第十一章 多线程、多进程和线程池
11.1 python中的GIL
GIL是global interpreter lock(全局解释器锁)。
python中一个线程对应于c语言中的一个线程,python前期为了简单,进行多线程编程的时候,会在解释器上加一把非常大的锁(防止多个线程运行同样的代码,保证线程安全)。
gil使得同一个时刻只有一个线程在一个cpu上执行字节码, 无法将多个线程映射到多个cpu上执行(无法运用多核的优势,运行一个Python进程,不管有多少线程,都只在一个cpu上运行)。
GIL会在适当情况下释放,先看一个例子
#gil global interpreter lock (cpython)
#python中一个线程对应于c语言中的一个线程
#gil使得同一个时刻只有一个线程在一个cpu上执行字节码, 无法将多个线程映射到多个cpu上执行
#gil会根据执行的字节码行数以及时间片释放gil,gil在遇到io的操作时候主动释放
total = 0
def add():
#1. dosomething1
#2. io操作
# 1. dosomething3
global total
for i in range(1000000):
total += 1
def desc():
global total
for i in range(1000000):
total -= 1
import threading
thread1 = threading.Thread(target=add)
thread2 = threading.Thread(target=desc)
thread1.start()
thread2.start()
thread1.join() # 添加到当前主线程下
thread2.join()
print(total)
每运行一次都会产生一个结果
第一次:-154129
第二次:-478261
第三次:-393351
GIL分配给一个线程之后,不是说线程执行完之后才会释放,再把GIL分配给另一个线程。
会在适当的时候释放GIL,这是结合了字节码执行的行数(比如执行了100行,1000行之后会释放),那么另一个线程就可以执行了。如果add函数线程一直占有,那么就会加到100万,然后在运行desc线程,减到0。
GIL的释放也会结合时间片的划分,比如add执行了15ms之后,则把GIL分配给desc。
GIL在遇到IO操作的时候也会释放,那么python在IO操作频繁的多线程工作中就比较适用。
11.2 多线程编程-threading
操作系统能够切换和调度的最小单元是线程,线程是依赖于进程的。比如windows任务管理器的进程,每一个进程下可能会有多个线程。
对于io操作来说,多线程和多进程性能差别不大,对操作系统来说,线程调度比进程调度更轻量。
通过Thread类实例化来进行多线程编程,用爬虫来距离,一个线程爬列表页,把爬到的URL扔到另一个线程里(负责爬取详情页的数据)并解析入库。一个线程爬列表页、一个线程爬详情页,几乎是同时进行的,为什么是同时进行的?我们说过,如果使用多线程编程的话,比如两个线程,对GIL来说,在遇到IO的时候,会将当前GIL释放,并分配给另外一个线程。
爬取列表页属于socket编程(io编程),当请求列表页返回的时候,将GIL释放,马上分配到另外一个线程,因为当前线程在等待网络的返回,等待的同时另一个线程(爬取详情页)开始运行,所以这两个线程其实是并行的。如果不用多线程,那么就是爬取列表页,等待网络返回,再爬取详情页,再等待网络返回,这里时间就白白消耗了。
写一个简单的例子来说明多线程
#对于io操作来说,多线程和多进程性能差别不大
#1.通过Thread类实例化
import time
import threading
def get_detail_html(url):
"""
模拟列表页
"""
print("get detail html started")
time.sleep(2) # 模拟请求
print("get detail html end")
def get_detail_url(url):
"""
模拟详情页
"""
print("get detail url started")
time.sleep(2)
print("get detail url end")
if __name__ == "__main__":
thread1 = threading.Thread(target=get_detail_html,args=("",))
thread2 = threading.Thread(target=get_detail_url,args=("",))
start_time = time.time()
thread1.start()
thread2.start()
print("last time: {}".format(time.time() - start_time)) # 会在主线程运行
get detail html started
get detail url started
last time: 0.0
get detail html end
get detail url end
为什么时间为0,正常来说应该是2。
因为运行py文件的时候,创建了2个线程,但实际上还有一个主线程,thread部分的代码会在子线程运行,但是其他代码会在主线程运行。线程之间是并行的,意味着子线程运行时,主线程也会运行,所以子线程在sleep的时候,print部分已经在运行了。但是主线程并没有退出,因为主线程退出会导致进程关闭,子线程也退出不会打印出"get detail html end"和"get detail url end"。那么衍生出两个需求
1.当主线程退出的时候,子线程kill掉
用到thread.setDaemon(True)
#对于io操作来说,多线程和多进程性能差别不大
#1.通过Thread类实例化
import time
import threading
def get_detail_html(url):
"""
模拟列表页
"""
print("get detail html started")
time.sleep(2) # 模拟请求
print("get detail html end")
def get_detail_url(url):
"""
模拟详情页
"""
print("get detail url started")
time.sleep(2)
print("get detail url end")
if __name__ == "__main__":
thread1 = threading.Thread(target=get_detail_html,args=("",))
thread2 = threading.Thread(target=get_detail_url,args=("",))
thread1.setDaemon(True) # 设置为守护进程,当主线程退出后,关闭子线程
thread2.setDaemon(True)
start_time = time.time()
thread1.start()
thread2.start()
print("last time: {}".format(time.time() - start_time))
get detail html started
get detail url started
last time: 0.0
那如果只设置一个守护进程呢
#对于io操作来说,多线程和多进程性能差别不大
#1.通过Thread类实例化
import time
import threading
def get_detail_html(url):
"""
模拟列表页
"""
print("get detail html started")
time.sleep(2) # 模拟请求
print("get detail html end")
def get_detail_url(url):
"""
模拟详情页
"""
print("get detail url started")
time.sleep(4)
print("get detail url end")
if __name__ == "__main__":
thread1 = threading.Thread(target=get_detail_html,args=("",))
thread2 = threading.Thread(target=get_detail_url,args=("",))
