

HBase中rowkey的设计
HBase的RowKey设计
HBase是三维有序存储的,通过rowkey(行键),column key(column family和qualifier)和TimeStamp(时间戳)这个三个维度可以对HBase中的数据进行快速定位。
HBase中rowkey可以唯一标识一行记录,在HBase查询的时候,有两种方式:
通过get方式,指定rowkey获取唯一一条记录
通过scan方式,设置startRow和stopRow参数进行范围匹配
全表扫描,即直接扫描整张表中所有行记录
rowkey长度原则
rowkey是一个二进制码流,可以是任意字符串,最大长度 64kb ,实际应用中一般为10-100bytes,以 byte[] 形式保存,一般设计成定长。
建议越短越好,不要超过16个字节,原因如下:
数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,比如超过100字节,1000w行数据,光rowkey就要占用100*1000w=10亿个字节,将近1G数据,这样会极大影响HFile的存储效率;
MemStore将缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。
目前操作系统都是64位系统,内存8字节对齐,控制在16个字节,8字节的整数倍利用了操作系统的最佳特性。
rowkey散列原则
如果rowkey按照时间戳的方式递增,不要将时间放在二进制码的前面,建议将rowkey的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息,所有的数据都会集中在一个RegionServer上,这样在数据检索的时候负载会集中在个别的RegionServer上,造成热点问题,会降低查询效率。
rowkey唯一原则
必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
什么是热点
HBase中的行是按照rowkey的字典顺序排序的,这种设计优化了scan操作,可以将相关的行以及会被一起读取的行存取在临近位置,便于scan。然而糟糕的rowkey设计是热点的源头。 热点发生在大量的client直接访问集群的一个或极少数个节点(访问可能是读,写或者其他操作)。大量访问会使热点region所在的单个机器超出自身承受能力,引起性能下降甚至region不可用,这也会影响同一个RegionServer上的其他region,由于主机无法服务其他region的请求。 设计良好的数据访问模式以使集群被充分,均衡的利用。
为了避免写热点,设计rowkey使得不同行在同一个region,但是在更多数据情况下,数据应该被写入集群的多个region,而不是一个。
下面是一些常见的避免热点的方法以及它们的优缺点:
加盐
这里所说的加盐不是密码学中的加盐,而是在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同。分配的前缀种类数量应该和你想使用数据分散到不同的region的数量一致。加盐之后的rowkey就会根据随机生成的前缀分散到各个region上,以避免热点。
哈希
反转
第三种防止热点的方法时反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。
反转rowkey的例子以手机号为rowkey,可以将手机号反转后的字符串作为rowkey,这样的就避免了以手机号那样比较固定开头导致热点问题
时间戳反转
一个常见的数据处理问题是快速获取数据的最近版本,使用反转的时间戳作为rowkey的一部分对这个问题十分有用,可以用 Long.Max_Value - timestamp 追加到key的末尾,例如 [key]reverse_timestamp , [key] 的最新值可以通过scan [key]获得[key]的第一条记录,因为HBase中rowkey是有序的,第一条记录是最后录入的数据。
比如需要保存一个用户的操作记录,按照操作时间倒序排序,在设计rowkey的时候,可以这样设计
[userId反转]Long.Max_Value - timestamp,在查询用户的所有操作记录数据的时候,直接指定反转后的userId,startRow是[userId反转]000000000000,stopRow是[userId反转]Long.Max_Value - timestamp
如果需要查询某段时间的操作记录,startRow是[user反转]Long.Max_Value - 起始时间,stopRow是[userId反转]Long.Max_Value - 结束时间
其他一些建议
尽量减少行和列的大小在HBase中,value永远和它的key一起传输的。当具体的值在系统间传输时,它的rowkey,列名,时间戳也会一起传输。如果你的rowkey和列名很大,甚至可以和具体的值相比较,那么你将会遇到一些有趣的问题。HBase storefiles中的索引(有助于随机访问)最终占据了HBase分配的大量内存,因为具体的值和它的key很大。可以增加block大小使得storefiles索引再更大的时间间隔增加,或者修改表的模式以减小rowkey和列名的大小。压缩也有助于更大的索引。
列族尽可能越短越好,最好是一个字符
冗长的属性名虽然可读性好,但是更短的属性名存储在HBase中会更好

# 原数据:以时间戳_user_id作为rowkey # 时间戳高位变化不大,太连续,最终可能会导致热点问题 1638584124_user_id 1638584135_user_id 1638584146_user_id 1638584157_user_id 1638584168_user_id 1638584179_user_id # 解决方案:加盐、反转、哈希 # 加盐 # 加上随即前缀,随机的打散 # 该过程无法预测 前缀时随机的 00_1638584124_user_id 05_1638584135_user_id 03_1638584146_user_id 04_1638584157_user_id 02_1638584168_user_id 06_1638584179_user_id # 反转 # 适用于高位变化不大,低位变化大的rowkey 4214858361_user_id 5314858361_user_id 6414858361_user_id 7514858361_user_id 8614858361_user_id 9714858361_user_id # 散列 md5(不可逆)、sha1(可逆)、sha256...... 