

hive配置和安装-day2
Hive1.2.1安装
1.上传压缩包并解压(在/usr/local/soft/目录下)
tar -zxvf apache-hive-1.2.1-bin.tar.gz
2.修改目录名称
mv apache-hive-1.2.1-bin hive-1.2.1
3.修改配置文件(在hive-1.2.1下)node1和node2的也需要修改
HIVE_HOME=/usr/local/soft/hive-1.2.1
$HIVE_HOME/bin
4.备份配置文件

后面有template的文件只是模板文件,所以需要复制一份修改文件名,模板文件不能删除
命令:
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
5.修改hive-env.sh和hive-site.xml配置文件(在/usr/local/soft/hive-1.2.1/conf下)
修改hive-env.sh
加入三行内容
HADOOP_HOME=/usr/local/soft/hadoop-2.7.6 JAVA_HOME=/usr/local/soft/jdk1.8.0_171 HIVE_HOME=/usr/local/soft/hive-1.2.1
修改core-site.xml 注意:三个节点上都需要修改
<!--该参数表示可以通过httpfs接口hdfs的ip地址限制--> <property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <!--通过httpfs接口访问的用户获得的群组身份--> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property>
修改hive-site.xml(是修改,不能复制粘贴)
<!--数据存储位置就是我们在HDFS上看的目录-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value> (数据仓库,Hive中创建的表和数据会放在此目录下,和源数据比较像)
</property>
(注意:修改自己安装mysql的主机地址) (hive中分隔使用↦)
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.40.110:3306/hive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=utf8&useSSL=false</value>
</property>
(固定写法,mysql驱动类的位置)
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
(mysql的用户名)
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
(mysql的用户密码)
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
(你的hive安装目录的tmp目录)
<property>
<name>hive.querylog.location</name>
<value>/usr/local/soft/hive-1.2.1/tmp</value>
</property>
(同上)
<property>
<name>hive.exec.local.scratchdir</name>
<value>/usr/local/soft/hive-1.2.1/tmp</value>
</property>
(同上)
<property>
<name>hive.downloaded.resources.dir</name>
<value>/usr/local/soft/hive-1.2.1/tmp</value>
</property>
<!--指定这个的时候,为了启动metastore服务的时候不用指定端口-->
<!--hive --service metastore -p 9083 & | hive --service metastore-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
<description>thrift://master:9083</description>
