Data Pipelines with Apache Airflow机翻-3.Airflow调度
3.Airflow调度
本章涵盖
- 定期运行DAG
- 构造动态DAG以增量方式处理数据
- 使用回填来加载和重新处理过去的数据集
- 将最佳实践应用于可靠的任务
在上一章中,我们探讨了Airflow的用户界面,并向您展示了如何定义基本的Airflow DAG,以及如何通过定义计划的时间间隔每天运行此DAG。 在本章中,我们将更深入地了解Airflow中的调度概念,并探讨如何使您能够定期处理增量数据。 首先,我们将介绍一个小型用例,重点是分析我们网站上的用户事件,并探讨如何构建DAG来定期分析这些事件。 接下来,我们将探索一种方法,通过采用增量方法来分析我们的数据,以及如何将其与Airflow的执行日期概念联系起来,从而使这一流程更加高效。 最后,我们将展示如何使用回填来填充数据集中的空白,并讨论适当的Airflow任务的一些重要属性。
3.1 一个例子:处理用户事件
为了了解Airflow的调度工作原理,我们首先考虑一个小例子。 想象一下,我们有一项服务可以跟踪用户在我们网站上的行为,并允许我们分析用户在我们的网站上访问了哪些页面(由IP地址标识)。 出于营销目的,我们想知道用户访问了多少个不同的页面,以及他们在每次访问期间花费了多少时间。 为了了解这种行为随时间的变化,我们希望每天计算这些统计信息,因为这使我们可以比较不同天和更大时间段内的变化。
出于实际原因,外部跟踪服务不会将数据存储超过30天。 这意味着我们需要自己存储和累积这些数据,因为我们想保留较长时间的历史记录。 通常,由于原始数据可能很大,因此将这些数据存储在诸如Amazon S3或Google的Cloud Storage服务之类的云存储服务中是有意义的,因为这些服务结合了高耐用性和相对较低的成本。 但是,为简单起见,我们不会担心这些事情,并将数据保存在本地。
为了模拟此示例,我们创建了一个简单的(本地)API,该API允许我们检索用户事件。 例如,我们可以使用以下API调用来检索过去30天中可用事件的完整列表:

该调用返回用户事件的列表(JSON编码),我们可以对其进行分析以计算用户统计信息。
使用此API,我们可以将工作流程分解为两个单独的任务:一个任务用于获取用户事件,另一个任务用于计算统计信息。 数据本身可以使用BashOperator下载,其方式与上一章类似。 为了计算统计信息,我们可以使用PythonOperator,它允许我们将数据加载到Pandas数据框中,并使用groupby和聚合来计算事件数:
清单3.2从JSON读取事件,处理并将结果写入CSV
def calculate_stats(input_path, output_path):
"""Calculates event statistics."""
events = pd.read_json(input_path)
stats = events.groupby(["date", "user"]).size().reset_index()
stats.to_csv(output_path, index=False)
总而言之,这为我们的工作流程提供了以下DAG:
Listing 3.3[TITLE to COME
from datetime import datetime
import pandas as pd
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.operators.python_operator import PythonOperator
dag = DAG(
dag_id="user_events",
start_date=datetime(2015, 6, 1),
schedule_interval=None,
)
fetch_events = BashOperator(
task_id="fetch_events",
bash_command="curl -o data/events.json https://localhost:5000/events",
dag=dag,
)
def _calculate_stats(input_path, output_path):
"""Calculates event statistics."""
events = pd.read_json(input_path)
stats = events.groupby(["date", "user"]).size().reset_index()
stats.to_csv(output_path, index=False)
calculate_stats = PythonOperator(
task_id="calculate_stats",
python_callable=_calculate_stats,
op_kwargs={
"input_path": "data/events.json",
"output_path": "data/stats.csv",
},
dag=dag,
)
fetch_events >> calculate_stats
现在我们有了基本的DAG,但仍然需要确保它由Airflow定期运行。 让我们安排好时间,以便我们每天进行更新!
