李宏毅深度学习笔记-无监督学习-深度自动编码器
什么是Auto-encoder

我们首先去找一个encoder,input一个东西,比如图像识别做MNIST的话,就是input一张手写数字图片(28 *28 维像素点),那就是input 784维的向量。这个encoder可能是一个神经网络,output就是一个code,这个code会远比784维小的,所以encoder有类似压缩的效果。这个code代表了原来图像的某种精简有效的表示。
不过现在做的是无监督学习,你可以找很多图像作为NN encoder的input,但是没有任何的output ,我们不知道code应该长什么样子,要学习一个神经网络必要要有input和output,只有input就没有办法学习。
那没有关系,我们先学习一个NN decoder,input一个向量,通过NN decoder得到的output是一张图像,即input一个code,根据code里面的信息,output一张图像。但是你也没办法训练 NN decoder,因为只有output没有input。
这两个神经网络,encoder和decoder,都没有办法单独训练,但是我们可以把它们接起来,然后一起训练。也就是说input一个图像,变成code,再把code通过decoder变成原来的图像,那encoder和decoder就一起学习。
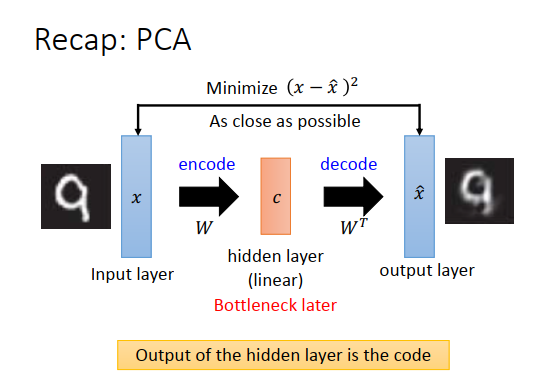
在PCA里面遇到过非常类似的概念。PCA做的事情是,input一张图像\(x\),在之前的例子里把\(x\)减去平均值\(\bar x\)后当做input,这边我们把\(\bar x\)省略掉,因为通常做NN的时候,都会先对数据做标准化(均值为0,方差为1),所以\(\bar x\)一般就等于0了。
把\(x\)乘上一个权重(W,成分向量组成的矩阵),经过一个线性隐藏层得到\(c\),这个\(c\)是对应成分的权重,\(c\)再乘以矩阵\(W\)的转置得到\(\hat x\),\(\hat x\)是成分的线性组合重构而成。
在PCA里面要做的事情就是最小化\(x\)和\(\hat x\) 的欧式距离。把PCA看成神经网络的话,\(x\)就是input layer,\(\hat x\)就是output layer,中间成分权重\(c\)就是一个线性的隐藏层。中间这个隐藏层我们通常叫做bottleneck layer。
为什么叫做bottleneck layer?
因为现在做的是降维,所以成分的数目通常比input的维度要小得多,那么\(c\)就是一个很窄的层,所以我们叫它bottleneck layer(瓶颈层)。
\(c\)前面的部分就是在做encode,\(c\)后面的部分就是在做decode。如果把成分的权重\(c\)看成是code的话,那么decoder就是把code变回原来的图像。
那么隐藏层的output,就是我们要找的code。
PCA就是这么做的,也可以使用梯度下降求解\(W\)。
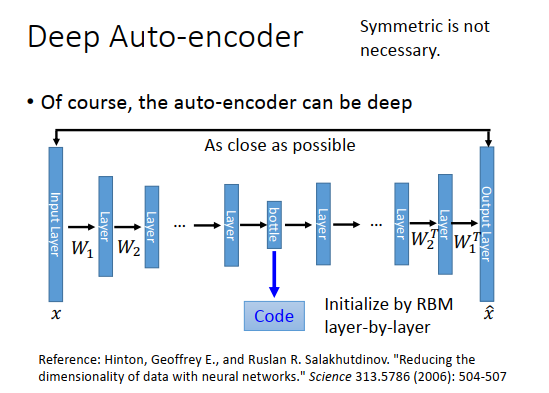
PCA只有一个隐藏层,那我们可以加入更多的隐藏层,你可以兜一个很深的神经网络,有很多很层。你input一个\(x\),得到\(\hat x\) ,训练目标是\(x,\hat x\)越接近越好,参数就用反向传播进行学习。中间会有一个特别窄的层(神经元很少),这个层的output就是一组code。从input到bottleneck layer的部分就是encoder,从bottleneck layer到\(\hat x\)就是decoder。
总结以上过程就是input做encoder得到bottleneck layer的output,bottleneck layer的output做decoder变成原来的图像。
按照PCA我们看到的,从input到第一个隐藏层的\(W_1\),要跟最后一个隐藏层到output中的\(W_1^T\)互为转置。在训练的时候可以只训练\(W_1\) ,这样auto-encdoer的参数就少一半,可以防止过拟合。但权重互为转置不是必要的,现在常见的做法就按照反向传播计算参数。
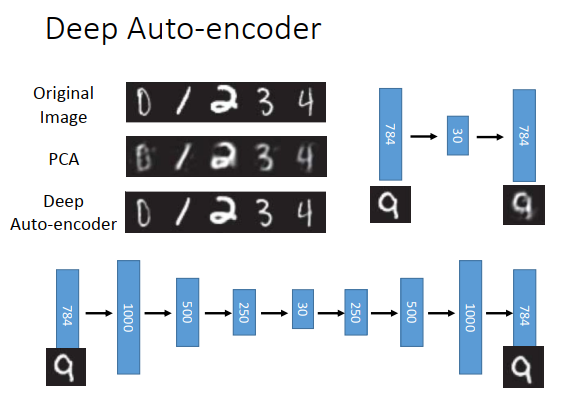
上图数字是原来MNIST上的原始图像,如果做PCA,从784维降到30维,再从30维重构回784维,得到的图像如上图左上方第二张图所示,可以看到它是比较模糊的。如果用deep auto-encoder的话,在Hinton的论文里做法如上图最下方所示,784维扩展到1000维,然后降到500维,再降到250维,再降到30维,你很难知道他为什么设计成这样,然后再依次变回到784维,你会发现它的结果会比较好。
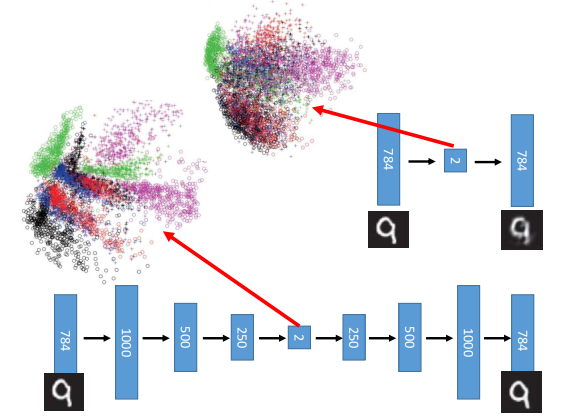
如果降到2维再做可视化,你会发现做PCA后,在这个二维的平面上,所有的数字混在一起,上图最上方不同颜色代表了不同的数字。如果使用deep auto-encoder的话,会发现数字是分开的,上图左边的图变成一群一群的。
自动编码器 - 文本检索
auto-encoder也可以用在文字处理上,比如我们想把一篇文章压成一个向量,压成一个code。
为什么我们要把一篇文章压成一个code?
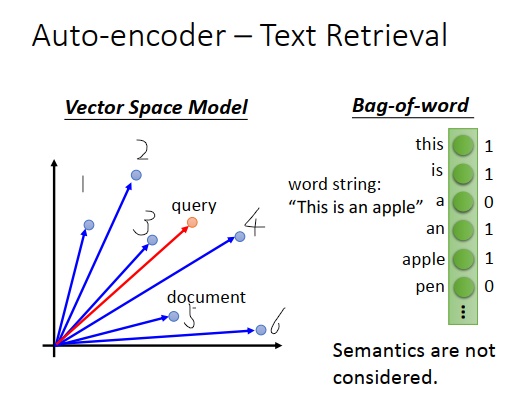
假设我们要做文字的搜寻,在文字搜寻里面有一招,叫向量空间模型。向量空间模型非常的单纯,把每一篇文章都表示成空间中的一个向量,都是空间中的一个点。上图左边蓝色的圈圈就是一篇文章,接下来假设使用者输入一个查询的词汇,把查询的词汇也变成空间中的一个点,然后计算这个输入词汇和每一篇文章的内积(或者余弦相似度等等),余弦相似度会有标准化的效果,可能会有比较好的结果。如果距离最近(余弦相似度的结果最大),你就会检出这些文章,比如输入红色点的查询,可能会检出3和4这两篇文章,它们跟红色这个查询的余弦相似度比较大。
这个模型要有效,取决于你现在表示的好不好(把文章表示为向量)。
怎么把文章表示为一个向量呢?
一个最基本的方式叫词袋,词袋的思想就是构造一个向量,向量大小是词典的大小,假设世界上有十万个词汇,那这个向量的大小就是十万维。如果现在有篇文章只有一个句子“this is an apple”,那把它表示为一个向量的话就如上图右边所示,“this"这维是1,“is”这维是1,“a”这维是0,“an”这维是1,
“apple”这维是1,其他都是0。
有时候你想把它做得更好,会乘上逆文档频率,向量里每一维不只是用词汇在文档出现的次数,会让次数再乘上一个权重,权重代表词汇的重要性,重要性可以用不同的方法衡量,比如逆文档频率。比如“is"可能出现在每个文档,所以重要性很低,那"is"维就变为1 * (一个比较小的值),“apple”只出现在个别文章,重要性比较高,所以乘上一个比较高的值,等等。
用词袋模型效果很弱,没有办法考虑语义相关的东西,比如不知道“台湾大学”指的是“台大”,不知道“apple”跟“orange”都是水果等等。对词袋模型来说,每个词汇都是独立的,词汇没有任何相关性。
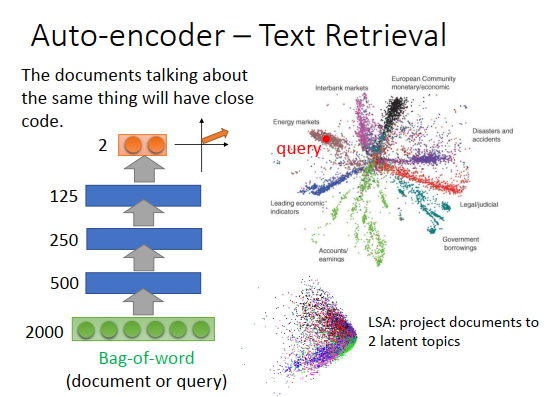
可以用auto-encoder让语义被考虑进来,举例来说,你学习一个auto-encoder,input是一篇文章或者一段文字(query),这个在Hinton的论文上是有实验的,他只用了比较小的词典大小,只有两千个词汇,使用词袋模型就把一篇文章变成了一个向量。把这个向量通过一个encoder,把它压成二维。Hinton用的语料库,文章会标明它属于哪一类。上图右边不同颜色的点代表文章属于哪一类,你会发现同一类的文章,都集中在一起。今天要做搜寻的的时候,输入一个词汇(查询词、query),那就把query通过这个encoder,把它变成一个二维的向量。假设query落在上图右边红色点处,那query跟energy marketing有关,就把那一类的文章检出来。用auto-encoder效果好的惊人,用LSA效果就没这么好。
自动编码器 - 类似图像搜索

