李宏毅深度学习笔记-Seq2seq

在讲Sequence Generation之前,再复习下RNN和有门的RNN(LSTM,GRU)
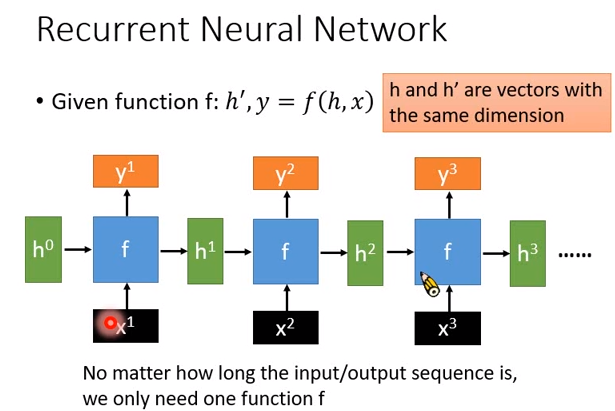
之前告诉你说,RNN是一个有记忆的神经网络,但今天从另外一个角度来讲RNN。我们说RNN特别的地方是它里面有一个basic函数,用\(f\)来表示,在RNN里面会被反复使用。这个basic函数的input是两个向量(\(h,x\)),output是另外两个向量,写作\(h',y\),我们知道说要使用RNN时,你的输入是一个向量序列,现在向量序列用\(x^1,x^2,x^3\)表示。
现在第一个向量\(x^1\)进来,是basic函数\(f\)的input,\(f\)还需要另外一个input \(h^0\)(在用RNN的时候,有一个初始化的向量),然后\(f\)产生两个向量\(h^1,y^1\)。
接下来新的\(x^2\)进来,同样的\(f\)会被反复使用。这边是用反复使用某一个函数来说明RNN,在之前告诉你说,神经元会把\(h^1\)存下来在下一个时间点被使用。\(f\)把\(x^2,h^1\)作为input,output \(y^2,h^2\)。你可以想象说,如果你要反复使用函数\(f\),那么\(h^0,h^1,h^2\)的维度一定是要一样的。
RNN比较强的地方在,不管input的sequence有多么长,它都是以不变应万变,都只有一个basic函数\(f\),所以RNN的参数量不会随着input sequence的长度而改变,特别适合用来处理input sequence特别长的状况
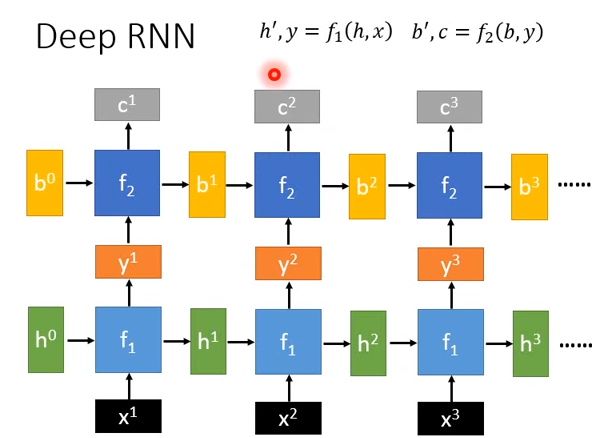
RNN可以是deep的,比如本来已经有一个basic函数\(f_1\),现在再加另一个basic函数\(f_2\)。\(f_2\)一样是接受两个向量作为input,输出另外两个向量。
如上图所示,\(f_2\)接受\(f_1\)的output \(y^1\),再接受另一个初始化向量\(b^0\),输出\(b^1,c^1\)......
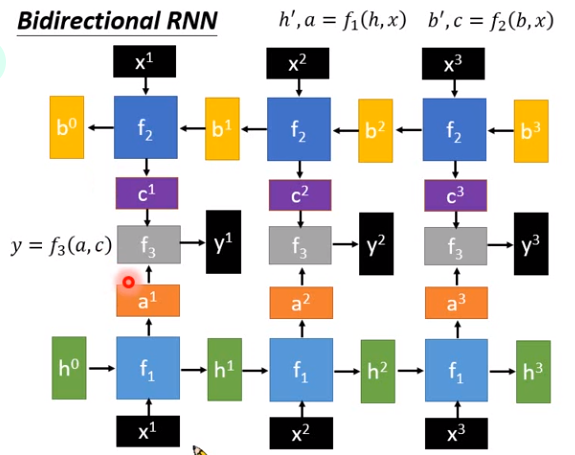
我们也讲过双向RNN,一样有两个函数,\(f_1\)就是之前看到的,\(f_2\)接受input的方向和\(f_1\)相反,\(f_2\)先input \(x^3\),再input \(x^2\),再input \(x^1\) 。\(f_1\)会产生一排向量(\(y^1,y^2,y^3\)),\(f_2\)也会产生另外一排向量(\(c^1,c^2,c^3\))。
接下来要有另外一个函数\(f_3\),接受两个向量\(a^1,c^1\),得到最后的output。
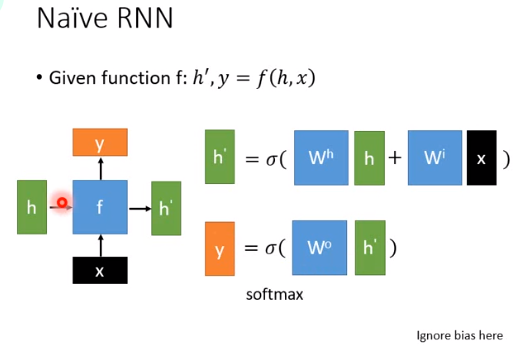
这个RNN我们说是由一个basic函数组成的,basic函数\(f\)长什么样子是自己自由设计的,只要能接受两个向量\(x,h\),output另外两个向量\(y,h'\),唯一的限制是\(h,h'\)的维度要一样,\(x,y\)的维度不需要一样。
\(f\)最简单的设计方式如上图右边所示,\(x\)乘上一个矩阵\(W^i\)(结果还是一个向量),\(h\)乘上另一个矩阵\(W^h\)(结果也是一个向量),把这两个结果向量加起来,通过一个激活函数得到\(h'\)。这个激活函数通常使用Hyperbolic tangent(双曲正切函数,tanh),我们知道在一般的深度网络里面通常会用Relu,但在RNN里面用Relu表现不会太好。
有了\(h'\)之后,乘上\(W^0\)得到一个向量,在通过一个激活函数得到\(y\),这个是最简单的basic函数的设计,但不是最常见的设计。
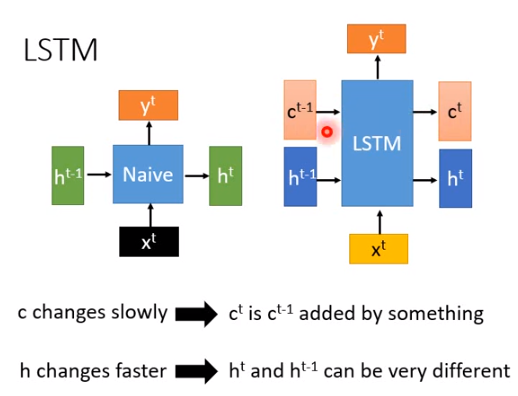
最常见的设计是LSTM。
之前RNN是input \(h^{t-1},x^t\),output \(h^t\)。LSTM不一样的地方是把本来的\(h\)拆成两块,如上图所示,红色的\(c^{t-1}\)和蓝色的\(h^{t-1}\)串在一起就是绿色的\(h^{t-1}\),红色的向量和蓝色的向量串在一起就是绿色的向量。在LSTM里面我们特别说,input和output都分两部分,两种不同的向量有不同的特性。