3.2 定期运行
正如我们在第2章中已经看到的那样,可以通过为DAG定义计划的时间间隔来定期运行Airflow DAG。 初始化DAG时,可以使用schedule_interval参数定义调度间隔。 默认情况下,此参数的值为None,这意味着将不安排DAG,并且仅在从UI或API手动触发时才运行DAG。
3.2.1 定义调度间隔
在摄取用户事件的示例中,我们希望每天计算统计信息,这表明安排DAG每天运行一次是有意义的。 由于这是一个常见用例,因此Airflow提供了方便的宏“ @daily”来定义每日计划的时间间隔,该间隔每天午夜运行我们的DAG:
Listing 3.4
dag = DAG(
dag_id="user_events",
schedule_interval="@daily",
...
)
但是,我们还没有完成。 为了让Airflow知道应该从哪个日期开始安排DAG运行,我们还需要提供DAG的开始日期。 根据该开始日期,Airflow会安排DAG的首次执行,以在开始日期之后的第一个计划间隔(开始+间隔)运行。 随后的运行将在第一个间隔之后的计划间隔内继续执行。
请注意“Airflow在间隔结束时开始一段新的间隔”这一事实。如果在2019年1月1日13:00时开发DAG,且start_date为01-01-2019且@daily间隔,则意味着它首先在午夜开始运行,即2019年1月1日24:00。如果您在1月1日13:00到24:00之前运行DAG,则不会发生任何事情。
例如,假设我们定义DAG的开始日期为一月的第一天:
Listing 3.5
import datetime as dt
dag = DAG(
dag_id="user_events",
schedule_interval="@daily",
start_date=dt.datetime(year=2019, month=1, day=1)
)
结合每日调度间隔,这将导致Airflow在1月1日后的每一天的午夜运行DAG(图3.1)。 请注意,我们的第一次执行是在1月2日(开始日期之后的第一个间隔)而不是1月1日执行。 我们将在本章后面深入探讨这种行为背后的原因。
图3.1 为每日计划的DAG安排具有指定开始日期的时间间隔。 显示了一个DAG的每日间隔时间,起始日期为2019-01-01。 箭头指示执行DAG的时间点。 如果没有指定结束日期,则DAG将每天执行直到DAG关闭。

如果没有结束日期,Airflow将(原则上)按照每天的时间表继续执行DAG,直到时间结束。但是,如果我们已经知道我们的项目有固定的持续时间,则可以使用end_date参数告诉Airflow在特定日期之后停止运行DAG:
Listing 3.6
dag = DAG(
dag_id="user_events",
schedule_interval="@daily",
start_date=dt.datetime(year=2019, month=1, day=1),
end_date=dt.datetime(year=2019, month=1, day=5),
)
这将导致如图3.2所示的完整的调度间隔集
图3.2 使用指定的开始日期和结束日期安排每日DAG的时间间隔。 显示与图3.1相同的DAG的时间间隔,但现在的结束日期为2019-01-05,这将阻止DAG在此日期之后执行。

3.2.3 基于Cron的间隔
到目前为止,我们所有的示例均显示DAG每天运行一次。 但是,如果我们想每小时或每周运行一次工作,该怎么办? 还有更复杂的时间间隔,例如,我们可能希望在每周六23:45运行 DAG?
为了支持更复杂的调度间隔,Airflow允许我们使用与cron(一种基于时间的作业调度程序)相同的语法来定义调度间隔,cron是类Unix的计算机操作系统(例如macOS和Linux)使用的基于时间的作业调度程序。 该语法由5个组成部分组成,定义如下:
# ┌─────── minute (0 - 59)
# │ ┌────── hour (0 - 23)
# │ │ ┌───── day of the month (1 - 31)
# │ │ │ ┌───── month (1 - 12)
# │ │ │ │ ┌──── day of the week (0 - 6) (Sunday to Saturday;
# │ │ │ │ │ 7 is also Sunday on some systems)
# * * * * *
在此定义中,当时间/日期指定字段与当前系统时间/日期匹配时,将执行cron作业。 可以使用星号(*)代替数字来定义不受限制的字段,这意味着我们不在乎该字段的值。
尽管这种基于cron的表示似乎有些令人费解,但是它为我们提供了相当大的灵活性来定义时间间隔。 例如,我们可以使用以下cron表达式定义每小时,每天和每周的间隔:
- 0 * * * * = hourly (running on the hour)
- 0 0 * * * = daily (running at midnight)
- 0 0 * * 0 = weekly (running at midnight on Sunday)
除此之外,我们还可以定义更复杂的表达式,例如:
- 0 0 1 * * = midnight on the first of every month
- 45 23 * * SAT = 23:45 every Saturday
此外,cron 表达式允许您使用逗号(‘ ,’)定义值集合以定义值列表,或者使用破折号(‘-’)定义值范围。使用这种语法,我们可以构建表达式,支持在多个工作日或一天中多组时间内运行作业:
- 0 0 * * MON,WED,FRI = run every Monday, Wednesday, Friday at midnight
- 0 0 * * MON-FRI = run every weekday at midnight
- 0 0,12 * * * = run every day at 00:00 AM and 12:00 P.M.