25531D7065AE158AAB6FA53379523979_user_id 60F9A0072C0BD06C92D768DACF2DFDC3_user_id D2EFD883A6C0198DA3AF4FD8F82DEB57_user_id A9A4C265D61E0801D163927DE1299C79_user_id 3F41251355E092D7D8A50130441B58A5_user_id 5E6043C773DA4CF991B389D200B77379_user_id # 时间戳"反转" # rowkey:时间戳_user_id # rowkey是字典升序的,那么越新的记录会被排在最后面,不容易被获取到 # 需求:让最新的记录排在最前面 # 大数:9999999999 # 大数-小数 1638584124_user_id => 8361415875_user_id 1638584135_user_id => 8361415864_user_id 1638584146_user_id => 8361415853_user_id 1638584157_user_id => 8361415842_user_id 1638584168_user_id => 8361415831_user_id 1638584179_user_id => 8361415820_user_id 1638586193_user_id => 8361413806_user_id
手机号,网格编号,城市编号,区县编号,停留时间,进入时间,离开时间,时间分区 D55433A437AEC8D8D3DB2BCA56E9E64392A9D93C,117210031795040,83401,8340104,301,20180503190539,20180503233517,20180503 将用户位置数据保存到hbase 查询需求 1、通过手机号查询用户最近10条位置记录 2、获取用户某一天在一个城市中的所有位置 怎么设计hbase表 1、rowkey 2、时间戳
package dianxin; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.*; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.filter.*; import org.apache.hadoop.hbase.util.Bytes; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.io.BufferedReader; import java.io.FileReader; import java.io.IOException; import java.util.ArrayList; import java.util.List; /* 75FB1C52EC61B895481733001AD88DC255F45283 117215031840040 83401 8340104 345 20180503091059 20180503145115 20180503 75FB1C52EC61B895481733001AD88DC255F45283 117175031705040 83401 8340123 31 20180503222458 20180503222458 20180503 75FB1C52EC61B895481733001AD88DC255F45283 117180031710040 83401 8340123 104 20180503192047 20180503205208 20180503 75FB1C52EC61B895481733001AD88DC255F45283 117180031710040 83401 8340123 26 20180503215402 20180503215402 20180503 75FB1C52EC61B895481733001AD88DC255F45283 117180031710040 83401 8340123 31 20180503225554 20180503225554 20180503 75FB1C52EC61B895481733001AD88DC255F45283 117210031835040 83401 8340104 6 20180503180533 20180503180533 20180503 rowkey: 75FB1C52EC61B895481733001AD88DC255F45283_20180503091059 75FB1C52EC61B895481733001AD88DC255F45283_20180503222458 75FB1C52EC61B895481733001AD88DC255F45283_20180503192047 75FB1C52EC61B895481733001AD88DC255F45283_20180503215402 75FB1C52EC61B895481733001AD88DC255F45283_20180503225554 75FB1C52EC61B895481733001AD88DC255F45283_20180503180533 在Hbase中存储的效果: 75FB1C52EC61B895481733001AD88DC255F45283_1 75FB1C52EC61B895481733001AD88DC255F45283_2 75FB1C52EC61B895481733001AD88DC255F45283_3 75FB1C52EC61B895481733001AD88DC255F45283_4 75FB1C52EC61B895481733001AD88DC255F45283_5 75FB1C52EC61B895481733001AD88DC255F45283_6 需求:求该用户的最近几条记录 拿一个较大的值减去时间戳 20190000000000 - 20180503091059 = numberMax 10- 75FB1C52EC61B895481733001AD88DC255F45283_1 ---> 75FB1C52EC61B895481733001AD88DC255F45283_9 75FB1C52EC61B895481733001AD88DC255F45283_2 ---> 75FB1C52EC61B895481733001AD88DC255F45283_8 75FB1C52EC61B895481733001AD88DC255F45283_3 ---> 75FB1C52EC61B895481733001AD88DC255F45283_7 75FB1C52EC61B895481733001AD88DC255F45283_4 ---> 75FB1C52EC61B895481733001AD88DC255F45283_6 75FB1C52EC61B895481733001AD88DC255F45283_5 ---> 75FB1C52EC61B895481733001AD88DC255F45283_5 75FB1C52EC61B895481733001AD88DC255F45283_6 ---> 75FB1C52EC61B895481733001AD88DC255F45283_4 时间戳反转后: 根据hbaserowkey是字典顺序排序的。