第四章 深入类和对象
4.1 鸭子类型和多态
class Cat(object):
def say(self):
print("i am a cat")
class Dog(object):
def say(self):
print("i am a fish")
class Duck(object):
def say(self):
print("i am a duck")
animal = Cat
animal().say
上面三个类都有一个函数say()。现在定义一个对象animal,有可能是Cat、Dog或者Duck(多态)。
animal_list = [Cat, Dog, Duck]
for animal in animal_list:
animal().say()
i am a cat
i am a fish
i am a duck
上面分别打印出三个类的say方法。
类只要定义同一个方法(鸭子类型),就可以实现多态。
类中的鸭子类型:只要类里面有同样的方法,在特定功能上就看成同一种类。
a = ["bobby1", "bobby2"]
b = ["bobby2", "bobby"]
name_tuple = ("bobby3", "bobby4")
name_set = set()
name_set.add("bobby5")
name_set.add("bobby6")
a.extend(b)
print(a)
a.extend(name_tuple)
print(a)
a.extend(name_set)
print(a)
['bobby1', 'bobby2', 'bobby2', 'bobby']
['bobby1', 'bobby2', 'bobby2', 'bobby', 'bobby3', 'bobby4']
['bobby1', 'bobby2', 'bobby2', 'bobby', 'bobby3', 'bobby4', 'bobby5', 'bobby6']
extend()有个参数Iterable(可迭代对象),list、tuple、set都是可迭代对象。可迭代对象也是鸭子类型,里面实现了迭代器(比如__iter__魔法函数,或者是__getitem__),魔法函数充分利用了鸭子类型,只要实现了某种魔法函数,就可以看做某种类型。
python中有很多方法,只要求参数是某种类型,不指定具体是哪种结构。
4.2-4.3 抽象基类(abc模块)
python是动态语言,没有变量类型,变量只是一个符号,可以指向任何类型的对象,因此天然支持多态。由于是动态语言,不需要指定变量类型,因此少了一个编译时检查错误的环境。在python中写错代码,事先是很难知道的,只有在运行时才会发现错误,即无法做类型检查。
python的类不需要继承,只要实现了某些魔法函数,就会拥有某些类型的特性(协议)。
抽象基类的意思是:
- 在基类中设定好一些方法,所以继承基类的类都必须复写这些方法
- 抽象基类无法实例化
为什么会有抽象基类这个概念,Python是基于鸭子类型的,在类中直接实现某些方法不就行了吗?
两种应用场景来说明:
检查某个类是否有某种方法
class Company(object):
"""
检查Company类是否可以计算长度
"""
def __init__(self, employee_list):
self.employee = employee_list
def __len__(self):
return len(self.employee)
com = Company(["bobby1","bobby2"])
print(len(com))
print(hasattr(com, "__len__")) # 在类中,函数也是一种属性
2
True
在某些情况之下判定某个对象的类型
如果没有抽象基类,必须使用hasattr,但isinstance这种用法更好,collections.abc模块中有Sized抽象基类,有抽象方法__len__,com实现了__len__方法。
from collections.abc import Sized
isinstance(com, Sized)
强制某个子类必须实现某些方法
假如实现一个web框架,要集成缓存cache,以后也希望可以用redis、cache、memorychache替换。那么一开始就需要设计一个抽象基类,指定子类必须实现某些方法。
class CacheBase(metaclass=abc.ABCMeta):
# 从缓存中获取数据,必须用户自己实现
@abc.abstractmethod
def get(self, key):
pass
# 添加数据,必须用户自己实现
@abc.abstractmethod
def set(self, key, value):
pass
上面相当于一个缓存组件,用户在使用的时候,可以使用redis、cache、或者memorychache来进行缓存,但是自己写缓存子类的时候,必须实现get、set方法。
模拟一个抽象基类:
class CacheBase():
def get(self, key):
raise NotImplementedError
def set(self, key, value):
raise NotImplementedError
定义一个子类继承抽象基类,不重写方法:
class RedisCache(CacheBase):
pass
redis_cache = RedisCache()
redis_cache.set("key", "value")
