第九章 迭代器和生成器
9.1 python的迭代协议
#什么是迭代协议
#迭代器是什么? 迭代器是访问集合内元素的一种方式, 一般用来遍历数据
#迭代器和以下标的访问方式不一样, 迭代器是不能返回的, 迭代器提供了一种产生惰性数据的方式
#[]下标的方式,原理是__getitem__ ,例如list等可迭代的类型都实现了迭代协议(__iter__这个方法)
from collections.abc import Iterable, Iterator
a = [1,2]
iter_rator = iter(a)
print (isinstance(a, Iterable)) # 是一个可迭代对象
print (isinstance(iter_rator, Iterator)) # 但不是一个迭代器
True
False
python中能完成for循环,是背后的迭代器在起作用。
生成器背后也是迭代器,访问数据的时候才去获取数据,和list不同。
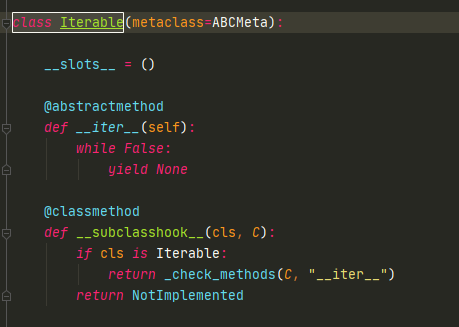
__iter__方法是Iterable的一个重要的魔法函数,只要实现了__iter__方法,那么就是一个可迭代类型。
我们的重点是Iterator(迭代器)
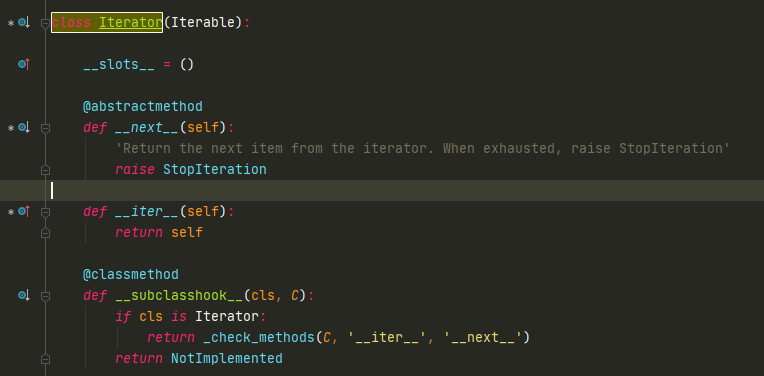
Iterator继承了Iterable这个抽象基类,并且加了一个抽象方法__next__(获取下一个元素必须要实现的方法)。所以Iterator有两个必须要实现的魔法函数,一个是Iterable里的__iter__(实现迭代协议),和__next__(返回下一个数据),从迭代器访问数据用的是__next__。
Iterator里已经重载了__iter__魔法函数,返回self。
list中只实现了__iter__,但没有__next__,所以它只是一个可迭代对象,而不是迭代器。
9.2 什么是迭代器和可迭代对象
from collections.abc import Iterable, Iterator
a = [1,2]
iter_rator = iter(a)
print (isinstance(a, Iterable))
print (isinstance(iter_rator, Iterator))
True
True
如果a实现了__iter__方法,再调用iter函数的话,就是返回一个迭代器。
之前我们讲过,实现了__geitem__方法,就可以进行for循环。
class Company(object):
def __init__(self, employee_list):
self.employee = employee_list
def __getitem__(self, item):
return self.employee[item]
if __name__ == "__main__":
company = Company(["tom", "bob", "jane"])
for item in company:
print(item)
tom
bob
jane
在调用for循环的时候,会去尝试调用iter(company),虽然company里没有实现__iter__魔法函数,但是iter这个内置方法首先会去寻找是否有__iter__方法,如果没有则默认创建一个迭代器,这个迭代器会利用__geitem__方法进行遍历(从0开始遍历)--相当于利用__geitem__退化为迭代器。
我们不用iter()利用__geitem__方法这种方式定义迭代器。
我们在类里面自定义一个迭代器
from collections.abc import Iterator
class MyIterator(Iterator):