结果如下: 75FB1C52EC61B895481733001AD88DC255F45283_4 75FB1C52EC61B895481733001AD88DC255F45283_5 75FB1C52EC61B895481733001AD88DC255F45283_6 75FB1C52EC61B895481733001AD88DC255F45283_7 75FB1C52EC61B895481733001AD88DC255F45283_8 75FB1C52EC61B895481733001AD88DC255F45283_9 */ public class DianXinDemo { HConnection conn = null; HBaseAdmin hadmin = null; @Before public void init() { try { //1、获取hadoop的相关环境 Configuration conf = new Configuration(); //2、设置zookeeper集群的配置 conf.set("hbase.zookeeper.quorum", "node1:2181,node2:2181,master:2181"); //3、获取hbase的连接对象 conn = HConnectionManager.createConnection(conf); //4、获取HMaster的对象 hadmin = new HBaseAdmin(conf); System.out.println("获取连接成功:" + hadmin); } catch (IOException e) { e.printStackTrace(); } } /** * 创建一张表 */ @Test public void createTable(){ //创建表描述器 HTableDescriptor dianxin_2 = new HTableDescriptor("dianxin_2"); //创建列簇描述器 HColumnDescriptor info = new HColumnDescriptor("info"); dianxin_2.addFamily(info); try { hadmin.createTable(dianxin_2); System.out.println("表创建成功!!"); } catch (IOException e) { e.printStackTrace(); } } @Test public void pusDatas(){ try { //获取表的实例 HTableInterface dianxin_2 = conn.getTable("dianxin_2"); //创建put集合 ArrayList<Put> puts = new ArrayList<>(); BufferedReader br = new BufferedReader(new FileReader("D:\\soft\\projects\\bigdata19-project\\bigdata19-hbase\\data\\dianxin_data")); String line = null; while ((line=br.readLine())!=null){ String[] strings = line.split("\t"); if(strings.length>7 && !("\\N".equals(strings[2]))){ //设计rowkey //2147483647 long l = 20190000000000L - Long.parseLong(strings[5]); //将手机号与减后的值做拼接得到rowkey String rowkey = strings[0]+"_"+l; String wg = strings[1]; String city = strings[2]; String qx = strings[3]; String stayTime = strings[4]; String leaveTime = strings[6]; String date = strings[7]; Put put = new Put(rowkey.getBytes()); put.add("info".getBytes(),"city".getBytes(),city.getBytes()); put.add("info".getBytes(),"wg".getBytes(),wg.getBytes()); put.add("info".getBytes(),"qx".getBytes(),qx.getBytes()); put.add("info".getBytes(),"stayTime".getBytes(),stayTime.getBytes()); put.add("info".getBytes(),"leaveTime".getBytes(),leaveTime.getBytes()); put.add("info".getBytes(),"date".getBytes(),date.getBytes()); puts.add(put); } } dianxin_2.put(puts); } catch (IOException e) { e.printStackTrace(); } } /** * 通过手机号查询用户最近10条位置记录 * * 288FE96588F7F21649E0A8A6856E86FA85EF2251 */ @Test public void scanData(){ try { //获取表的实例 HTableInterface dianxin_2 = conn.getTable("dianxin_2"); Scan scan = new Scan(); //创建二进制前缀比较器 BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator("288FE96588F7F21649E0A8A6856E86FA85EF2251".getBytes()); //创建行键过滤器 RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL, binaryPrefixComparator); scan.setFilter(rowFilter); scan.setLimit(10); ResultScanner sc = dianxin_2.getScanner(scan); /** * 第一种方式,当知道列名列的个数的时候 */ Result rs = null; while ((rs=sc.next())!