

HBase的优化
在这里是简单模拟将索引存到redis中,再通过先查询索引再将Hbase中的数据查询出来。 需要考虑的问题: 1、建立redis的连接,建立Hbase的连接 2、如何创建索引,即创建索引的key和value的设计 3、如何通过将查到的索引,去查询到对应Hbase的数据
添加依赖
<!-- https://mvnrepository.com/artifact/redis.clients/jedis --> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>4.2.3</version> </dependency>
启动redis服务
nohup redis-server ./redis.conf &
代码编写
二、HBase优化
2.1 行键的设计(重点)
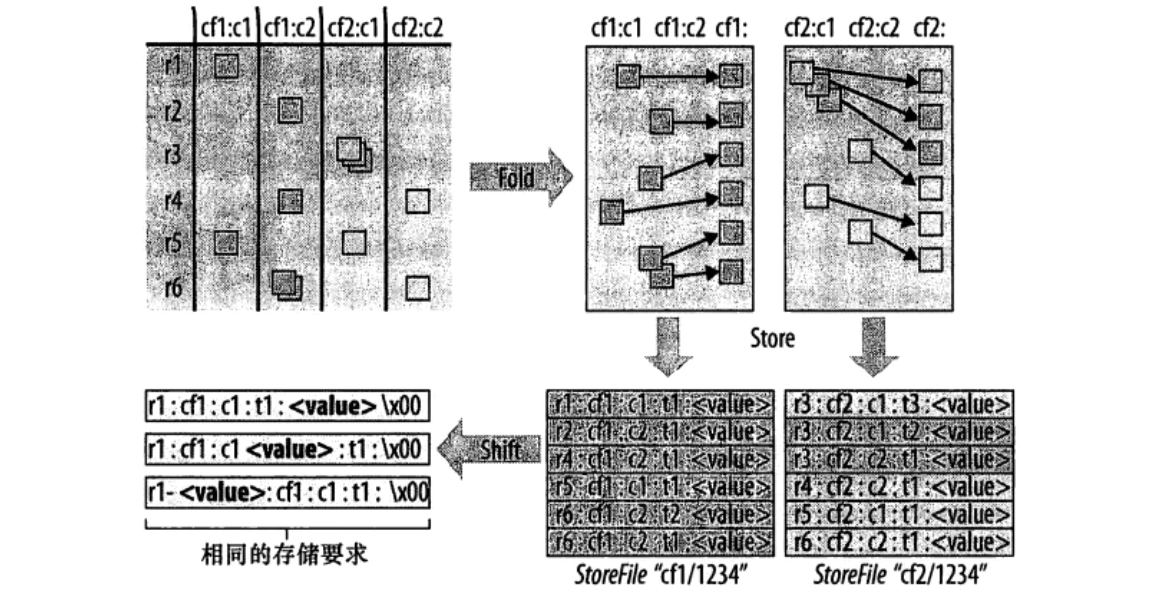
实际上底层存储是按列族线性地存储单元格
列包括了HBase特有的列族和列限定符,从而组成列键。
磁盘上一个列族下所有的单元格都存储在一个存储文件中,不同列族的单元格不会出现在同一个存储文件中。
每个单元格在实际存储时保存了行键和列键,所以每个单元格都单独存储了它在表中所处位置的相关信息。
单元格按时间戳降序排列。
含有结构信息的整个单元格在HBase中被叫做KeyValue。
2.2 设计的时候,列不要太多(优先考虑高表,其次宽表)
HBase只能按行分片,因此高表更有优势。
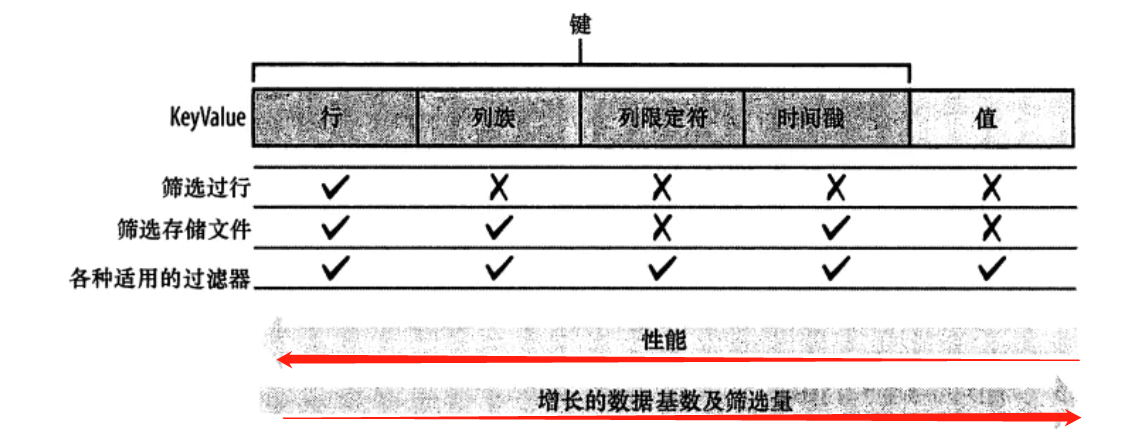
2.3 部分键扫描
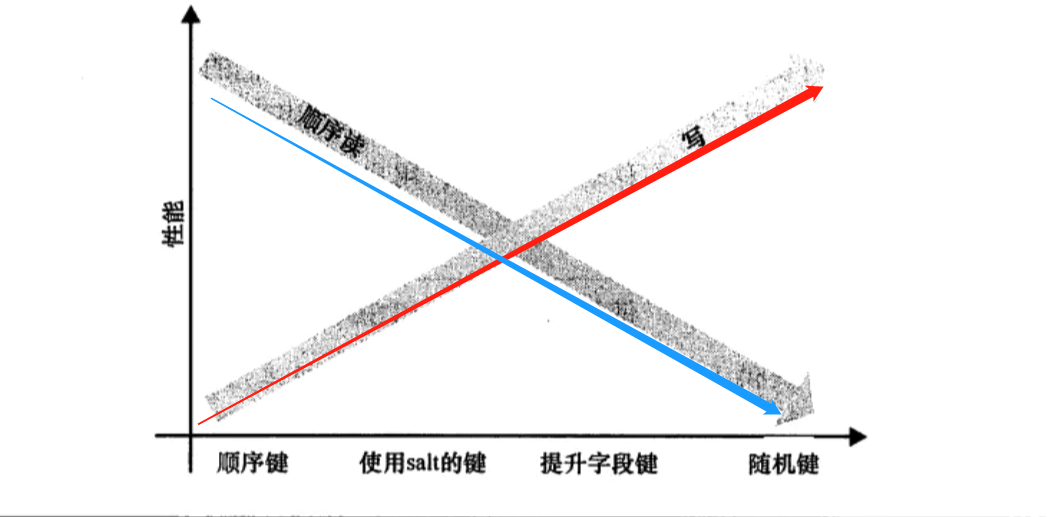
2.4 不同方式解决顺序读的性能变化对比图

2.5 布隆过滤器(重点)
在读取数据时,hbase会首先在布隆过滤器中查询,根据布隆过滤器的结果,再在MemStore中查询,最后再在对应的HFile中查询。
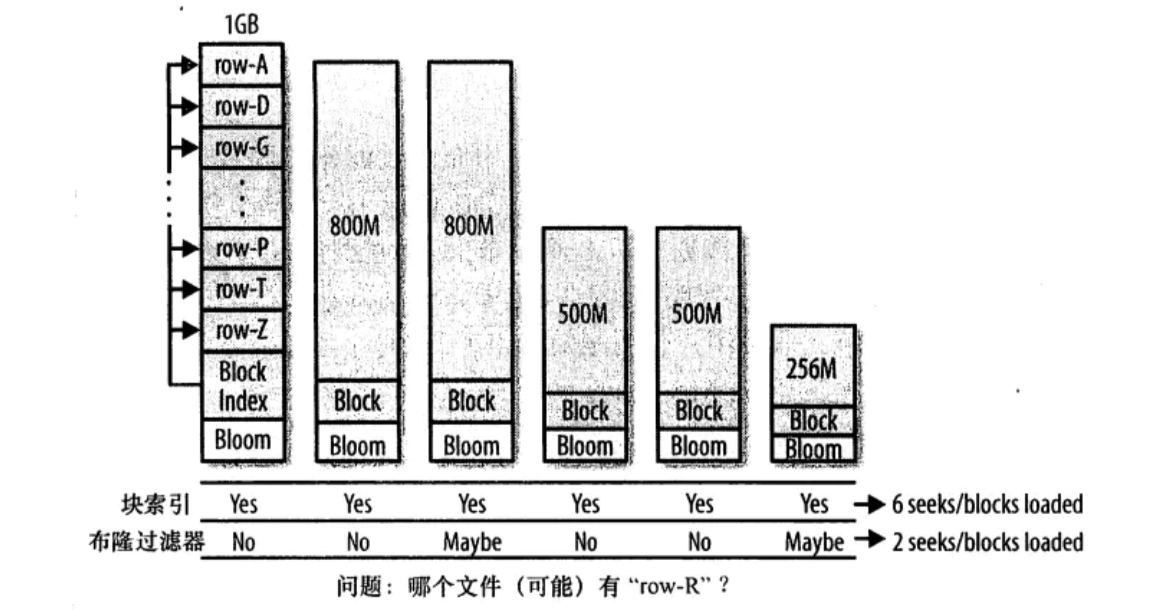
当我们随机读get数据时,如果采用hbase的块索引机制,hbase会加载很多块文件。如果采用布隆过滤器后,它能够准确判断该HFile的所有数据块中,是否含有我们查询的数据,从而大大减少不必要的块加载,从而增加hbase集群的吞吐率。
2.6 选择合适的 GC 策略
Hbase是java开发的,也是运行在java虚拟机jvm中,所以也可以通过GC参数配置调优
主要调节的是RegionServer节点的JVM垃圾回收参数
垃圾回收策略:Parraller New Collector垃圾回收策略; PC
并行标记回收器(Concurrent Mark-Sweep Collector),避免GC停顿, CMS
使用:
一般用于用于写在hbase-env.sh
export HBASE_REGIONSERVER_OPTS="-Xmx8g -Xms8G -Xmn128m -XX:UseParNewGC -XX:UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:$HBASE_HOME/logs/gc-${hostname}-hbase.log"
