机器学习
机器学习
机器学习,是人工智能一个基本条件,是建立大数据基础之上。从数据中提取出模型,并可以利用模型对未知的数据做出预测
历史往往不一样,但历史总是惊人的相似
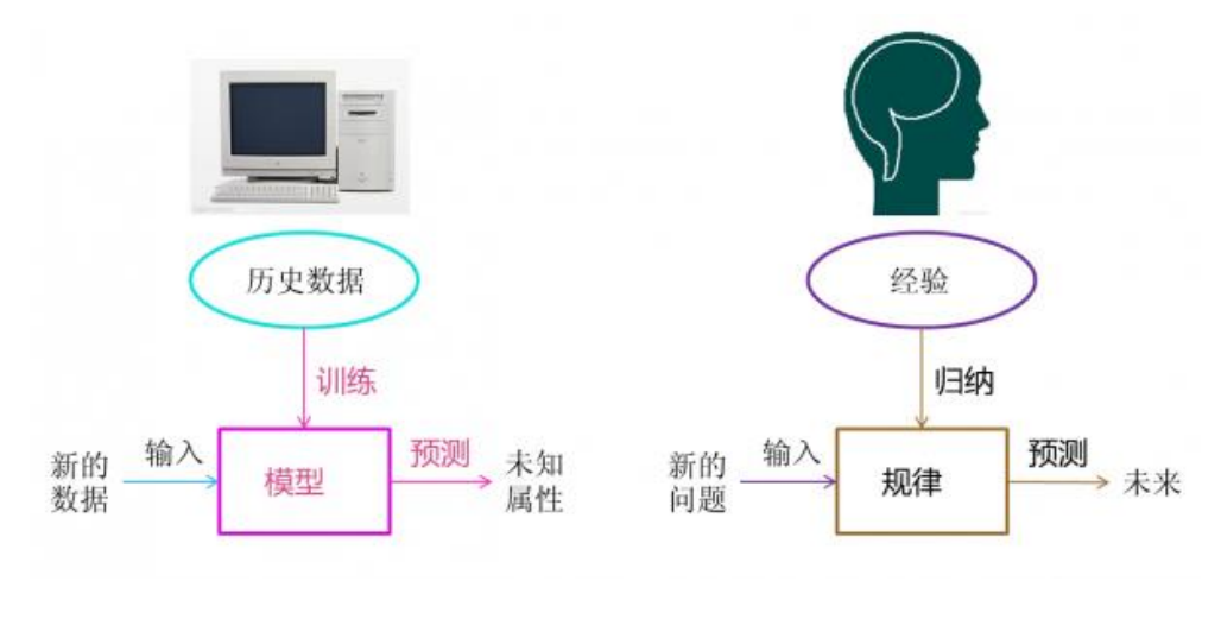
有监督学习和无监督学习

