离散分箱
离散分箱有什么用?
- 离散特征的增加和减少都很容易,易于模型的快速迭代
- 离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。4. 如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰
- 逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合
- 离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力
- 特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问
- 特征离散化以后,会有信息损失,相当于加入了正则化,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险
- 可以将缺失作为独立的一类带入模型
无监督分箱
等宽、等频
等宽、等频很容易理解
有监督分箱
卡方分箱
原假设是相邻两箱独立

这里需要注意初始化时需要对实例进行排序,在排序的基础上进行合并。
卡方阈值的确定:
根据显著性水平和自由度得到卡方值自由度比类别数量小1。例如:有3类,自由度为2,则90%置信度(10%显著性水平)下,卡方的值为4.6。
阈值的意义:
类别和属性独立时,有90%的可能性,计算得到的卡方值会小于4.6。 大于阈值4.6的卡方值就说明属性和类不是相互独立的,不能合并。如果阈值选的大,区间合并就会进行很多次,离散后的区间数量少、区间大。
注:
1、ChiMerge算法推荐使用0.90、0.95、0.99置信度,最大区间数取10到15之间.
2、也可以不考虑卡方阈值,此时可以考虑最小区间数或者最大区间数。指定区间数量的上限和下限,最多几个区间,最少几个区间。
3、对于类别型变量,需要分箱时需要按照某种方式进行排序。
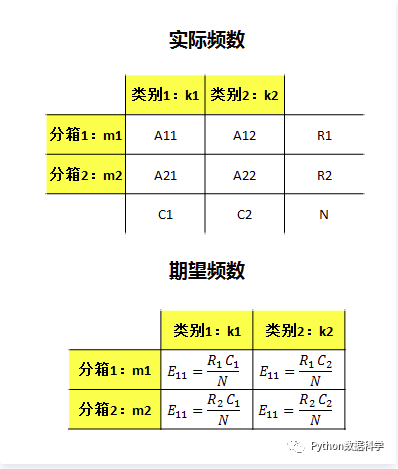
best-ks分箱

Best-KS分箱的特点:
- 连续型变量:分箱后的KS值<=分箱前的KS值
- 分箱过程中,决定分箱后的KS值是某一个切点,而不是多个切点的共同作用。这个切点的位置是原始KS值最大的位置。
基于熵的离散
MDLP的基本思想是,离散后输入变量对输出变量的解释能力变强,则这种离散是有用的,否则是没有意义的。它是利用信息增益最大化的方法寻找连续变量的最优切点,当切点确定后,将连续变量一分为二,分为两部分数据集,在这两部分数据集中用同样的方法循环切分,直到信息增益的值小于停止标准为止。
集合D中第k类样本所占比例为,则信息熵为
通过一个划分点划分集合,信息增益为:
的类别数量未,的类别数量为
停止准则为:


· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· [.NET]调用本地 Deepseek 模型
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 全网最简单!3分钟用满血DeepSeek R1开发一款AI智能客服,零代码轻松接入微信、公众号、小程
· .NET 10 首个预览版发布,跨平台开发与性能全面提升
· 《HelloGitHub》第 107 期
· 全程使用 AI 从 0 到 1 写了个小工具
· 从文本到图像:SSE 如何助力 AI 内容实时呈现?(Typescript篇)