thread2.setDaemon(True)
start_time = time.time()
thread1.start()
thread2.start()
print("last time: {}".format(time.time() - start_time))
get detail html started
get detail url started
last time: 0.0
get detail html end
这意味着thread2是守护进程,主线程等待thread1运行完成后会退出,那么会关闭thread2。
2.等待子线程执行完后,再执行主线程
使用thread.join()
#对于io操作来说,多线程和多进程性能差别不大
#1.通过Thread类实例化
import time
import threading
def get_detail_html(url):
"""
模拟列表页
"""
print("get detail html started")
time.sleep(2) # 模拟请求
print("get detail html end")
def get_detail_url(url):
"""
模拟详情页
"""
print("get detail url started")
time.sleep(4)
print("get detail url end")
if __name__ == "__main__":
thread1 = threading.Thread(target=get_detail_html,args=("",))
thread2 = threading.Thread(target=get_detail_url,args=("",))
thread2.setDaemon(True)
start_time = time.time()
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print("last time: {}".format(time.time() - start_time))
get detail html started
get detail url started
get detail html end
get detail url end
last time: 4.00957727432251
会等到两个子线程执行完成,才会运行主线程。
子线程仍旧在并发。
python中有一种常用的方法来写多线程,就是继承threading.Thread,继承类里可以添加复杂的逻辑
# 通过集成Thread来实现多线程
import time
import threading
class GetDetailHtml(threading.Thread):
def __init__(self, name):
super().__init__(name=name) # name,给线程命名,要加入其他变量可以自己定义
def run(self): # 重写run方法,线程中的逻辑
print("get detail html started")
time.sleep(2)
print("get detail html end")
class GetDetailUrl(threading.Thread):
def __init__(self, name):
super().__init__(name=name) # 多线程编程,要学会调用父类方法
def run(self):
print("get detail url started")
time.sleep(4)
print("get detail url end")
if __name__ == "__main__":
thread1 = GetDetailHtml("get_detail_html")
thread2 = GetDetailUrl("get_detail_url")
start_time = time.time()
thread1.start()
thread2.start()
thread1.join()
thread2.join()
#当主线程退出的时候, 子线程kill掉
print ("last time: {}".format(time.time()-start_time))
get detail html started
get detail url started
get detail html end
get detail url end
last time: 4.006060838699341
11.3 线程间通信-共享变量和Queue
1.线程通信方式-共享变量
一个线程爬取列表页,通过共享变量,让另一个线程爬取详情页
一个问题是列表页抓url比详情页处理url快,一个解决方法是开多个爬取详情页的线程,比如列表页有20个url,那么开20个线程处理这些url,但是20个线程也是一个个运行的,这样并发效率并不高。
使用共享变量可能导致线程不安全,所以要加锁,但不建议使用这种方式
2.通过Queue进行线程间同步
Queue本身是线程安全的,多个线程queue.get时不会造成线程错误,因为get里面有用到锁机制。
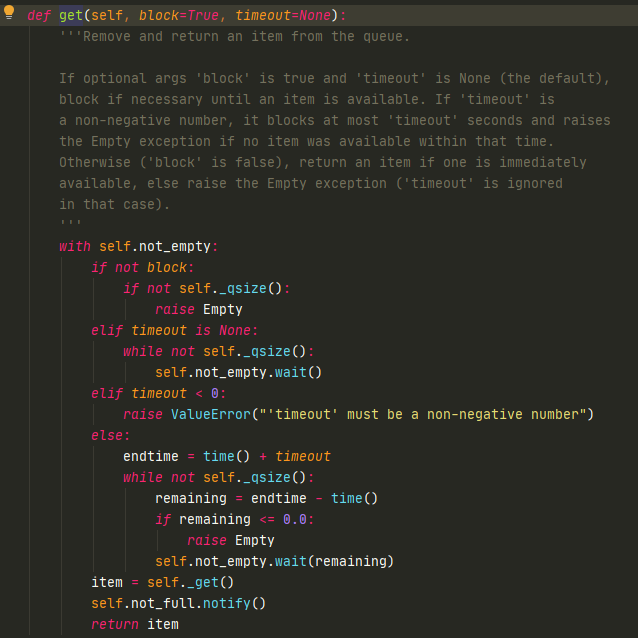
真正用到的self._get()并没有使用锁
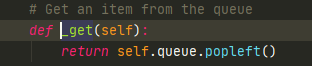

实际上使用的是deque,deque是python中的双端队列,是线程安全的。
python Queue有一些常用方法(都是线程安全的):
put(放),get(取)
put_nowait,get_nowait(在put,get函数中加了block参数)
qsize可以获取到队列长度,empty队列是否为空,full队列是否已满
join(会阻塞主线程,等待子线程完成),task_done会在主线程退出的时候,把子线程kill掉
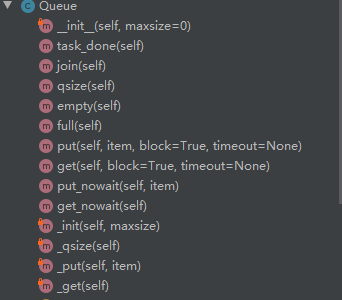
#通过queue的方式进行线程间同步
from queue import Queue
import time
import threading
def get_detail_html(queue):
#爬取文章详情页
while True:
url = queue.get() # get是阻塞的方法,如果队列为空则一直停在这
print("get detail html started")
time.sleep(2)
print("get detail html end")
def get_detail_url(queue):
# 爬取文章列表页
while True:
print("get detail url started")
time.sleep(4)
for i in range(20):
queue.put("http://projectsedu.com/{id}".format(id=i)) #队列满时会阻塞在这里,等到有空间为止
print("get detail url end")
if __name__ == "__main__":
detail_url_queue = Queue(maxsize=1000) # 允许消息队列最多多少个,越大对内存要求越高
thread_detail_url = threading.Thread(target=get_detail_url, args=(detail_url_queue,))
thread_detail_url.start()
for i in range(10): # 开10个线程
html_thread = threading.Thread(target=get_detail_html, args=(detail_url_queue,))
html_thread.start()
start_time = time.time()
detail_url_queue.task_done()
detail_url_queue.join()
#当主线程退出的时候, 子线程kill掉
print ("last time: {}".format(time.time()-start_time))
11.4 线程同步(Lock,RLock)
之前GIL的例子中,会发现结果每次都不一样,为什么会出现这种情况?