Airflow同时还支持几个宏,这些宏表示常用的调度间隔。我们已经看到其中一个用于定义每日间隔的宏(@daily)。表3.1给出了一个由气流支持的其他宏的概述。
表3.1 Airflow预置常用的调度间隔
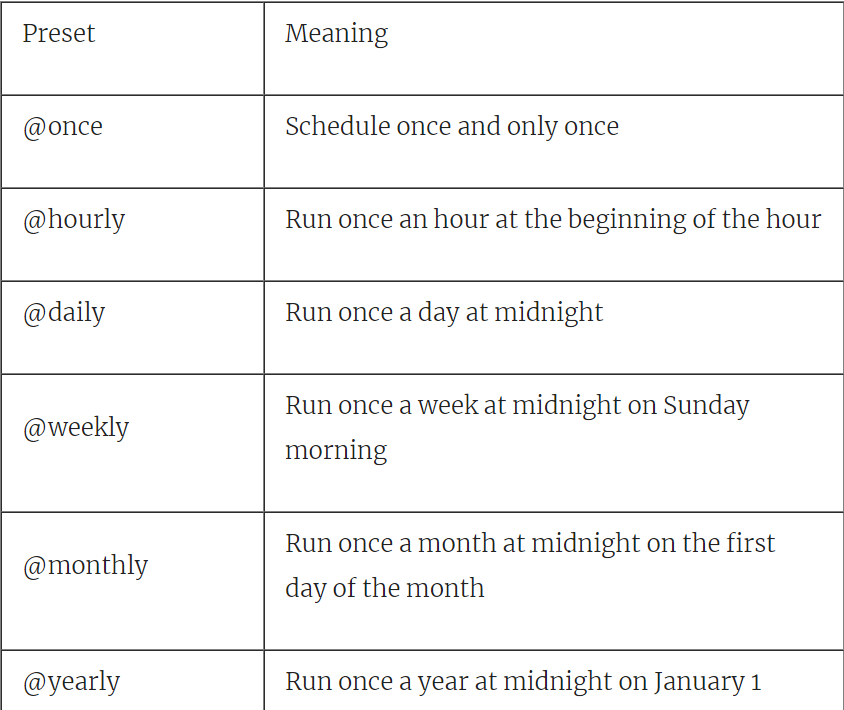
尽管cron表达式功能非常强大,但可能很难使用它们。因此,最好先在Airflow中测试您的表达式。幸运的是,在线上有很多工具[6],可以帮助您用简单的英语定义,验证或解释您的cron表达式。在代码中记录复杂 cron 表达式背后的原因也不会有什么坏处。这可以帮助其他人(包括将来的您!)在重新访问代码时理解表达式。
3.2.3 基于频率的间隔
Cron 表达式的一个重要限制是它们无法表示某些基于频率的调度。 例如,您如何定义每三天运行一次DAG的cron表达式?事实证明,您可以编写一个表达式,在每个月的第1天、第4天、第7天运行,但是这种方法在月底会遇到问题,因为 DAG 会在下个月的第31天和第1天连续运行,违反了预期的时间表。
Cron 的这种局限性源于 cron 表达式的性质,因为 cron 表达式定义了一个模式,该模式与当前时间不断匹配,以确定是否应该执行某个作业。这样做的好处是使表达式成为无状态的,这意味着您不必记住何时运行前一个作业以计算下一个间隔。然而,正如您所看到的,这是以一些表达能力为代价的。
那么,如果我们真的想要按照每天三次的时间表运行 DAG,又该怎么办呢?
