第六章 深入python的set和dict
6.1 dict的abc继承关系
首先讲解map类型,dict实际上就属于Mapping类型。
from collections.abc import Mapping, MutableMapping
#dict属于mapping类型
a = {}
print (isinstance(a, MutableMapping))
点进去看
__all__ = ["Awaitable", "Coroutine",
"AsyncIterable", "AsyncIterator", "AsyncGenerator",
"Hashable", "Iterable", "Iterator", "Generator", "Reversible",
"Sized", "Container", "Callable", "Collection",
"Set", "MutableSet",
"Mapping", "MutableMapping",
"MappingView", "KeysView", "ItemsView", "ValuesView",
"Sequence", "MutableSequence",
"ByteString",
]
有Mapping和MutableMapping,MutableMapping属于一个可修改的Mapping。
dict就是属于MutableMapping。
点击看MutableMapping的structure。
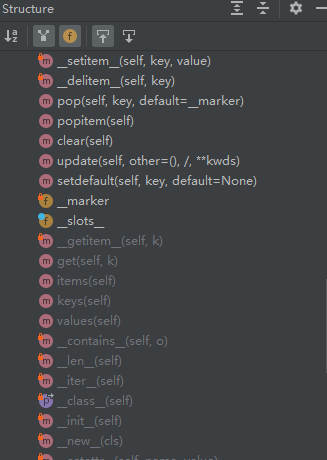
定义有__setitem__,__delitem__这两个抽象方法,跟前面的序列类型是一样的。还定义了很多方法如pop、update、setdefault......
我们先看继承关系
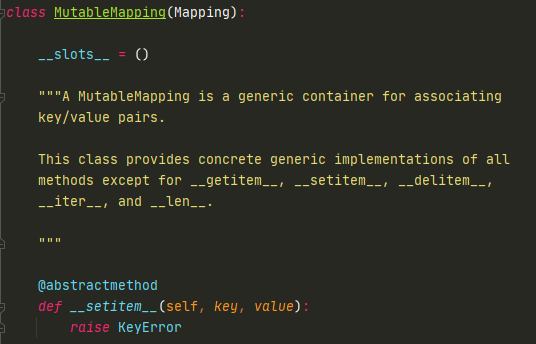
继承的是Mapping,点进去看Mapping
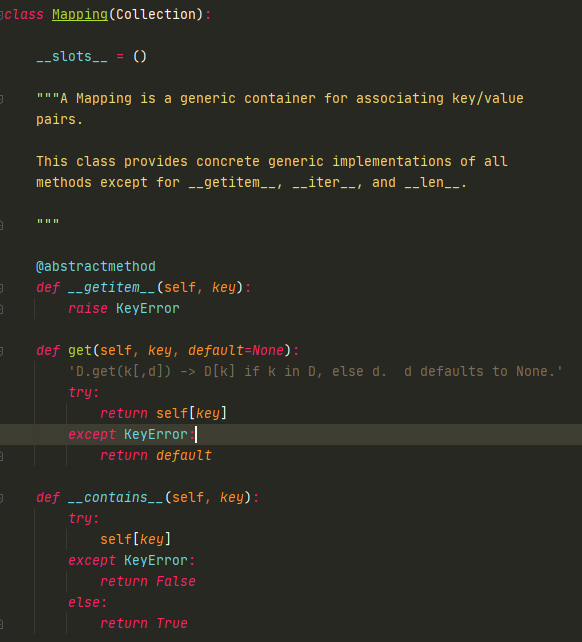
Mapping里面多了一个__getitem__这个抽象方法,还有__contaions__实际上是重载了Collection
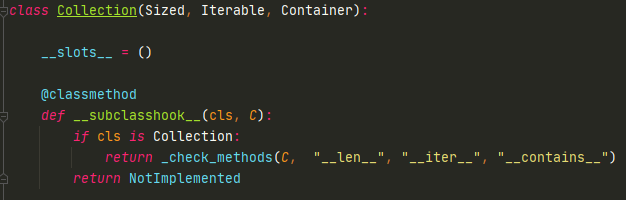
这个Collection和序列当中是一样的,继承于Sized、Iterable和Container。所以我们也可以知道,dict和list有很多方法是一样的。
之前说过dict属于mapping类型,那么可以判断dict是否属于MutableMapping
from collections.abc import Mapping, MutableMapping
#dict属于mapping类型
a = {}
print (isinstance(a, MutableMapping))
D:\python3\python.exe E:/pyproject/AdvancePython-master/chapter06/dict_abc.py
True
Process finished with exit code 0
来看看isinstance是怎么做的,首先a是一个dict类型。这个a,不是继承了MutableMapping,而是实现了MutableMapping里边的一些方法(魔法函数)。
6.2 dict的常用操作
点进去看dict的源码,Python的dict是用C语言写的。
1.首先看clear方法

“remove all all items from D"就是清空数据
用简单的方式声明一个dict,然后直接clear
a = {"bobby1":{"company":"imooc"},
"bobby2": {"company": "imooc2"}
}
print(a)
a.clear()
print(a)
{'bobby1': {'company': 'imooc'}, 'bobby2': {'company': 'imooc2'}}
{}
2.然后看copy方法

”a shallow copy of D“,返回的是一个浅拷贝(共享内存,对象指向同一个指针)。
如果做深拷贝,要用一个包copy
import copy
new_dict = copy.deepcopy(a)
new_dict["bobby1"]["company"] = "imooc3"
修改new_dict的数据不会同时修改a的数据
3.再看fromkeys

fromkeys是一个静态方法,从一个可迭代对象(key,value)创建一个新的字典。
new_list = ["bobby1", "bobby2"]