在LSTM里面,\(c\)是一个变换比较慢的memory,\(c^t\)和\(c^{t-1}\)会非常像,\(c^t\)就是\(c^{t-1}\)加上某个东西,而\(h^t\)和\(h^{t-1}\)是非常不一样的。像一般的RNN里\(h^t\)和\(h^{t-1}\)就非常不像,\(h^{t-1}\)会乘上一个transformation以后再加上某个东西变成\(h^t\)(\(h^{t-1}\)会乘以一个矩阵\(W\))。
LSTM强的地方在于,相较于一般的RNN,不太会忘记很久以前的信息,就是因为有\(c^{t-1}\)跟\(c^t\)的关系,变化是比较缓慢的,如果有要长时间记忆的东西,就放在\(c\)里面。
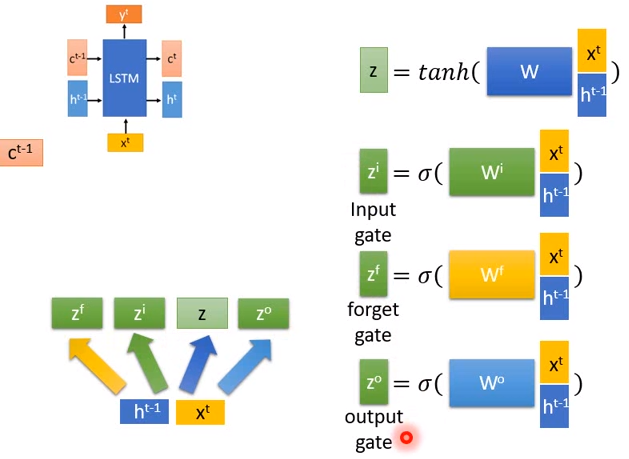
实际看一下LSTM的计算过程。
input 三个向量\(c^{t-1},h^{t-1},x^t\),如上图右上方所示,把\(x^t,h^{t-1}\)接在一起变成一个比较长的向量,再乘上一个矩阵\(W\)再通过tanh()得到一个向量\(z\) 。
\(x^t,h^{t-1}\)接在一起的向量会乘上不同的transform矩阵,可以制造出不同的向量。如上图乘上了一个矩阵\(W^i\) ,和\(W\)是不一样的,但都可以从训练数据中学习出来。之后通过一个激活函数得到\(z^i\),以此类推得到\(z^f、z^o\)。
\(z^i\)就是输入门的input,\(z^f\)是遗忘门的input,\(z^o\)是输出门的input。
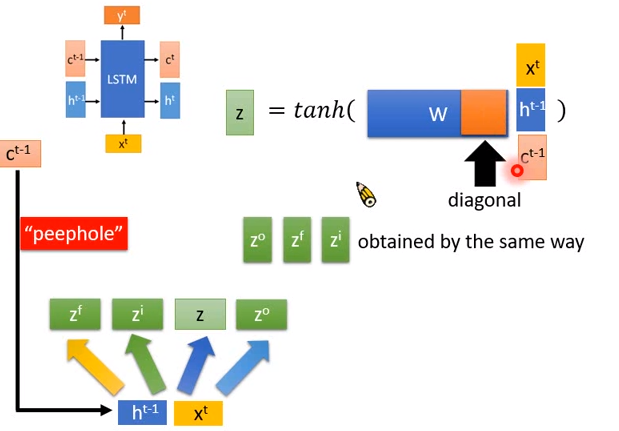
除了把\(x\)跟\(h\)串在一起乘上一个transform以外,你要做的更好还有一招叫做peephole,把\(c\)跟\(h、x\)也串在一起,再乘上一个特别长的矩阵\(W\),再通过tanh()得到\(z\)。你可以想象说,加了\(c\)后向量变长了,所以\(W\)的参数就变多了,实际上这样做表现不一定会好,因为参数变多了就容易过拟合。实际你要做peephole的话,你会强迫矩阵的右边部分是diagonal的(对角化的),也就是说现在\(x^t\)会乘上蓝色矩阵\(W\)的前三分之一,\(h^{t-1}\)会乘上蓝色矩阵\(W\)中间的三分之一,\(c^{t-1}\)会乘上蓝色矩阵\(W\)的对角化部分(最后三分之一),乘对角化矩阵的好处是可以减少参数使用量。所以\(C^{t-1}\)不同维度不会有相关性,不同维度就是各自乘上一个数值而已。
\(z^o、z^f、z^i\)也是做同样的事情。
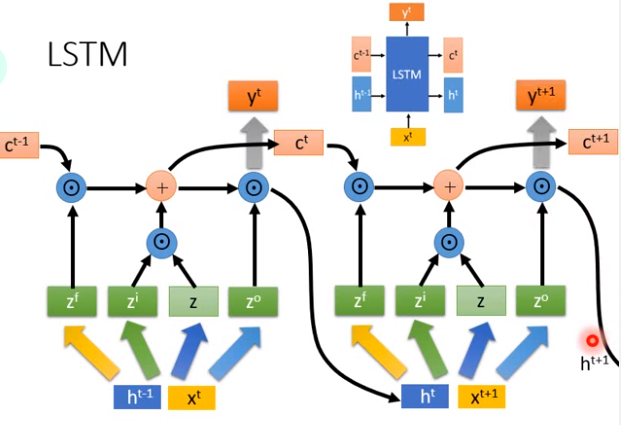
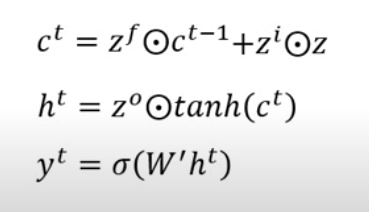
有了四个向量(\(z^f、z^i、z、z^o\))之后,接下来做的事情就是把\(z、z^i\)做元素乘积,\(c^{t-1}、z^f\)也做元素乘积,把两个元素乘积加起来得到\(c^t\)。从这个结果可以看到,原来的\(c^{t-1}\)跟\(z^f\)做元素乘积再加上一个东西。所以发现说,\(c^t\)跟\(c^{t-1}\)可能没有太大差别,变化比较少,那么一些不太需要的信息就可以放在\(c\)里面。你会意外发现说,\(c^{t-1}\)跟\(c^t\)之间甚至连非线性激活函数都没有。
\(h^t\)是从\(c^t\)算出来的,\(c^t\)先做tanh(),然后和\(z^0\)做元素乘积,所以发现说\(h^{t-1}\)跟\(h^t\)非常不一样。\(h^{t-1}\)做了transform之后才得到\(z^0、z^i、z^f\),间接影响\(c^t\)(\(c^t\)做计算得到\(h^t\))。\(h^t\)和\(h^{t-1}\)有关系,但是是非常不一样的。
最后要得到\(y^t\)的话,就是把\(h^t\)乘上一个矩阵\(W'\)再通过一个激活函数。
我们知道说同样的block(上图右上方所示)会反复使用,我们知道RNN的特性就是同样的basic函数被反复使用,那在LSTM里面block被反复使用,所以\(c^t、h^t\)又接入下一个block,产生新的\(c^{t+1}、h^{t+1}\)。