首先看个字节码的例子:
def add1(a):
a += 1
def desc1(a):
a -= 1
"""
a是全局变量
1.load a
2.load 1
3.+
4.赋值给a
"""
import dis
print(dis.dis(add1))
print(dis.dis(desc1))
19 0 LOAD_FAST 0 (a) #将a load到内存中
2 LOAD_CONST 1 (1) #把1 load到内存中
4 INPLACE_ADD # 相加
6 STORE_FAST 0 (a) # 将相加结果赋值给a
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
None
22 0 LOAD_FAST 0 (a)
2 LOAD_CONST 1 (1)
4 INPLACE_SUBTRACT # 减法
6 STORE_FAST 0 (a)
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
None
在同时执行add1和desc1字节码的时候,每执行一行,GIL都有可能被释放掉(时间片满了或者字节码行数满了),所以在4行中的任意一行都有可能被切换到另一个线程。所以两个线程都有可能操作a全局变量。
可以来模拟一个极端地切换过程
add 真实的GIL步骤
"""
1.load a a=0 1.在add第一行
2.load 1 1 3.load 1
3.+ 1 5.a加上1
4.赋值给a a=1 7.赋值a=1
"""
desc
"""
1.load a a=0 2.切换到desc第一行
2.load 1 1 4.load 1
3.+ 1 6.load 1
4.赋值给a a=1 8.赋值a=-1
"""
那么最后a的结果要么为1,要么为-1,不会是0。
有什么解决方法呢,可以让一个代码段运行的时候,另一个代码段停止运行,这引出了线程同步机制。
python中有一个同步的工具-锁,可以把代码段锁住,只有锁住的代码段才可以运行,释放锁之后才能让其他代码段执行。
那么怎么用一个锁,先要声明一个锁并获取这把锁,看这个锁是不是正在使用,如果没有使用则传递进要执行的代码段。
from threading import Lock, RLock, Condition
total = 0
lock = Lock() # 声明一把锁
def add():
global lock # 两边都要加锁,因为在竞争GIL
global total
for i in range(1000000):
lock.acquire() # 获取锁
total += 1
lock.release() # 释放锁
def desc():
global total
global lock # 两边都要加锁,因为在竞争GIL
for i in range(1000000):
lock.acquire() # 获取到锁,但是锁没有被释放,就会阻塞在这直到锁释放
total -= 1
lock.release()
import threading
thread1 = threading.Thread(target=add)
thread2 = threading.Thread(target=desc)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print(total)
0
但是使用锁会影响性能,获取锁和释放锁都需要时间。
而且锁会引起死锁
其中一种情况是:
def add():
global lock
global total
for i in range(1000000):
lock.acquire() # 获取了一把锁
lock.acquire() # 由于锁未释放,就阻塞在这,造成死锁
total += 1
lock.release()
lock.release()
def add(lock):
global total
for i in range(1000000):
lock.acquire() # 获取锁
dosomethong(lock) # 这里面也获取了一把锁,也会导致死锁
total += 1
lock.release() # 释放锁
def dosomethong(lock):
lock.acquire() # 获取锁
# do something
lock.release() # 释放锁
还有一种情况是互相等待:
"""
A(a、b) #A线程要获取资源要acquire a和acquire b
acquire (a)
acquire (b)
B(a、b) # B线程要先拿b再拿a
acquire (b)
acquire (a)
"""
A拿到a的同时B拿到b,A要等待B释放b,B要等待A释放a
python提供了一个可重入锁RLock来解决死锁问题
在同一个线程里面,可以连续调用多次acquire, 一定要注意acquire的次数要和release的次数相等
from threading import Lock, RLock, Condition #可重入的锁
lock = RLock() # 一定要在同一个线程里面,不同线程还是竞争的关系
def add():
global lock
global total
for i in range(1000000):
lock.acquire()
lock.acquire()
total += 1
lock.release()
lock.release()
11.5 线程同步-condition
condition(条件变量)是一个用于复杂线程间同步的锁
我们举个例子来看看condition有什么用处
小爱同学和天猫精灵之间的一段对话

把小爱和天猫精灵看做两个线程,如果用之前的Lock来做
import threading
class XiaoAi(threading.Thread):
def __init__(self, lock):
super().__init__(name="小爱")
self.lock = lock
def run(self):
self.lock.acquire()
print("{} : 在 ".format(self.name))
self.lock.release()
self.lock.acquire()
print("{} : 好啊 ".format(self.name))
self.lock.release()
class TianMao(threading.Thread):
def __init__(self, lock):
super().__init__(name="天猫精灵")
self.lock = lock
def run(self):
self.lock.acquire()
print("{} : 小爱同学 ".format(self.name)) # 天猫精灵先说话
self.lock.release()
self.lock.acquire()
print("{} : 我们来对古诗吧 ".format(self.name))
self.lock.release()
if __name__ == "__main__":
lock = threading.Lock()
xiaoai = XiaoAi(lock)
tianmao = TianMao(lock)
tianmao.start()
xiaoai.start()
天猫精灵 : 小爱同学
天猫精灵 : 我们来对古诗吧
小爱 : 在
小爱 : 好啊
可以看到不是我们想要的结果,tianmao在xiaoai没有start之前,将代码逻辑全部执行完了。
GIL有可能先在天猫精灵切换,之后再在小爱切换。
如果要保证顺序,就要使用条件变量,里面有一些参数可以让天猫精灵说一句后,通知小爱说
先看下condition有什么方法
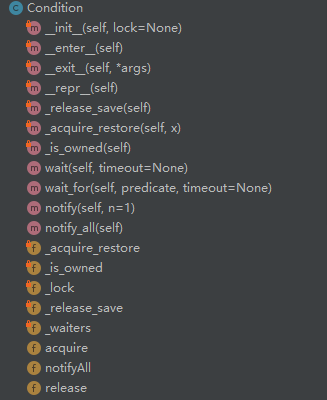
实现了__enter__和__exit__方法,可以让我们用with语句使用。
还有比较重要的方法:
acquire(__enter__中会调用acquire方法,所以with的时候就会调用)
condition内部还是使用的RLock,调用的acquire方法
还有release方法,调用的也是RLock的release方法。
其中wait和notify是condition的精髓