new_dict = dict.fromkeys(new_list, {"company":"imooc"})
new_dict1 = dict.fromkeys(new_list, [1,2])
print(new_dict)
print(new_dict1)
{'bobby1': {'company': 'imooc'}, 'bobby2': {'company': 'imooc'}}
{'bobby1': [1, 2], 'bobby2': [1, 2]}
4.get方法

get方法用来增强从dict通过key获取数据的功能,如果key不存在,则返回一个制定的默认值。
new_list = ["bobby1", "bobby2"]
new_dict = dict.fromkeys(new_list, {"company":"imooc"})
value = new_dict.get("bobby",{})
print(value)
{}
5.items方法

经常在for循环中使用
new_list = ["bobby1", "bobby2"]
new_dict = dict.fromkeys(new_list, {"company":"imooc"})
for key,value in new_dict.items():
print(key,value)
bobby1 {'company': 'imooc'}
bobby2 {'company': 'imooc'}
6......还有很多方法
7.setdefault方法
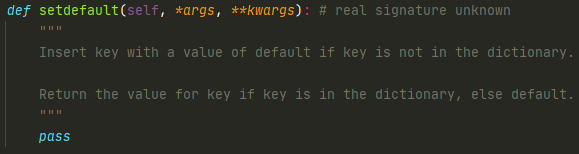
setdefault会做两件事
1.如果dict里面没有对应的key,则添加该key和默认值
2.从dict里取出对应key的值
new_list = ["bobby1", "bobby2"]
new_dict = dict.fromkeys(new_list, {"company":"imooc"})
default_value = new_dict.setdefault("bobby","imooc")
print(default_value)
print(new_dict)
imooc
{'bobby1': {'company': 'imooc'}, 'bobby2': {'company': 'imooc'}, 'bobby': 'imooc'}
8.update方法
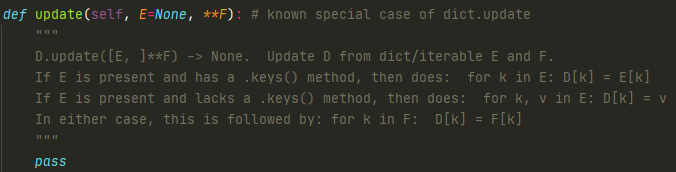
update可以合并两个dict对象
new_list = ["bobby1", "bobby2"]
new_dict = dict.fromkeys(new_list, {"company":"imooc"})
print(new_dict)
new_dict.update({"bobby":"imooc"})
print(new_dict)
{'bobby1': {'company': 'imooc'}, 'bobby2': {'company': 'imooc'}}
{'bobby1': {'company': 'imooc'}, 'bobby2': {'company': 'imooc'}, 'bobby': 'imooc'}
update也可以处理iterable对象
new_list = ["bobby1", "bobby2"]
new_dict = dict.fromkeys(new_list, {"company":"imooc"})
print(new_dict)
new_dict.update(bobby='imooc')
print(new_dict)
{'bobby1': {'company': 'imooc'}, 'bobby2': {'company': 'imooc'}}
{'bobby1': {'company': 'imooc'}, 'bobby2': {'company': 'imooc'}, 'bobby': 'imooc'}
这个iterable对象可以是list里面是tuple的形式
new_list = ["bobby1", "bobby2"]
new_dict = dict.fromkeys(new_list, {"company":"imooc"})
print(new_dict)
new_dict.update([("bobby","imooc")])
print(new_dict)
{'bobby1': {'company': 'imooc'}, 'bobby2': {'company': 'imooc'}}