Traceback (most recent call last):
File "D:/py_tutrial/AdvancePython-master/chapter04/abc_test.py", line 61, in <module>
redis_cache.set("key", "value")
File "D:/py_tutrial/AdvancePython-master/chapter04/abc_test.py", line 53, in set
raise NotImplementedError
NotImplementedError
会抛出NotImplementedError 异常
模拟的方法会有一个不好的地方,在调用set函数的时候才会抛出异常。我们希望在初始化的时候(实例化的时候)就能够抛出异常,这需要用到abc 模块。
import abc
class CacheBase(metaclass=abc.ABCMeta):
@abc.abstractmethod # 抽象方法,就不用raise异常
def get(self, key):
pass
@abc.abstractmethod
def set(self, key, value):
pass
关于abc的模块,python中有两个地方,一个就是abc(全局),另外一个是collections.abc。
这时候再调用:
class RedisCache(CacheBase):
pass
redis_cache = RedisCache()
redis_cache.set("key", "value")
Traceback (most recent call last):
File "D:/py_tutrial/AdvancePython-master/chapter04/abc_test.py", line 60, in <module>
redis_cache = RedisCache()
TypeError: Can't instantiate abstract class RedisCache with abstract methods get, set
抛出异常,我们必须重新定义get、set方法。
我们重新定义set方法:
class RedisCache(CacheBase):
def set(self, key, value):
pass
redis_cache = RedisCache()
redis_cache.set("key", "value")
Traceback (most recent call last):
File "D:/py_tutrial/AdvancePython-master/chapter04/abc_test.py", line 59, in <module>
redis_cache = RedisCache()
TypeError: Can't instantiate abstract class RedisCache with abstract methods get
异常只告诉我们要重载get,已经没有set的异常了。
采用abc模块后,在实例化的时候就抛出异常了,可以强制子类实现某些方法。
在python中已经实现了通用了抽象基类,放在collections.abc模块中,点进去看:
__all__ = ["Awaitable", "Coroutine",
"AsyncIterable", "AsyncIterator", "AsyncGenerator",
"Hashable", "Iterable", "Iterator", "Generator", "Reversible",
"Sized", "Container", "Callable", "Collection",
"Set", "MutableSet",
"Mapping", "MutableMapping",
"MappingView", "KeysView", "ItemsView", "ValuesView",
"Sequence", "MutableSequence",
"ByteString",
]
列表里的都是抽象基类,点进抽象基类里:
class Awaitable(metaclass=ABCMeta):
__slots__ = ()
@abstractmethod
def __await__(self):
yield
@classmethod
def __subclasshook__(cls, C):
if cls is Awaitable:
return _check_methods(C, "__await__")
return NotImplemented
有个很重要的魔法函数 __subclasshook__
看上面的例子
class Company(object):
def __init__(self, employee_list):
self.employee = employee_list
def __len__(self):
return len(self.employee)
com = Company(["bobby1","bobby2"])
from collections.abc import Sized
print(isinstance(com, Sized))
com并没有继承Sized,但却可以判断出com是Sized类型,为什么能判断出来,点进去看Sized:
class Sized(metaclass=ABCMeta):