除了LSTM,GRU也是非常常用的RNN的basic函数。GRU input一个\(h^{t-1}\),output一个\(h^t\),input一个\(x^t\),output一个\(y^t\),表面上看起来跟原来的RNN一样。然而GRU更像是LSTM,GRU里\(h\)的角色比较像LSTM里\(c\)的角色(没有LSTM里\(h\)的角色)。
GRU的运作方式是:
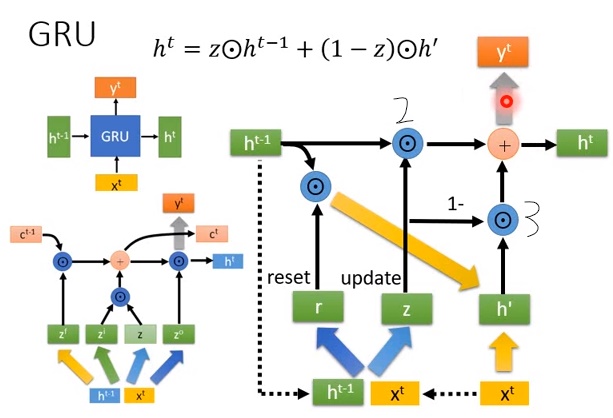
- input \(x^t\)跟\(h^{t-1}\),首先把\(x^t\)跟\(h^{t-1}\)接起来,再乘上一个transform(蓝色箭头)后得到\(r\)(叫做reset 门),乘上另一个transform后得到\(z\)(叫做update门)。
- 有了reset门和update门之后,把\(r\)跟\(h\)先做元素乘积得到一个向量,这个向量跟\(x^t\)并在一起后再通过一个transform(黄色箭头)得到\(h'\)。
- 把\(z\)跟\(h^{t-1}\)做元素乘积后得到一个向量,\(1-z\)跟\(h'\)做元素乘积后得到另一个向量,这两个向量加起来得到\(h^t\)
- \(h^t\)乘上一个transform之后得到\(y^t\)
把式子列出来就是\(h^t=z \bigodot h^{t-1}+(1-z)\bigodot h'\)。
那可以看到GRU的参数量是比LSTM少的,可以减少过拟合的可能性。看上图所示,LSTM有4个transform(不同颜色粗箭头,不算到\(y^t\)的transform),GRU只有三个transform(不同颜色粗箭头,两个黄色算一个transform)。
那么GRU跟LSTM有什么关系呢?
GRU可以再看做是LSTM里面遗忘门跟输入门是联动的,从上面的图很难看出来。现在把GRU里面的\(h\)想象成是LSTM的\(c\),因为GRU里面\(h^t\)跟\(h^{t-1}\)是非常相近的,看式子里,只是差了一个东西而已。
那GRU的\(h\)在哪里呢?
在LSTM里面,\(c\)乘上输出门得到\(h^t\)。在GRU中把\(h^{t-1}\)想成\(c\),reset门想成是输出门,\(h^{t-1}\)乘上reset门得到的就是\(h\)。LSTM里面的\(h\)变化很快,那在GRU里面\(h\)不会被拿到输出的地方。 \(h^{t-1}\)既然是memory,那跟memory相乘的东西就是遗忘门(上图右边2处),上图3处就是输入门,输入门和遗忘门是联动的(一个是\(z\),一个是\(1-z\))。
\(h^t\)跟\(y^t\)有什么差别?
不管是在LSTM还是GRU里面,都是把\(h^t\)乘上一个transform之后(灰色箭头),才会得到\(y^t\)。
Sequence Generation
要讲的是怎么让让机器产生出东西,过去机器学习通常是做分类。假设要让机器output一个sentences,怎么做呢?我们知道说一个句子,是由words(词)或者characters(字)组成的。举例来说,如果是英文的话,英文的词和词之间是有空白隔开的,比如apple是一个word,那a到e这5个字母就是characters(因为里面的字)。那对中文来说的话,每一个词汇是由数个字所组成的,比如说葡萄(词)是由葡(字)萄(字)组成的。
今天要让机器学习做Sequence Generation(写一个句子)的话,我们可以用characters(字)为单位,也可以用词为单位,我们只要让RNN每次都可以产生出一个字或是一个词就可以了。
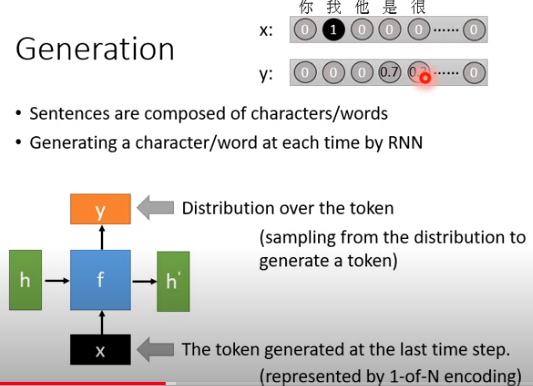
我们说RNN是一个basic函数,input \(h\)和\(x\),output \(h'\)和\(y\)。在做Generation的时候,这个\(x\)是前一个时间点产生出来的token(不管是字符还是词),\(y\)是现在机器要产生出来的token的distribution,但我们要的是某一个字或词,而不是token的distribution,所以最后要从\(y\)这个distribution里面sample出一个token。如上图最上方,以字符为单位,假如在某个时间点,机器写了一个“我”,那么此时\(x\)就是“我”位置为1的向量\([0 \ 1\ 0 \ 0 \cdots 0]\),而\(y\)这个向量是在每个字符上的distribution(概率分布),然后根据概率分布sample出字符,比如0.7概率为“我是”,0.3概率为“我很”。