{'bobby1': {'company': 'imooc'}, 'bobby2': {'company': 'imooc'}, 'bobby': 'imooc'}
这个iterable对象可以是tuple里面是tuple的形式
new_list = ["bobby1", "bobby2"]
new_dict = dict.fromkeys(new_list, {"company":"imooc"})
print(new_dict)
new_dict.update((("bobby","imooc")))
print(new_dict)
{'bobby1': {'company': 'imooc'}, 'bobby2': {'company': 'imooc'}}
{'bobby1': {'company': 'imooc'}, 'bobby2': {'company': 'imooc'}, 'bobby': 'imooc'}
6.3 dict的子类
python中一切都可以继承,所以dict也是可以继承的,但是不建议去继承python中用C语言写的数据结构(list,dict...)。举个例子说明一下:
#不建议继承list和dict
class Mydict(dict):
def __setitem__(self, key, value):
super().__setitem__(key, value*2)
my_dict = Mydict(one=1)
print (my_dict)
my_dict['one'] = 1
print(my_dict)
子类重写__setitem__方法,然后调用调用父类。可以看到类实例化,并没有调用覆盖的方法,而使用[]的方法,则生效。这事因为在某些情况下,用C语言写的dict不会去调用覆盖的方法。
如果要继承dict,建议用collections模块中的UserDict,我们可以点进去看下UserDict。
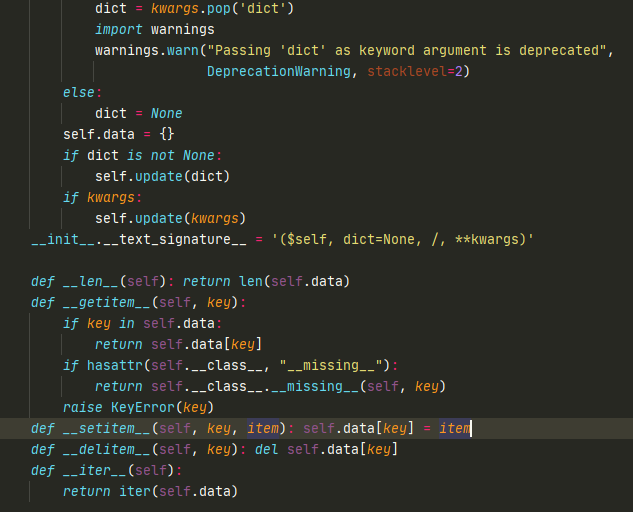
它里面的一些方法,都是用python重新写过,用的不是C语言。
from collections import UserDict
class Mydict(UserDict):
def __setitem__(self, key, value):
super().__setitem__(key, value*2)
my_dict = Mydict(one=1)
print (my_dict)
{'one': 2}
说到继承的问题,讲解一个python内置的dict的一个子类,叫做defaultdict。先看UserDict,里面有一个__missing__方法,在找不到key的时候,会调用这个方法。再看defaultdict的源码
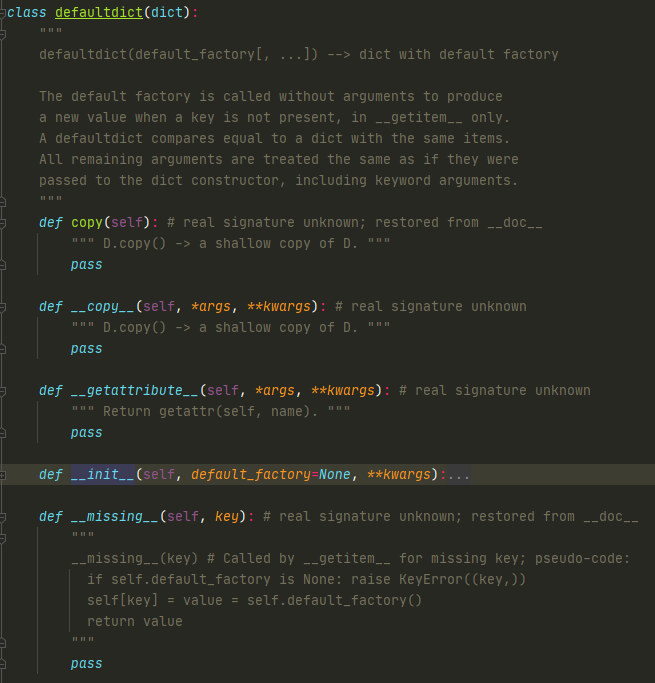
实际上defaultdict重写了__missing__方法,当找不到某个key时,会把这个key存进来,赋值为self.default_facory()。
from collections import defaultdict
my_dict = defaultdict(dict)
my_value = my_dict["bobby"]
print(my_value)
{}
本来如果dict里没有key的话,是会报keyerror的,但这里就会是一个空的dict。没有bobby这个key的时候,进入了defaultdict的__missing__方法。
6.4 set和frozenset
set是集合,frozenset是不可变集合(冻结集合)。set是无序,不重复的。
看set的源码
接受的参数是一个iterable(可迭代对象),所以我们用字符串,list,tuple都是可以的。
s = set('abcdee')
print(s)
s = set(['a','b','c','d','e'])
print(s)
{'d', 'b', 'c', 'e', 'a'}
{'d', 'b', 'c', 'e', 'a'}
set的初始化方式很类似dict,要注意
s={'a','b'}
# s={'a':"11",'b':"22"}
print(type(s))
<class 'set'>
对set可以用add添加值,但是对frozenset是无法使用add添加值的,frozenset一旦设置就无法修改。
s={'a','b'}
s.add('c')
print(s)
s = frozenset("abcde") #frozenset 可以作为dict的key