wait函数允许我们等待某个条件变量的通知,比如启动小爱同学时让它等待某个信号,在天猫精灵线程里,说完一句话后,让它发起一个notify,通知调用了wait的线程启动。
那么就变成天猫说一句话后,发起一个通知给小爱,天猫进入等待状态,小爱接收到通知,说一句话后发起另一个通知给天猫,小爱进入等待。
import threading
#通过condition完成协同读诗
class XiaoAi(threading.Thread):
def __init__(self, cond):
super().__init__(name="小爱")
self.cond = cond
def run(self):
with self.cond:
self.cond.wait() # wait一定要在acquire之后
print("{} : 在 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 好啊 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 君住长江尾 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 共饮长江水 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 此恨何时已 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 定不负相思意 ".format(self.name))
self.cond.notify()
class TianMao(threading.Thread):
def __init__(self, cond):
super().__init__(name="天猫精灵")
self.cond = cond
def run(self):
with self.cond: # 一定要用with语句
print("{} : 小爱同学 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 我们来对古诗吧 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 我住长江头 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 日日思君不见君 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 此水几时休 ".format(self.name))
self.cond.notify()
self.cond.wait()
print("{} : 只愿君心似我心 ".format(self.name))
self.cond.notify()
self.cond.wait()
if __name__ == "__main__":
from concurrent import futures
cond = threading.Condition()
xiaoai = XiaoAi(cond)
tianmao = TianMao(cond)
#启动顺序很重要
#在调用with cond之后才能调用wait或者notify方法
xiaoai.start()
tianmao.start()
天猫精灵 : 小爱同学
小爱 : 在
天猫精灵 : 我们来对古诗吧
小爱 : 好啊
天猫精灵 : 我住长江头
小爱 : 君住长江尾
天猫精灵 : 日日思君不见君
小爱 : 共饮长江水
天猫精灵 : 此水几时休
小爱 : 此恨何时已
天猫精灵 : 只愿君心似我心
小爱 : 定不负相思意
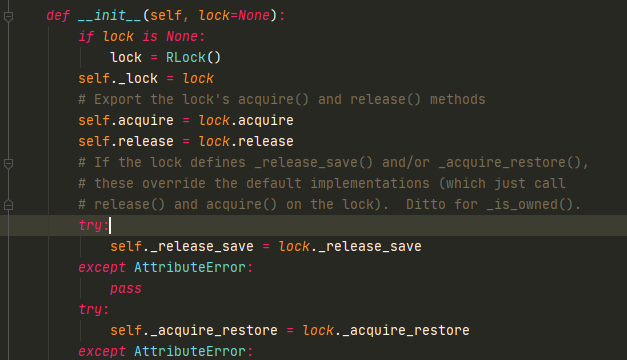
看下cond的源码
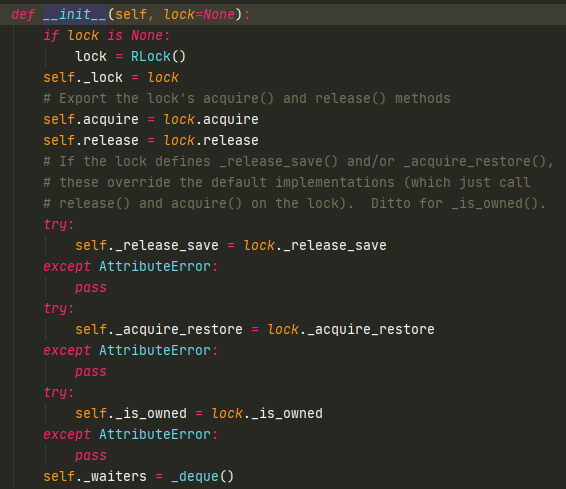
condition内部会有一把可重入锁(RLock,避免不同condition出现竞争),是针对condition的,调用with的时候,调用_ enter 方法(获取锁)和 exit _方法(释放锁)。
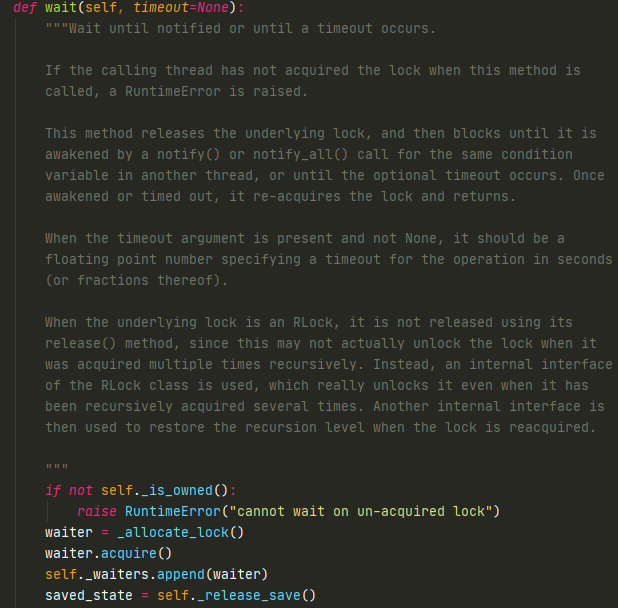
运行wait的时候,获取一把Lock锁放在waiters队列中,释放掉RLock锁,然后又会创建一把RLock锁
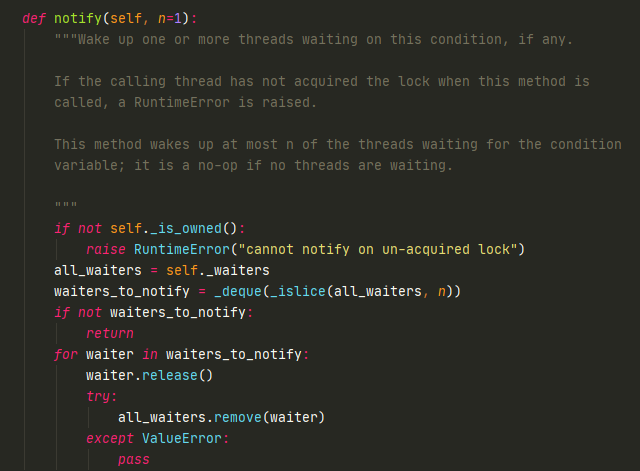
notify会在waiters中弹出一把Lock锁然后释放掉
-
小爱中调用with,获取小爱Rlock锁
-
天猫中调用with,获取天猫RLock锁
-
小爱运行wait,释放小爱Rlock内锁,切换到天猫RLock内锁,在waiters中添加Lock锁(用来阻塞线程),再添加小爱RLock锁(用来切换线程),此时小爱阻塞(等待小爱Lock释放)
-
天猫print “小爱同学”
-
天猫运行notify(释放waiters中的小爱Lock锁)
-
天猫调用wait,释放天猫RLock锁,切换到小爱RLock锁,在waiters中添加天猫Lock锁,阻塞天猫线程,然后再次添加Rlock锁等待下次切换
-
小爱print "在"
-
小爱运行notify(释放waiters的天猫Lock锁,相当于唤醒天猫Rlock锁,等待切换)
-
小爱运行wait,释放小爱RLock锁,切换到天猫Rlock锁,在waiters中添加小爱Lock锁,阻塞小爱线程,然后再次添加RLock等待唤醒
可以看到,wait用来切换和阻塞当前线程,notify用来唤醒被阻塞线程。
11.6 线程同步-semaphore
Semaphore 是用于控制进入数量的锁
例如文件,有读、写,写一般只适用于一个线程,读可以运行多个线程
写爬虫时,希望控制并发数量,semaphore就很有用
import threading
import time
class HtmlSpider(threading.Thread):
def __init__(self, url, sem):
super().__init__()
self.url = url
self.sem = sem
def run(self):
time.sleep(2)
print("got html text success")
self.sem.release() # 在这里释放掉,sem+1
class UrlProducer(threading.Thread):
def __init__(self, sem):
super().__init__()
self.sem = sem
def run(self):
for i in range(20):
self.sem.acquire() #调用一次时,sem维护的数量-1
html_thread = HtmlSpider("https://baidu.com/{}".format(i), self.sem)
html_thread.start()
# 如果这里release,无法起到控制线程数量的作用
if __name__ == "__main__":
sem = threading.Semaphore(3) # 允许3个并发
url_producer = UrlProducer(sem)
url_producer.start()
got html text success
got html text success
got html text success
---------------------
got html text success
got html text success
got html text success
---------------------
got html text success
got html text success
got html text success
会三个三个输出
Semaphore内部是使用condition完成的
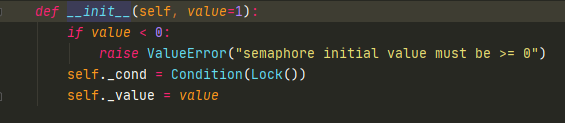

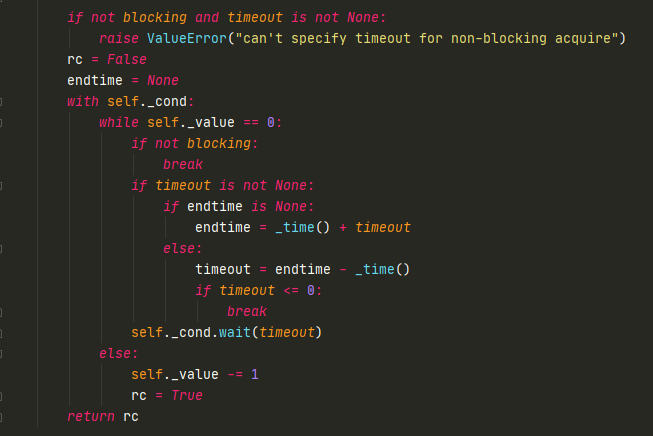
with condition,在里面可以做条件判断,如果不满足则进入wait,如果value>0,则-1。
11.7 ThreadPoolExecutor线程池