HBase上的Regionserver的内存主要分为两部分,一部分作为Memstore,主要用来写;一部分作为BlockCache,主要用于读。 写请求会先写入Memstore,Regionserver会给每个region的store提供一个Memstore,当Memstore满128M(hbase.hregion.memstore.flush.size)以后,会启动flush刷新到磁盘,当Memstore的总大小超过限制时(heapsizehbase.regionserver.global.memstore.upperLimit0.9),会强行启动flush进程,从最大的Memstore开始flush直到低于限制
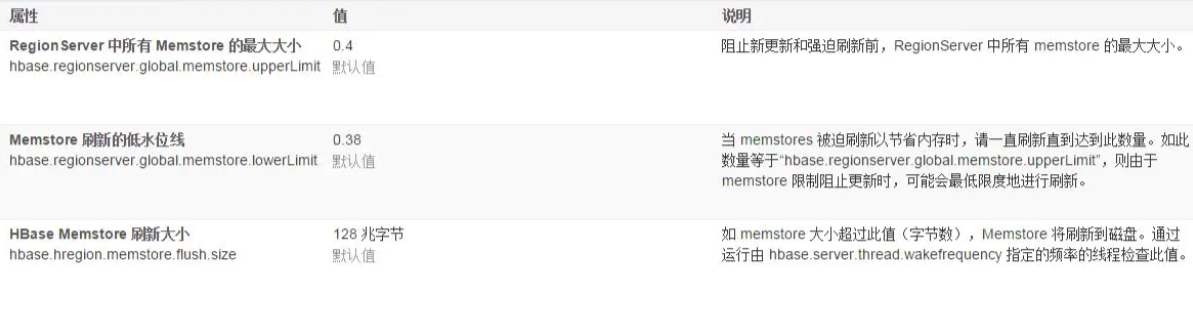
如果不希望自动触发溢写,就将值调大 <name>hbase.hregion.memstore.flush.size</name> <value>134217728</value> 一般在企业中这个参数是禁用的 <name>hbase.hregion.majorcompaction</name> <value>604800000</value> 直接将值设置为0就可以了,表示禁用 何时执行split <name>hbase.hregion.max.filesize</name> <value>10737418240</value> 一般建议将值调大,在期间手动去触发split
创建HBase时,就预先根据可能的RowKey划分出多个Region而不是默认的一个,从而可以将后续的读写操作负载均衡到不同的Region上,避免热点现象; HBase表的预分区需要紧密结合业务场景来选择分区的key值,每个region都有一个startKey和一个endKey来表示该region存储的rowKey范围;
//有以下四种创建方式: create 'ns1:t1' , 'f1' , SPLITS => ['10','20','30','40'] ; create 't1','f1',SPLITS_FILE => 'splits.txt', OWNER=> 'johnode' ; ——其中splits.txt文件内容是每行一个rowkey值 create 't1','f1',{NUMREGIONS => 15, SPLITALGO =>'HexStringSplit'} JavaAPI HTableDescriptor desc = new HTableDescriptor(TableName.valueOf(weibo_content)); HColumnDescriptor family = new HColumnDescriptor(Bytes.toBytes("cf")); // 开启列簇 -- store的块缓存 family.setBlockCacheEnabled(true); family.setBlocksize(1024 * 1024 * 2); family.setCompressionType(Algorithm.SNAPPY); family.setMaxVersions(1); family.setMinVersions(1); desc.addFamily(family); // admin.createTable(desc); byte[][] splitKeys = { Bytes.toBytes("100"), Bytes.toBytes("200"), Bytes.toBytes("300") }; admin.createTable(desc, splitKeys);