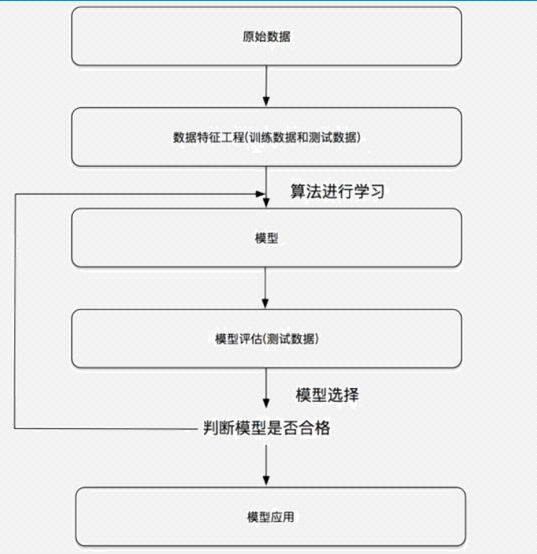
机器学习流程
机器学习有监督学习过程代码
package com.mllib import org.apache.spark.ml.classification.{LogisticRegression, LogisticRegressionModel} import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession} object Demo02Person { def main(args: Array[String]): Unit = { // 1、加载数据 进行数据特征工程 将数据转换成机器学习能够识别的数据 val spark: SparkSession = SparkSession .builder() .appName("Demo02Person") .master("local[*]") .getOrCreate() import spark.implicits._ import org.apache.spark.sql.functions._ val personDF: DataFrame = spark .read .format("libsvm") .load("bigdata19-spark/data/mllib/data/人体指标.txt") // 2、将数据切分成训练集、测试集,一般比例为8:2 val splitDF: Array[Dataset[Row]] = personDF.randomSplit(Array(0.8, 0.2)) val trainDF: Dataset[Row] = splitDF(0) val testDF: Dataset[Row] = splitDF(1) /** * 3、选择合适的模型,将训练集带入模型进行训练 * 数据有无label --> 有,有监督学习 --> label是离散的还是连续的 --> 离散 --> 选择 分类的算法 --> 逻辑回归(适合做二分类) * --> 无,无监督学习 --> 连续 --> 选择 回归的算法 */ val logisticRegression: LogisticRegression = new LogisticRegression() .setMaxIter(10) .setRegParam(0.3) .setElasticNetParam(0.8) val logisticRegressionModel: LogisticRegressionModel = logisticRegression.fit(trainDF) //4、使用测试集评估模型 val transDF: DataFrame = logisticRegressionModel.transform(testDF) transDF.where("label != prediction").show() // 计算准确率 transDF .withColumn("flag", when($"label" === $"prediction", 1).otherwise(0)) .groupBy() .agg(sum($"flag") / count("*") as "准确率") .show() /** * 基于人体指标.txt数据 * 参考https://cloud.tencent.com/developer/article/1510724 * * 将label中的1 当作男生 * 将label中的0 当作女生 * 计算 精确率(Precision)和召回率(Recall) */ // 5、如果模型通过评估,则可以将模型保存起来 logisticRegressionModel.write.overwrite().save("bigdata19-spark/data/mllib/person") } }
机器学习有监督学习过程代码
package com.mllib import org.apache.spark.ml.clustering.{KMeans, KMeansModel} import org.apache.spark.ml.linalg import org.apache.spark.ml.linalg.Vectors import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession} object Demo06KMeans { def main(args: Array[String]): Unit = { // 1、加载数据,进行数据特征工程处理,将数据转换成模型所能识别的向量形式 val spark: SparkSession = SparkSession .builder() .appName("Demo06KMeans") .master("local[*]") .config("spark.sql.shuffle.partition", "4") .getOrCreate() import spark.implicits._ import org.apache.spark.sql.functions._ val kmeansDF: DataFrame = spark .read .format("csv") .option("sep", ",") .schema("x Double,y Double") .load("bigdata19-spark/data/mllib/data/kmeans.txt") val df: DataFrame = kmeansDF .as[(Double, Double)] .map { case (x: Double, y: Double) => Tuple1(Vectors.dense(x, y)) }.toDF("features") // 