print(s)
frozenset是不可变的,相对于可变类型来说,有一个好处是可以作为dict的key,这个非常有用,对dict来说,key是需要一个恒定的值。
向set添加 数据,最简单的方式就是add方法。我们可以看一下set的源码
set有很多魔法函数,还有很多方法。

update可以把两个set合并成一个set
s = {'a','b', 'c'}
another_set = set("cef")
s.update(another_set)
print(s)
{'e', 'a', 'f', 'c', 'b'}
difference可以计算集合的差集
s = {'a','b', 'c'}
another_set = set("cef")
re_set = s.difference(another_set)
print(re_set)
{'a', 'b'}
关于差集、交集、并集的运算是由魔法函数实现的
s = {'a','b', 'c'}
another_set = set("cef")
print(s - another_set)
print(s & another_set)
print(s | another_set)
{'b', 'a'}
{'c'}
{'b', 'c', 'e', 'f', 'a'}
__ior__实现了并集,__isub__实现了差集,__ixor__实现了交集。set的性能是非常高的,实现原理和list的原理相同(哈希),所以查找元素的时间复杂度是很低的(o(1))。
判断一个元素是否在set中,直接使用if,in
re_set = {'a','b', 'c'}
if "c" in re_set:
print ("i am in set")
i am in set
能使用in是因为里面有一个魔法函数

frozenset和set的操作是一样的。
6.5 dict和set的实现原理
为什么要了解实现原理,当我们使用一个数据结构的时候,当我们知道它的原理之后就会知道在什么情况下用dict以及为什么要用dict。
来看一下测试dict和list性能的代码。去10000(100000,1000000)个元素里查找1000个元素要花费的时间(dict和list都尝试)。
def load_list_data(total_nums, target_nums):
"""
从文件中读取数据,以list的方式返回
:param total_nums: 读取的数量
:param target_nums: 需要查询的数据的数量
"""
all_data = [] # 我们要查找的1000个元素
target_data = [] # 所有元素
file_name = "G:/慕课网课程/AdvancePython/fbobject_idnew.txt"
with open(file_name, encoding="utf8", mode="r") as f_open:
for count, line in enumerate(f_open):
if count < total_nums: # 小于total_nums时添加到all_data
all_data.append(line)
else:
break
for x in range(target_nums):
random_index = randint(0, total_nums) # 生成随机值(int 索引)
if all_data[random_index] not in target_data: # 如果取出来的值不在target_data
# 里,则添加到target_data里
target_data.append(all_data[random_index])
if len(target_data) == target_nums: # target_data里面的数据量=target_nums
break # 停止
return all_data, target_data
load_list_data函数去文件读取数据。返回数据后使用find_test测试。
def find_test(all_data, target_data):
#测试运行时间
test_times = 100 # 测试次数
total_times = 0
import time
for i in range(test_times): # 查询逻辑,for循环
find = 0
start_time = time.time()
for data in target_data:
if data in all_data: # 用if、in的方式查找
find += 1