auto-encoder也可以用在图像搜索上面,可以用在以图找图上。
怎么做以图找图?
最简单的方法就是,假设上图是要找的对象(query),计算这个query跟你在图像库里面的图片的相似度,比如可以计算它们在像素点上的相似程度,那么最想的几张就是要检出的结果。

如果只是这么做,其实是得不到太好的结果。如果query如上图是迈克尔杰克逊,那么那迈克尔的图像去跟图像库其他图像计算相似度的话,找出来最像的几张会如上图所示。你会发现和马蹄铁很像。如果只在像素点层面上做比较,是找不到好结果的。
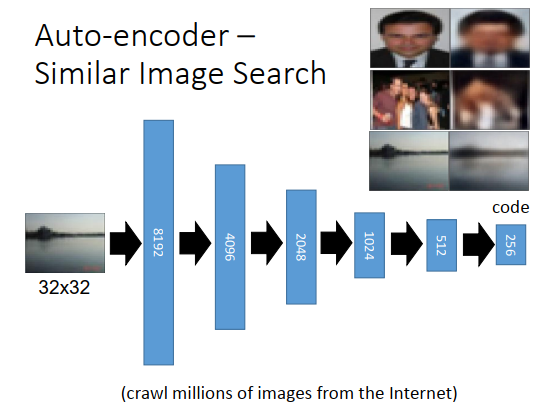
可以用deep auto-encoder把每一张图像变成一个code,然后在code上面再去做搜索,而且学习一个auto-encoder是无监督的,所以你收集多少数据都行。
怎么把它变成一个code?
上图最下方也是从Hinton的论文上来的,input一个32 *32 图像,其实每一个像素点用RGB表示,所以是32 *32 *3,那么把图像变成8192维的向量,再变成4096维,再变成2048维,1024维,最后到256维,也就是说这张图像用256维的向量来描述。
再把这个code通过另一个decoder,再变回原来的图像,得到的重构结果如上图右上方所示。