热点现象:某个小的时段内,对HBase的读写请求集中到极少数的Region上,导致这些Region所在的RegionServer处理请求量骤增,负载量明显偏大,而其他的RegionServer明显空闲; 出现的原因:主要是因为Hbase表设计时,rowKey设计不合理造成的; 解决办法:Rowkey的随机散列+创表预分区
RowKey设计原则: 1、总的原则:避免热点现象,提高读写性能; 2、长度原则:最大长度64KB,开发通常8个字节倍数,因为Hbase中每个单元格是以key-value进行存储的,因此每个value都会存储rowkey,所以rowkey越来越占空间; 3、散列原则:将时间上连续产生的rowkey散列化,以避免集中到极少数Region上 4、唯一原则:必须在设计上保证rowkey的唯一性 RowKey设计结合业务: 在满足rowkey设计原则的基础上,往往需要将经常用于查询的字段整合到rowkey上,以提高检索查询效率
2.10 Hbase参数调优
hbase.regionserver.handler.count
该设置决定了处理RPC的线程数量,默认值是10,通常可以调大,比如:150,当请求内容很大(上MB,比如大的put、使用缓存的scans)的时候,如果该值设置过大则会占用过多的内存,导致频繁的GC,或者出现OutOfMemory,因此该值不是越大越好。
hbase.hregion.max.filesize
配置region大小,默认是10G,region大小一般控制在几个G比较合适,可以在建表时规划好region数量,进行预分区,做到一定时间内,每个region的数据大小在一定的数据量之下,当发现有大的region,或者需要对整个表进行region扩充时再进行split操作,一般提供在线服务的hbase集群均会弃用hbase的自动split,转而自己管理split。
hbase.hregion.majorcompaction
配置major合并的间隔时间,默认值604800000,单位ms。表示major compaction默认7天调度一次,HBase 0.96.x及之前默认为1天调度一次,设置为 0 时表示禁用自动触发major compaction。一般major compaction持续时间较长、系统资源消耗较大,对上层业务也有比较大的影响,一般生产环境下为了避免影响读写请求,会禁用自动触发major compaction,可手动或者通过脚本定期进行major合并。
hbase.hstore.compaction.min
默认值 3,一个列族下的HFile数量超过该值就会触发Minor Compaction,这个参数默认值小了,一般情况下建议调大到5~10之间,注意相应调整下一个参数
hbase.hstore.compaction.max
默认值 10,一次Minor Compaction最多合并的HFile文件数量,这个参数基本控制着一次压缩即Compaction的耗时。这个参数要比上一个参数hbase.hstore.compaction.min值大,通常是其2~3倍。