为了支持这种基于频率的计划,Airflow还允许您根据相对时间间隔来定义计划间隔。要使用这种基于频率的调度,可以将“ timedelta”实例(来自标准库中的 datetime 模块)作为调度间隔传递:
Listing 3.7
from datetime import timedelta
dag = DAG(
dag_id="user_events",
schedule_interval=timedelta(days=3),
start_date=dt.datetime(year=2019, month=1, day=1),
)
这将导致我们的 DAG 在开始日期后每三天运行一次(2019年1月4日、7日、10日等)。当然,您也可以使用这种方法每10分钟(使用timedelta(minutes=10))或每2小时(使用 timedelta(hours=2))运行 DAG。
3.3 增量处理数据
3.3.1 增量获取事件
尽管现在我们的DAG每天运行一次(假设我们坚持使用@daily时间表),但我们尚未完全实现我们的目标。一方面,我们的DAG每天都在下载和计算整个用户事件目录的统计信息,这几乎没有效率。此外,这个过程只是下载过去30天的事件,这意味着我们没有为过去的日期建立任何历史记录。
解决这些问题的一种方法是更改DAG以增量方式加载数据,在这种方式中,我们仅加载每个计划间隔中相应日期的事件,并且仅计算新事件的统计信息(图3.3)
图3.3. 以增量方式获取和处理数据

这种增量式方法比获取和处理整个数据集要有效得多,因为它大大减少了每个计划间隔中必须处理的数据量。 此外,由于我们现在每天将数据存储在单独的文件中,因此我们也有机会开始建立一段时间内的文件历史记录,这已经超过了API的30天限制。
要在工作流程中实施增量处理,我们需要修改DAG以下载特定日期的数据。 幸运的是,我们可以通过包括开始和结束日期参数来调整API调用以获取当前日期的事件:
curl -O http://localhost:5000/events?start_date=2019-01-01&end_date=2019-01-02
这两个日期参数一起指示了我们要获取事件的时间范围。 请注意,在此示例中,start_date是包含性的,而end_date是排除性的,这意味着我们有效地获取了在2019-01-01 00:00:00和2019-01-01 23:59:59之间发生的事件。
我们可以通过更改bash命令以包括两个日期来在DAG中实现这种增量数据获取:
Listing 3.8
fetch_events = BashOperator(
task_id="fetch_events",
bash_command="curl -o data/events.json http://localhost:5000/events?start_date=2019-01-01&end_date=2019-01-02",
dag=dag,
)
但是,要获取2019年1月1日以外的任何其他日期的数据,我们需要更改命令以使用开始和结束日期,这些开始和结束日期反映了DAG的执行日期。 幸运的是,Airflow为此提供了一些额外的参数,我们将在下一部分中进行探讨。
3.3.2 使用执行日期的动态时间引用
对于许多涉及基于时间的流程的工作流,了解给定任务执行的时间间隔非常重要。因此,Airflow为任务提供了额外的参数,这些参数可用于确定任务在哪个计划间隔内执行。
这些参数中最重要的称为执行日期,它表示执行DAG的日期和时间。 与参数名称所暗示的相反,execution_date不是日期,而是时间戳,它反映了要对其执行DAG的计划间隔的开始时间。 计划间隔的结束时间由另一个参数(称为next_execution_date)指示。 这两个日期共同定义了任务计划的整个长度
图3.4. Airflow中的执行日期

除了这两个参数外,Airflow还提供了一个previous_execution_date参数,该参数描述了上一个计划间隔的开始。 尽管此处不会使用此参数,但是它对于执行将当前时间间隔的数据与前一个时间间隔的结果进行对比的分析很有用。
在Airflow中,我们可以通过在operators中引用这些执行日期来使用它们。 例如,在BashOperator中,我们可以使用Airflow的模板功能将执行日期动态地包含在Bash命令中。 第4章将详细介绍模板。
Listing 3.9
fetch_events = BashOperator(
task_id="fetch_events",
bash_command=(
"curl -o data/events.json "
"http://localhost:5000/events?"