</property>
6.拷贝mysql驱动包到/usr/local/soft/hive-1.2.1/lib目录下
cp /usr/local/soft/mysql-connector-java-5.1.49.jar ./
启动hive
启动hadoop
start-all.sh
启动hive
hive --service metastore
nohup hive --service metastore >/dev/null &
hive
启动HiveServer2
hiveserver2
nohup hiveserver2 >/dev/null &
beeline -u jdbc:hive2://master:10000 -n root
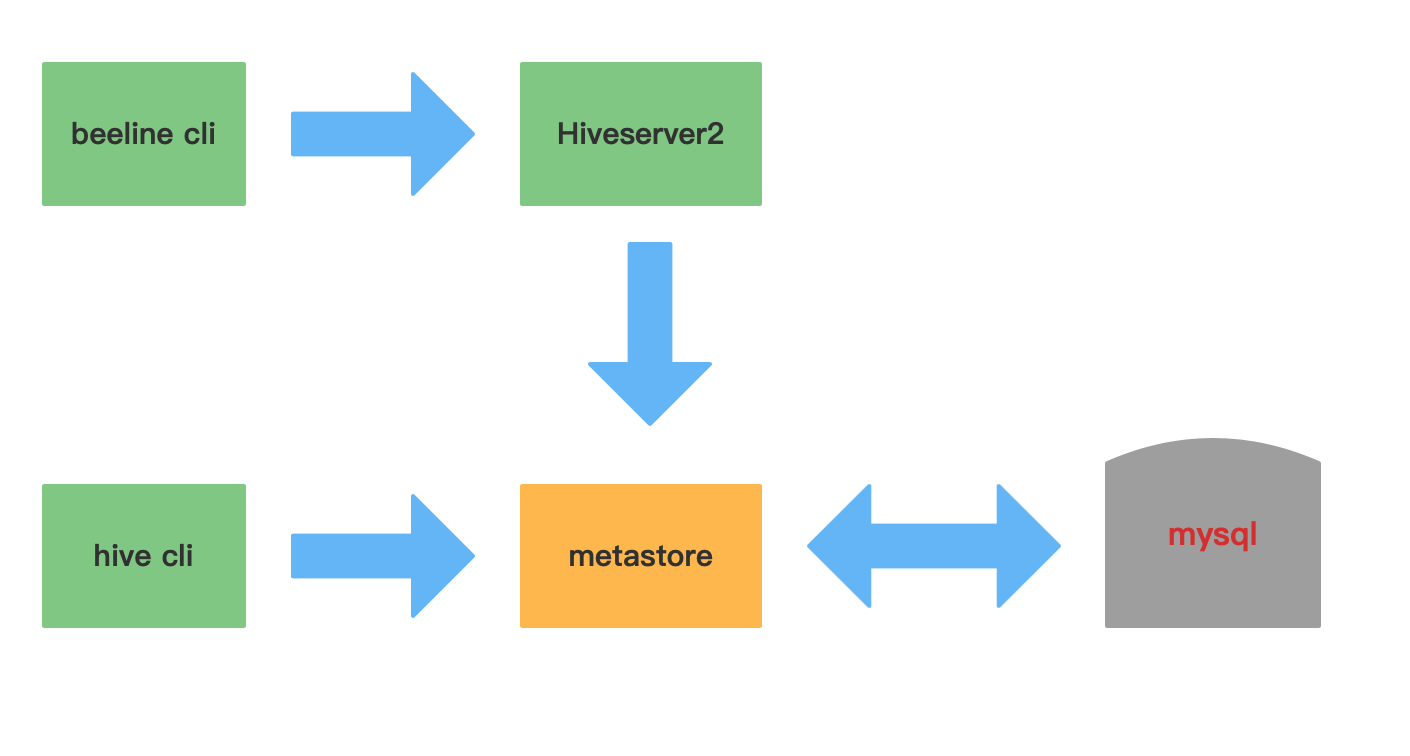
Hive的三种交互方式
1.第一种交互方式
shell交互Hive,用命令hive启动一个hive的shell命令行,在命令行中输入sql或者命令来和Hive交互。
服务端启动metastore服务(后台启动):nohup hive --service metastore >/dev/null & 进入命令:hive 退出命令行:quit;
2.第二种交互方式
服务端启动hiveserver2服务: nohup hive --service metastore >/dev/null & nohup hiveserver2 >/dev/null & 需要稍等一下,启动服务需要时间:(使用前提:修改core.site.xml)(需要把master上的hive-1.2.1远程复制到node1和node2上;命令:scp -r hive-1.2.1 node1或者node2:`pwd`) 进入命令:1)先执行: beeline ,再执行: !connect jdbc:hive2://master:10000 2)或者直接执行: beeline -u jdbc:hive2://master:10000 -n root 退出命令行:!exit
3.第三种交互方式
使用 –e 参数来直接执行hql的语句
bin/hive -e "show databases;"
vim hive.sql use myhive; select * from test;
hive -f hive.sql
怎么执行sql语句:
1.把sql语句放到文件中,执行那个文件;
使用:hive -f sql文件名 执行文件(可以使用脚本来定时执行)
2.执行sql文件
hive与beeline方式区别
Hive元数据
Hive元数据库中一些重要的表结构及用途,方便Impala、SparkSQL、Hive等组件访问元数据库的理解。
1、存储Hive版本的元数据表(VERSION),该表比较简单,但很重要,如果这个表出现问题,根本进不来Hive-Cli。比如该表不存在,当启动Hive-Cli的时候,就会报错“Table 'hive.version' doesn't exist”
DBS:该表存储Hive中所有数据库的基本信息。
DATABASE_PARAMS:该表存储数据库的相关参数。
3、Hive表和视图相关的元数据表
主要有TBLS、TABLE_PARAMS、TBL_PRIVS,这三张表通过TBL_ID关联。 TBLS:该表中存储Hive表,视图,索引表的基本信息。 TABLE_PARAMS:该表存储表/视图的属性信息。 TBL_PRIVS:该表存储表/视图的授权信息。
4、Hive文件存储信息相关的元数据表
主要涉及SDS、SD_PARAMS、SERDES、SERDE_PARAMS,由于HDFS支持的文件格式很多,而建Hive表时候也可以指定各种文件格式,Hive在将HQL解析成MapReduce时候,需要知道去哪里,使用哪种格式去读写HDFS文件,而这些信息就保存在这几张表中。 SDS:该表保存文件存储的基本信息,如INPUT_FORMAT、OUTPUT_FORMAT、是否压缩等。TBLS表中的SD_ID与该表关联,可以获取Hive表的存储信息。 SD_PARAMS: 该表存储Hive存储的属性信息。 SERDES:该表存储序列化使用的类信息。 SERDE_PARAMS:该表存储序列化的一些属性、格式信息,比如:行、列分隔符。
5、Hive表字段相关的元数据表
主要涉及COLUMNS_V2:该表存储表对应的字段信息。