说说机器是怎么完整的产生Sequence的。
要产生第一个字符的时候,会给机器一个非常特殊的字源,只有在句子的开头才会发生,通常叫做begin of sentence(
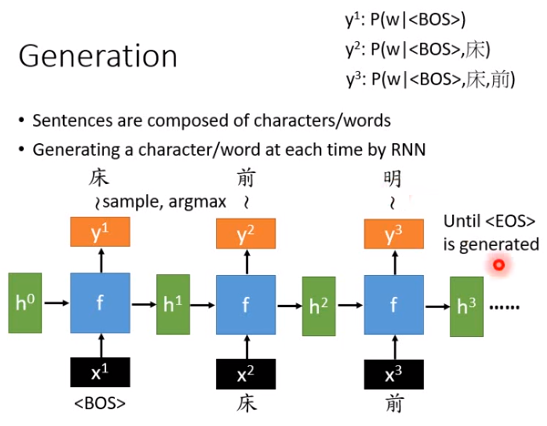
- 如上图所示,把\(y^1\)看作是给定句首(
)这个token的时候某一个character出现的概率分布,然后根据这个分布做sample,可能sample出“床”这个字(也可以argmax,但这样每次取出来的都是同一个字)。 - 接下来把“床”作为\(x^2\)向量(对应到“床”的维度为1,其他维度为0)丢进去,经过同样的函数\(f\),input是\(x^2\)和\(h^1\),output是\(h^2\)和\(y^2\),同样的对\(y^2\)做sample,可能就得到下一个字(“前”)。\(y^2\)就是一个概率分布,在床之后每个字出现的概率。
- 然后把“前”作为\(x^3\)向量丢进去,得到\(h^3\)和\(y^3\),\(y^3\)可以看作是已经有“床、前”后,下一个字出现的概率分布。\(y^3\)不是只看到了“前”,还有“床”,因为还input了\(h^2\),然后可能“明”出现的概率最大,这样就能写出一首诗。
- 那什么时候停止呢?你会设计一个特殊的符号
,代表句子的结束,即当机器产生 时停止。
这个是生成的过程,我们还没有讲怎么得到这个\(f\)函数。
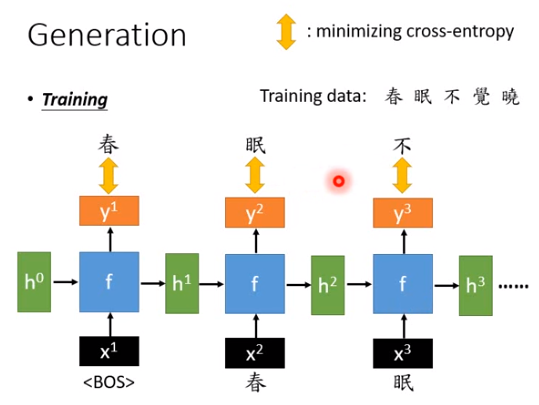
要找出这个\(f\),首先要给机器训练数据,比如你要给机器读唐诗三百首,例如“春眠不觉晓”。给
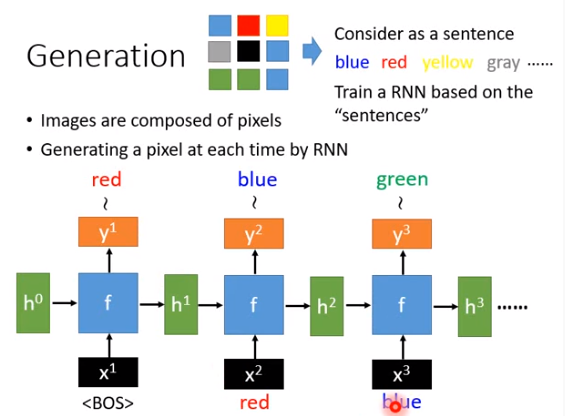
刚才说的是产生一个句子,也可以产生其他东西,比如让机器画一个图。
我们知道一张图片是由一大堆像素组成的,如果把每个像素看做是一个字的话,一张图片就可以看做一个句子。比如上图一个3x3的图片,把每个像素想成是一个词,就可以写为“blue red yellow gray ......”。接下来就训练一个RNN,然后把RNN训练好之后就可以用来画图。
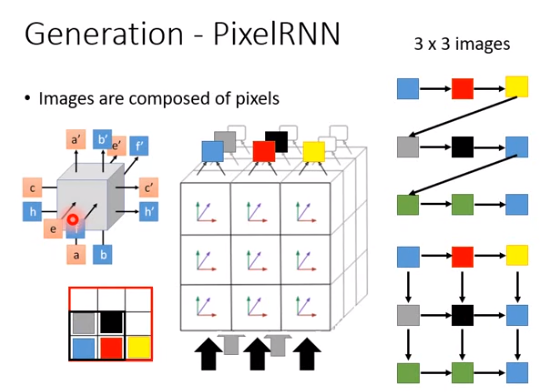
如果你要产生更好的图,就要有更进阶的方法。在刚才的例子里,产生图的顺序是blue-red-yellow-gray.....,但实际上我们知道在一个图片里面,“yellow”和“gray”的距离可能是很远的,它们之间可能没有什么太大的关系,真正跟“gray”有关系的可能是“blue”。所以你要做一个先进的图片生成的话,会用一个特别的技术叫做pixelRNN。
pixelRNN改变了生成的方式,如上图右下方所示,在产生灰色pixel的时候,看得不是黄色的pixel,而是蓝色的pixel。在产生黑色pixel的时候,要同时看红色和灰色的pixel,以此类推,这个技术叫做pixelRNN。它的结构比较复杂,之后有时间再会讲到。
Conditional Generation

接下来要讲的是conditional generation,到刚才为止我们训练出来的RNN,如果让它看唐诗三百首,那么它确实是一个能写诗的RNN(随机的诗)。但没有办法让它遇景生情,比如给它一幅画,让它写一首诗。它只能写一些非常random的东西。那我们其实可以做到让机器看着某个conditional,根据某一个情景,然后产生适合的output,这个东西就叫做conditional generation。
conditional generation有什么应用呢?
- 机器看到一段video,然后output “A young gril is dancing”。
- 或者是chat-bot,你说一句话,机器回应一个response。
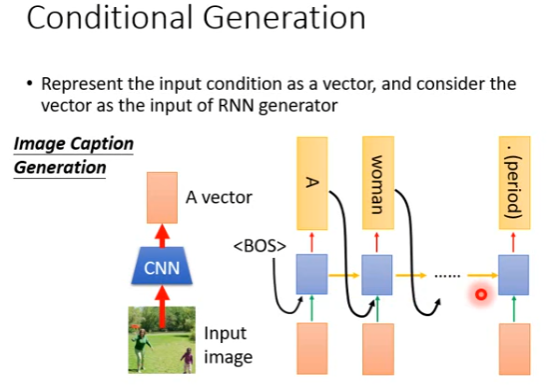
先看一下图片的conditional generation是怎么做的。给机器看一张图片,然后告诉你说图片里有什么东西。刚才我们讲过说,可以弄一个RNN出来,这个RNN可以随机产生句子,给它
那怎么丢进去呢?