如果不是在像素点上算相似度,而是在code上计算相似度的话,你就会得到比较好的结果。

比如用迈克尔的图像做input,找出来的都是人脸,虽然这些图像在像素点层面上看起来是不像的,但是通过很多个隐藏层,把它们转成code的时候,在256维的空间上,它们是很像的。比如有的是黑头发,有的是金头发,通过很多转换后可能在256维里面,有一个维度就代表人脸,所以知道说这些图像都对应到人脸的那个class。
自动编码器-预训练

Auto-encoder过去有一个很好的应用,可以用在预训练上面。我们知道在训练一个神经网络的时候,有时候很烦恼怎么做参数的初始化, 那有没有一些方法可以帮助你找到一组比较好的初始化呢,那可以用auto-encoder来做预训练。
怎么用auto-encoder做预训练?
如果要做MNIST的识别任务,可以建一个神经网络,input是784维,然后output是10维。在做预训练的时候,就先训练一个auto-encoder,input是784维,中间有个1000维的向量,再变回784维,希望input和output越接近越好。这里做的时候要稍微小心一点,因为我们一般做auto-encoder的时候会希望code比原数据维度小,如果比原数据维度大的话,有可能就不学习了,把原来的向量放大1000维,再降回原来的向量就结束了。这样就什么都没学习,得到一个恒等的矩阵。所以如果发现code比input维度要大的时候,要加一个很强的正则化项,比如对隐藏层做L1正则,希望1000维的结果是稀疏的,希望1000维里只有某几维是有值的,其它维都是0,避免恒等变换。

学习好一个auto-encoder之后,我们把\(W^1\)固定住。
接下来把图像库里的数字图像都变成1000维的向量,然后再学习另一个auto-encoder,把1000维的向量变成1000维的code,再把1000维的code转回1000维的向量,让input(\(a^1\))和output(\(\hat{a}^1\))越接近越好,然后把\(W^2\)固定下来。
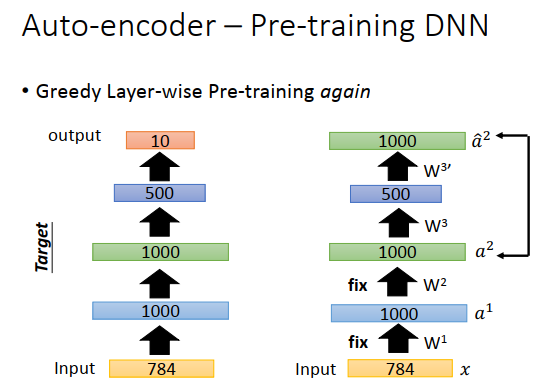
固定住\(W^2\)的值后,再学习第三个auto-encoder。第三个auto-encoder的input是1000维,code是500维,output是1000维,得到\(W^3\)并固定。
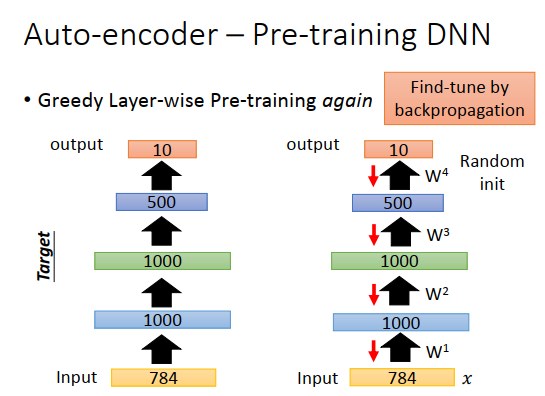
那么\(W^1,W^2,W^3\)就是你在学习整个神经网络时的初始化参数值,然后随机初始化参数\(W^4\),最后用反向传播调整参数,这个称之为微调(因为\(W^1,W^2,W^3\)已经是很好的权重了)。
这招预训练在过去是需要的,现在神经网络基本不用预训练了,但是预训练有个妙用,就是如果标注数据很少而未标注数据很多时,可以用大量的未标注数据去把\(W^1,W^2,W^3\)先学习好,那最后在标注数据上训练时只要微调\(W\)就好了。所以预训练在你有大量未标注数据的时候是有用的。
降噪自动编码器
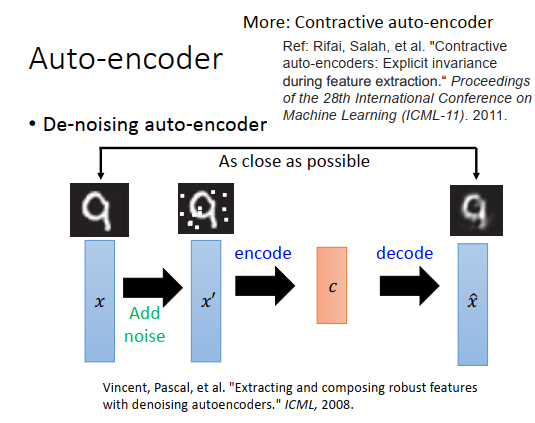
有个方法可以让auto-encoder做得更好,叫做降噪自动编码器。
概念很简单,把原来的input \(x\)加上一些噪声变成\(x'\),对\(x'\)encode以后变成code c,再把c decode回来变成\(\hat x\),但是要注意本来auto-encoder是让input(\(x'\))跟output(\(\hat x\))越接近越好,在这里则是让\(x\)跟\(\hat x\)越接近越好,这样学习出来的结果比较鲁棒。encoder不只学习了encode这件事,还学习到了把杂志过滤掉这件事。
还有另外一个方法叫做压缩自动编码器。在学习这个code的时候,加上一个约束(当input有变化时对code的影响要最小),这件事情很像降噪自动编码器。降噪自动编码器是说家里噪声后,要重构会原来没有噪声的结果,压缩自动编码器是说当input变了(也就是加了噪声),对code的影响很小。