hbase.hstore.blockingStoreFiles
默认值 10,一个列族下HFile数量达到该值,flush操作将会受到阻塞,阻塞时间为hbase.hstore.blockingWaitTime,默认90000,即1.5分钟,在这段时间内,如果compaction操作使得HFile下降到blockingStoreFiles配置值,则停止阻塞。另外阻塞超过时间后,也会恢复执行flush操作。这样做可以有效地控制大量写请求的速度,但同时这也是影响写请求速度的主要原因之一。生产环境中默认值太小了,一般建议设置大点比如100,避免出现阻塞更新的情况
hbase.regionserver.global.memstore.size
默认值0.4,RS所有memstore占用内存在总内存中的比例,当达到该值,则会从整个RS中找出最需要flush的region进行flush,直到总内存比例降至该数限制以下,并且在降至限制比例前,将阻塞所有的写memstore的操作,在以写为主的集群中,可以调大该配置项,不建议太大,因为block cache和memstore cache的总大小不会超过0.8,而且不建议这两个cache的大小总和达到或者接近0.8,避免OOM,在偏向写的业务时,可配置为0.45
hbase.regionserver.global.memstore.size.lower.limit
默认值0.95,相当于上一个参数的0.95
如果有 16G 堆内存,默认情况下:
# 达到该值会触发刷写 16 * 0.4 * 0.95 = 6.08 # 达到该值会触发阻塞 16 * 0.4 = 6.4
| 新参数 | 老参数 |
|---|---|
| hbase.regionserver.global.memstore.size | hbase.regionserver.global.memstore.upperLimit |
| hbase.regionserver.global.memstore.size.lower.limit | hbase.regionserver.global.memstore.lowerLimit |
hfile.block.cache.size
RS的block cache的内存大小限制,默认值0.4,在偏向读的业务中,可以适当调大该值,具体配置时需试hbase集群服务的业务特征,结合memstore的内存占比进行综合考虑。
hbase.hregion.memstore.flush.size
默认值128M,单位字节,超过将被flush到hdfs,该值比较适中,一般不需要调整。
hbase.hregion.memstore.block.multiplier
默认值4,如果memstore的内存大小已经超过了hbase.hregion.memstore.flush.size的4倍,则会阻塞memstore的写操作,直到降至该值以下,为避免发生阻塞,最好调大该值,比如:6,不可太大,如果太大,则会增大导致整个RS的memstore内存超过global.memstore.size限制的可能性,进而增大阻塞整个RS的写的几率,如果region发生了阻塞会导致大量的线程被阻塞在到该region上,从而其它region的线程数会下降,影响整体的RS服务能力。