为什么要线程池,比如获取html的时候有并发,我们希望最高并发是3个,那么我们就需要维护一个semaphore。那有没有一个包,可以让我们管理线程更加容易?可以有一些功能
- 可以方便管理线程数量
- 有一个url之后,不是等待,而是扔到线程池中,由线程池自己调度
线程池还有很多其他功能,比如在主线程中可以获取某一个线程的状态或者某一个任务的状态,以及返回值,再比如当一个线程完成的时候我们主线程能立即知道。
python中用来线程池编程的包是concurrent.futures,futures可以让多线程和多进程编码接口一致
from concurrent.futures import ThreadPoolExecutor, as_completed, wait, FIRST_COMPLETED
import time
def get_html(times):
time.sleep(times) # 模拟html请求
print("get page {} success".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2) # 实例化一个线程池,max_workers:同时运行的线程个数
# 通过submit函数提交执行的函数到线程池中, submit是立即返回,是非阻塞的,主线程中可以立马执行
# task2 sleep2,那么task2先运行
# 返回的是futures类对象
task1 = executor.submit(get_html, (3)) # (3)sleep3秒
task2 = executor.submit(get_html, (2)) # (2)sleep2秒
#done方法用于判定某个任务是否完成
print(task1.done()) # 判断是否执行成功,因为会sleep 3秒,所以是False
print(task2.cancel()) # 取消掉,如果任务在执行中,则无法取消
time.sleep(4)
print(task1.done()) #
# result方法可以获取task的执行结果
print(task1.result()) # result是阻塞的方法
False
False
get page 2 success
get page 3 success
True
3
如果不是提交具体某一个任务,而是批量提交
先看下as_completed函数,是一个生成器,会把已经完成的task yield出来,由于as_completed是在主线程执行的,如果执行到对as_completed的for循环,因为线程中的任务是异步的,所以可能有一部分已经完成了,那么as_completed就会yield 已经成功的task,然后等待执行中的task完成并再次yield。
from concurrent.futures import ThreadPoolExecutor, as_completed, wait, FIRST_COMPLETED
import time
def get_html(times):
time.sleep(times) # 模拟html请求
print("get page {} success".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2) # 实例化一个线程池,max_workers:同时运行的线程个数
#要获取已经成功的task的返回
urls = [3,2,4] # 模拟URL 请求时间
all_task = [executor.submit(get_html, (url)) for url in urls]
for future in as_completed(all_task):
data = future.result()
print("get {} page".format(data))
get page 2 success # 子线程打印
get 2 page # 主线程打印
get page 3 success
get 3 page
get page 4 success
get 4 page
还可以通过executor.map获取已完成task的结果,map是yield result
from concurrent.futures import ThreadPoolExecutor, as_completed, wait, FIRST_COMPLETED
import time
def get_html(times):
time.sleep(times) # 模拟html请求
print("get page {} success".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2) # 实例化一个线程池,max_workers:同时运行的线程个数
#通过executor的map获取已经完成的task的值
urls = [3,2,4] # 可以提交任意多个,虽然线程池只允许同时运行2个
for data in executor.map(get_html, urls): # 对url一一执行get_html函数
print("get {} page".format(data))
get page 2 success
get page 3 success
get 3 page # 打印顺序和Url中的顺序一致
get 2 page
get page 4 success
get 4 page
wait 可以让主线程阻塞,指定某些task完成后才继续执行
from concurrent.futures import ThreadPoolExecutor, as_completed, wait, FIRST_COMPLETED
import time
def get_html(times):
time.sleep(times) # 模拟html请求
print("get page {} success".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2) # 实例化一个线程池,max_workers:同时运行的线程个数
urls = [3,2,4] # 可以提交任意多个,虽然线程池只允许同时运行2个
all_task = [executor.submit(get_html, (url)) for url in urls]
wait(all_task) # wait 可以让主线程阻塞,指定某些task完成后才继续执行
print("main")
get page 2 success
get page 3 success
get page 4 success
main
from concurrent.futures import ThreadPoolExecutor, as_completed, wait, FIRST_COMPLETED
import time
def get_html(times):
time.sleep(times) # 模拟html请求
print("get page {} success".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2) # 实例化一个线程池,max_workers:同时运行的线程个数
urls = [3,2,4] # 可以提交任意多个,虽然线程池只允许同时运行2个
all_task = [executor.submit(get_html, (url)) for url in urls]
wait(all_task,return_when=FIRST_COMPLETED) # wait 可以让主线程阻塞,指定某些task完成后才继续执行
print("main")
get page 2 success
main
get page 3 success
get page 4 success
11.8 ThreadPoolExecutor源码分析
from concurrent.futures import Future
Future 很重要,很多地方都被叫做未来对象,因为submit之后返回Future 对象,有可能任务没有完成,但会在将来某个时候完成。也可以叫做task返回容器,拿到Future 对象,就可以知道某个task的执行状况。那如何更新task状况和什么时候更新task?