还有很多非线性降维的方法,比如受限玻尔兹曼机。

还有深度信念网络,这个和深度神经网络是不一样的东西,和受限玻尔兹曼机都是图协模型。
CNN自动编码器
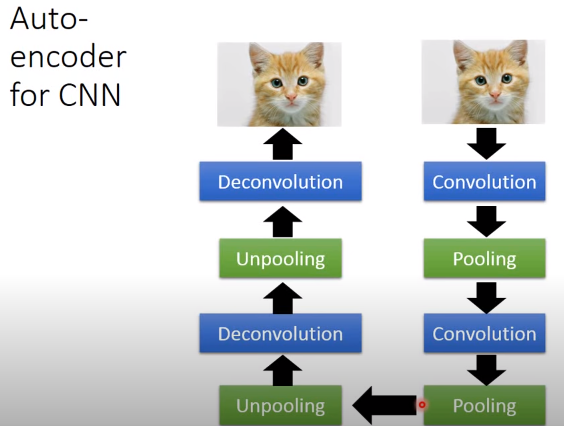
如果要处理的对象是图像的话,我们知道一般用CNN,会有一些卷积层、池化层,卷积和池化交替让图像变得越来越小,最后去做展平(flatten)。
做auto-encoder的话,要有一个encoder和一个decoder,如果encoder的部分是做卷积-池化-卷积-池化,那么理论上decoder应该和encoder做相反的事情(unpooling-deconvolution-unpooling-deconvolution)。但是这个反池化和反卷积到底是什么呢?训练的标准就是让input和output越接近越好。
unpooling
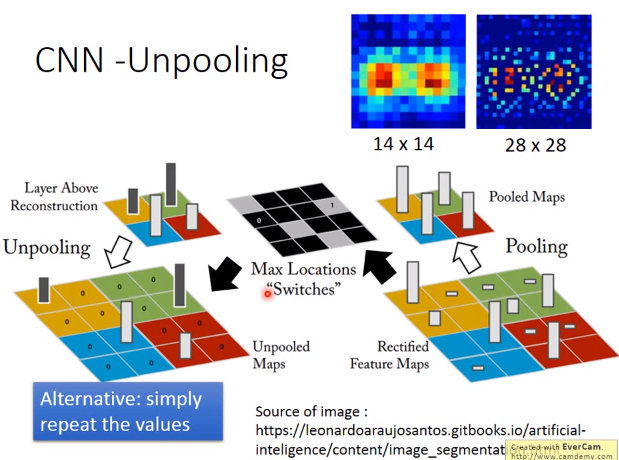
我们知道做pooling的时候,比如做max pooling时有一个16 *16矩阵,分成4组(4个颜色),从每组里面挑一个最大的(上图右下方白色柱形,越高代表越大),然后你的图像就变成原来的四分之一(上图右上方)。
如果是做unpooling的话,你要先记得做pooling时是从哪里取值,如上图黑白图片里的,白色方块就取值的记录。做unpooling,要把原来比较小的矩阵扩大,比如上图左下方,变成了原来的4倍。
怎么做呢?
之前记录的pooling取值位置就可以派上用场,比如记录了从左上角取值,那unpooling的时候就把该值放到左上角,其余位置为0(上图左下方黄色区域,左上角为原值,其余位置为0),这个就是unpooling的一种方式。
做完unpooling后本来一张比较小的图像会变得比较大,如上图右上方,原来14 *14的图像变成28 *28的图像,会发现就是把原来的14 *14的图像做一下扩散,有些地方就是补0(蓝色区域),原来14 *14的值,扩散到28 *28里面,都会加上三个0。
上述方法不是唯一的做法,在keras,是直接复制值,不用记住原来pooling的位子,扩大时使用同一个值。
deconvolution

比较难理解的是deconvolution。
事实上,deconvolution就是convolution,举个例子解释下。我们做一个一维的convolution,假设input有5个维度,filter size是3,那我们就把input的三个值分别乘上红色、蓝色、绿色的权重,得到一个output(上图左边做上面3个圆点),然后把filter 平移一格,三个值乘上红色、蓝色、绿色的权重得到下一个output,在平移一格,又得到一个output。那deconvolution和convolution相反,所以本来是三个值变成一个值,那deconvolution就应该是一个值变三个值。一个值分别乘上红色、绿色、蓝色的权重变成三个值,如果有重叠就加起来。
deconvolution等同于在做convolution,为什么呢?
等同于,input是三个值,然后做padding,在旁边补0,接下来一样做卷积,3个值乘上绿色蓝色红色权重得到一个值,以此类推如上图右边所示。你会发现上图右边框框做的事情和中间框框做的事情一模一样,检查中间框框中间三个加起来的值(1 * 绿色权重+2 * 蓝色权重+3 * 红色权重),等于右边框框中间的值(4 * 绿色权重+5 * 蓝色权重+6 * 红色权重)。
右边的deconvolution和左边的convolution不同点是什么?
它们的权重是相反的,上图左边到9的权重是红、蓝、绿,右边到10的权重是绿、蓝、红,正好相反。但是deconvolution一样也是在做convolution这件事。

之前讲的降维,一般是用encoder把原来的图像变成小的维度,同时也训练了一个decoder,这个decoder是有妙用的,可以用来产生新的图像。把学习好的decoder拿出来,给它一个随机的input 数字,它的output希望是一张图。
那MNIST来训练一下,把每一张784维的图像通过一个隐藏层投影到二维,再用一个隐藏层解回原来的图像。encoder部分的二维向量画出来如上图左边所示,不同颜色的点代表不同数字,然后在红色框框里等间隔抽样一个二维向量出来,丢进NN decoder里面,output一个图像。这些二维向量不见得是某个图像压缩后的结果,不见得对应原来的图像,就是某个二维向量。得到的结果如上图右边所示。
More about auto-encoder
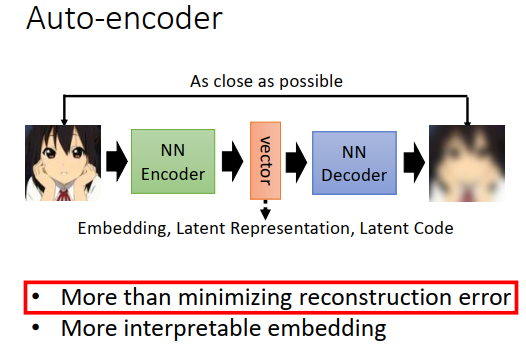
auto-encoder里面就是有一个encoder,output一个向量,有时候我们叫这个向量为embedding、latent representation、latent code。有一个decoder,把向量还原为图像。
训练的时候,要最小化重构误差,让encoder的输入和decoder的输出越接近越好。今天要讲两个内容:
- 为什么是最小化重构误差,有没有其他做法?
- 让encoder的向量更有解释性
为什么是最小化重构误差