2、无监督学习不需要切分数据集 // 3、选择合适的算法模型,将数据带入模型 val kMeans: KMeans = new KMeans() .setK(2) // 控制最后会分为几类 val kMeansModel: KMeansModel = kMeans.fit(df) val transDF: DataFrame = kMeansModel.transform(df) transDF.printSchema() transDF .map(row => { val denseVec: linalg.Vector = row.getAs[linalg.Vector]("features") val x: Double = denseVec.toArray(0) val y: Double = denseVec.toArray(1) val prediction: Int = row.getAs[Int]("prediction") (x, y, prediction) }) .toDF("x", "y", "prediction") .write .mode(SaveMode.Overwrite) .format("csv") .save("bigdata19-spark/data/mllib/kmeans") // kMeansModel.write.overwrite().save("Spark/data/mllib/kemansModel") } }
机器学习的两种向量
稠密向量和稀疏向量
package com.mllib import org.apache.spark.ml.feature.LabeledPoint import org.apache.spark.ml.linalg import org.apache.spark.ml.linalg.Vectors import org.apache.spark.mllib.regression import org.apache.spark.mllib.util.MLUtils import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, SparkSession} object Demo01Vector { def main(args: Array[String]): Unit = { // 机器学习第一步:数据特征工程,将数据转换成机器学习模型所能够识别的数据——向量 // 构建向量 /** * Spark的MLLib有两个package:ml、mllib * ml:基于DataFrame * mllib:基于RDD */ /** * Spark MLLib中一共有两类向量:稠密向量、稀疏向量 */ // 构建稠密向量 val denseVec: linalg.Vector = Vectors.dense(Array(1.0, 2.0, 3.0, 3.5, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 4.0, 5.0, 6.0)) println(denseVec) /** * (54,[0,1,2,3,51,52,53],[1.0,2.0,3.0,3.5,4.0,5.0,6.0]) * 54:向量的长度 * [0,1,2,3,51,52,53]:值不为零的元素的位置(索引、下标) * [1.0,2.0,3.0,3.5,4.0,5.0,6.0]):上面每个值不为零的位置上对应的值 * 当向量中特征比较多时,并且每行数据中为零的元素很多 * 则使用稀疏向量可以减少内存空间的占用 */ println(denseVec.toSparse) // 转稀疏向量 // 构建稀疏向量 val sparseVec: linalg.Vector = Vectors.sparse(10, Array(0, 4, 7), Array(10.0, 8.8, 9.9)) println(sparseVec) // [10.0,0.0,0.0,0.0,8.8,0.0,0.0,9.9,0.0,0.0] println(sparseVec.toDense) // 转稠密向量 /** * 机器学习算法可以通过数据有无Label(标签)划分为:有监督学习、无监督学习 * 完整的一条数据一般可以分为两个部分:特征(features)、标签(label) * 特征可以使用向量表示 * 标签需要使用LabeledPoint直接表示 */ // 构建带标签的数据:有监督学习模型所需要的数据格式 val labelPoint: LabeledPoint = LabeledPoint(1.0, Vectors.dense(Array(1.0, 2.0, 0.0, 0.0, 3.0))) println(labelPoint) val spark: SparkSession = SparkSession .builder() .appName("Demo01Vector") .master("local[*]") .getOrCreate() val personRDD: RDD[regression.LabeledPoint] = MLUtils.loadLibSVMFile(spark.sparkContext, "bigdata19-spark/data/mllib/data/人体指标.txt", 10) personRDD.take(10).foreach(println) val personDF: DataFrame = spark .read .format("libsvm") .option("numFeatures", "10") .load("bigdata19-spark/data/mllib/data/人体指标.txt") personDF.printSchema() personDF.show() } }
K-近邻算法(KNN)