Future 这种设计模式在进程池中也有,以及协程也是这个设计理念。python为了提高代码可维护性,会尽量将多线程,多进程和协程都采用同一种设计模式。
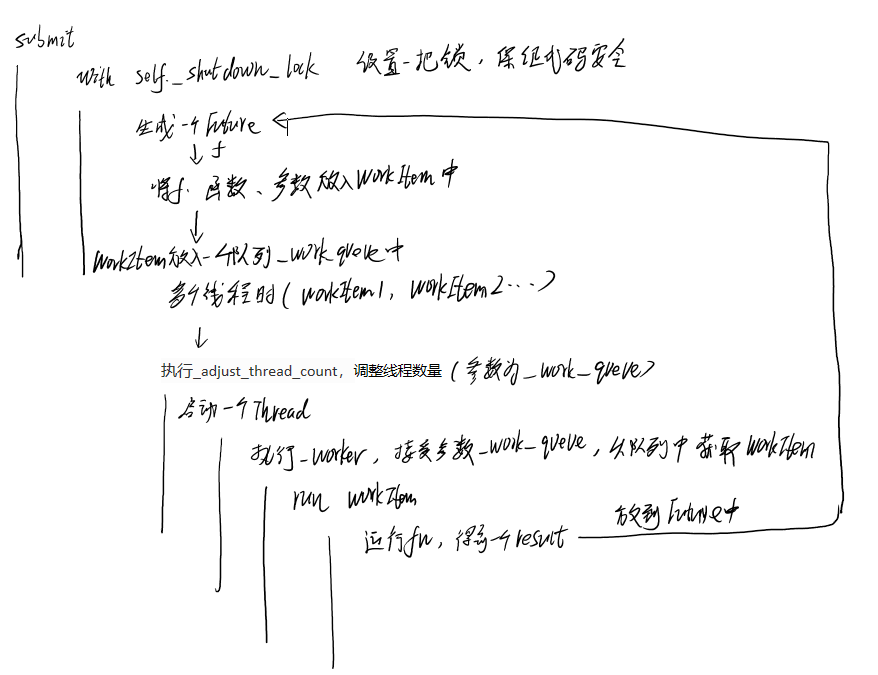
我们看下ThreadPoolExecutor的submit方法
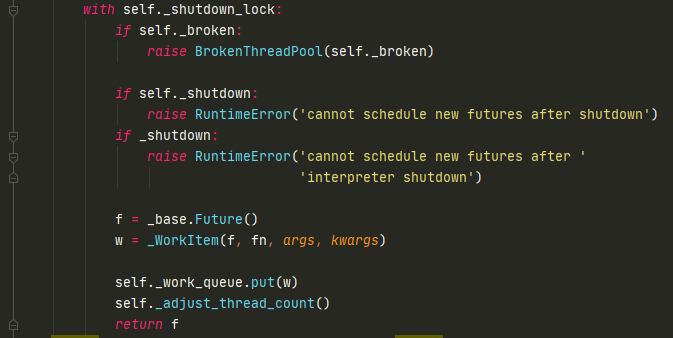
self._shutdown_lock是个锁,保证这段代码安全。
我们提交任务到线程池的时候,会生成一个Future对象,最后return,关键是怎么传递给线程。
生成Future对象之后,会调用_WorkItem类,这个类会将Future放到WorkItem中,所以WorkItem才是线程池的执行单元(放进Future、函数、参数)。然后会把WorkItem放到线程池的_work_queue中(一个队列),然后_adjust_thread_count会调整线程数量。
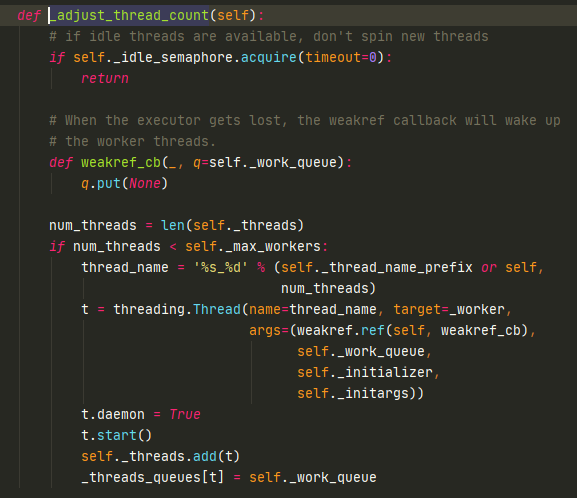
_adjust_thread_count中,会判断线程池中启动了多少线程,如果线程数量少于线程池最大数量,那么会立马启动一个Thread,并加入到内部的_threads(一个set)。因此在一开始的时候,会一直启动线程,直到最大数量。
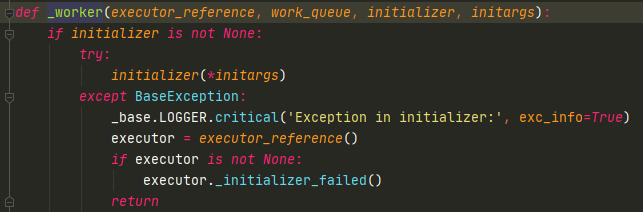
Thread中执行的是_worker,接受参数work_queue,就是_adjust_thread_count中的self._work_queue。
一开始WorkItem被放到_work_queue中,所以Thread启动的时候,可以获取到WorkItem(提交的任务)。如果线程池数量为2,那就会起两个线程,读取同一个_work_queue
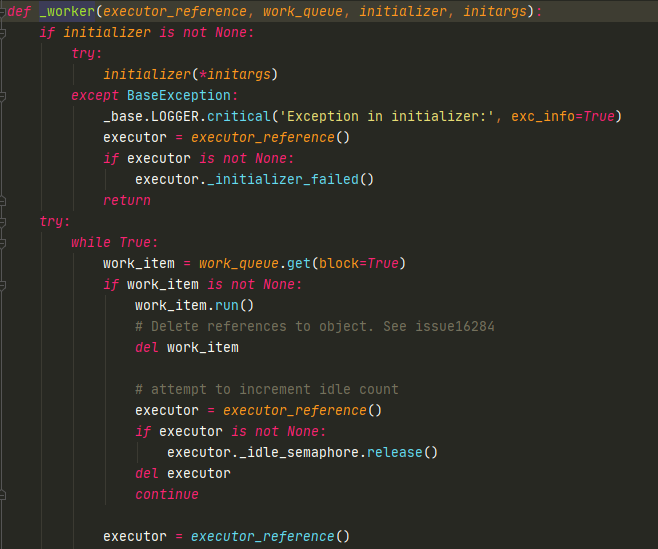
之后会run WorkItem,那么在run什么东西?