其实有各种不同的做法,你可以选择一个自己喜欢的。比如把图片通过CNN变成一个vector,然后把这个vector跟
那么就是把红色的vector存在memory里面,然后产生对应的句子。训练的时候就是准备图片和对应的句子,搜集10万个pair进行训练。
这样做就是有一个风险,就是RNN部分,看过第一个时间点的红色vector,随着时间点的推移,可能就忘了当初看过什么东西。所以一个常见的做法是,在每个时间点都输入红色vector。
seq2seq模型
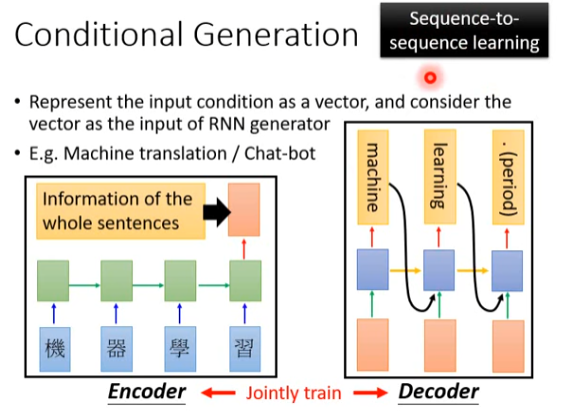
同样的技术完全可以做机器翻译或者是chat-bot。刚才是输入一张图片,然后把图片变成一个vector之后丢给RNN generator。那现在input是一个句子,只要把句子变成一个vector,接下来的步骤就是一模一样的。
怎么把句子变成vector呢?
使用一个RNN,如上图下方所示,假设要做翻译,翻译“机器学习”为“Machine learning"。这个RNN就把中文sequence”机器学习"input进去,把最后一个时间点的output取出来。其实RNN在每个时间点都会output一个东西(y),但前面的output都不要。因为最后一个时间点的output \(y\),可能包含了所有input 的信息。有时候红色vector不一定是最后时间点的\(y\),也可能是h(隐藏状态)、c(记忆状态)或者h和c的结合。
然后把红色的vector丢进generator里面,每个时间点都丢,希望可以产生"Machine""learning" "."。当然在训练的时候,上图左下方部分叫做encoder,右下方部分叫做decoder。因为左下方部分是把一个sequence变成一个vector,右下方部分是把一个vector变成一个sequence。
当然encoder、decoder是一起训练的。
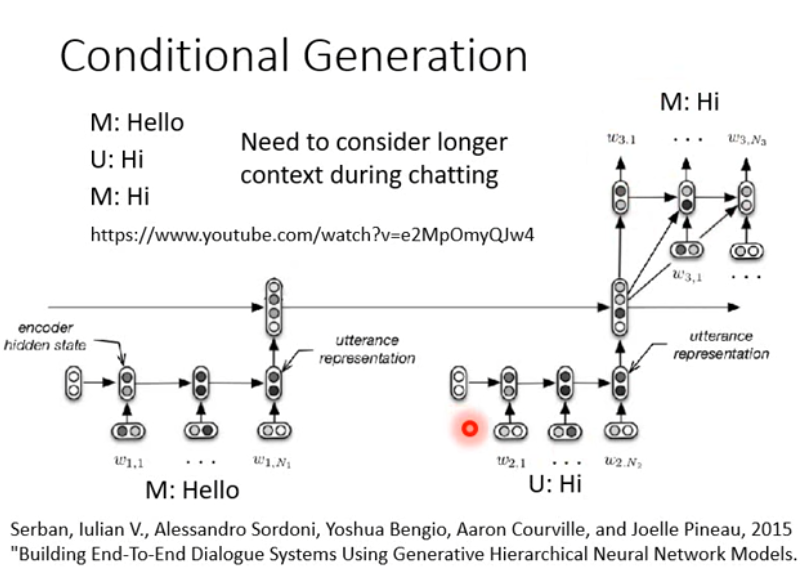
在chat-bot里当然也可以使用这种技术,学习一个seq2seq模型,input一个句子,然后output就是另外一个句子。有人可能会觉得说,也许这样没有办法真的让机器做到跟人聊天,因为机器不记得之前说过什么。比如你说HI的时候,根据seq2seq模型,机器给出一个HI,但也许可能之前机器已经说过一个Hello,HI是你的回答,然后机器仍会给出HI。
那怎么避免这个问题?
就是把历史的信息也放进encoder里面去。比如之前机器说过hello,然后人说HI,那之后seq2seq模型可能有很多层的,第一层把第一个句子变成vector,第二层把第二个句子变成vector......。然后把之前的句子都做encoder,丢进一个decoder里去,这样训练后机器就可以得到过去的信息了。
Dynamic Conditional Generation
很多文献把这种模型叫做attention base model。之前encoder、decoder会遇到一些问题,即encoder可能没有足够的能力把所有东西都压到一个vector中去。如果input是各种各样的句子,很难用一个vector就表示句子中所有的信息,这样就不得不丢掉一些信息后再丢进decoder。
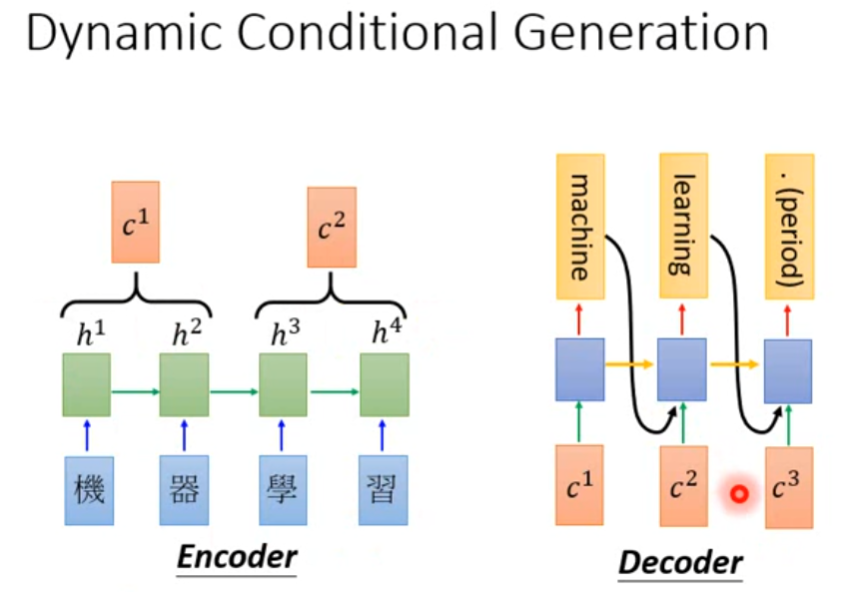
Dynamic Conditional Generation意思是说,decoder中每个时间段从encoder得到的input都是不一样的,由decoder自己决定如何截取信息。
encoder每个隐藏层状态为\(h^1,h^2,h^3,h^4\),然后把这些状态存在一个database。decoder生成一个词汇的时候,从database中搜寻自己需要的信息。
比如decoder要产生“machine”之前,从database中搜寻\(h^1,h^2\)并抽取出\(c^1\)作为input,在生成“learning”之前会抽取出\(c^2\)......
