观影数据集1
数据清洗
1 导入数据
# 数据导入
import numpy as np
import pandas as pd
from pandas import DataFrame, Series
# 可视化显示在界面
#%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来显示中文
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
import seaborn as sns
sns.set(color_codes=True)
import json
import warnings
warnings.filterwarnings('ignore')
from wordcloud import WordCloud, STOPWORDS
movies = pd.read_csv('F:\\java 王建民\\2021下\\大作业\\观影数据集之大数据分析\\data\\tmdb_5000_movies.csv', encoding='utf_8')
credits = pd.read_csv('F:\\java 王建民\\2021下\\大作业\\观影数据集之大数据分析\\data\\tmdb_5000_credits.csv', encoding='utf_8')
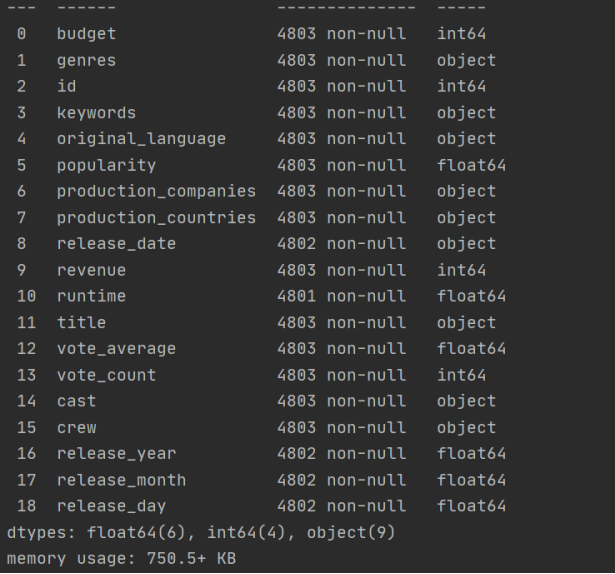
movies.info() # 查看信息
credits.info()
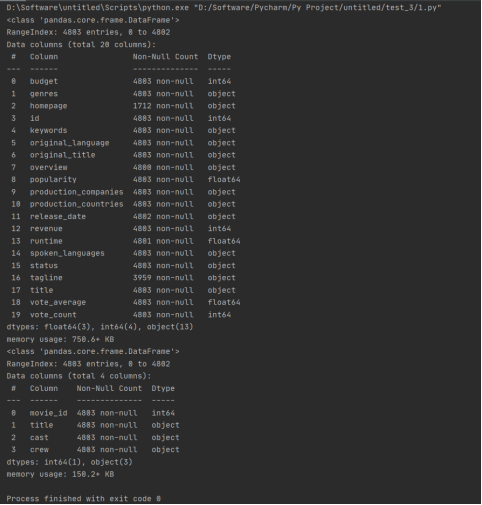
# 两个数据框都有title列,以及movies.riginal_title
# 以上三个数据列重复,删除两个
del credits['title']
del movies['original_title']
# 连接两个csv文件
merged = pd.merge(movies, credits, left_on='id', right_on='movie_id', how='left')
# 删除不需要分析的列
df=merged.drop(['homepage','overview','spoken_languages','status','tagline','movie_id'],axis=1)
df.info()
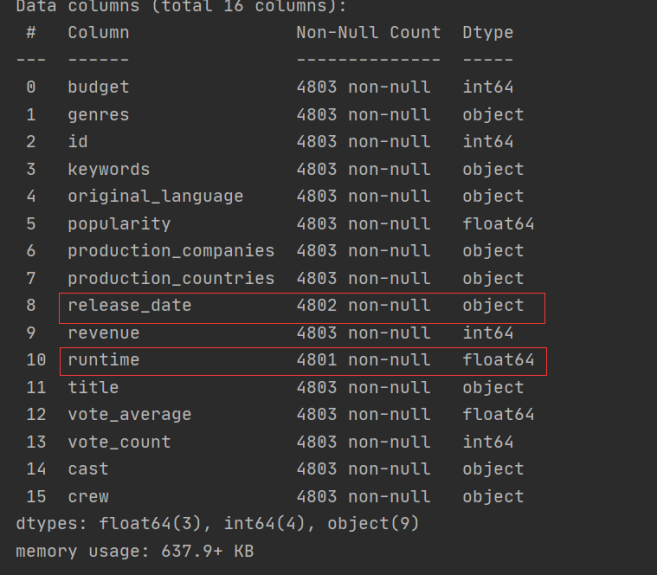
2缺失值处理
缺失记录仅3 条,采取网上搜索,补全信息。
2.1 补全 release_date
from test_3.t1 import df
# 查找缺失值记录-release_date
release = df[df.release_date.isnull()]
print(release.title)
# 查找缺失值记录-runtime
runtime = df[df.runtime.isnull()]
print(runtime.title)

缺失发布日期的电影为:《America Is Still the Place》日期为2014-06-01
缺失时长的两部电影为:《Chiamatemi Francesco - Il Papa della gente》
《To Be Frank, Sinatra at 100》
2.2 补全 runtime
#补全数据
df['release_date'] = df['release_date'].fillna('2014-06-01')
df.loc[2656] = df.loc[2656].fillna('94, limit=1')
df.loc[4140] = df.loc[4140].fillna('240, limit=1')
df.info()
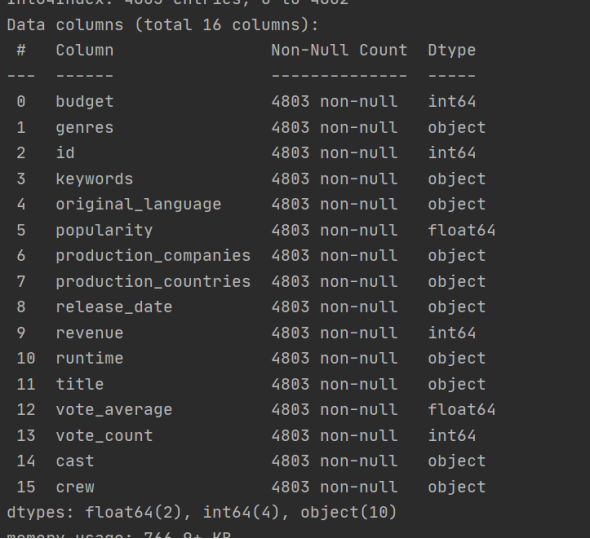
缺失记录的电影 runtime 分别为 98 min 和 81 min。
3重复值处理
print(len(df.id.unique()))
运行结果:有 4803 个不重复的 id,可以认为没有重复数据。
4日期值处理
将 release_date 列转换为日期类型:
#将 release_date 列转换为日期类型
df['release_year'] = pd.to_datetime_new(df.release_date, format = '%Y-%m-%d',errors='coerce').dt.year
df['release_month'] = pd.to_datetime_new(df.release_date).apply(lambda x: x.month)
df['release_day'] = pd.to_datetime_new(df.release_date).apply(lambda x: x.day)
df.info()
print(df['release_year'],df['release_month'],df['release_day'])