"""
实现了一个迭代器
"""
def __init__(self, employee_list):
self.iter_list = employee_list
self.index = 0
def __next__(self):
# 真正返回迭代值的逻辑,不支持切片
# 迭代器不会产生索引值,且是一个一个产生数据的,所以我们需要内部维护一个索引变量
try:
word = self.iter_list[self.index] # 这里可能会抛出异常,随着index增加,会超出已有数据索引范围
except IndexError: # list中的异常是索引异常
raise StopIteration # 迭代器中的异常是停止迭代器
self.index += 1
return word
class Company(object):
def __init__(self, employee_list):
self.employee = employee_list
def __iter__(self):
return MyIterator(self.employee) # 返回自定义迭代器
if __name__ == "__main__":
company = Company(["tom", "bob", "jane"])
for item in company:
print (item)
tom
bob
jane
迭代器是经典设计模式中的一种,要遍历一个数据对象的时候,必须要新建一个迭代器,在对象里返回迭代器,用迭代器去维护迭代所需的一些变量,不要去迭代对象内部维护。比如上面的self.index,或者不要在class Company内定义__next__。
9.3 生成器函数使用
生成器和普通函数定义是一样的
#生成器函数,函数里只要有yield关键字
def gen_func():
yield 1 # 为什么有了yield就会变成生成器呢?因为python在运行前,会将代码变成字节码,
yield 2 # 发现有yield就生成一个生成器对象
yield 3 # yield是返回值,可以多次yield
def func():
return 1
# return 2 普通函数只能写一个return
if __name__ == "__main__":
#生成器对象, 在python编译字节码的时候就产生了
gen = gen_func() # 生成器对象也实现了迭代器协议,所以可以使用for循环
re = func()
pass # 在此处打断点debug
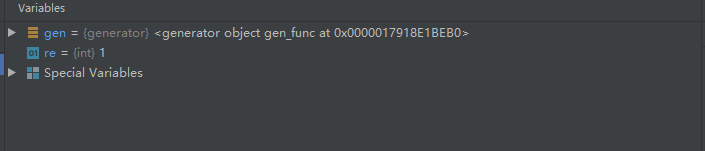
re=1就是返回的值,gen是一个生成器对象,不再是普通的值。
#生成器函数,函数里只要有yield关键字
def gen_func():
yield 1
yield 2
yield 3
if __name__ == "__main__":
gen = gen_func()
for value in gen:
print (value)
1
2
3
yield是python语法中非常精妙的设计
1.yield关键词(生成器)为实现协程提供可能
2.也为惰性求值(延迟求值)提供了可能
9.4 生成器的原理
什么是字节码?
def foo():
bar()
def bar():
pass
import dis
print(dis.dis(foo))
2 0 LOAD_GLOBAL 0 (bar)
2 CALL_FUNCTION 0
4 POP_TOP # 从栈顶端把元素打印出来
6 LOAD_CONST 0 (None)
8 RETURN_VALUE
None
什么场景下考虑使用生成器?自己如何写生成器?如何和函数区别开来?
