

Spark SQL概述、函数用法
Spark SQL
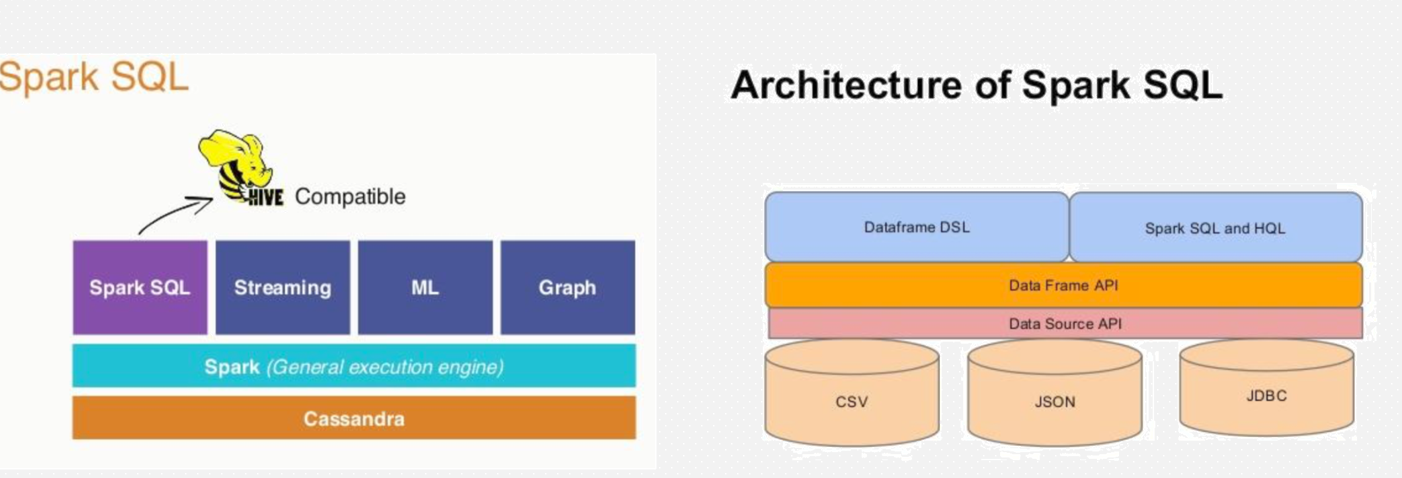
底层还是基于RDD的,常用的语言DSL
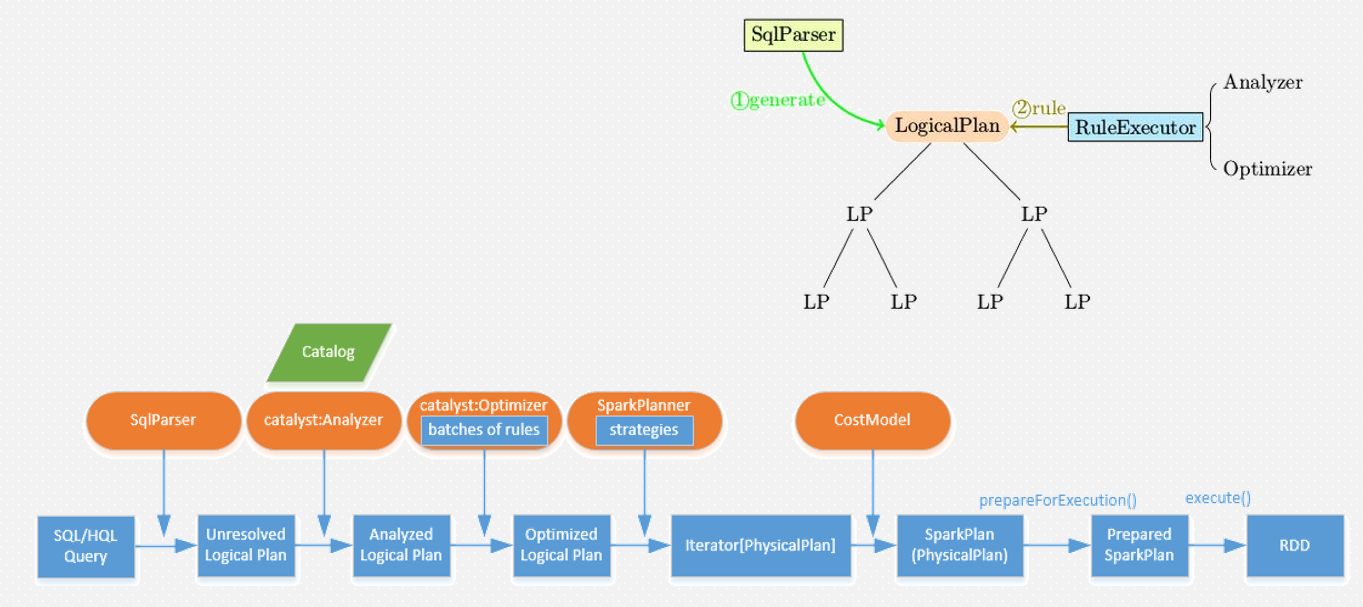
底层架构

在idea中的操作
引入pom依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
</dependency>
同时在主工程中添加
1、sparkSession
package com.sql import org.apache.spark.SparkContext import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, SparkSession} object Demo01Session { def main(args: Array[String]): Unit = { /** * 构建SparkSession,由Spark 2.x引入的统一的路口 */ // 注意命名规范 val spark: SparkSession = SparkSession .builder() .appName("Demo01Session") .master("local") .getOrCreate() // 如果需要使用SparkContext,可以直接获取 val sc: SparkContext = spark.sparkContext // 通过SC构建RDD val lineRDD: RDD[String] = sc.textFile("bigdata19-spark/data/students.txt") lineRDD.foreach(println) // 如果构建DataFrame val stuDF: DataFrame = spark.read.format("csv").option("sep", ",").schema("id String,name String,age Int,gender String,clazz String").load("bigdata19-spark/data/students.txt") // 打印DataFrame的结构 stuDF.printSchema() // 默认会打印20条 stuDF.show() stuDF.show(10) // 打印10条 stuDF.show(10,truncate = false)// 不截断数据进行输出 } }
2、读文件的五种方式
package com.sql import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession} object Demo02SourceAPI { def main(args: Array[String]): Unit = { //构建SparkSession环境 val spark: SparkSession = SparkSession .builder() .appName("Demo02SourceAPI") .master("local") .getOrCreate() //1、csv格式:用于读取普通的文本文件,数据没有结构 val csvDF: DataFrame = spark .read .format("csv") // 指定读取文件的格式 .option("sep", ",")// 指定分隔符 .schema("id String,name String,age Int,gender String,clazz String")// 指定结构 .load("bigdata19-spark/data/students.txt")// 指定路径 // csvDF.show() // 2、json格式:数据自带结构,但空间占用要比csv格式大 val jsonDF: DataFrame = spark.read.format("json").load("bigdata19-spark/data/stu/json") // jsonDF.show() // parquet以及orc都是以snappy的方式进行压缩 // 3、parquet格式:数据自带结构,空間占用要比csv小很多,一般适用于保存嵌套格式的数据 val parquetDF: DataFrame = spark.read.format("parquet").load("bigdata19-spark/data/stu/parquet") // parquetDF.show() // 4、orc格式:数据自带结构,空間占用最小 val orcDF: DataFrame = spark.read.format("orc").load("bigdata19-spark/data/stu/orc") // orcDF.show() // 5、JDBC // val jdbcDF: DataFrame = spark // .read // .format("jdbc") // .option("url", "jdbc:mysql://rm-bp1h7v927zia3t8iwho.mysql.rds.aliyuncs.com:3307/stu018?useSSL=false") // .option("dbtable", "student") // .option("user", "bigdata018") // .option("password", "123456") // .load() // jdbcDF.show() // 保存数据 csvDF .write .format("json") // 指定输出的格式 /** * 指定写入的模式: * 1、Append * 2、Overwrite * 3、ErrorIfExists * 4、Ignore * */ .mode(SaveMode.Overwrite) // .save("bigdata19-spark/data/stu/json") // 指定输出的路径 // csvDF.write.format("parquet").mode(SaveMode.Overwrite).save("bigdata19-spark/data/stu/parquet") // csvDF.write.format("orc").mode(SaveMode.Overwrite).save("bigdata19-spark/data/stu/orc") csvDF.write .format("jdbc") .option("url", "jdbc:mysql://rm-bp1h7v927zia3t8iwho.mysql.rds.aliyuncs.com:3307/stu018?useSSL=false") .option("dbtable", "student_sql") .option("user", "bigdata018") .option("password", "123456") /** * 当SparkSQL以Overwrite方式写MySQL时会先将表drop, * 然后再以DF的格式按照SparkSQL的标准重新建表并插入数据 */ .option("truncate", "true") .mode(SaveMode.Overwrite) .save() } }
3、写sql和dsl
package com.sql import org.apache.spark.sql.{DataFrame, SparkSession} object Demo03wordCount { def main(args: Array[String]): Unit = { // 构建SparkSession环境 val spark: SparkSession = SparkSession .builder() .appName("Demo03WordCount") .master("local") // 设置Spark SQL产生shuffle时的分区数,默认是200 .config("spark.sql.shuffle.partitions", "2") .getOrCreate() // 导入Spark SQL的隐士转换以及函数 import spark.implicits._ import org.apache.spark.sql.functions._ val lineDF: DataFrame = spark .read .format("csv") .option("sep", "|") .schema("line String") .load("bigdata19-spark/data/words.txt") //将df注册成表 lineDF.createOrReplaceTempView("words_tb") //sql spark .sql( """ |select t1.word | ,count(1) as cnt |from ( | select explode(split(line,",")) as word | from words_tb | )t1 group by t1.word |""".stripMargin).show() //DSL lineDF.select("line").show()//字符串表达式 lineDF.select($"line").show()//列表达式 lineDF .select(explode(split($"line",",")) as "word") .groupBy($"word") .agg(count("word") as "cnt") .show() } }
函数用法(DSL)