=null){ String rowkey = Bytes.toString(rs.getRow()); String phoneNum = rowkey.split("_")[0]; long enterTime = 20190000000000L - Long.parseLong(rowkey.split("_")[1]); String wg = Bytes.toString(rs.getValue("info".getBytes(), "wg".getBytes())); String city = Bytes.toString(rs.getValue("info".getBytes(), "city".getBytes())); String qx = Bytes.toString(rs.getValue("info".getBytes(), "qx".getBytes())); String stayTime = Bytes.toString(rs.getValue("info".getBytes(), "stayTime".getBytes())); String leaveTime = Bytes.toString(rs.getValue("info".getBytes(), "leaveTime".getBytes())); String date = Bytes.toString(rs.getValue("info".getBytes(), "date".getBytes())); System.out.println("手机号:"+phoneNum+"\t网格编号:"+wg+"\t城市:"+city +"\t区县:"+qx+"\t停留时间:"+stayTime+"分钟\t进入网格时间:" +enterTime+"\t离开网格时间:"+leaveTime+"\t日期:"+date); //自己实现,第二种遍历方式 //cell方式实现 } } catch (IOException e) { e.printStackTrace(); } } /** * 获取用户某一天在一个城市中的所有位置 * 288FE96588F7F21649E0A8A6856E86FA85EF2251 * 20180503 * 83401 * * wg */ @Test public void scanDatas2(){ try { //获取表的实例 HTableInterface dianxin_2 = conn.getTable("dianxin_2"); Scan scan = new Scan(); //创建二进制前缀比较器 BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator("288FE96588F7F21649E0A8A6856E86FA85EF2251".getBytes()); //创建行键过滤器 RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL, binaryPrefixComparator); //创建二进制比较器 BinaryComparator binaryComparator = new BinaryComparator("20180503".getBytes()); //创建单列值过滤器 SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter( "info".getBytes(), "date".getBytes(), CompareFilter.CompareOp.EQUAL, binaryComparator ); //创建二进制比较器 BinaryComparator binaryComparator2 = new BinaryComparator("83401".getBytes()); //创建单列值过滤器 SingleColumnValueFilter singleColumnValueFilter2 = new SingleColumnValueFilter( "info".getBytes(), "city".getBytes(), CompareFilter.CompareOp.EQUAL, binaryComparator2 ); //创建FilterList FilterList filterList = new FilterList(); filterList.addFilter(rowFilter); filterList.addFilter(singleColumnValueFilter); filterList.addFilter(singleColumnValueFilter2); scan.setFilter(filterList); ResultScanner sc = dianxin_2.getScanner(scan); /** * 第一种方式,当知道列名列的个数的时候 */ Result rs = null; while ((rs=sc.next())!=null){ String rowkey = Bytes.toString(rs.getRow()); String phoneNum = rowkey.split("_")[0]; long enterTime = 20190000000000L - Long.parseLong(rowkey.split("_")[1]); String wg = Bytes.toString(rs.getValue("info".getBytes(), "wg".getBytes())); String city = Bytes.toString(rs.getValue("info".getBytes(), "city".getBytes())); String qx = Bytes.toString(rs.getValue("info".getBytes(), "qx".getBytes())); String stayTime = Bytes.toString(rs.getValue("info".getBytes(), "stayTime".getBytes())); String leaveTime = Bytes.toString(rs.getValue("info".getBytes(), "leaveTime".getBytes())); String date = Bytes.toString(rs.getValue("info".getBytes(), "date".getBytes())); System.out.println("手机号:"+phoneNum+"\t网格编号:"+wg+"\t城市:"+city +"\t区县:"+qx+"\t停留时间:"+stayTime+"分钟\t进入网格时间:" +enterTime+"\t离开网格时间:"+leaveTime+"\t日期:"+date); //自己实现,第二种遍历方式 } } catch (IOException e) { e.printStackTrace(); } } @After public void close() { if (hadmin != null) { try { hadmin.close(); } catch (IOException e) { e.printStackTrace(); } } if (conn != null) { try { conn.close(); } catch (IOException e) { e.printStackTrace(); } } } }
九、二级索引
二级索引的本质就是建立各列值与行键之间的映射关系
Hbase的局限性:
HBase本身只提供基于行键和全表扫描的查询,而行键索引单一,对于多维度的查询困难。
所以我们引进一个二级索引的概念
常见的二级索引:
HBase的一级索引就是rowkey,我们只能通过rowkey进行检索。如果我们相对hbase里面列族的列列进行一些组合查询,就需要采用HBase的二级索引方案来进行多条件的查询。
-
MapReduce方案
-
ITHBASE(Indexed-Transanctional HBase)方案
-
IHBASE(Index HBase)方案
-
Hbase Coprocessor(协处理器)方案
-
Solr+hbase方案 redis+hbase 方案
-
CCIndex(complementalclustering index)方案
二级索引的种类
1、创建单列索引 2、同时创建多个单列索引 3、创建联合索引(最多同时支持3个列) 4、只根据rowkey创建索引
单表建立二级索引
1.首先disable ‘表名’ 2.然后修改表 alter 'LogTable',METHOD=>'table_att','coprocessor'=>'hdfs:///写好的Hbase协处理器(coprocessor)的jar包名|类的绝对路径名|1001' 3. enable '表名'
二级索引的设计思路
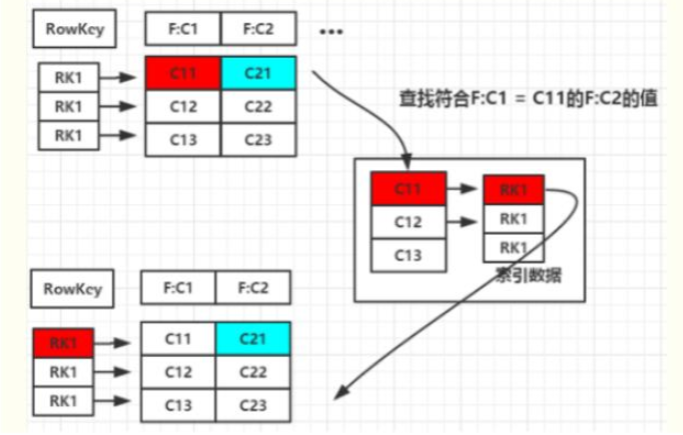
二级索引的本质就是建立各列值与行键之间的映射关系 如上图1,当要对F:C1这列建立索引时,只需要建立F:C1各列值到其对应行键的映射关系,如C11->RK1等,这样就完成了对F:C1列值的二级索引的构建,当要查询符合F:C1=C11对应的F:C2的列值时(即根据C1=C11来查询C2的值,图1青色部分) 其查询步骤如下: 1. 根据C1=C11到索引数据中查找其对应的RK,查询得到其对应的RK=RK1 2. 得到RK1后就自然能根据RK1来查询C2的值了 这是构建二级索引大概思路,其他组合查询的联合索引的建立也类似。
使用整合MapReduce的方式创建hbase索引。主要的流程如下:
1.1扫描输入表,使用hbase继承类TableMapper
1.2获取rowkey和指定字段名称和字段值
1.3创建Put实例, value=” “, rowkey=班级,column=学号
1.4使用IdentityTableReducer将数据写入索引表
案例:
1、在hbase中创建索引表 student_index
create 'student_index','info'
2、编写mapreduce代码
package com.shujia.hbaseapi.hbaseindexdemo; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.client.Mutation; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.hbase.mapreduce.TableMapper; import org.apache.hadoop.hbase.mapreduce.TableReducer; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * 编写整个mapreduce程序建立索引表 */ class IndexMapper extends TableMapper<Text, NullWritable>{ @Override protected void map(ImmutableBytesWritable key, Result value, Mapper<ImmutableBytesWritable, Result, Text, NullWritable>.Context context) throws IOException, InterruptedException { String id = Bytes.toString(key.get()); String clazz = Bytes.toString(value.getValue("info".getBytes(), "clazz".getBytes())); String key1 = id+"_"+clazz; context.write(new Text(key1),NullWritable.get()); } } /** * * reduce端获取map端传过来的key */ class IndexReduce extends TableReducer<Text,NullWritable,NullWritable>{ @Override protected void reduce(Text key, Iterable<NullWritable> values, Reducer<Text, NullWritable, NullWritable, Mutation>.Context context) throws IOException, InterruptedException { String[] strings = key.toString().split("_"); String id = strings[0]; String clazz = strings[1]; //索引表也是属于hbase的表,需要使用put实例添加数据 Put put = new Put(clazz.getBytes()); put.add("info".getBytes(),id.getBytes(),"".getBytes()); context.write(NullWritable.get(),put); } } public