Machine Translation
假设机器翻译要做的事情是input 机器学习,ouput 翻译为machine learning。在训练的时候,就是给机器很多的中文和英文pair。
attention-base model是怎么做的呢?
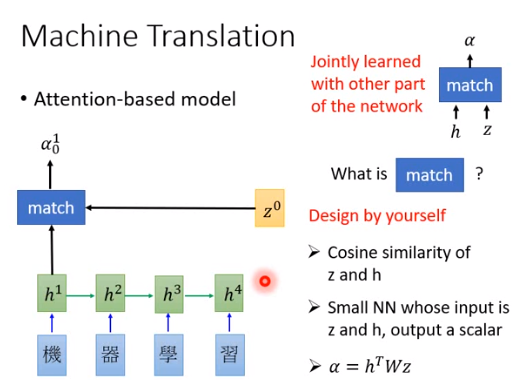
input中文的character sequence,每个character依序丢到RNN里,RNN cell产生隐藏状态\(h^1\)到\(h^4\),RNN会存起来作为一个database,\(h\)比\(y\)的维度要小,因此用\(y\)的话可能计算代价会变高。
向量\(z^0\)是神经网络参数的一部分,需要训练数据才能找出来,是搜寻database的一个关键字,一般叫做key。
怎么进行搜寻?
会跟database中每个\(h\)向量计算一个匹配程度,match模组(又叫做attention模组)是专门用来计算匹配度的。接收\(z\)(key)、\(h\)作为input,output 一个分数\(\alpha\)(又叫做attention分数)表明\(z\)跟\(h\)有多匹配。
match是什么?
match可以自己设计,比如点积、一个小的神经网络(input 是\(z、h\),output是分数\(\alpha\)),也可以是一个函数式\(\alpha = h^TWz\) 。
要强调的点是,如果你的match本身有参数的话,比如一个神经网络,是不需要额外再把它找出来的,因为match模组是和encoder-decoder合在一起学的。
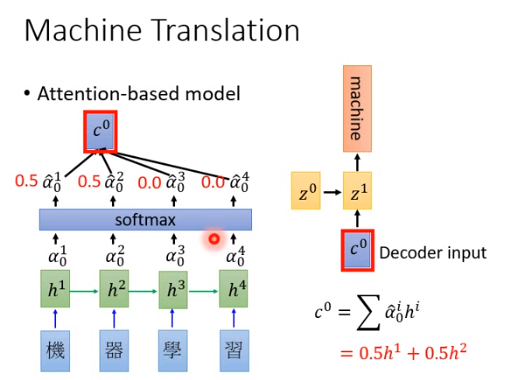
\(\alpha_0^0\)到\(\alpha_0^4\)你可以做一个softmax,也可以不做,有时候会进步有时候没有进步。\(\hat{\alpha}_0^1\)到\(\hat{\alpha}_0^2\)是\(\alpha_0\)标准化后的值,接下来加权计算\(c\) 。举个例子\(\hat{\alpha}_0^1=0.5,\hat{\alpha}_0^2=0.5,\hat{\alpha}_0^3=0,\hat{\alpha}_0^4=0\),那么\(c^0=0.5h^1+0.5h^2\)。然后把\(c^0\)当做decoder的input,根据\(z^0,c^0\) output \(z^1\) 和machine。
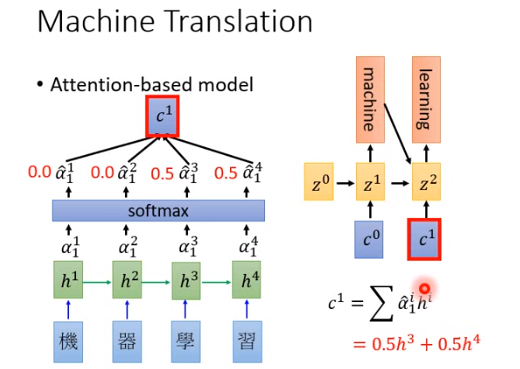
然后根据\(z^1\)重新算一次\(c^1\)(\(z^1 、h\)重新算一个分数\(\alpha_1\),再得到\(c^1\)),如上图所示\(c^1=0.5h^3+0.5h^4\)。
然后\(c^1\)作为下一个时间点basic function的input,下一个时间点的basic function还会接收上一个时间的输出。
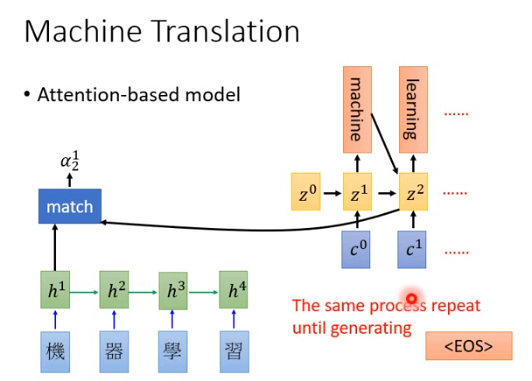
持续这个过程直到输出句点或者\(<EOS>\)时结束。
Image Caption Generation
attention-base model 也可以用在图片字幕生成上。
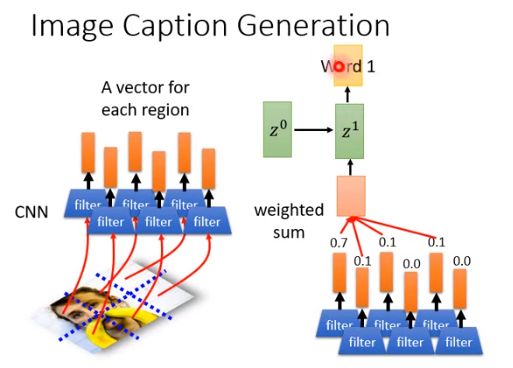
把图片切割成一小块一小块的,每一小块丢进CNN里产生一个向量,在没有attention-base model的时候,一张图片就是一个向量,用了attention-base model之后,一张图片分割成小块,就是一把向量。
然后把\(z^0\)跟这一把向量算一个分数,所有分数加权求和丢到decoder里面,产生word1和第二个key\(z^1\) 。
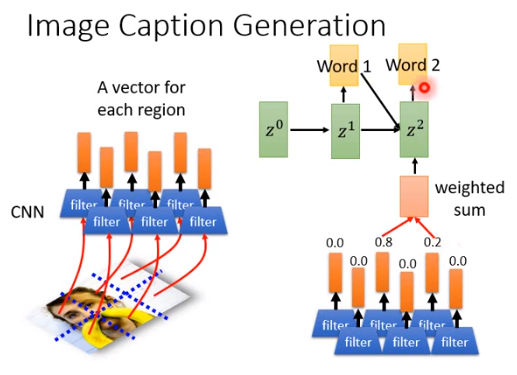
第二个key \(z^1\)和向量再算一次分数,再做加权求和,然后产生word2,以此类推。

根据attention的结果你可以分析,机器在产生一个word的时候到底看到了什么东西。你可以让机器告诉你,它是凭借什么东西或者看到什么东西,才决定写出这样的句子。
比如上图所示,亮点代表特别大的attention,那么第一张图,在飞盘部分的attention特别大,那么机器产生frisbee。第二张图,狗部分的attention特别大,那么产生dog......。最后一张图,长颈鹿周围的attention特别大,所以说看到树然后产生trees。机器不是乱蒙的,它真的知道它在看什么。

当然机器也会犯错,但可能是有道理的错。比如上图,第一张图机器说看到鸟,但其实是两个长颈鹿叠在一起,看起来像鸟和鸟的翅膀。第二张图机器说看到一个人拿着一个钟,其实是衣服上的图案......