package com.sql import org.apache.spark.sql.expressions.Window import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession} object Demo04DSL { def main(args: Array[String]): Unit = { /** * DSL:特定领域语言 */ val spark: SparkSession = SparkSession .builder() .appName("Demo04DSL") .master("local") .config("spark.sql.shuffle.partitions", "2") .getOrCreate() // 导入隐式转换及函数 import spark.implicits._ import org.apache.spark.sql.functions._ /** * DataFrame 同 Dataset[Row] 没有区别,是一样的 * Row对象:就是给每行数据增加列结构 * 在RDD基础上增加了列结构 */ val stuDF: DataFrame = spark .read .format("csv") .option("sep", ",") .schema("id String,name String,age Int,gender String,clazz String") .load("bigdata19-spark/data/students.txt") /** * SQL常见的操作: * select * from tb * where 过滤 * group by分组 --> max、min、sum、count、avg聚合函数 * having 分组之后进行过滤 * order by 全局排序 * limit 分页、限制输出的数据条数 * * 关联:join * 内连接:join、inner join * 外连接(outer):left join、right join、full join * * 连接:union、union all * * 常用的函数: * 字符串函数、日期函数、数值函数、条件函数、聚合函数、窗口函数、自定义函数...... * */ // 对多次使用的DF进行缓存 stuDF.cache() // select 选择DF中指定的列 stuDF.select("id", "name", "clazz") // .show() // 字符串表达式 stuDF.select($"id", $"name", $"clazz") // .show() // 列表达式(推介) // where 过滤 // 过滤出理科班的学生 stuDF.where("clazz like '理科%'") // .show() stuDF.where($"clazz" like "理科%") // .show() // 也可以使用filter进行过滤:不仅可以传入字符串表达式、列表达式,还可以传入一个函数 stuDF.filter(row => { // 从row对象中提取班级 val clazz: String = row.getAs[String]("clazz") clazz.startsWith("理科") }) // .show() // group by 分组 一般分完组会进行聚合操作 /** * 分组聚合操作会产生shuffle,在Spark SQL中shuffle后得到的DF默认的分区数是200 * 对于小数据来说分区数太多了,可以进行配置 * 通过spark.sql.shuffle.partitions */ // 统计性别人数 stuDF.groupBy("gender").agg(count("id") as "cnt") // .show() // having 分组之后对聚合后的结果进行过滤 // 统计班级人数 并把班级人数大于100人的班级过滤出来 stuDF .groupBy("clazz") .agg(count("id") as "cnt") /** * 为什么在SQL中不能在分组聚合之后直接使用where,在DSL中可以? * 因为在SQL中where的执行顺序在from之后 在groupBy之前,所以不能直接对分组后的结果进行过滤,可以使用子查询嵌套 * 在DSL中执行顺序就是代码的先后顺序,所以可以直接在分组聚合之后跟where */ .where($"cnt" > 100) // .show() // order by 全局排序 // 统计班级人数 并按人数从大到小排序 stuDF .groupBy("clazz") .agg(count("id") as "cnt") .orderBy($"cnt".desc) // .show() // limit 控制输出的数据条数 (在DSL中不太好实现分页) // stuDF.limit(11).show() // 加载分数的数据 val scoDF: DataFrame = spark .read .format("csv") .option("sep", ",") .schema("id String,subject_id String,score Int") .load("bigdata19-spark/data/score.txt") // inner join (join) 内连接 // 当关联的字段名相同时,使用列表达式会出现ambiguous错误 // stuDF.join(scoDF, $"id" === $"id", "inner").show() // 1、修改列名 