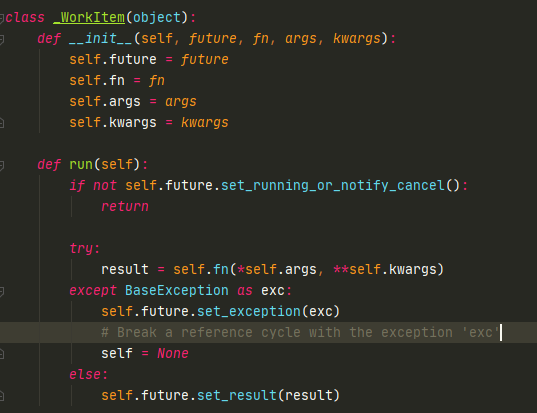
WorkItem里面有个参数fn,run这个函数后得到一个result,然后把result设置到Future中
子线程运行_worker,会不断执行WorkItem的run,然后把结果设置到Future中,返回给主线程调用
11.9 多线程和多进程对比
由于python中有GIL锁,所以python多线程无法利用多核的优势,那么对于耗cpu的操作,用多线程无法并行,这时可以使用多进程编程。
对io操作来说,可以使用多线程编程,这时不使用多进程的原因是因为进程切换代价高。
# 1. 对于耗费cpu的操作,多进程优于多线程
# 主要是一些计算,比如图像处理,数学运算,机器学习算法,比特币挖矿
import time
from concurrent.futures import ThreadPoolExecutor, as_completed,Future
def fib(n):
if n<=2:
return 1
return fib(n-1)+fib(n-2)
if __name__ == "__main__":
with ThreadPoolExecutor(3) as executor:
all_task = [executor.submit(fib, (num)) for num in range(25,40)]
start_time = time.time()
for future in as_completed(all_task):
data = future.result()
print("exe result: {}".format(data))
print("last time is: {}".format(time.time()-start_time))
exe result: 121393
exe result: 75025
exe result: 196418
exe result: 514229
exe result: 317811
exe result: 832040
exe result: 1346269
exe result: 2178309
exe result: 3524578
exe result: 5702887
exe result: 9227465
exe result: 14930352
exe result: 24157817
exe result: 39088169
exe result: 63245986
last time is: 30.834314346313477
# 1. 对于耗费cpu的操作,多进程优于多线程
# 主要是一些计算,比如图像处理,数学运算,机器学习算法,比特币挖矿
import time
from concurrent.futures import ProcessPoolExecutor
from concurrent.futures import ThreadPoolExecutor, as_completed
def fib(n):
if n<=2:
return 1
return fib(n-1)+fib(n-2)
if __name__ == "__main__":
with ProcessPoolExecutor(3) as executor:
all_task = [executor.submit(fib, (num)) for num in range(25,40)]
start_time = time.time()
for future in as_completed(all_task):
data = future.result()
print("exe result: {}".format(data))
print("last time is: {}".format(time.time()-start_time))
exe result: 75025
exe result: 121393
exe result: 196418
exe result: 317811
exe result: 514229
exe result: 832040
exe result: 1346269
exe result: 2178309
exe result: 3524578
exe result: 5702887
exe result: 9227465
exe result: 14930352
exe result: 24157817
exe result: 39088169
exe result: 63245986
last time is: 16.645468711853027
对于io操作来说,多线程优于多进程
# 1. 对于耗费cpu的操作,多进程优于多线程
# 主要是一些计算,比如图像处理,数学运算,机器学习算法,比特币挖矿
import time
from concurrent.futures import ProcessPoolExecutor
from concurrent.futures import ThreadPoolExecutor, as_completed
#2. 对于io操作来说,多线程优于多进程
def random_sleep(n):
time.sleep(n)
return n
if __name__ == "__main__":
with ThreadPoolExecutor(3) as executor:
all_task = [executor.submit(random_sleep, (num)) for num in [2]*30]
start_time = time.time()
for future in as_completed(all_task):
data = future.result()
print("exe result: {}".format(data))
print("last time is: {}".format(time.time()-start_time))
last time is: 20.112141847610474
# 1. 对于耗费cpu的操作,多进程优于多线程
# 主要是一些计算,比如图像处理,数学运算,机器学习算法,比特币挖矿
import time
from concurrent.futures import ProcessPoolExecutor
from concurrent.futures import ThreadPoolExecutor, as_completed
#2. 对于io操作来说,多线程优于多进程
def random_sleep(n):
time.sleep(n)
return n
if __name__ == "__main__":
with ProcessPoolExecutor(3) as executor:
all_task = [executor.submit(random_sleep, (num)) for num in [2]*30]
start_time = time.time()
for future in as_completed(all_task):
data = future.result()
print("exe result: {}".format(data))
print("last time is: {}".format(time.time()-start_time))
last time is: 21.29654049873352
11.10 multiprocessing 多进程编程
进程间的数据是隔离的。
ProcssPoolExecutor是进行多进程编程的首选。
还有一个包,multiprocessing,比ProcssPoolExecutor更加底层,ProcssPoolExecutor用的是multiprocessing的方法。
import multiprocessing
#多进程编程
import time
def get_html(n):
time.sleep(n)
print("sub_progress success")
return n
if __name__ == "__main__": #在windows中必须这么写
progress = multiprocessing.Process(target=get_html, args=(2,))
print(progress.pid) # 没有start之前是没有ID的
progress.start()
print(progress.pid) # 可以获取进程ID
progress.join()
print("main progress end")
None
10896
sub_progress success
main progress end
可以看到和多线程使用接口差不多。
接下来使用multiprocessing的进程池
import multiprocessing
#多进程编程
import time
def get_html(n):
time.sleep(n)
print("sub_progress success")
return n
if __name__ == "__main__": #在windows中必须这么写
pool = multiprocessing.Pool(multiprocessing.cpu_count()) # cpu核心数量
result = pool.apply_async(get_html, args=(3,)) # 异步提交一个任务
pool.close() # 一定要讲pool关闭,不再接受新任务