上图上方所示,机器产生一个句子 A man and a wowan ride a motorcycle。机器在产生road词汇的时候,attention集中在第三张图......
上图下方机器产生一个句子Someone is frying a fish in a pot。机器看到第二张图才产生someone,看到第一张图才产生pot......
Tips for Generation
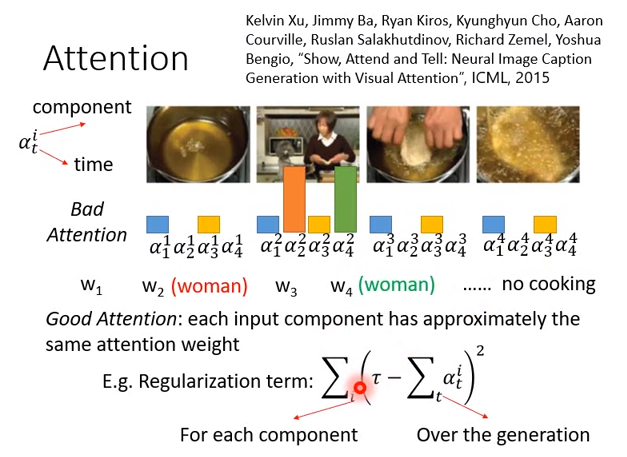
我们可不可以在match的时候(计算attention分数)做一些限制,因为实际上在做attention的时候,会有一些问题。比如上图左上方所示,i是哪一个图,t代表时刻。
- 一开始机器会对4张图都算一个attention分数,然后会产生第一个词汇\(w_1\)
- 在第2个时刻再算一次attention分数,产生词汇\(w_2\)
- 第3个时刻算一次attention分数,产生词汇\(w_3\)
- 第4个时刻算一次attention分数,产生词汇\(w_4\)
如果attention都集中在某一张图上,比如时刻2,时刻4机器都集中在第二张图上,那么都看到women,词汇\(w_2,w_4\)都是women,这样句子就很奇怪。
我们希望机器在看片段的时候,某个时刻在每个片段上的attention是平均的,不应该特别看某个片段。一个做法就是,对attention加一个正则。比如在机器学习中加L1正则的时候,你就希望参数距离0越近越好。
比如上图下方所示的正则,对同一个片段在不同时间点的attention求和(比如\(\alpha_1^2,\alpha_2^2,\alpha_3^2,\alpha_4^2\)求和),希望这个求和值和某一个值(自己定义的)越接近越好。这样某个时刻的attention就不会集中在一个片段上。
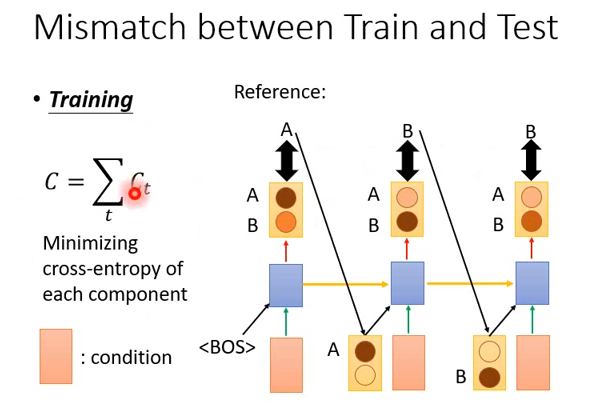
还有另外一个问题是,比如训练的时候,你的目标是ABB。你的学习过程是:
- input一个condition和
,产生一个AB的概率分布,希望这个分布和A越接近越好(即A的概率越大越好) - 接下来input一个conditon和一个字符,产生第二个概率分布,希望这个分布和B接近越好
但是在产生第二个概率分布的时候,input的字符是什么?我们之前说过,在训练的时候,是把正确答案当做第二个input的字符。如果你要的结果是ABB,那么第一个output是A还是B都不重要,我们不关心机器的预测,第二个input的字符一直就是A。
然后最喜欢交叉熵得到参数。
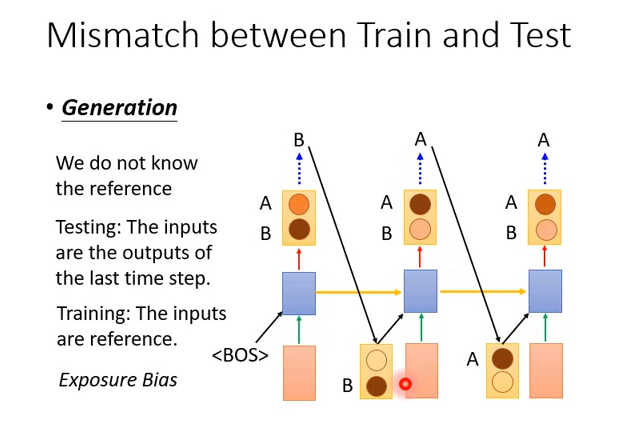
但是在测试的时候,我们对第一个概率分布sample,得到B,那么接下来第二个input字符就是B。你会发现测试的时候,input字符都是机器自己生成的,可能会有错误,但是训练的时候却都是正确的,中间就会有一个暴露误差。我们希望机器学习的时候,训练数据和测试数据的分布是一样的,但是这里却有偏差。
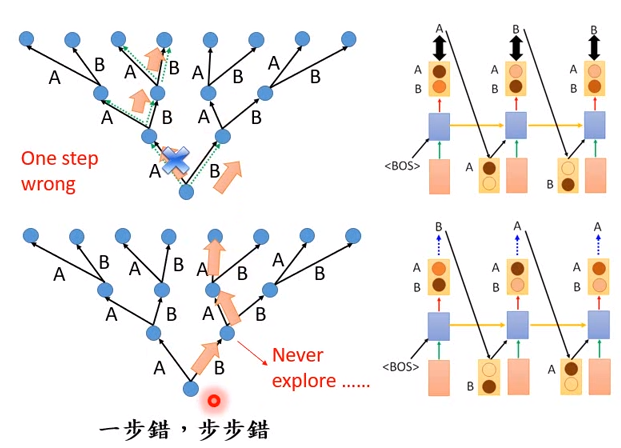
我们看一下训练和测试之间的差别,上面是训练的状况。假设只有两个词汇AB,那么机器产生三个词的可能性就只有8种。
训练时走的只有一条路径,机器犯错会被纠正:
- 时刻1的output 有A和B,但是数据告诉机器要输出A
- 时刻2的output有A和B,告诉机器在已经产生A的情况下,要产生B
- 时刻3的output有A和B,告诉机器在已经产生A和B的情况下,要产生B
测试时每个路径都有可能,如果机器第一步就犯错,那么接下来就都是错的。
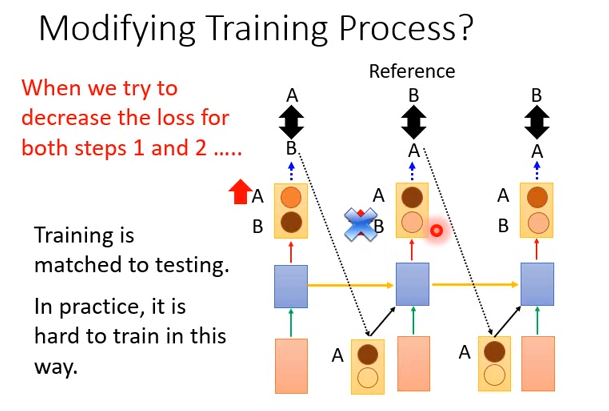
那你可能会说,为什么不在训练的时候用output的结果呢?