"start_date={{execution_date.strftime('%Y-%m-%d')}}"
"&end_date={{next_execution_date.strftime('%Y-%m-%d')}}"
),
dag=dag,
)
在此示例中,语法{{variable_name}}是使用Airflow基于Jinja的[7]模板语法来引用Airflow特定参数之一的示例。 在这里,我们使用此语法来引用两个执行日期,并使用datetimes strftime方法将它们格式化为期望的字符串格式(因为两个执行日期都是datetime对象)。
由于execute_date参数通常以这种方式用于将日期作为格式字符串引用,因此Airflow还为常用的日期格式提供了几个简写参数。 例如,ds和ds_nodash参数是execution_date的不同表示形式,其格式分别为YYYY-MM-DD和YYYYMMDD。同样,next_ds,next_ds_nodash,prev_ds和prev_ds_nodash分别提供了下一个和上一个执行日期的简写。
使用这些缩写,我们还可以编写如下的增量fetch命令:
Listing 3.10
fetch_events = BashOperator(
task_id="fetch_events",
bash_command="curl -o data/events.json http://localhost:5000/events?start_date={{ds}}&end_date={{next_ds}}", #A
dag=dag,
)
这个较短的版本更容易阅读。 但是,对于更复杂的日期(或日期时间)格式,您可能仍将需要使用更灵活的strftime方法。
3.3.3 对数据进行分区
尽管我们新的fetch_events任务现在在每个新的计划时间间隔内增量获取事件,但是精明的读者可能已经注意到,每个新任务都只是覆盖了前一天的结果,这意味着我们实际上没有建立任何历史记录。
解决此问题的一种方法是将新事件简单地追加到events.json文件,这将使我们能够在单个JSON文件中建立历史记录。但是,这种方法的一个缺点是,任何下游处理作业都需要加载整个数据集,即使我们只对某一天的统计数据感兴趣。此外,它还使该文件成为单点故障,如果该文件丢失或损坏,我们可能会丢失整个数据集。
一种替代方法是通过将任务的输出写入带有相应执行日期名称的文件中,将我们的数据集分成每日批处理:
Listing 3.11
fetch_events = BashOperator(
task_id="fetch_events",
bash_command="curl -o data/events/{{ds}}.json http://localhost:5000/events?start_date={{ds}}&end_date={{next_ds}}",
dag=dag,
)
这将导致将执行日期为2019-01-01的所有数据下载到文件data / events / 2019-01-01.json中。
在数据存储和处理系统中,将数据集划分为更小、更易于管理的部分是一种常见的策略。这种做法通常称为分区,将数据集的较小部分称为分区。
当我们考虑DAG中的第二项任务(calculate_stats)时,按执行日期对数据集进行分区的优势就显而易见了,在该任务中,我们可以计算每天用户事件的价值统计信息。 在我们之前的实现中,我们每天都在加载整个数据集并计算整个事件历史记录的统计信息:
Listing 3.12
def _calculate_stats(input_path, output_path):
"""Calculates event statistics."""
events = pd.read_json(input_path)
stats = events.groupby(["date", "user"]).size().reset_index()
stats.to_csv(output_path, index=False)
calculate_stats = PythonOperator(
task_id="calculate_stats",
python_callable=_calculate_stats,
op_kwargs={
"input_path": "data/events.json",
"output_path": "data/stats.csv",
},
dag=dag,
)
然而,使用我们的分区数据集,我们可以通过改变这个任务的输入和输出路径,指向分区的事件数据和分区的输出文件,更有效地计算每个分区的统计数据:
Listing 3.13
def _calculate_stats(**context):
"""Calculates event statistics."""