__slots__ = ()
@abstractmethod
def __len__(self):
return 0
@classmethod
def __subclasshook__(cls, C):
if cls is Sized:
return _check_methods(C, "__len__")
return NotImplemented
这里面也有个魔法函数 __subclasshook__,这个函数首先判断传递进来的对象C有没有__len__方法,有则返回True。
所以例子里面就是利用了Sized的魔法函数__subclasshook__,如果com有__len__方法,则判断com是Sized类型。
当然isinstance的功能并没有看起来这么简单,它内部会做很多的步骤,比如:
我们实现
class A:
pass
class B(A):
pass
b = B()
print(isinstance(b, A))
True
所以isinstance不只是去找__subclasshook__,还会去找继承链。
综上,抽象基类有两个用途,一是调用isinstance,二是可以做接口的强制规定。
可以看到Python在尽量使用鸭子类型,抽象基类也不推荐使用,抽象基类在设计的时候容易设计过度,反而不容易理解。
4.4 isinstance和type的区别
为什么尽量使用isinstance而少使用type
举个例子说明:
class A:
pass
class B(A):
pass
b = B()
print(isinstance(b, B))
print(isinstance(b, A))
True
True
B是A的子类,所以b也是A类。
使用type时:
print(type(b))
print(type(b) is B)
print(type(b) is A)
<class '__main__.B'>
True
False
可以看到b是B类,type(b)指向B,虽然B继承A,但A和B是两个不同的对象,但是isinstance会找继承链。
这里有个知识点is和==的区别,is在判断两个对象的id是否相同:
print(id(B))
print(id(type(b)))
2158572618624
2158572618624
==是在判断值是否相同
4.5 类变量和实例变量
class A:
aa = 1
def __init__(self, x, y):
self.x = x
self.y = y
a = A(2,3)
print(a.x, a.y, a.aa)
print(A.aa)
print(A.x)
2 3 1
1
print(A.x)
AttributeError: type object 'A' has no attribute 'x'
aa是类变量,__init__中的self是实例,所以self.x,self.y是实例变量。
实例化后(a),a.aa先在实例变量中查找,没有再向上从类变量中查找。
类没有办法向下查找变量,因为实例变量是绑定在具体实例中的,如果在类变量中没有找到,则抛出异常。
A.aa = 11
print(a.x, a.y, a.aa)
a.aa = 100
print(a.x, a.y, a.aa)
b = A(3,5)
print(b.aa)
2 3 11
2 3 100
11
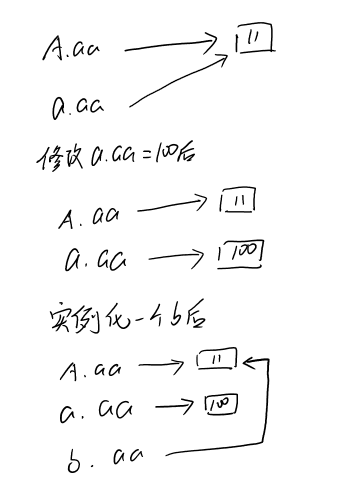
修改类中的aa变量后,已经实例化的aa变量也会改变(实例aa变量指向类aa变量指向的对象)。
修改实例aa变量后,a.aa指向100,但A.aa仍然指向11,先查找实例中的aa变量,找到不会再向上查找类的aa变量。
4.7 类属性和实例属性以及查找顺序
class A:
name = 'A'
a = A()
print(a.name)
A
实例是有自己的属性的,可以在类里面初始化
class A:
name = 'A'
def __init__(self):
self.name = "obj"
a = A()
print(a.name)
obj
a.name的查找顺序是由下而上的,所以首先查找实例的name,如果查不到再向上查找类的name。
在多继承里,查找循序会变得复杂。
首先看下一种继承关系,python比较早的继承算法:MRO算法
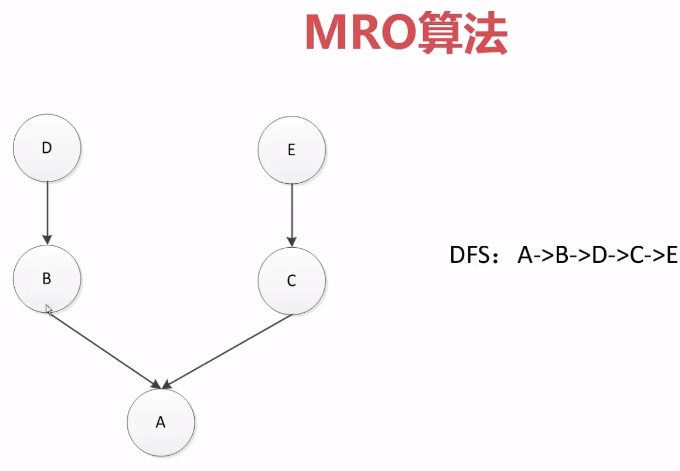
DFS:深度优先搜索
属性查找顺序是A、B、D、C、E,比如A中有个方法,在B中没有,那么则会去D中查找。
这种查找顺序其实是合理的,A从B、C继承,先搜索B的那个继承链。
但如果换一种继承方式,这种逻辑就不合理
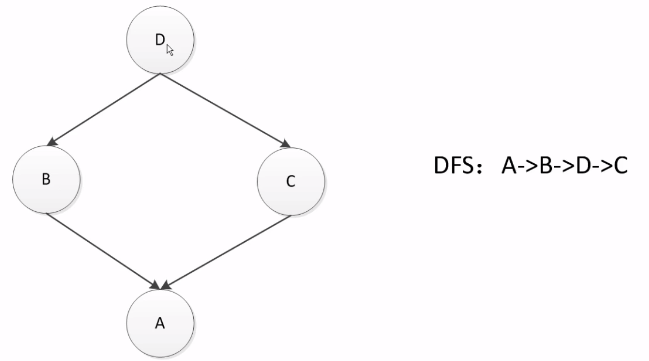
A继承于B、C,B、C继承于D(菱形继承),这种情况下使用DFS的逻辑就不合适。如果使用的是C中继承的方法,那么从B、D、C的顺序就不合理,这样相当于C永远无法覆盖D中的方法。
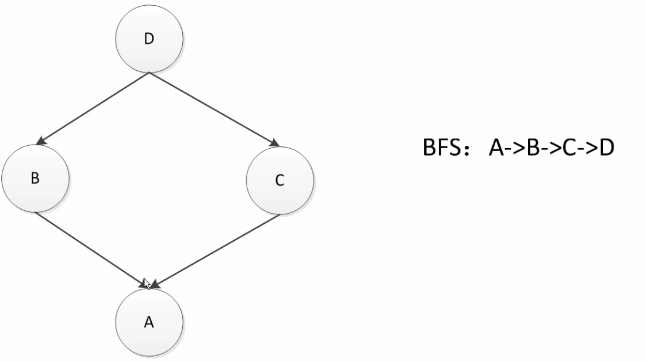
这种情况下改为广度优先算法BFS。
但这种方法又会出现问题
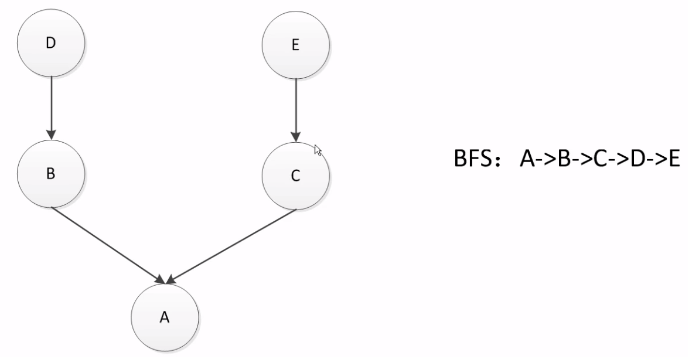
如上图,如果D和C中有同名的方法,那在搜索的时候,在B中没找到,就会去C中找。但此时B继承于D,而C继承于A,此时D、B应该看成一个整体,所以B后应该是D。所以广度优先算法BFS在这种情况下又不合适了。
Python3中的继承算法是C3算法,可以克服上述两个方法的缺点。