python.exe运行python脚本,python.exe是用c语言写的。
#1.python中函数的工作原理
"""
"""
import inspect
frame = None
def foo():
bar()
def bar():
global frame
frame = inspect.currentframe()
#python.exe会用一个叫做 PyEval_EvalFramEx(c函数)去执行foo函数,
#1.首先会创建一个栈帧(stack frame),在栈帧上下文运行字节码(字节码-即函数,全局唯一)
#2.当foo调用子函数 bar, 又会创建一个栈帧,然后把函数控制权交给这个栈帧对象,运行bar的上下文字节码
#3.所有的栈帧都是分配在堆内存上(不是栈的内存上),堆的特性是不释放就会一直在内存中,这就决定了栈帧可以
# 独立于调用者存在,就算调用者foo函数删了,bar栈帧还是在内存中,只要有对应的指针,就可以控制bar
"""
python一切皆对象,栈帧也是对象
"""
改写下上面的函数,看下栈帧的特性
import inspect
frame = None
def foo():
bar()
def bar():
global frame
frame = inspect.currentframe() # 把当前bar的栈帧赋值给全局变量
foo() # 运行foo函数,完成后即退出该函数
print(frame.f_code.co_name) # frame的栈帧
caller_frame = frame.f_back # 调用者的栈帧
print(caller_frame.f_code.co_name)
bar
foo
所以调用foo的时候,产生一个栈帧,调用子程序的时候,又会创建一个栈帧
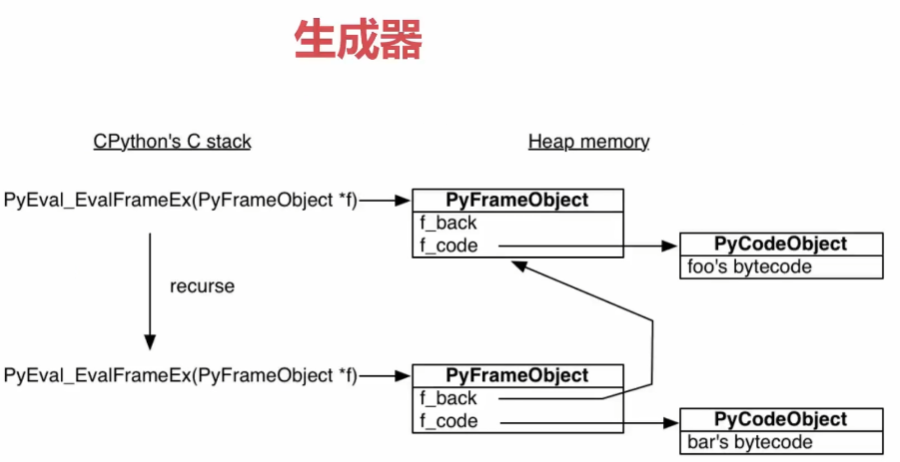
cpython(python解释器)
1.通过PyEval_EvalFramEx函数创建一个栈帧对象
- f_code指向PyCodeObject(foo的字节码)
2.foo里面调用了bar,又创建一个栈帧对象
- f_back指向调用者的栈帧对象
- f_code指向PyCodeObject(boo的字节码)
生成器对象利用了python栈帧对象是分配在堆内存中的这一特性。
生成器对象对python frame做了一个封装
def gen_func():
"""
python解释器会编译函数的字节码,遇到yield关键词,知道这是个生成器函数,会对这个函数做一个标记
"""
yield 1
name = "bobby"
yield 2
age = 30
return "imooc" # 生成器可以return一个值
gen = gen_func() # 返回生成器对象,实际上对pyframe做了封装
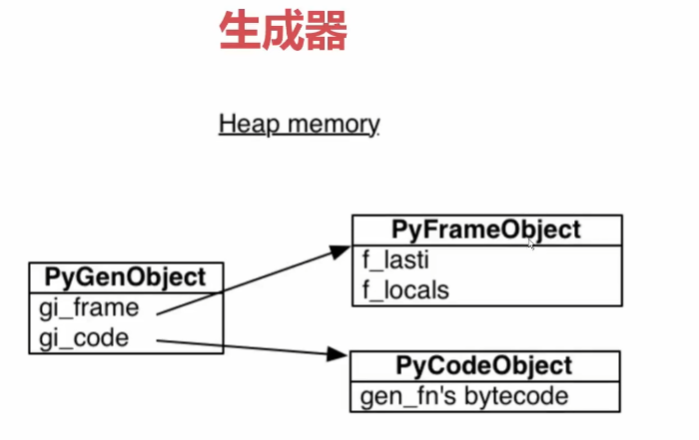
在PyFrameObject和PyCodeObject上面又加了一层PyGenObject(python中的生成器对象)。
PyFrameObject中的
- f_lasti:指向最近执行的代码(在字节码中的什么位置)
- f_locals:运行到下一个yield之前保存的局部变量