hbase.regionserver.regionSplitLimit
控制最大的region数量,超过则不可以进行split操作,默认是Integer.MAX(2147483647),可设置为1,禁止自动的split,通过人工,或者写脚本在集群空闲时执行。如果不禁止自动的split,则当region大小超过hbase.hregion.max.filesize时会触发split操作(具体的split有一定的策略,不仅仅通过该参数控制,前期的split会考虑region数据量和memstore大小),每次flush或者compact之后,regionserver都会检查是否需要Split,split会先下线老region再上线split后的region,该过程会很快,但是会存在两个问题:1、老region下线后,新region上线前client访问会失败,在重试过程中会成功但是如果是提供实时服务的系统则响应时长会增加;2、split后的compact是一个比较耗资源的动作。
hbase.regionserver.maxlogs:默认值32,HLOG最大的数量
hbase.regionserver.hlog.blocksize:默认为 2 倍的HDFS block size(128MB),即256MB
JVM调整:
内存大小:master默认为1G,可增加到2G,regionserver默认1G,可调大到10G,或者更大,zk并不耗资源,可以不用调整,需要注意的是,调整了rs的内存大小后,需调整hbase.regionserver.maxlogs和hbase.regionserver.hlog.blocksize这两个参数,WAL的最大值由hbase.regionserver.maxlogs * hbase.regionserver.hlog.blocksize决定(默认32*2*128M=8G),一旦达到这个值,就会被触发flush memstore,如果memstore的内存增大了,但是没有调整这两个参数,实际上对大量小文件没有任何改进,调整策略:hbase.regionserver.hlog.blocksize * hbase.regionserver.maxlogs 设置为略大于hbase.regionserver.global.memstore.size* HBASE_HEAPSIZE。
什么时候触发 MemStore Flush?
有很多情况会触发 MemStore 的 Flush 操作,主要有以下几种情况:
-
Region 中任意一个 MemStore 占用的内存超过相关阈值
当一个 Region 中所有 MemStore 占用的内存大小超过刷写阈值的时候会触发一次刷写,这个阈值由 hbase.hregion.memstore.flush.size 参数控制,默认为128MB。我们每次调用 put、delete 等操作都会检查的这个条件的。