input_path = context["templates_dict"]["input_path"]
output_path = context["templates_dict"]["output_path"]
events = pd.read_json(input_path)
stats = events.groupby(["date", "user"]).size().reset_index()
stats.to_csv(output_path, index=False)
calculate_stats = PythonOperator(
task_id="calculate_stats",
python_callable=_calculate_stats,
templates_dict={
"input_path": "data/events/{{ds}}.json",
"output_path": "data/stats/{{ds}}.csv",
},
provide_context=True,
dag=dag,
)
尽管这些更改看起来有些复杂,但它们大多涉及样板代码,以确保输入和输出路径是模板化的。为了在 PythonOperator 中实现这种模板化,我们需要使用操作符 templates _ dict 参数传递任何应该模板化的参数。为了在 Python 函数中检索这些模板化参数,我们需要通过设置 provide_context = True 确保将上下文传递给函数,然后从任务上下文中检索它们的值。
如果这一切进行得有点太快了,不要担心——我们将在下一章更详细地讨论任务上下文。这里需要理解的重要一点是,这些变化允许我们通过每天只处理一小部分数据来逐步计算我们的统计数据。
3.4 了解Airflow的execution dates
由于execution dates是Airflow的重要组成部分,因此请花一点时间来确保我们完全了解如何定义这些日期。
3.4.1 以固定的时间间隔执行工作
正如我们所看到的,我们可以控制什么时候Airflow运行一个DAG,它有三个参数: 开始日期、时间间隔和(可选的)结束日期。为了实际开始安排DAG,Airflow使用这三个参数将时间划分为一系列计划间隔,从给定的开始日期开始,还可以选择在结束日期结束(图3.5)。
图3.5 时间表示为Airflow的计划间隔时间。假设每天的间隔时间开始日期为2019-01-01

在这种基于时间间隔的时间表示中,一旦超过某个时间间隔的时隙,就会执行一个 DAG。例如,图3.5中的第一个间隔将在2019-01-0123:59:59之后尽快执行,因为此时间间隔中的最后一个时间点已经过去。类似地,DAG 将在2019-01-02 23:59:59之后的第二个间隔内执行,以此类推,直到我们到达可选的结束日期。
使用这种基于区间的方法的一个优点是,它非常适合执行我们在前面几节中看到的增量数据处理类型,因为我们准确地知道一个任务执行的时间间隔——相应时间间隔的开始和结束。这与例如 cron 这样的基于时间点的计划系统形成了鲜明的对比,后者只知道执行任务的当前时间。例如在 cron 中,我们要么必须计算或“猜测”我们以前的执行中断的地方,例如假设任务是在前一天执行的(图3.6)。
图3.6。 与基于时间点的系统(例如cron)派生的窗口相比,基于间隔的调度窗口(例如气流)中的增量处理。 对于增量(数据)处理,通常将时间划分为离散的时间间隔,在经过相应的时间间隔后立即对其进行处理。 基于时间间隔的计划方法(如Airflow)明确安排任务在每个时间间隔内运行,同时向每个任务提供有关时间间隔开始和结束的准确信息。相比之下,基于时间点的计划方法只在给定时间执行任务,由任务本身决定任务执行的增量间隔。

了解Airflow的时间处理是围绕计划间隔建立的,这也有助于了解如何在Airflow中定义执行日期。并考虑应处理2019-01-03日数据的相应时间间隔。在Airflow中,此时间间隔将在2019-01-04 00:00:00之后不久运行,因为那时我们知道在2019-01-03那天我们将不再接收任何新数据。回想上一节中我们在任务中使用执行日期的解释,您认为在此间隔内execution_date的值是什么?