- 为PyGenObject的暂停和继续提供了理论基础
生成器对象也是保存在堆内存中的,所以可以独立于调用者存在,只要有这个栈帧对象,就可以自由控制。可以在任何地方,任何函数或模块中,只要拿到了生成器对象,就可以恢复、暂停、继续这个生成器对象。正了有了这个特性,才有后面协程的概念,这是协程能够执行的理论基础。
有个f_lasti,f_locals,就可以在生成器里面不断地循环同一个函数。
9.5 通过UserList来看生成器的应用
通过对list的遍历来看生成器的具体应用,list可以用for循环进行遍历(list实现了__getitem__方法)。
为什么__getitem__可以进行遍历,来看一下一个数据结构UserList(list使用c语言写的,UserList是用python写的),UserList也可以用自己继承,不要去继承list(因为是c语言写的,里面有一些很关键的方法)。
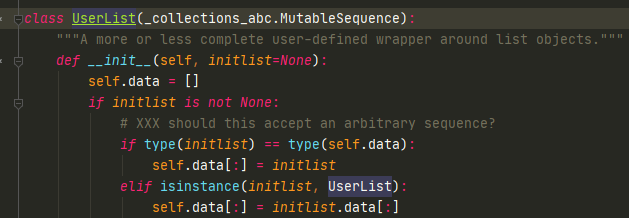
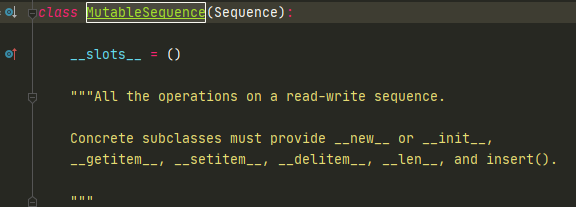
UserList继承了MutableSequence,MutableSequence继承了Sequence
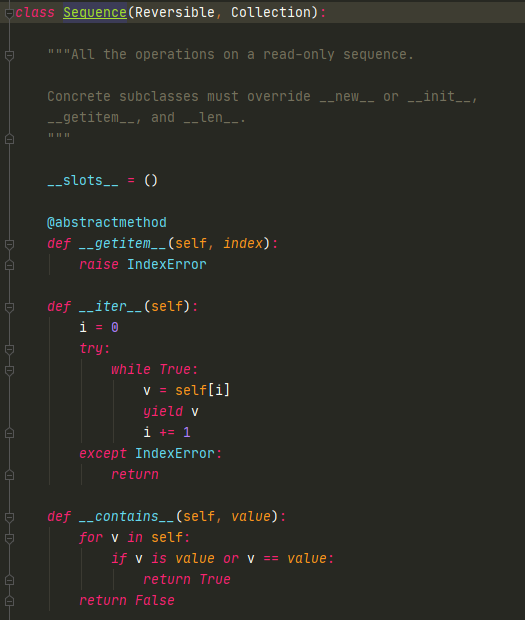
Sequence里的__iter__内部就是用yield实现的
- while True在函数里不停的循环取数据(循环同一个方法__getitem__)
- i是一个局部变量且保存在生成器栈帧中,记录了元素位置
- 内部的self[i]调用了__getitem__方法,相当于__getitem__退化为了一个迭代器
所以通过生成器的方式,实现了对list的遍历
9.6 生成器如何读取大文件
读取500G的文件,一行一行读取出来,写入到数据库中。
可以通过open方式,然后一行一行读,但这对文件本身有一定要求(是一行一行保存的)。
如果文件只有一行,中间用特殊分隔符分割,那就没法使用open方式。
#500G, 特殊 一行
def myreadlines(f, newline):
buf = "" # 声明一个buf,缓存
while True:
while newline in buf: # 缓存中是否包含newline分隔符
pos = buf.index(newline) # 如果存在则把分隔符位置找到
yield buf[:pos]
buf = buf[pos + len(newline):] # buf有可能会有多行,所以在取出一行后,要更新
chunk = f.read(4096)# 刚开始buf为空字符串,直接读取f
# f.read(4096) 只会读取4096个字符
# f.read(4096) f会接着上一个偏移量进行数据读取,f内部会自己维护这个偏移量
if not chunk:
#说明已经读到了文件结尾
yield buf
break
buf += chunk
with open("input.txt") as f:
for line in myreadlines(f, "{|}"):
print (line)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号