来看一下查找的例子:
#新式类
class D:
pass
class E:
pass
class C(E):
pass
class B(D):
pass
class A(B, C):
pass
print(A.__mro__)
(<class '__main__.A'>, <class '__main__.B'>, <class '__main__.D'>, <class '__main__.C'>, <class '__main__.E'>, <class 'object'>)
可以看到继承的顺序。
4.6 静态方法、类方法以及实例方法和参数
class Date:
#构造函数
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
def __str__(self):
return "{year}/{month}/{day}".format(year=self.year,
month=self.month, day=self.day)
new_day = Date(2018, 12, 10)
print(new_day)
2018/12/10
def __str__(self)是实例方法,普通情况下类中定义的方法都是实例方法
class Date:
#构造函数
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
def tomorrow(self):
self.day += 1
def __str__(self):
return "{year}/{month}/{day}".format(year=self.year,
month=self.month, day=self.day)
new_day = Date(2018, 12, 10)
new_day.tomorrow()
print(new_day)
2018/12/11
new_day.tomorrow(),没有传入参数,python解释器会自动变成tomorrow(new_day)。
上面就是实例方法的使用。
接下来讲解静态方法:
class Date:
#构造函数
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
def tomorrow(self):
self.day += 1
def __str__(self):
return "{year}/{month}/{day}".format(year=self.year,
month=self.month, day=self.day)
date_str = "2018-12-31"
year, month, day = tuple(date_str.split("-"))
new_day = Date(int(year), int(month), int(day))
print (new_day)
2018/12/10
用.split先对字符串切片,然后实例化Date。这组方法有个缺陷,就是每次对Date实例化时,都需要先对字符串切片。
我们可以把处理date的逻辑拿到类中,就是定义一个静态方法。
class Date:
#构造函数
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
def tomorrow(self):
self.day += 1
# 静态方法不需要self参数,也不需要cls对象
@staticmethod
def parse_from_string(date_str):
year, month, day = tuple(date_str.split("-"))
return Date(int(year), int(month), int(day))
date_str = "2018-12-10"
new_day = Date.parse_from_string(date_str)
print(new_day)
2018/12/31
这样我们使用时,代码变精简了,不需要每次都写代码处理一次date。
但是静态方法不好的地方是,在return的时候采用硬编码方式(Date()),如果改一下类名称为MyDate,那么我们也要改掉return的Date为MyDate。
所以有了一个python中常用的方法,@classmethod
class Date:
#构造函数
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
def tomorrow(self):
self.day += 1
@staticmethod
def parse_from_string(date_str):
year, month, day = tuple(date_str.split("-"))
return Date(int(year), int(month), int(day))
# 要传递cls,代表类本身
@classmethod
def from_string(cls, date_str):
year, month, day = tuple(date_str.split("-"))
return cls(int(year), int(month), int(day)) # 直接返回cls,不是硬编码
def __str__(self):
return "{year}/{month}/{day}".format(year=self.year,
month=self.month, day=self.day)