为什么要做embedding,希望embedding可以做什么事情呢?
我们希望embedding可以代表encoder中输入的对象,看到embedding就可以想到原来的对象。比如你看到耳机,就会中野三玖,不会想到中野一花。
我们有一个encoder,输入一张图片,就output一个embedding,比如上图左下方,input三玖图片就输出一个蓝色的embedding,输入凉宫的图片就output一个黄色的embedding。
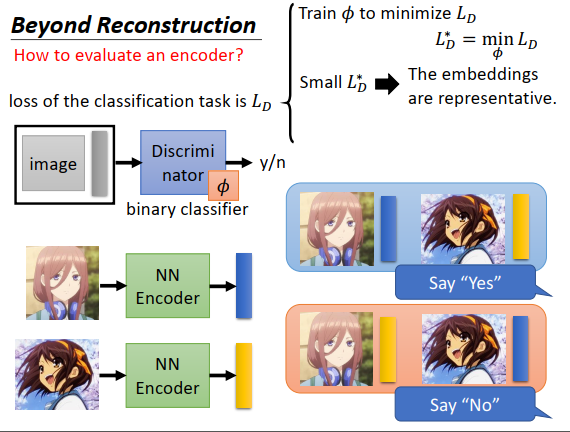
我们如何知道一个encoder是好还是不好?
训练一个判别器(想象成一个二分类器),输入一张图片和一个embedding,输出这两者是否是一对。你需要训练数据去训练这个二分类器,如上图右下方所示,如果是一对输出就是“Yes”,如果图片配错了embedding,就对机器说这些是负例,要输出“No”
确定一个损失函数\(L_D\),寻找最小化这个损失函数的参数,假设二分类器的参数为\(\phi\) ,最低的损失为\(L_D^*\),如果\(L_D^*\)非常小,说明这个二分类器效果很好,代表这个embedding非常具有代表性。
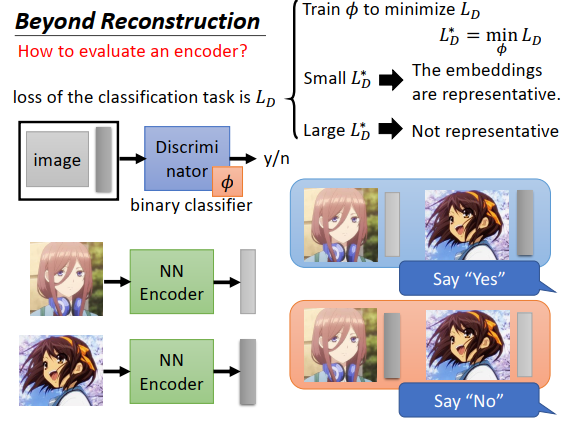
如果有一个很差的encoder,output出来的向量都是灰色的,三九和凉宫的embedding看起来没有什么不同,那么三九和凉宫的embedding交换(配错),二分类器就无法区分,那损失函数值\(L_D^*\)就会非常大,说明这个embedding不具有代表性,机器无法判断embedding和图片是否是一对。
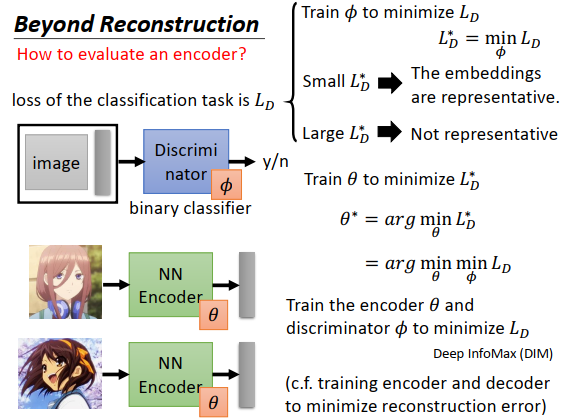
这种想法提供了一种新的训练encoder的方式,过去训练encoder的时候是要最小化重构误差,现在我们知道可以训练一个二分类器去评估一个encoder,那么接下来我们要做的事情就是调整encoder的参数,让encoder去学习使得在当前评估标准下结果最好。
我们的评估标注就是\(L_D^*\)越小越好,于是我们训练encoder的目标就变为最小化\(L_D^*\),如果encoder的参数是\(\theta\),那就是寻找能使\(L_D^*\)最小的\(\theta^*\)。
\(L_D^*\)是什么呢?
我们先定义好一个损失函数\(L_D\) ,\(L_D^*\)就是找一个\(\phi\)后最小的\(L_D\),则\(L_D^*=\min\limits_{\theta}L_D\)。
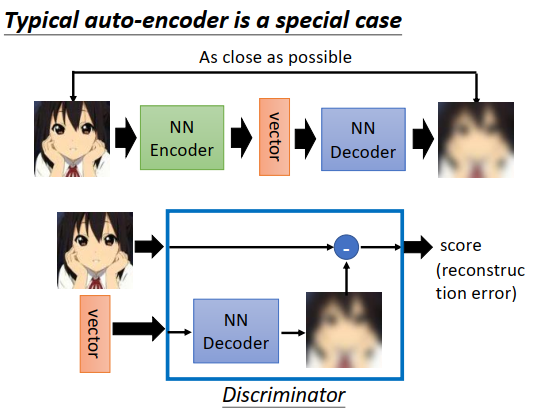
原来我们熟悉的auto-encoder,其实就是去训练一个二分类器看encoder是好是坏的一种特殊情况。
为什么说是特殊情况?
今天一般的auto-encoder里面,我们的判别器(discriminator),也就是一个二分类器,接收一张图片和一个向量,输出一个分数代表这个图片和向量是否是一组的。如果把discriminator里面的神经网络架构(运作过程)做一下设计,改成之前讲得二分类器的训练方式,那么auto-encoder就是二分类器看encoder是好是坏的一种特例。
假设discriminator里有一个NN decoder,接收一个向量,输出一个和输入图片大小一样的图片,然后把两张图片做相减,计算它们之间的差异,你会发现这个discriminator的输出就是重构误差。也就是在原来典型auto-encoder里面(上图最上方),可以把输入到输出的过程看成是一个二分类器,而重构误差就是二分类器输出的值。
在训练的时候,给它图片和embedding向量,输出的重构误差要越小越好,不过在典型的auto-encoder里面没有考虑负例。
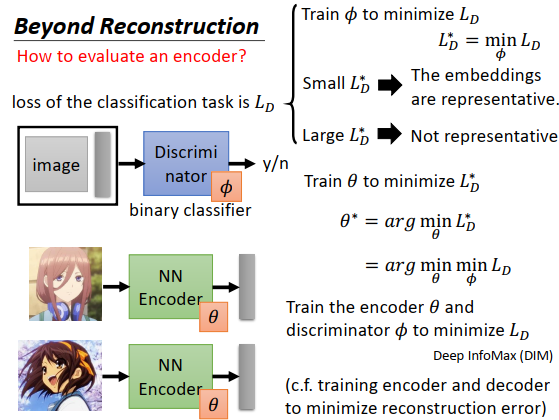
要同时找最好的encoder和最好的discriminator,一起去最小化\(L_D\) 。
这一招被用在Deep infomax,这个discriminator可以任意设计,可以给discriminator不同的损失函数,结果也会不太一样。
我们这边说,当我们训练encoder的时候,是和discriminator一起训练的,这件事就好像训练一般的auto-encoder的时候,同时训练encoder和decoder,去最小化重构误差。
顺序数据