但是如果我们的数据增加得很快,达到了 hbase.hregion.memstore.flush.size * hbase.hregion.memstore.block.multiplier 的大小,hbase.hregion.memstore.block.multiplier 默认值为4,也就是128*4=512MB的时候,那么除了触发 MemStore 刷写之外,HBase 还会在刷写的时候同时阻塞所有写入该 Store 的写请求!这时候如果你往对应的 Store 写数据,会出现 RegionTooBusyException 异常。
-
整个 RegionServer 的 MemStore 占用内存总和大于相关阈值
如果达到了 RegionServer 级别的 Flush,那么当前 RegionServer 的所有写操作将会被阻塞,而且这个阻塞可能会持续到分钟级别。
-
WAL数量大于相关阈值或WAL的大小超过一定阈值
如果设置了
hbase.regionserver.maxlogs,那就是这个参数的值;否则是max(32, hbase_heapsize * hbase.regionserver.global.memstore.size * 2 / logRollSize)(logRollSize 默认大小为:0.95 * HDFS block size)
如果某个 RegionServer 的 WAL 数量大于
maxLogs就会触发 MemStore 的刷写。WAL的最大值由hbase.regionserver.maxlogs * hbase.regionserver.hlog.blocksize决定(默认32*2*128M=8G),一旦达到这个值,就会被触发flush memstore,如果memstore的内存增大了,但是没有调整这两个参数,实际上对大量小文件没有任何改进,调整策略:hbase.regionserver.hlog.blocksize * hbase.regionserver.maxlogs 设置为略大于hbase.regionserver.global.memstore.size* HBASE_HEAPSIZE。
-
定期自动刷写
如果我们很久没有对 HBase 的数据进行更新,这时候就可以依赖定期刷写策略了。RegionServer 在启动的时候会启动一个线程 PeriodicMemStoreFlusher 每隔 hbase.server.thread.wakefrequency 时间(服务线程的sleep时间,默认10000毫秒)去检查属于这个 RegionServer 的 Region 有没有超过一定时间都没有刷写,这个时间是由 hbase.regionserver.optionalcacheflushinterval 参数控制的,默认是 3600000,也就是1小时会进行一次刷写。如果设定为0,则意味着关闭定时自动刷写。
为了防止一次性有过多的 MemStore 刷写,定期自动刷写会有 0 ~ 5 分钟的延迟
-
数据更新超过一定阈值
如果 HBase 的某个 Region 更新的很频繁,而且既没有达到自动刷写阀值,也没有达到内存的使用限制,但是内存中的更新数量已经足够多,比如超过
hbase.regionserver.flush.per.changes参数配置,默认为30000000,那么也是会触发刷写的。 -
手动触发刷写
分别对某张表、某个 Region 进行刷写操作。
可以在 Shell 中执行 flush 命令
什么操作会触发 MemStore 刷写?