pool.join() # 等待所有任务执行完成
print(result.get()) # get方法返回result的值
sub_progress success
3
这是单个,也可以多个
import multiprocessing
#多进程编程
import time
def get_html(n):
time.sleep(n)
print("sub_progress success")
return n
if __name__ == "__main__": #在windows中必须这么写
pool = multiprocessing.Pool(multiprocessing.cpu_count()) # cpu核心数量
for result in pool.imap(get_html, [1,5,3]):
print("{} sleep success".format(result))
sub_progress success
1 sleep success
sub_progress success
sub_progress success
5 sleep success
3 sleep success
完成的顺序和添加的顺序是一样的,类似于线程池的map
import multiprocessing
#多进程编程
import time
def get_html(n):
time.sleep(n)
print("sub_progress success")
return n
if __name__ == "__main__": #在windows中必须这么写
pool = multiprocessing.Pool(multiprocessing.cpu_count()) # cpu核心数量
for result in pool.imap_unordered(get_html, [1,5,3]):
print("{} sleep success".format(result))
sub_progress success
1 sleep success
sub_progress success
3 sleep success
sub_progress success
5 sleep success
imap_unordered是谁先完成先打印谁
11.11 进程间通信-Queue,Pipe,Manager
进程间通信和线程间通信有不一样的地方,也有相同的地方。
不一样的地方是,多线程中的类和锁在多进程中是不能用的。
多进程需要用multiprocessing中的Queue
from multiprocessing import Process,Queue
import time
def producer(queue):
queue.put("a")
time.sleep(2)
def consumer(queue):
time.sleep(2)
data = queue.get()
print(data)
if __name__ == "__main__":
queue = Queue(10)
my_producer = Process(target=producer, args=(queue,))
my_consumer = Process(target=consumer, args=(queue,))
my_producer.start()
my_consumer.start()
my_producer.join()
my_consumer.join()
a
那是否可以用共享变量呢?
from multiprocessing import Process,Queue
import time
def producer(a):
a += 100
time.sleep(2)
def consumer(a):
time.sleep(2)
print(a)
if __name__ == "__main__":
a = 1
my_producer = Process(target=producer, args=(a,))
my_consumer = Process(target=consumer, args=(a,))
my_producer.start()
my_consumer.start()
my_producer.join()
my_consumer.join()
1
结果仍然为1,所以共享全局变量不能适用于多进程编程,可以适用于多线程
进程间通信可以用multiprocessing中的queue,但不能用于pool进程池
from multiprocessing import Process,Queue,Pool
import time
def producer(queue):
queue.put("a")
time.sleep(2)
def consumer(queue):
time.sleep(2)
data = queue.get()
print(data)
if __name__ == "__main__":
queue = Queue(10)
pool = Pool(2)
pool.apply_async(producer, args=(queue,))
pool.apply_async(consumer, args=(queue,))
pool.close()
pool.join()
multiprocessing中的queue用在pool进程池没有任何输出
pool中的进程间通信需要使用manager中的queue
from multiprocessing import Process,Manager,Pool
import time
def producer(queue):
queue.put("a")
time.sleep(2)
def consumer(queue):
time.sleep(2)
data = queue.get()
print(data)
if __name__ == "__main__":
queue = Manager().Queue(10) # 需要对Manager进行实例化
pool = Pool(2)
pool.apply_async(producer, args=(queue,))
pool.apply_async(consumer, args=(queue,))
pool.close()
pool.join()
a
进程间通信还可以使用管道Pipe,是简化版的queue
from multiprocessing import Pipe,Process
import time
# 通过pipe实现进程间通信
# pipe的性能高于queue
def producer(pipe):
pipe.send("bobby")
def consumer(pipe):
print(pipe.recv())
if __name__ == "__main__":
recevie_pipe, send_pipe = Pipe() # 接受,发送
#pipe只能适用于两个进程
my_producer= Process(target=producer, args=(send_pipe, ))
my_consumer = Process(target=consumer, args=(recevie_pipe,))
my_producer.start()
my_consumer.start()
my_producer.join()
my_consumer.join()
bobby
虽然进程间的变量是隔离的,但是在某些情况下我们希望能在进程间维护一个公共的内存模块
我们可以使用Manage().dict(),Manage中创建的python数据类型都有
from multiprocessing import Pipe,Process,Manager
import time
def add_data(p_dict, key, value):
p_dict[key] = value
if __name__ == "__main__":
progress_dict = Manager().dict()
from queue import PriorityQueue
first_progress = Process(target=add_data, args=(progress_dict, "bobby1", 22))
second_progress = Process(target=add_data, args=(progress_dict, "bobby2", 23))
first_progress.start()
second_progress.start()
first_progress.join()
second_progress.join()
print(progress_dict)
{'bobby1': 22, 'bobby2': 23}
可以使用Manage().dict()进行数据共享,但是要注意数据同步


· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· [.NET]调用本地 Deepseek 模型
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 全网最简单!3分钟用满血DeepSeek R1开发一款AI智能客服,零代码轻松接入微信、公众号、小程
· .NET 10 首个预览版发布,跨平台开发与性能全面提升
· 《HelloGitHub》第 107 期
· 全程使用 AI 从 0 到 1 写了个小工具
· 从文本到图像:SSE 如何助力 AI 内容实时呈现?(Typescript篇)