许多人期望该DAG运行的执行日期为2019年1月4日,因为这是DAG实际运行的时刻。但是,如果我们在执行任务时查看 execution _ date 变量的值,我们实际上会看到执行日期为2019-01-03。这是因为Airflow将DAG的执行日期定义为相应间隔的开始。从概念上讲,如果我们认为执行日期标记了我们的计划间隔,而不是实际执行DAG的时刻,那么这是有意义的。不幸的是,这个命名可能有点混乱。
图3.7 在计划时间间隔的上下文中执行日期。 在Airflow中,DAG的执行日期定义为相应计划间隔的开始时间,而不是DAG的执行时间(通常是间隔的结束)。因此,execution _ date 的值指向当前间隔的开始,而 previous _ execution _ date 和 next _ execution _ date 参数分别指向上一个和下一个调度间隔的开始。当前间隔可以从执行日期和下一个执行日期的组合中派生出来,后者表示下一个间隔的开始,从而表示当前间隔的结束。

如果将Airflow执行日期定义为相应调度间隔的开始,则可以使用它们来推导特定间隔的开始和结束(图3.7)。例如,当执行一个任务时,相应间隔的开始和结束是由 execution _ date (间隔的开始)和 next _ execution date (下一个间隔的开始)参数定义的。类似地,可以使用previous_execution_date和execution_date 参数导出先前的调度间隔。
但是,在任务中使用previous_execution_date和next_execution_date参数时要记住的一个注意事项是,这些参数仅针对已经定义好计划时间间隔下的DAG。 因此,对于使用Airflow UI或CLI手动触发的任何运行,这些参数的值都将是不确定的。这样做的原因是,如果您不遵循计划间隔,则Airflow无法为您提供有关下一个或先前计划间隔的信息。
3.5 使用回填填补过去的空白
由于Airflow 允许我们定义从任意开始日期开始的时间间隔,我们也可以定义从过去某个开始日期开始的过去时间间隔。我们可以使用这个属性来执行 DAG 的历史运行来加载或分析过去的数据集——这个过程通常被称为回填。
3.5.1 在过去时间执行工作
默认情况下,Airflow将计划并运行任何之前尚未运行的计划间隔。因此,指定过去的开始日期并激活相应的 DAG 将会运行所有当前执行时间之前的所有时间间隔。这种行为受 DAG 捕获参数控制,可以通过设置catchup为 False 来禁用:
Listing 3.13
dag = DAG(
dag_id="user_events",
schedule_interval=timedelta(days=3),
start_date=dt.datetime(year=2019, month=1, day=1),
catchup=False,
)
使用此设置,DAG将仅在最近的调度间隔内运行,而不执行所有过去的间隔。通过catchup_by_default可以设置catchup的默认值。
尽管回填是一个强大的概念,但它受源系统中数据可用性的限制。 例如,在示例用例中,我们可以通过指定最长30天的开始日期来从API加载过去的事件。 但是,由于该API仅提供长达30天的历史记录,因此我们不能使用回填来加载早期的数据。
回填还可以用于在我们对代码进行更改后重新处理数据。例如,假设我们对 _ calc _ statistics 函数进行了更改,以添加一个新的统计值。使用回填,我们可以清除过去运行的 calc _ statistics 任务,以使用新代码重新分析我们的历史数据。请注意,在这种情况下,我们不受数据源30天限制的限制,因为我们已经在过去的运行中加载了这些早期的数据分区。
3.6 设计任务的最佳实践
虽然Airflow 在回填和重新运行任务时承担了大部分繁重的工作,但我们需要确保我们的任务满足某些关键属性,以确保取得适当的结果。在本节中,我们将深入讨论适当的Airflow 任务的两个最重要的性质: 原子性和幂等性。
3.6.1 原子性
原子性一词在数据库系统中经常使用,其中原子性事务被视为一系列不可分割且不可还原的数据库操作,因此要么全部发生,要么什么都不发生。同样,在Airflow中,任务应该被定义为要么成功并产生某种适当的最终结果,要么以不影响系统状态的方式失败。
图3.8 原子性确保了要么完成一切,要么什么都不完成。不会产生半功,因此,避免了错误的结果。

再举一个例子,考虑对用户事件 DAG 的一个简单扩展,我们希望在其中添加一些功能,在每次运行结束时发送前十名用户的电子邮件。一个简单的方法就是扩展我们之前的函数,再调用一些函数来发送包含我们统计数据的邮件:
Listing 3.14
def _calculate_stats(**context):
"""Calculates event statistics."""