date_str = "2018-12-10"
new_day = Date.from_string(date_str)
print(new_day)
2018/12/10
@classmethod方法里不是采用硬编码,传递cls参数。
classmethod貌似可以完全替代staticmethod,那么staticmethod的作用是什么?
假设在另外一种场景,要判断字符串是不是合法的:
class Date:
#构造函数
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
def tomorrow(self):
self.day += 1
@staticmethod
def parse_from_string(date_str):
year, month, day = tuple(date_str.split("-"))
return Date(int(year), int(month), int(day))
@staticmethod
def valid_str(date_str):
year, month, day = tuple(date_str.split("-"))
if int(year)>0 and (int(month) >0 and
int(month)<=12) and (int(day) >0 and int(day)<=31):
return True
else:
return False
@classmethod
def from_string(cls, date_str):
year, month, day = tuple(date_str.split("-"))
return cls(int(year), int(month), int(day))
def __str__(self):
return "{year}/{month}/{day}".format(year=self.year,
month=self.month, day=self.day)
print(Date.valid_str("2018-12-32"))
1990/2/1
28
在判断字符串时,不需要返回对象,只有判断(True or False),这时候就没有必要传递cls参数进去。
静态方法,类方法必须加装饰器,实例方法就是普通的函数。
4.8 数据封装和私有属性
from class_method import Date
class User:
def __init__(self, birthday):
self.__birthday = birthday
def get_age(self):
#返回年龄
return 2018 - self.__birthday.year
user = User(Date(1990,2,1))
print(user.birthday)
print(user.get_age())
1990/2/1
28
输出了birthday和年龄,但一般我们希望将birthday隐藏掉,不希望用户直接看到。
在python中是没有private的,做法是添加双下划线。
from class_method import Date
class User:
def __init__(self, birthday):
self.__birthday = birthday
def get_age(self):
#返回年龄
return 2018 - self.__birthday.year
user = User(Date(1990,2,1))
print(user.__birthday)
print(user.get_age())
print(user.__birthday)
AttributeError: 'User' object has no attribute '__birthday'
告诉我们没有这个__birthday,这样就相当于私有属性的封装。
私有属性是无法通过实例.__birthday来访问的,只能通过公共方法get_age间接获取__birthday。
当然,函数方法上也可以加双划线变为私有属性。
实际上,python封装私有属性,是对原有属性做变形,把名字改掉。
打印_classname__attr:
print(user._User__birthday)
1990/2/1
所以加双下划线不是从语言层面上来解决私有性,只是加了一些小技巧。把birthday变形成了_User__birthday。
4.9 python 的自省机制
自省是通过一定的机制查询到对象的内部结构
from class_method import Date
class Person:
"""
人
"""
name = "user"
class Student(Person):
def __init__(self, school_name):
self.school_name = school_name
user = Student("慕课网")
#通过__dict__查询属性
print(user.__dict__)
print(user.name)
{'scool_name': '慕课网'}
user
dict在python中是c语言实现的,所以效率很高,还有很多优化,这是个性能很高的数据结构。
我们理清关系,user是Student的实例,Student是Person的子类。
看两个输出,既然__dict__打印的是实例属性,为什么user.name打印出来的user没有进入dict呢?