常见的 put、delete、append、incr、调用 flush 命令、Region 分裂、Region Merge、bulkLoad HFiles 以及给表做快照操作都会对上面的相关条件做检查,以便判断要不要做刷写操作。
MemStore 刷写策略(FlushPolicy)
在 HBase 1.1 之前,MemStore 刷写是 Region 级别的。就是说,如果要刷写某个 MemStore ,MemStore 所在的 Region 中其他 MemStore 也是会被一起刷写的!这会造成一定的问题,比如小文件问题。可以通过 hbase.regionserver.flush.policy 参数选择不同的刷写策略。
目前 HBase 2.x 的刷写策略全部都是实现 FlushPolicy 抽象类的。并且自带三种刷写策略:FlushAllLargeStoresPolicy、FlushNonSloppyStoresFirstPolicy 以及 FlushAllStoresPolicy。
-
FlushAllStoresPolicy
这种刷写策略实现最简单,直接返回当前 Region 对应的所有 MemStore。也就是每次刷写都是对 Region 里面所有的 MemStore 进行的,这个行为和 HBase 1.1 之前是一样的。
-
FlushAllLargeStoresPolicy
在 HBase 2.0 之前版本是 FlushLargeStoresPolicy,后面被拆分成分 FlushAllLargeStoresPolicy 和FlushNonSloppyStoresFirstPolicy
这种策略会先判断 Region 中每个 MemStore 的使用内存是否大于某个阀值,大于这个阀值的 MemStore 将会被刷写
hbase.hregion.percolumnfamilyflush.size.lower.bound.min 默认值为 16MB
hbase.hregion.percolumnfamilyflush.size.lower.bound 没有默认值,计算规则如下:
比如当前表有3个列族,那么 flushSizeLowerBound = max((long)128 / 3, 16) = 42。
如果 Region 中没有 MemStore 的使用内存大于上面的阀值,FlushAllLargeStoresPolicy 策略就退化成 FlushAllStoresPolicy 策略了,也就是会对 Region 里面所有的 MemStore 进行 Flush。
-
FlushNonSloppyStoresFirstPolicy
HBase 2.0 引入了 in-memory compaction,如果我们对相关列族 hbase.hregion.compacting.memstore.type 参数的值不是 NONE,那么这个 MemStore 的 isSloppyMemStore 值就是 true,否则就是 false。
FlushNonSloppyStoresFirstPolicy 策略将 Region 中的 MemStore 按照 isSloppyMemStore 分到两个 HashSet 里面(sloppyStores 和 regularStores)。然后
-
判断 regularStores 里面是否有 MemStore 内存占用大于相关阀值的 MemStore ,有的话就会对这些 MemStore 进行刷写,其他的不做处理,这个阀值计算和 FlushAllLargeStoresPolicy 的阀值计算逻辑一致。
-
如果 regularStores 里面没有 MemStore 内存占用大于相关阀值的 MemStore,这时候就开始在 sloppyStores 里面寻找是否有 MemStore 内存占用大于相关阀值的 MemStore,有的话就会对这些 MemStore 进行刷写,其他的不做处理。
-
如果上面 sloppyStores 和 regularStores 都没有满足条件的 MemStore 需要刷写,这时候就 FlushNonSloppyStoresFirstPolicy 策略久退化成 FlushAllStoresPolicy 策略了。
-