input_path = context["templates_dict"]["input_path"]
output_path = context["templates_dict"]["output_path"]
events = pd.read_json(input_path)
stats = events.groupby(["date", "user"]).size().reset_index()
stats.to_csv(output_path, index=False)
send_stats(stats, email="user@example.com")
不幸的是,这种方法的缺点是任务不再是原子的。 你知道为什么吗? 如果没有,请考虑如果send_stats函数失败会发生什么(如果我们的电子邮件服务器有些不稳定,那肯定会发生)。 在这种情况下,我们已经将统计信息写入到output_path的输出文件中,即使任务以失败而结束,看起来我们的任务也成功了。
为了以原子的方式实现这个功能,我们可以简单地将电子邮件功能分割成一个单独的任务:
Listing 3.15
def _send_stats(email, **context):
stats = pd.read_csv(context["templates_dict"]["stats_path"])
email_stats(stats, email=email)
send_stats = PythonOperator(
task_id="send_stats",
python_callable=_send_stats,
op_kwargs={"email": "user@example.com"},
templates_dict={"stats_path": "data/stats/{{ds}}.csv"},
provide_context=True,
dag=dag,
)
calculate_stats >> send_stats
这样,发送电子邮件失败不再影响calculate_stats任务的结果,而只会使send_stats失败,从而使这两个任务都是原子的。
从这个例子中,您可能会认为将所有操作分成单独的任务足以使我们的所有任务原子化。 但是,这不一定是正确的。 要了解原因,请考虑如果事件API要求我们在查询事件之前登录,该怎么办。 通常,这需要额外的API调用来获取一些身份验证令牌,然后我们才能开始检索事件。
按照我们之前的推理,一个operation = 一个task,我们将不得不将这些操作分成两个单独的任务。但是,这样做会在两个任务之间创建一个强大的依赖关系,因为第二个任务(获取事件)将在不运行第一个任务之前失败。这两个任务之间的强大依赖性意味着我们最好将两个操作保持在一个任务中,使任务形成一个连贯的工作单元。
大多数Airflow operators 已经被设计为原子的,这就是为什么许多operators 都包括用于在内部执行紧密耦合操作(如内部身份验证)的选项的原因。
3.6.2 幂等性
除了原子性之外,编写Airflow 任务时要考虑的另一个重要属性是幂等性。如果用相同的输入多次调用相同的任务没有额外的结果,则称任务为幂等的。例如,这意味着在不更改输入的情况下重新运行任务不应更改整体输出。
例如,考虑一下我们上一个 fetch _ events 任务的实现,它获取一天的结果并将其写入分区数据集:
Listing 3.16
fetch_events = BashOperator(
task_id="fetch_events",
bash_command="curl -o data/events/{{ds}}.json http://localhost:5000/events?start_date={{ds}}&end_date={{next_ds}}",
dag=dag,
)
在给定的日期重新运行这个任务将导致获取与前一次执行相同的事件集(假设日期在我们的30天窗口内) ,并覆盖数据/事件文件夹中的现有 JSON 文件,从而产生相同的最终结果。因此,获取事件任务的这种实现显然是幂等的。
为了展示一个非幂等任务的示例,考虑我们讨论的使用单个 JSON 文件(data/events.JSON)并简单地将事件附加到该文件的情况。在这种情况下,重新运行任务将导致事件被附加到现有数据集,从而在数据集中重复天事件。因此,这个实现不是幂等的,因为任务的额外执行会改变整个结果。
图3.9 无论执行多少次,幂等任务都会产生相同的结果。 幂等确保了一致性和处理失败的能力。

通常,可以通过检查现有结果或确保先前的结果被任务覆盖来使写入数据的任务具有幂等性。在分时数据集中,这是相对简单的,因为我们可以简单地覆盖相应的分区。类似地,对于数据库系统,我们可以使用 upsert 操作来插入数据,这允许我们覆盖由以前的任务执行所写入的现有行。但是,在更一般的应用程序中,您应该仔细考虑任务的所有副作用,并确保以幂等的方式执行所有这些副作用。
3.7 摘要
-
通过设置schedule_interval,DAG可以定期运行
-
间隔的工作在间隔结束时开始
-
schedule_interval可以使用cron和timedelta表达式进行配置
-
通过使用模板动态设置变量,可以增量处理数据
-
execution_date是指间隔的开始日期时间,而不是实际的执行时间
-
DAG可以通过回填及时运行
-
幂等确保在产生相同输出结果的同时可以重新运行任务

 浙公网安备 33010602011771号
浙公网安备 33010602011771号