如果数据是有顺序的,比如是一篇文章,有一堆句子,句子是按照某种顺序排列的,那这个时候就可以做更多不同的变化。
除了训练一个auto-encoder,输入自己预测自己之外,你还可以训练一个model,它是输入一个句子,预测前一个句子跟下一个句子,这个概念叫做skip thought。这个概念跟训练一个词嵌入向量是很像的,我们说训练词嵌入向量时如果两个词汇上下文都很像,那这两个不同的词汇语义是相近的,这个和skip thought的概念是一样的,只不过skip thought扩展到了句子的层级,也就是说两个不同的句子,如果他们的上下问都很像,那这个两个句子应该有同样的意思。
举例来说
有人会说“啊,这个东西要多少钱”,另外一个人回答说“要十块”。
有人会说“这个东西多贵”,另外一个人回答说“要十块”。
那“多少钱”和“多贵”,如果用skip thought这个model,会知道说答案都是一样的,那这两个问句的意思应该是一样的。
quick thought是skip thought延伸的想法,看名字就知道说是训练比较快的。skip thought往往是很花时间的,因为不只是要训练encoder,还要训练decoder,还要去产生前一个句子和后一个句子,这个计算是很大的。在quick thought里面只学习encoder,不学习decoder。
quick thought的想法是说,把每一个句子都丢到encoder里面,output一个embedding向量,接下来就不训练decoder。
不训练decoder,怎么训练encoder(Enc())?
每一个句子(上图current的句子)要跟它的下一个句子(上图next的句子)的output的embedding向量越接近越好。如果是随机的句子(上图random的句子),则要跟current的句子的embedding向量越远越好。quick thought论文里讲的更具有一般性,说什么才是一个好的embedding,就是现在学习一个分类器,接收某个句子的embedding和该句子下一个句子的embedding,然后再接收随机句子的embedding,如上右下方所示,接收了4个embedding,然后分类器可以正确判断哪个句子是下一个句子。分类器和encoder是共同训练的,一直训练下去就可以得到一个好的encoder。实际分类器做的事情是很简单的,把现在句子encoder的output和其他句子encoder的output计算内积,内积越大代表是下一个句子的概率越高,实际上就是计算current sentence的embedding向量和next sentence的embedding向量并希望它们越接近越好,和random sentence的embedding向量越远越好。
在quick thought的时候,一定要有random抽样一些句子,如果没有random,我们让所有句子都有一样的embedding 向量,也满足current就和next越接近,为了避免这个问题,还要加条件说要跟random越远越好。
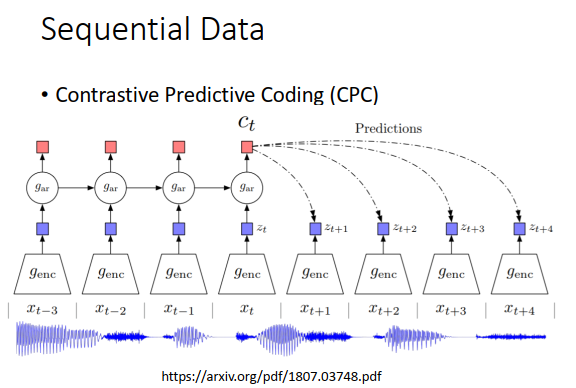
有另外一个技术叫做Contrastive predictive coding(CPC),训练一个encoder(genc),把声音讯号的一小段encode得到它的embedding(用\(z\)表示)。训练目标是希望encoder output的embedding可以拿去预测接下来同一个encoder会output的embedding。
怎么让embedding更容易解释
特征分离
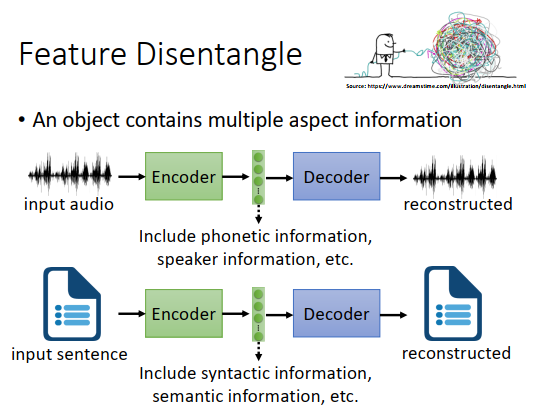
第一个要讲的概念叫做feature disentangle(特征分离),一般auto-encoder的input对象可能是图像、声音、一段文字,这些对象包含了各种各样复杂的资讯,比如一段声音里面不只有文字的资讯、语音内容的资讯、还包含了说话人声音的特质、环境里的噪音等等。一段文字也是一样,有语义的资讯、语法的资讯。一张图片里面有图片风格的资讯、里面有什么部件的资讯。但是我们用一个向量来表示输入对象,显然向量里面某些维度,比如input一段声音讯号,通过encoder,然后用decoder解回来,这个向量可能包含了这个声音里的内容咨询(它里面讲了什么话)、speaker资讯(说话的是男生还是女生、是老人还是小孩),但是我们不知道这个向量里哪些维度是说话人的speaker资讯、哪些维度是内容的资讯。
我们希望encoder可以自动告诉我们哪些维度是内容的资讯,哪些维度是speaker的资讯。

我们希望encoder输出一个向量后,比如这个向量是200维,前100维是内容的资讯(这句话说了什么东西),后200维是speaker的资讯,这样我们就可以很容易知道向量里哪些部分是speaker的资讯,哪些部分是内容的资讯。
这个想法也可以有个变形,有两个encoder,一个encoder专门抽内容的资讯,另外一个encoder专门抽出语者的资讯,把两个向量拼在一起丢给decoder,才能还原原来的信号。这边简化了问题,声音讯号里除了内容、语者资讯,可能还有其他的资讯,比如噪音的资讯、麦克风的资讯等等。
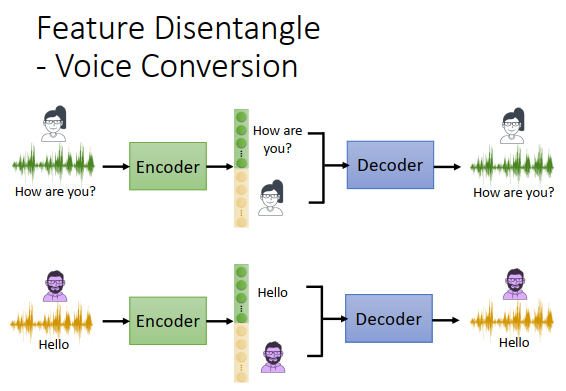
特征分离在语音上有什么用?
假设你训练了一个encoder,可以把声音内容资讯和语者资讯切开
某一个女生说“how are you”,丢到encoder里面,encoder会把“how are you”(内容资讯)放在绿色向量里面,把"女生"(语者资讯)放在黄色向量里。
某一个男生说“hello”,“hello”放在绿色向量里面,“男生”放在黄色向量里。
你可以把“how are you”的向量和“男生”向量结合起来,丢到decoder里,这样就可以用男生的声音说“how are you”,这样就可以做一个变声器。

