pandas
1 2 3 | import pandas as pdfrom pandas import Series,DataFrameimport numpy as np |
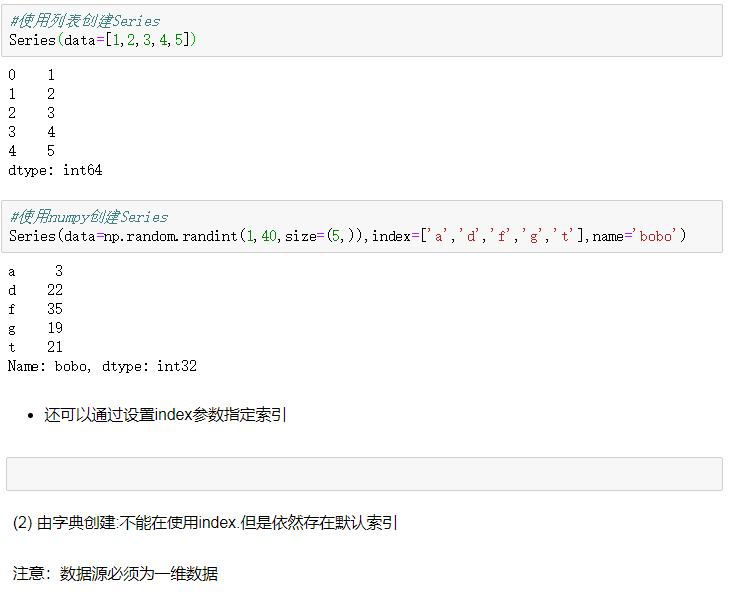
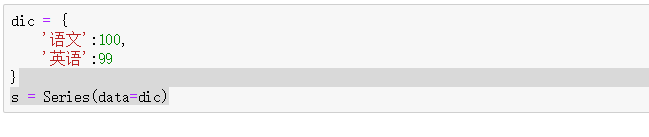
1 2 3 4 5 6 7 8 9 10 11 | 1、SeriesSeries是一种类似与一维数组的对象,由下面两个部分组成:values:一组数据(ndarray类型)index:相关的数据索引标签1)Series的创建两种创建方式:(1) 由列表或numpy数组创建默认索引为0到N-1的整数型索引 |
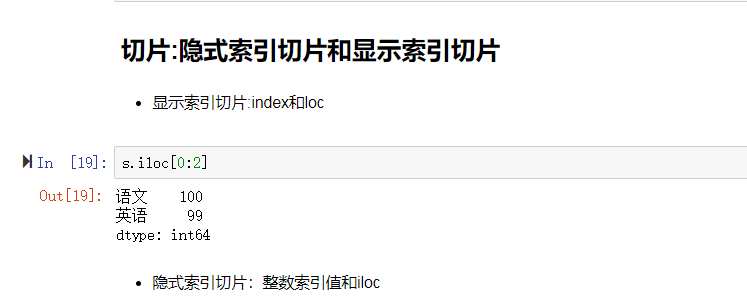
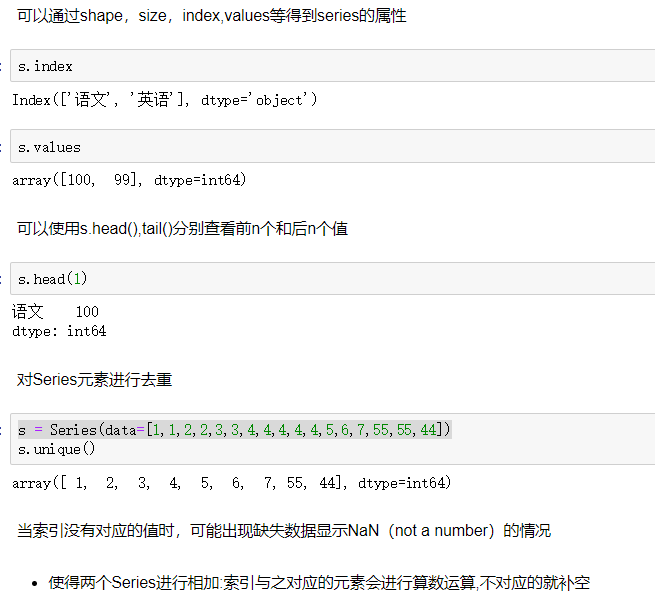
1 2 3 4 5 6 7 8 9 | 2)Series的索引和切片可以使用中括号取单个索引(此时返回的是元素类型),或者中括号里一个列表取多个索引(此时返回的是一个Series类型)。(1) 显式索引:- 使用index中的元素作为索引值- 使用s.loc[](推荐):注意,loc中括号中放置的一定是显示索引注意,此时是闭区间- 使用整数作为索引值- 使用.iloc[](推荐):iloc中的中括号中必须放置隐式索引 |
(2) 隐式索引:
注意,此时是半开区间



1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 | DataFrameDataFrame是一个【表格型】的数据结构。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。行索引:index列索引:columns值:values1)DataFrame的创建最常用的方法是传递一个字典来创建。DataFrame以字典的键作为每一【列】的名称,以字典的值(一个数组)作为每一列。此外,DataFrame会自动加上每一行的索引。使用字典创建的DataFrame后,则columns参数将不可被使用。同Series一样,若传入的列与字典的键不匹配,则相应的值为NaN。使用ndarray创建DataFrameDataFrame(data=np.random.randint(0,100,size=(5,6)))0 1 2 3 4 50 32 93 0 23 21 401 27 35 9 76 41 682 63 96 63 30 96 513 2 50 28 26 26 414 32 74 97 84 56 7DataFrame属性:values、columns、index、shapedfdf.valuesarray([[77, 67], [88, 88], [99, 99], [90, 78]], dtype=int64)df.indexIndex(['语文', '数学', '英语', '理综'], dtype='object')使用ndarray创建DataFrame:创建一个表格用于展示张三,李四,王五的java,python的成绩'语文','数学','英语','理综'dic = { '张三':[77,88,99,90], '李四':[67,88,99,78]}df = DataFrame(data=dic,index=['语文','数学','英语','理综'])df张三 李四语文 77 67数学 88 88英语 99 99理综 90 78============================================ 张三 李四 语文 150 0数学 150 0英语 150 0理综 300 0============================================2)DataFrame的索引(1) 对列进行索引- 通过类似字典的方式 df['q']- 通过属性的方式 df.q可以将DataFrame的列获取为一个Series。返回的Series拥有原DataFrame相同的索引,且name属性也已经设置好了,就是相应的列名。df张三 李四语文 77 67数学 88 88英语 99 99理综 90 78df['张三']语文 77数学 88英语 99理综 90Name: 张三, dtype: int64df.张三语文 77数学 88英语 99理综 90Name: 张三, dtype: int64df[['李四','张三']]df[['李四','张三']]李四 张三语文 67 77数学 88 88英语 99 99理综 78 90#修改列索引df.columns = ['zhangsan','lisi']dfzhangsan lisi语文 77 67数学 88 88英语 99 99理综 90 78(2) 对行进行索引- 使用.loc[]加index来进行行索引- 使用.iloc[]加整数来进行行索引同样返回一个Series,index为原来的columns。df.iloc[[0,1]]zhangsan lisi语文 77 67数学 88 88(3) 对元素索引的方法- 使用列索引- 使用行索引(iloc[3,1] or loc['C','q']) 行索引在前,列索引在后df.iloc[0,1]67切片:【注意】 直接用中括号时:索引表示的是列索引切片表示的是行切片df[0:2]zhangsan lisi语文 77 67数学 88 88在loc和iloc中使用切片(切列) : df.loc['B':'C','丙':'丁']df.iloc[:,0:1]zhangsan语文 77数学 88英语 99理综 903)DataFrame的运算(1) DataFrame之间的运算同Series一样:在运算中自动对齐不同索引的数据如果索引不对应,则补NaN创建DataFrame df1 不同人员的各科目成绩,月考一创建DataFrame df2 不同人员的各科目成绩,月考二df zhangsan lisi语文 87 177数学 10 198英语 109 209理综 100 188df.loc['数学','zhangsan'] = 0df['lisi'] += 100df += 10df += 10(df+df)/2zhangsan lisi语文 77 67数学 88 88英语 99 99理综 90 78 |

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步