因为name属于Person,是Person类属性,是Person对象空间里的值,并不是Student的属性,没有在Student的对象空间里。用.name这种方法,其实是会向上查找的。
print(Person.__dict__)
{'__module__': '__main__', '__doc__': '\n 人\n ', 'name': 'user', '__dict__': <attribute '__dict__' of 'Person' objects>, '__weakref__': <attribute '__weakref__' of 'Person' objects>}
再用Person.__dict__的时候,里面是有“name”的。
如果对user的属性添加值:
user.__dict__["school_addr"] = "北京市"
print(user.school_addr)
北京市
所以__dict__我们可以取出来,也可以添加值,可以完成动态操纵user对象。
print(dir(user))
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'name', 'scool_name']
dir会列出对象中所有的属性,比__dict__功能更加强大,但只有属性名称,没有属性值。
4.10 super真的是调用父类吗
class A:
def __init__(self):
print ("A")
class B(A):
def __init__(self):
print ("B")
b = B()
B
这个打印逻辑很简单,但某种情况下,我们希望再调用父类的init方法。
class A:
def __init__(self):
print ("A")
class B(A):
def __init__(self):
print ("B")
super().__init__()
b = B()
B
A
添加super函数,获取父类的init方法。
这里会有两个疑问:
- 既然B重写了A的构造函数(不一定要是init),为什么还要调用super?
- super的执行顺序是什么样的?
第一个问题回答:
在某些情况下,比如多线程的时候:
from threading import Thread
class MyThread(Thread):
def __init__(self, name, user):
self.user = user
# self.name = name 实际上不用做这一步
super().__init__(name=name) # 不用自己再写处理逻辑
定义自己的MyThread类,继承于Thread,定义初始化方法时,可以使用父类的方法。
class Thread:
_initialized = False
def __init__(self, group=None, target=None, name=None,
args=(), kwargs=None, *, daemon=None):
Thread类中初始化方法有个参数name,Thread有很多处理的逻辑,那我们可以直接调用父类,好处是可以重用代码。
第二个问题回答:
不要认为super是调用父类方法,执行顺序涉及到mro算法。
class A:
def __init__(self):
print ("A")
class B(A):
def __init__(self):
print ("B")
super().__init__()
class C(A):
def __init__(self):
print ("C")
super().__init__()
class D(B, C):
def __init__(self):
print ("D")
super(D, self).__init__()
print(D.__mro__)
d = D()
(<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>)
D
B
C
A
可以看到顺序是D、B、C、A,如果是调用父类方法这种逻辑,那么打印应该是D、B、A、C。
4.11 mixin继承案例
python是支持多继承的,但是也不推荐编码使用多继承,设计不好很容易造成关系混乱,mro算法也可能造成预料不到的问题。python中推荐的做法是mixin(混合模式)的模式。
class GoodListViewSet(CacheResponseMixin,mixins.ListModelMixin,
mixins.RetrieveModelMixin,viewsets.GenericViewSet):
"""
商品列表页,分页,搜索,过滤,排序
"""
只写一个类,就能完成商品列表页,分页,搜索,过滤,排序,实际就是集成了多个mixin,这些mixin只写了一个方法。
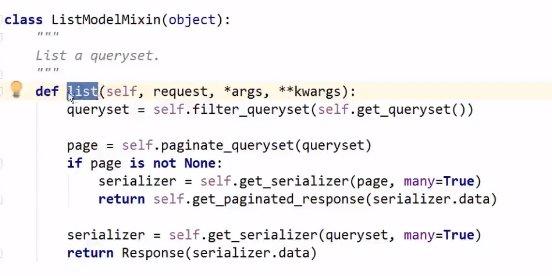
ListModelMixin也是一个类,但只有一个方法(获取商品的列表)。
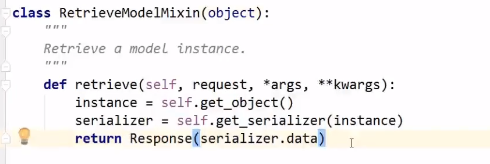
RetrieveModelMixin也只有一个函数,返回商品详情。
所以mixin模式,就是自己写一个mixin类,这个类只有一个方法(干一件事情)。
- mixin功能单一,只提供一个方法
- mixin不和基类关联,GenericViewSet才是真正的基类,mixin可以和任何基类组合,基类不和mixin关联也能初始化
- 在mixin中不要使用super
4.12 python中的with语句
首先介绍下try,except,finally
try:
print ("code started")
raise KeyError
except KeyError as e:
print ("key error")
code started
key error
如果改为IndexError
try:
print ("code started")
raise IndexError
except KeyError as e:
print ("key error")
code started
Traceback (most recent call last):
File "D:/py_tutrial/AdvancePython-master/chapter04/ttt.py", line 4, in <module>
raise IndexError
IndexError
这样就没有捕获到error,如果我们知道错误类型,那可以该except语句里的代码,如果不知道错误类型,那么可以加else语句
try:
print ("code started")
# raise IndexError
except KeyError as e:
print ("key error")
else:
print ("other error")
code started
other error
注意else是在没有抛异常时运行的,有异常且无法捕获时无法运行。
还可以加finally,finally后的语句不管前面有没有错误都会运行
try:
print ("code started")
raise KeyError
except KeyError as e:
print ("key error")
else:
print ("other error")
finally:
print ("finally")
code started
key error
finally
finally 有什么用呢?
try:
f_read = open("bobby.txt")
print ("code started")
raise KeyError as e:
f_read.close()
except KeyError as e:
print ("key error")
f_read.close()
比如打开一个文件,如果没有异常,就要close关闭会话,如果有异常,就不会执行close,那么要在
except里写一个close。如果还有其它异常,都写close就很繁琐。close操作其实可以写在finally中。
try:
f_read = open("bobby.txt")
print ("code started")
raise KeyError as e:
except KeyError as e:
print ("key error")
finally:
f_read.close()
所以finally一般是用来做资源释放的。
解下来讲一下try,finally执行过程:
def exe_try():
try:
print ("code started")
raise KeyError
return 1
except KeyError as e:
print ("key error")
return 2
else:
print ("other error")
return 3
finally:
print ("finally")
return 4
result = exe_try()
print(result)
code started
key error
finally
4
加了return后返回4,正常逻辑是raise一个error,进入except return 2,那为什么最后是return 4?
因为先return 2,那么会把2要让栈里,然后return 4,再把4压入栈,最后结果就是栈顶4。
python的with语句(上下文管理器)就是简化try,except,finally 这种用法。
在魔法函数中讲过python的协议,类只要实现了某些魔法函数,就可以看做某种类型的协议。with上下文管理器协议涉及到了两个魔法函数__enter__,__exit__,上下文管理器协议就可以直接使用with语句。
#上下文管理器协议
class Sample:
def __enter__(self):
print ("enter")
#获取资源
return self
def __exit__(self, exc_type, exc_val, exc_tb):
#释放资源
print ("exit")
def do_something(self):
print ("doing something")
with Sample() as sample:
sample.do_something()
enter
doing something
exit
实际上我们并没有调用enter、exit,with自动调用了这两个魔法函数。调用顺序是enter、do_something、exit,所以可以去enter里获取资源,去exit里释放资源。
4.13 contextlib简化上下文管理器
本来自己实现上下文管理器,要写一个class和对应的魔法函数。
为了简化实现,python内置了contextlib。
import contextlib
@contextlib.contextmanager # 装饰器可以把函数变为上下文管理器
def file_open(file_name):
print ("file open") # 可以看成enter
yield {} # 必须是一个生成器
print ("file end") # 可以看成exit
with file_open("bobby.txt") as f_opened:
print ("file processing")
file open
file processing
file end

 浙公网安备 33010602011771号
浙公网安备 33010602011771号