同一个句子不同人说出来效果是不一样的,比如一个老师叫你读博,你会直接拒绝。但是如果用新垣结衣的声音来说,你可能就接受了,所以变声器是有用的。
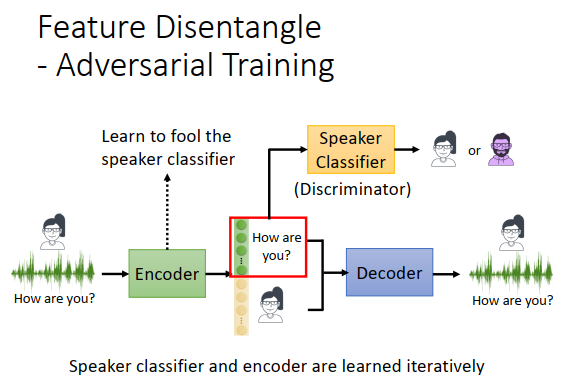
那要怎么做特征分离呢?
用对抗训练的概念,今天到底要怎么训练一个encoder,让前100维代表内容的资讯,后100维代表语者的资讯呢?
我们去训练一个语者的分类器,接收encoder 的前100维output向量(embedding向量),判断语者是男是女。然后encoder做的事情是想办法骗过这个语者的分类器,让语者分类器的准确率越低越好,让它统统都猜错,就跟随机一样。如果encoder 成功骗过语者分类器,语者分类器接收的是前100维的向量,那么encoder就学到有关语者的任何资讯都不可以放在前100维(放在里面意味着语者分类器可以因此提高准确率)。
实际会用GAN来训练语者分类器,也就是说语者分类器就是一个判别器,encoder是一个生成器,语者分类器和encoder是迭代训练的,先训练语者分类器,再训练encoder,在训练语者分类器,再训练encoder......。
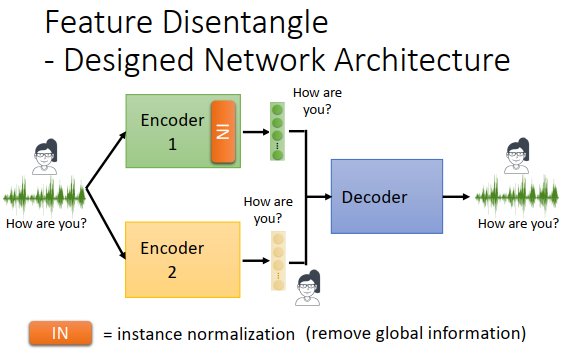
代表不同资讯的embedding,是用不同的encoder输出的,我们其实也可以用更简洁的方式,就是直接改encoder的架构,抹掉不希望出现的资讯。我们可以想办法设计神经网络的架构,可以把我们不要的资讯过滤掉。举例来说,有一种layer叫做instance normalization(IN,实例规范化),可以抹掉global信息(整个对象每个小部分都有的资讯)。语音讯号里面每个片段都有的资讯可能是“说这句的人”的资讯,所以通过encoder(加了IN)之后,就抹掉了语者的资讯,可能只保留了跟内容有关的资讯。
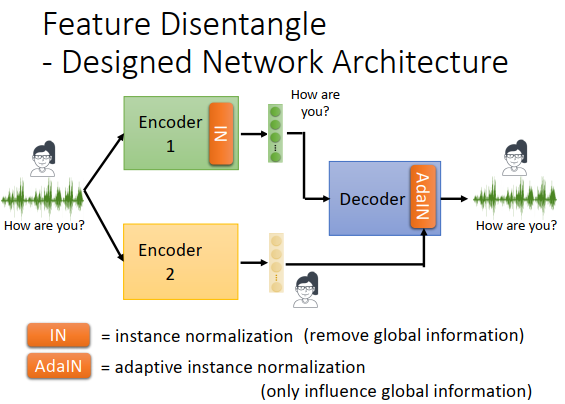
但只这么做是不够的,虽然encoder1没有包含任何语者的资讯,但并不意味着encoder2没有包含内容的资讯。解决方法是一个可能的设计是 在decoder上加一个特别的layer,叫做adaptive instance normalization(AdaIN,自适应实例规范化)。
原来是把两个encoder的输出直接接在一起,丢进decoder去还原声音讯号。但是现在decoder处理两个embedding向量的方法不同,直接接收encoder1的输出,而encoder2的输出在decoder中要加在AdaIN里,AdaIN会调整global信息,如果adaptive instance layer变化了,那么每个句子每个片段都会做改变,所以encoder2输出的向量会改变decoder输出的句子,那么encoder2里面就不能放语音内容的资讯,改变语音内容就不对了(变声器之类的,不会改句子),encoder2里只能放语者的资讯(是global信息)。decoder把encoder1的输出当做一般的输入,把encoder2的输出做特别的处理,然后还原声音讯号。你也可以用这种设计神经网络的方法把不同的资讯分开。

