.23
def _train_model(**context):
model_id = str(uuid.uuid4())
return model_id
def _deploy_model(**context):
model_id = context["task_instance"].xcom_pull(task_ids="train_model")
print(f"Deploying model {model_id}")
在后台,这可以通过在默认键“ return_value”下注册XCom来实现,正如我们在Admin部分中所见(图5.17)。
图5.17来自PythonOperator的隐式XCom已在“ return_value”键下注册。

5.5.2 何时(不)使用xcom
尽管XCom似乎对于在任务之间共享状态很有用,但它们的使用也有一些缺点。
例如,使用XComs的一个重要缺点是它们在任务之间添加了隐藏的依赖关系,因为提取任务对推送所需值的任务具有隐式依赖关系。 与显式任务相关性相反,此任务相关性在DAG中不可见,并且在安排任务时不会考虑。 因此,您有责任确保具有XCom依赖关系的任务以正确的顺序执行,Airflow不会为您执行此操作。当在不同的DAG或执行日期之间共享XCom值时,这些隐藏的依赖关系变得更加复杂,因此,这也不是我们建议的做法。
此外,当XCom破坏了operator的原子性时,它们可能会有点反模式。 例如,我们在实践中已经看到人们使用的一种用法是使用运算符在一个任务中获取API令牌,然后使用XCom将令牌传递给下一个任务。 在这种情况下,此方法的缺点是令牌在几个小时后过期,这意味着第二个任务的任何重新运行都将由于令牌过期而失败。更好的方法可能是将令牌的提取与第二个任务结合起来,这样一来,API令牌和相关工作的刷新就一次性发生了(从而使任务保持原子性)。
最后,XCom 的一个技术限制是,XCom 存储的任何值都需要是picklable。这意味着某些 Python 类型(如 lambdas 或许多与多处理相关的类)不能存储在 XCom 中(尽管您可能不希望这样做)。 此外,XCom值的大小受到将XCom存储在Airflow元存储中的数据库字段类型的最大大小限制:
-
SQLite-存储为BLOB类型,限制为2GB
-
PostgreSQL-存储为BYTEA类型,限制为1 GB
-
MySQL-存储为BLOB类型,限制为64 KB
话虽如此,如果适当地使用XComs可以成为强大的工具。 只要确保仔细考虑它们的用法并清楚地记录它们在任务之间引入的依赖关系,就可以避免日后出现意外情况。
5.6 摘要
在这一章里你学到了:
-
如何在Airflow DAG中定义基本线性依赖性和扇入/扇出结构。
-
如何将分支合并到DAG中,从而允许您根据特定条件选择多个执行路径。
-
可以将分支合并到DAG的结构中,而不是将其合并到任务中,从而在DAG的执行方式的可解释性方面提供了很多好处。
-
如何在DAG中定义条件任务,可以根据某些定义的条件执行这些任务。 与分支类似,这些条件可以直接在DAG中编码。
-
Airflow使用触发规则来启用这些行为,这些行为准确定义了Airflow何时可以执行给定任务。
-
除了默认触发规则“ all_success”之外,Airflow还支持其他各种触发规则,您可以使用这些触发规则来触发您的任务以应对不同类型的情况。
-
如何使用XCom在两个任务之间共享状态。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号