class HbaseIndex { public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { Configuration conf = new Configuration(); conf.set("hbase.zookeeper.quorum", "master:2181,node1:2181,node2:2181"); Job job = Job.getInstance(conf); job.setJobName("建立学生索引表"); job.setJarByClass(HbaseIndex.class); Scan scan = new Scan(); scan.addFamily("info".getBytes()); //指定对哪张表建立索引,以及指定需要建索引的列所属的列簇 TableMapReduceUtil.initTableMapperJob("students",scan,IndexMapper.class,Text.class,NullWritable.class,job); TableMapReduceUtil.initTableReducerJob("student_index",IndexReduce.class,job); job.waitForCompletion(true); } }
3、打成jar包上传到hadoop中运行
hadoop jar had-hbase-demo-1.0-SNAPSHOT-jar-with-dependencies.jar com.shujia.hbaseapi.hbaseindexdemo.HbaseIndex
4、编写查询代码,测试结果(先查询索引表,在查数据)
package com.shujia.hbaseapi.hbaseindexdemo; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellUtil; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.filter.CompareFilter; import org.apache.hadoop.hbase.filter.SingleColumnValueFilter; import org.apache.hadoop.hbase.filter.SubstringComparator; import org.apache.hadoop.hbase.util.Bytes; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.io.IOException; import java.util.ArrayList; import java.util.List; public class HbaseIndexToStudents { private HConnection conn; private HBaseAdmin hAdmin; @Before public void connect() { try { //1、获取Hadoop的相关配置环境 Configuration conf = new Configuration(); //2、获取zookeeper的配置 conf.set("hbase.zookeeper.quorum", "master:2181,node1:2181,node2:2181"); //获取与Hbase的连接,这个连接是将来可以用户获取hbase表的 conn = HConnectionManager.createConnection(conf); //将来我们要对表做DDL相关操作,而对表的操作在hbase架构中是有HMaster hAdmin = new HBaseAdmin(conf); System.out.println("建立连接成功:" + conn + ", HMaster获取成功:" + hAdmin); } catch (IOException e) { e.printStackTrace(); } } /** * 通过索引表进行查询数据 * <p> * 需求:获取理科二班所有的学生信息,不适用过滤器,使用索引表查询 */ @Test public void scanData() { try { long start = System.currentTimeMillis(); //创建一个集合存放查询到的学号 ArrayList<Get> gets = new ArrayList<>(); //获取到索引表 HTableInterface student_index = conn.getTable("student_index"); //创建Get实例 Get get = new Get("理科二班".getBytes()); Result result = student_index.get(get); List<Cell> cells = result.listCells(); for (Cell cell : cells) { //每一个单元格的列名 byte[] bytes = CellUtil.cloneQualifier(cell); String id = Bytes.toString(bytes); Get get1 = new Get(id.getBytes()); //将学号添加到集合中 gets.add(get1); } //获取真正的学生数据表 students HTableInterface students = conn.getTable("students"); Result[] results = students.get(gets); for (Result result1 : results) { String id = Bytes.toString(result1.getRow()); String name = Bytes.toString(result1.getValue("info".getBytes(), "name".getBytes())); String age = Bytes.toString(result1.getValue("info".getBytes(), "age".getBytes())); String gender = Bytes.toString(result1.getValue("info".getBytes(), "gender".getBytes())); String clazz = Bytes.toString(result1.getValue("info".getBytes(), "clazz".getBytes())); System.out.println("学号:" + id + ", 姓名:" + name + ", 年龄:" + age + ", 性别:" + gender + ", 班级:" + clazz); } long endtime = System.currentTimeMillis(); System.out.println("========================================="); System.out.println((endtime - start) + "毫秒"); } catch (IOException e) { e.printStackTrace(); } } @Test public void getData() { try { long start = System.currentTimeMillis(); //获取真正的学生数据表 students HTableInterface students = conn.getTable("students"); Scan scan = new Scan(); SubstringComparator substringComparator = new SubstringComparator("理科二班"); SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter("info".getBytes(), "clazz".getBytes(), CompareFilter.CompareOp.EQUAL, substringComparator); scan.setFilter(singleColumnValueFilter); ResultScanner scanner = students.getScanner(scan); Result rs = null; while ((rs = scanner.next()) != null) { String id = Bytes.toString(rs.getRow()); String name = Bytes.toString(rs.getValue("info".getBytes(), "name".getBytes())); String age = Bytes.toString(rs.getValue("info".getBytes(), "age".getBytes())); String gender = Bytes.toString(rs.getValue("info".getBytes(), "gender".getBytes())); String clazz = Bytes.toString(rs.getValue("info".getBytes(), "clazz".getBytes())); System.out.println("学号:" + id + ", 姓名:" + name + ", 年龄:" + age + ", 性别:" + gender + ", 班级:" + clazz); } long endtime = System.currentTimeMillis(); System.out.println("========================================="); System.out.println((endtime - start) + "毫秒"); } catch (IOException e) { e.printStackTrace(); } } @After public void close() { if (conn != null) { try { conn.close(); } catch (IOException e) { e.printStackTrace(); } System.out.println("conn连接已经关闭....."); } if (hAdmin != null) { try { hAdmin.close(); } catch (IOException e) { e.printStackTrace(); } System.out.println("HMaster已经关闭......"); } } }
对于Hbase,如果想精确定位到某行记录,唯一的办法就是通过rowkey查询。如果不通过rowkey查找数据,就必须逐行比较每一行的值,对于较大的表,全表扫描的代价是不可接受的。
1、开启索引支持
# 关闭hbase集群 stop-hbase.sh # 在/usr/local/soft/hbase-1.4.6/conf/hbase-site.xml中增加如下配置 <property> <name>hbase.regionserver.wal.codec</name> <value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value> </property> <property> <name>hbase.rpc.timeout</name> <value>60000000</value> </property> <property> <name>hbase.client.scanner.timeout.period</name> <value>60000000</value> </property> <property> <name>phoenix.query.timeoutMs</name> <value>60000000</value> </property> # 同步到所有节点 scp hbase-site.xml node1:`pwd` scp hbase-site.xml node2:`pwd` # 修改phoenix目录下的bin目录中的hbase-site.xml <property> <name>hbase.rpc.timeout</name> <value>60000000</value> </property> <property> <name>hbase.client.scanner.timeout.period</name> <value>60000000</value> </property> <property> <name>phoenix.query.timeoutMs</name> <value>60000000</value> </property> # 启动hbase start-hbase.sh # 重新进入phoenix客户端 sqlline.py master,node1,node2
2.1、全局索引
全局索引适合读多写少的场景。如果使用全局索引,读数据基本不损耗性能,所有的性能损耗都来源于写数据。数据表的添加、删除和修改都会更新相关的索引表(数据删除了,索引表中的数据也会删除;数据增加了,索引表的数据也会增加)