val renameScoDF: DataFrame = scoDF.withColumnRenamed("id", "sid") stuDF.join(renameScoDF, $"id" === $"sid", "inner").show(10) // 2、使用Scala的本地集合 stuDF.join(scoDF, List("id"), "inner").show(10) // left join stuDF.join(scoDF, List("id"), "left").show(10) // right join stuDF.join(scoDF, List("id"), "right").show(10) // full join stuDF.join(scoDF, List("id"), "full").orderBy($"id").show(10) // 连接:union、union all val sampleStuDF1: Dataset[Row] = stuDF.sample(withReplacement = false, fraction = 0.01, seed = 10) val sampleStuDF2: DataFrame = stuDF.sample(withReplacement = false, fraction = 0.01, seed = 10) // DSL的union相当于SQL中的union all sampleStuDF1.union(sampleStuDF2).show(50) // 在DSL中实现SQL中的union操作 sampleStuDF1.union(sampleStuDF2).distinct().show(50) // 提取每个学生的姓氏 stuDF.select(substring($"name", 1, 1) as "Last Name").show() /** * DSL中的条件函数:when * 没有if,if是Scala中的关键字 */ /** * 统计每个学生的成绩: * 如果成绩大于等于90分-->优秀 * 如果成绩大于等于80分-->良好 * 如果成绩大于等于70分-->一般 * 如果成绩大于等于60分-->及格 * 如果成绩小于60分-->不及格 * * 最终输出id、name、subject_name、score、level * * 注意分数要进行归一化处理:需要先转换成百分制再处理 */ // 加载科目的数据 val subDF: DataFrame = spark .read .format("csv") .option("sep", ",") .schema("subject_id String,subject_name String,subject_score Int") .load("bigdata19-spark/data/subject.txt") scoDF .join(subDF, List("subject_id"), "inner") .select($"id", $"subject_name", round($"score" * 100.0 / $"subject_score", 2) as "new_score") // 如果需要额外增加新的一列数据可以直接使用withColumn .withColumn("level" , when($"new_score" >= 90, "优秀") // 也可以当成SQL中的if使用 .when($"new_score" >= 80, "良好") .when($"new_score" >= 70, "一般") .when($"new_score" >= 60, "及格") // 相当于case when .otherwise("不及格") // 相当于else ).join(stuDF, List("id"), "inner") .select($"id", $"name", $"subject_name", $"new_score", $"level") .show() // 窗口函数的使用 // 统计班级前三名 scoDF .groupBy("id") .agg(sum("score") as "sum_score") .join(stuDF, List("id"), "inner") .select($"id", $"name", $"clazz", $"sum_score") // 使用row_number统计每个人的排名 // .select($"id", $"name", $"clazz", $"sum_score" // , row_number().over(Window.partitionBy("clazz").orderBy($"sum_score".desc)) as "rn" // ) // 使用withColumn .withColumn("rn", row_number() over Window.partitionBy("clazz").orderBy($"sum_score".desc)) .where($"rn" <= 3) .show() } }