last_time = time.time() - start_time
total_times += last_time
return total_times/test_times # 返回一个平均时间
还有一个load_dict_data函数,功能和load_list_data是一样的,但是变成了测试dict。
def load_dict_data(total_nums, target_nums):
"""
从文件中读取数据,以dict的方式返回
:param total_nums: 读取的数量
:param target_nums: 需要查询的数据的数量
"""
all_data = {}
target_data = []
file_name = "G:/慕课网课程/AdvancePython/fbobject_idnew.txt"
with open(file_name, encoding="utf8", mode="r") as f_open:
for count, line in enumerate(f_open):
if count < total_nums:
all_data[line] = 0
else:
break
all_data_list = list(all_data)
for x in range(target_nums):
random_index = randint(0, total_nums-1)
if all_data_list[random_index] not in target_data:
target_data.append(all_data_list[random_index])
if len(target_data) == target_nums:
break
return all_data, target_data
运行测试
all_data, target_data = load_dict_data(2000000, 1000)
last_time = find_test(all_data, target_data)
print(last_time)
结论是
- dict查找的性能远远大于list
- dict查找元素开销不会随着dict里数据量的增大而增大
这个就涉及到dict后面实现的原理,是哈希表
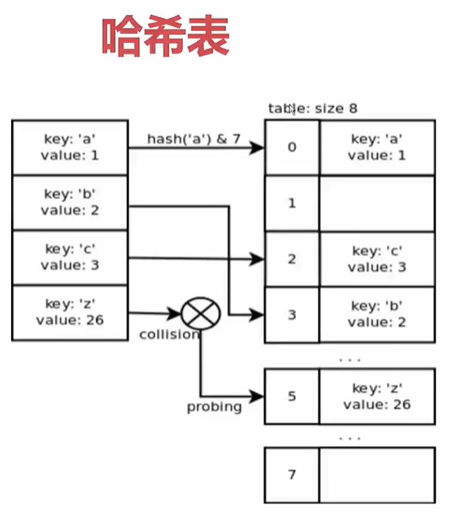
dict中必须要保证key是可哈希的,如上图计算a的哈希值(散列值),和7做 &(与)位运算,如果计算出来是0这个偏移量,就把key:'a' value:1 放在0位置处。对b、c做同样的哈希运算,计算偏移量并存储数据。如果哈希z时有冲突,则重新计算z的哈希值(重新计算的方法有很多种)。
可以看到哈希表里有很多空白,因为当哈希表可利用空间少于1/3时,就会去申请更多的空间,然后把整张表拷贝到另外的空间中去,保证数据之间的冲突概率较小。
在哈希表中查找数据,是对key进行哈希处理后,直接获得了内存地址,查找步骤只有一步(因为数组是连续的空间,不需要像链表那样需要从头遍历),所以数组(array)取数的时间复杂度是O(1)。
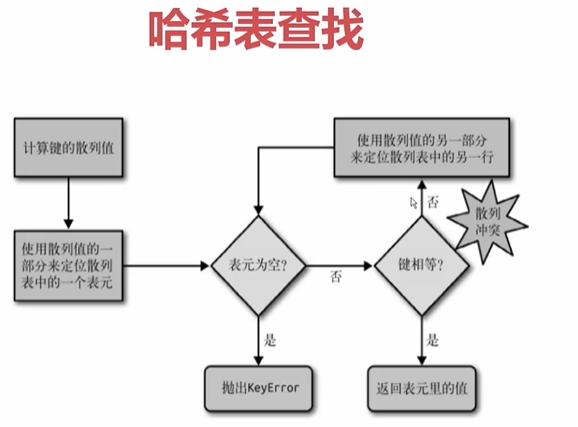
比如查找a的值,首先计算a的散列值,然后利用散列值定位表元

如果表元为空,意味着a没有对应的数据
如果表元不为空,还要去判断里面数据的key和a是否相同,因为可能有冲突存在,如果存a数据时有冲突,那么a的散列值是修改过的,意味着a的对应数据在另一个表元上。
dict的几个特性
- dict的key和set的值,都是用的哈希存储,所以必须要可哈希的。不可变对象都是可哈希的,比如str、fronzenset、tuple,这些都可以放到set中或作为dict的key。如果自己实现一个类,就可以重载__hash__这个魔法函数,保证返回一个固定的值,那么这个类对象就是可哈希的。
- dict的内存花销大,使用的哈希表会有很大的空白python内部的对象,和自己定义的对象,都是用dict包装的。
- dict的存储顺序和元素添加顺序有关,如果有冲突,修改的是后添加元素的散列值,可能会存储在靠前的位置,也可能存储在靠后的位置。所以dict一般就是无顺序的存储。当然orderdict是有顺序的存储。
- 添加数据有可能改变已有数据的顺序,当表元小于1/3时,会重新申请空间,然后把原来的数据重新插入新的空间,由于新空间比原空间大,很有可能原来数据存储位置会改变(因为重新分配内存位置了)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号