注意: 对于全局索引在默认情况下,在查询语句中检索的列如果不在索引表中,Phoenix不会使用索引表将,除非使用hint。
手机号 进入网格的时间 离开网格的时间 区县编码 经度 纬度 基站标识 网格编号 业务类型 # 创建DIANXIN.sql CREATE TABLE IF NOT EXISTS DIANXIN ( mdn VARCHAR , start_date VARCHAR , end_date VARCHAR , county VARCHAR, x DOUBLE , y DOUBLE, bsid VARCHAR, grid_id VARCHAR, biz_type VARCHAR, event_type VARCHAR , data_source VARCHAR , CONSTRAINT PK PRIMARY KEY (mdn,start_date) ) column_encoded_bytes=0; # 上传数据DIANXIN.csv # 导入数据 psql.py master,node1,node2 DIANXIN.sql DIANXIN.csv # 创建全局索引 CREATE INDEX DIANXIN_INDEX ON DIANXIN ( end_date ); # 查询数据 ( 索引未生效) select * from DIANXIN where end_date = '20180503154014'; # 强制使用索引 (索引生效) hint select /*+ INDEX(DIANXIN DIANXIN_INDEX) */ * from DIANXIN where end_date = '20180503154014'; select /*+ INDEX(DIANXIN DIANXIN_INDEX) */ * from DIANXIN where end_date = '20180503154014' and start_date = '20180503154614'; # 取索引列,(索引生效) select end_date from DIANXIN where end_date = '20180503154014'; # 创建多列索引 CREATE INDEX DIANXIN_INDEX1 ON DIANXIN ( end_date,COUNTY ); # 多条件查询 (索引生效) select end_date,MDN,COUNTY from DIANXIN where end_date = '20180503154014' and COUNTY = '8340104'; # 查询所有列 (索引未生效) select * from DIANXIN where end_date = '20180503154014' and COUNTY = '8340104'; # 查询所有列 (索引生效) select /*+ INDEX(DIANXIN DIANXIN_INDEX1) */ * from DIANXIN where end_date = '20180503154014' and COUNTY = '8340104'; # 单条件 (索引未生效) select end_date from DIANXIN where COUNTY = '8340103'; # 单条件 (索引生效) end_date 在前 select COUNTY from DIANXIN where end_date = '20180503154014'; # 删除索引 drop index DIANXIN_INDEX on DIANXIN;
本地索引适合写多读少的场景,或者存储空间有限的场景。和全局索引一样,Phoenix也会在查询的时候自动选择是否使用本地索引。本地索引因为索引数据和原数据存储在同一台机器上,避免网络数据传输的开销,所以更适合写多的场景。由于无法提前确定数据在哪个Region上,所以在读数据的时候,需要检查每个Region上的数据从而带来一些性能损耗。
注意:对于本地索引,查询中无论是否指定hint或者是查询的列是否都在索引表中,都会使用索引表。
# 创建本地索引 CREATE LOCAL INDEX DIANXIN_LOCAL_IDEX ON DIANXIN(grid_id); # 索引生效 select grid_id from dianxin where grid_id='117285031820040'; # 索引生效 select * from dianxin where grid_id='117285031820040';
覆盖索引是把原数据存储在索引数据表中,这样在查询时不需要再去HBase的原表获取数据就,直接返回查询结果。
注意:查询是 select 的列和 where 的列都需要在索引中出现。
# 创建覆盖索引 CREATE INDEX DIANXIN_INDEX_COVER ON DIANXIN ( x,y ) INCLUDE ( county ); # 查询所有列 (索引未生效) select * from DIANXIN where x=117.288 and y =31.822; # 强制使用索引 (索引生效) select /*+ INDEX(DIANXIN DIANXIN_INDEX_COVER) */ * from DIANXIN where x=117.288 and y =31.822; # 查询索引中的列 (索引生效) mdn是DIANXIN表的RowKey中的一部分 select x,y,county from DIANXIN where x=117.288 and y =31.822; select mdn,x,y,county from DIANXIN where x=117.288 and y =31.822; # 查询条件必须放在索引中 select 中的列可以放在INCLUDE (将数据保存在索引中) select /*+ INDEX(DIANXIN DIANXIN_INDEX_COVER) */ x,y,count(*) from DIANXIN group by x,y;
# 导入依赖 <dependency> <groupId>org.apache.phoenix</groupId> <artifactId>phoenix-core</artifactId> <version>4.15.0-HBase-1.4</version> </dependency> <dependency> <groupId>com.lmax</groupId> <artifactId>disruptor</artifactId> <version>3.4.2</version> </dependency>



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下