这个是用对抗训练做的结果,把一个人的声音转成另一个人的声音。
离散表示
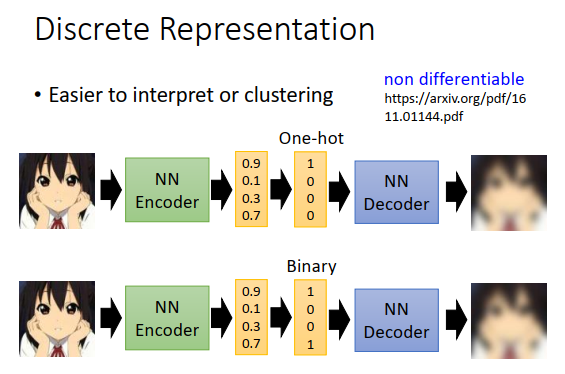
过去训练auto-encoder的时候,embedding都是连续的向量,一般给一个连续的向量,你也搞不清楚到底在干什么。所以我们进一步期待,encoder能不能output一个离散的东西,这样就更容易解读output代表什么意思,甚至可以更容易的做分群,比如output直接告诉你这一张图片的code是1,另外一种图片code是2,再一张图片是code3,这样你直接就知道code是1的图片是一群,code是2的图片是一群,code是3的图片是一群。举例来说,我们能不能让encoder的输出就是one-hot,只有一维是1,其他都是0,这样就自动分好群了。
那怎么做这件事?
可以说,在训练encoder和decoder的时候,在encoder和decoder之间再加一个东西,encoder本来的输出是一个连续向量,现在看里面哪一维最大,接下来就把那一维改成1,其他维都改成0,得到一个one-hot,然后把one-hot丢进decoder还原原来的图片。
或者说,你想做binary向量,那encoder同样output一个连续向量,这个向量里面的值如果大于某个阈值(比如0.5)就给1,否则给0。然后把这个binary向量丢给decoder还原为原来的图片。
那这个东西怎么做呢?显然连续向量到离散向量是没办法微分的(最大值变为1,其他维0;大于某个阈值为1,否则为0),那怎么把这个步骤放到auto-encoder里面,看上图右上方的文章,总之就算不能微分,也有办法训练这样的神经网络。
个人认为binary向量是更好的选择,因为如果图像库可以分为1024个群,那one-hot就需要1024维,但是binary向量只需要10维就够了,那么训练神经网络的时候用binary向量,需要的参数就比较少。binary向量还有个好处就是,有机会处理训练集中从来没出现过的类别,有可能在训练资料里看到的是\(\begin{bmatrix} 1\\0\\0\\1 \end{bmatrix}\)跟\(\begin{bmatrix} 0\\1\\1\\0 \end{bmatrix}\),但是有可能在测试的资料里看到其它的组合,所以可能处理训练时没看到的东西。
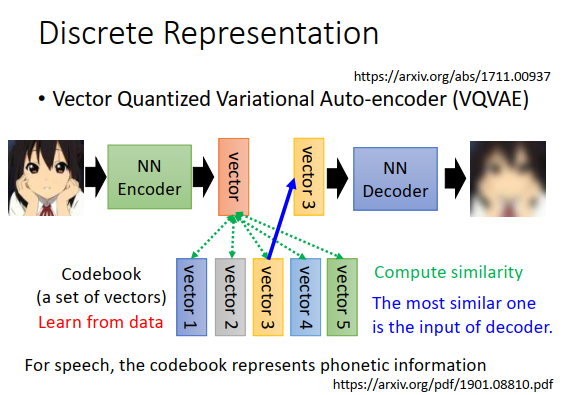
有个知名的做法叫做vector quantized variational auto-encoder(VQVAE,矢量化变分自动编码器)。有一个encoder和一个decoder,还有一个codebook,codebook里是一排向量。codebook不是人设定的,也是学习出来的,如上图codebook里的5个向量也是参数,假设向量是10维,那总共就有50个参数。现在有一张图片进来,encoder会output一个向量(连续向量),接下来计算output向量和codebook里面每个向量的相似度,看谁的相似度最高。比如上图所示,红色向量和黄色向量相似度最高,那就把黄色的相似度拿出来,当做decoder的input,训练的时候还是最小化重构误差。今天因为codebook里面只有5种向量,所以对给decoder的只有5种选择。这个计算相似的什么的,也不能微分,但是也是有手法可以训练这种网络的。
这种离散表示有什么应用呢?
用VQVAE或者其它离散表示方法来encode语音讯号,强迫你的embedding必须是离散的话,那学习出来的离散embedding包含的就会是声音的内容资讯,也就是声音里有关文字的部分才会被放到embedding里面,有关语者、噪声的部分就会被过滤掉。
为什么语者、噪声的部分就会被过滤掉?
因为这些embedding是离散的,就比较容易存离散的资讯,而声音里有关文字的部分是离散的,文字本身就是一个一个token(符号)组成,不是离散的资讯就会被过滤掉。
这样的话,假如你要做语音识别,先把声音讯号通过这个encoder,就比较容易保留需要识别的内容资讯,把其他的杂讯过滤掉。

可以让embedding不再是一个向量,比如我们让它是一个句子。
假设我们现在encoder的对象是一大堆的文章,那我们可以训练一个Seq2seq的auto-encoder,接收一篇文章,encoder的output不是一个向量而是一个sequence(一串文字),decoder接收这串文字,试图还原原来的文章。
你可能期待说,中间的文字到底会是什么样的内容,可能是原来文章的摘要,原来文章精简后的结果。
但是直接训练一个Seq2seq的auto-encoder,是训练不出好的结果的,因为encoder和decoder都是机器,它们会发明自己的暗号,比如“台湾大学”,可能学成“湾学”,只要decoder能把“湾学”解回“台湾大学”。所有encoder输出的确实是一串文字,但人是看不懂的。
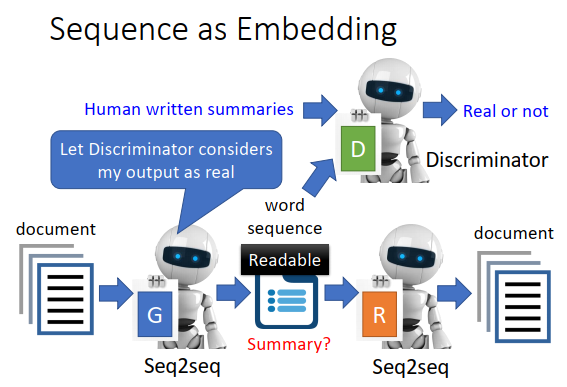
那怎么让encoder输出的文字能让人看懂?
需要用到GAN的概念,训练一个判别器(或者一个二元分类器),这个二元分类器的工作就是看一个句子,判断这个句子是否是人写的。今天encoder要学习去骗过这个二元分类器,encoder要学习说输出一串文字,让二元分类器判断时人写的,同时encoder的输出要通过decoder还原为原来的文章,那么encoder的输出可能就保留了文章里面最重要的资讯。

上图是真正的例子,summary里面的红色开头部分,就是encoder的输出。

有时候机器也会犯错。
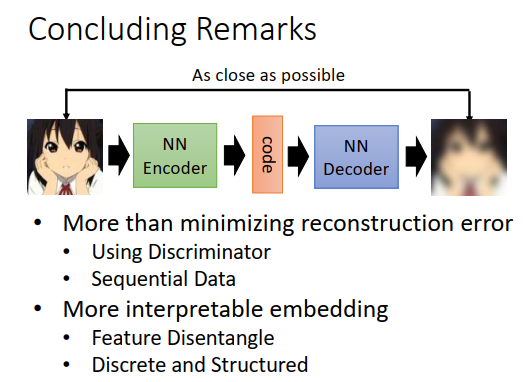
这就是讲的内容:
- 除了最小化重构误差外,有没有别的做法
- 有没有什么技术,可以让embedding更具有解释性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号