如果这样做,参数就很难学习。比如
时刻1的正确答案为A,机器在学习的时候会想办法增加output中A的概率,虽然可能一开始的时候B的概率比较高,导致sample出B。但是在学习中,A的概率会不断增大。
时刻2的正确答案为B,机器就会想办法增大B的概率,但是这是在时刻1的output为B的前提下。
那么随着训练的不断进行,时刻1 A的概率越来越大,直到sample出A,结果反转,那么之前时刻2学习的东西都没有用了,因为都是基于B学习的。
Scheduled Sampling
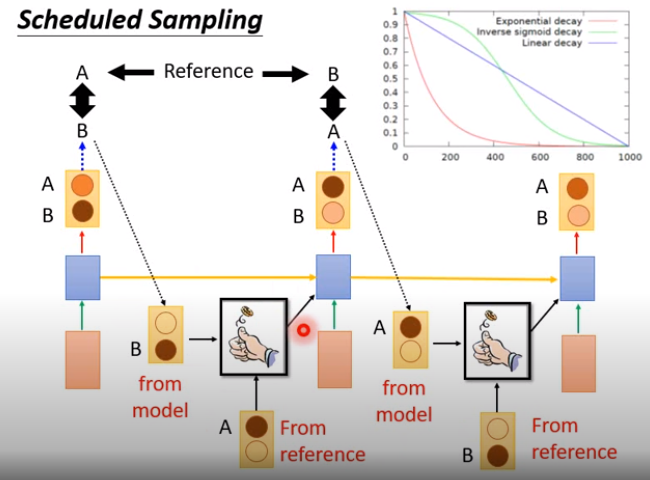
那怎么做呢?
可以取两者的折衷。在下一个时刻会input什么字符,用一个骰子决定,正面去机器的output,反面取正确的答案。
在训练的时候,就可以调骰子的概率,动态决定。一开始的时候,正确答案出现的概率比较高,随着训练的进行,让model出现的概率变高,这是合理的。先让机器学习到一定地步后,一开始的结果已经比较稳定了,再使用model进行训练。
Beam Search
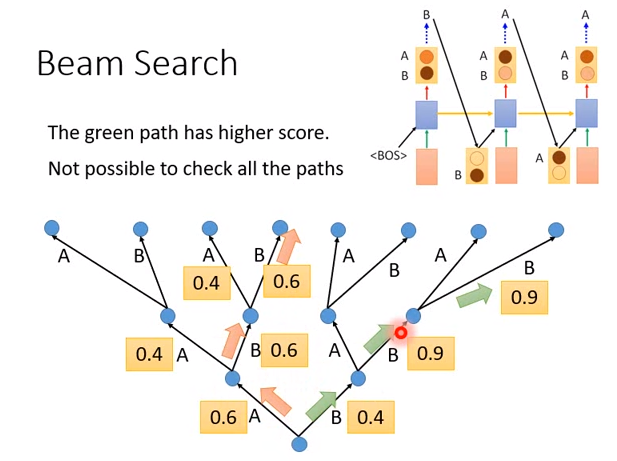
机器每次ouput的都是一个概率。
- 假设时刻1 A的概率是0.6,B的概率是0.4,那我们可能选择A
- 时刻2 A的概率是0.4,B的概率是0.6,我们选择B
- 时刻3 A的概率是0.4,B的概率是0.6,选择B
这种选择的方法结果是ABB,但这真的是概率最大的结果吗?有没有可能时刻1选择B,基于B时刻2的B为0.9,时刻3的概率为0.9,那么0.9*0.9*0.4 >0.6*0.6*0.6,一开始选择B的路径概率更大。
当然训练RNN的时候,你没有办法全局计算,也就没办法知道所有路径的概率。而beam search就是用来克服这个问题的一种方法。
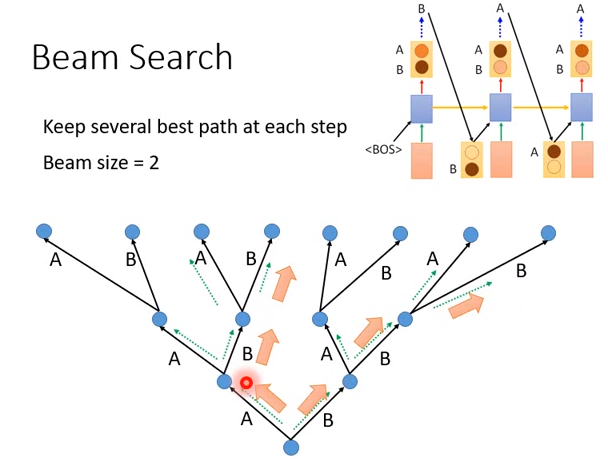
beam search在每一次sequence 生成的时候,都会保留前N个分数最高的可能。比如,假设保留2个分数最高的可能(beam size=2)
- 时刻1有A和B,机器就保留2个结果的分数
- 时刻2在A后面接A或B,B后面也可以接A或B,有4种可能,那么选择最好的2条路径存下来
- 时刻3也有4种可能,选择最好的2条路径保存下来
- 最后在从保存的2中路径中,选择最好的那条
beam search和训练完全无关,只在测试中使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号