贝叶斯定理

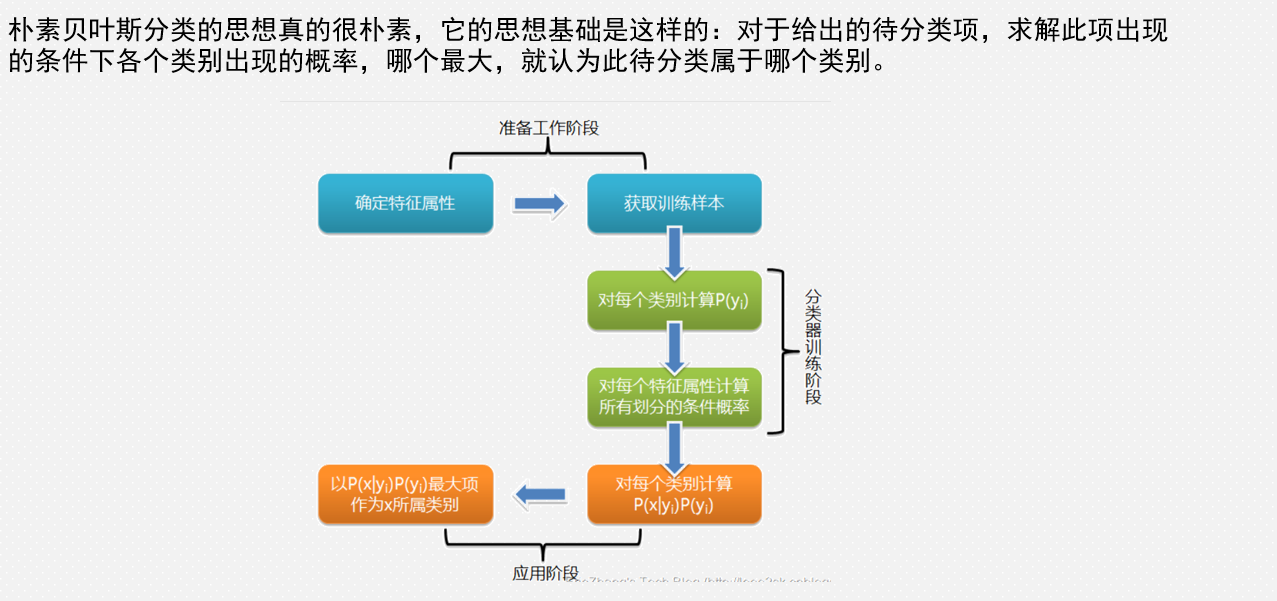
朴素贝叶斯分类算法

朴素贝叶斯分类

![]()
决策树算法

随机森林算法

逻辑回归算法

k-means聚类
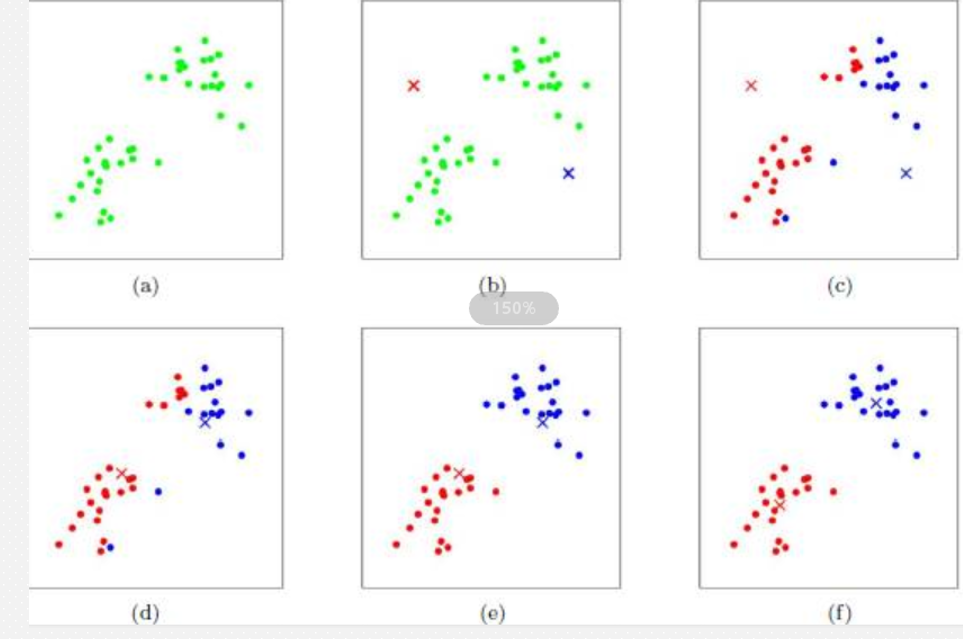
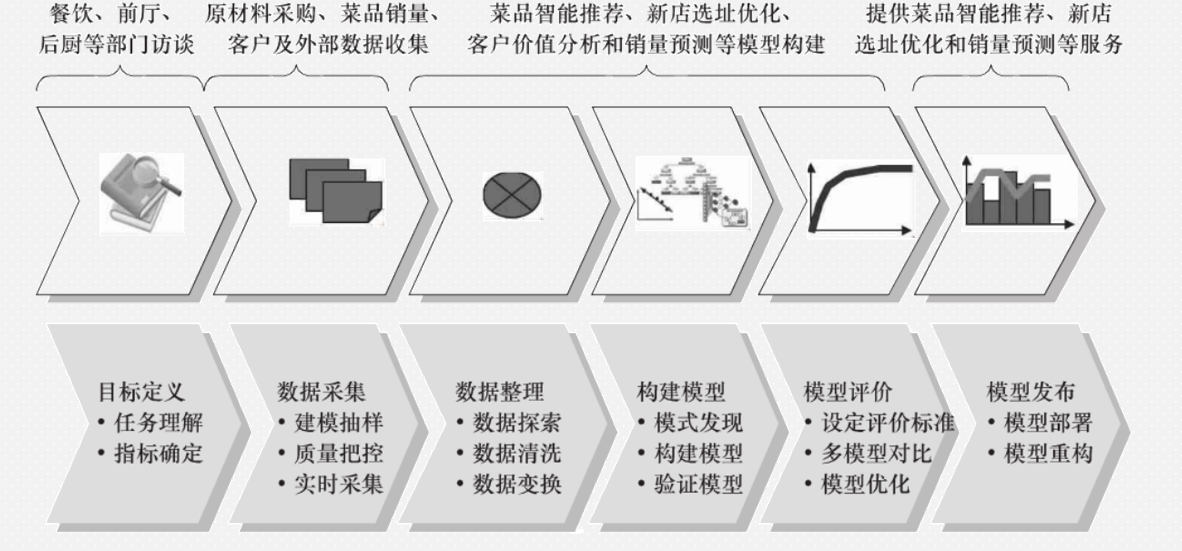
机器学习/数据挖掘建模过程