

hadoop day2-搭建
hadoop搭建
准备工作
三台虚拟机:master、node1、node2
检查时间是否同步:date
检查java的jdk是否被安装好:java-version
修改主机名
三台分别执行 vim /etc/hostname 并将内容指定为对应的主机名
关闭防火墙:systemctl stop firewalld
a.查看防火墙状态:systemctl status firewalld
b.取消防火墙自启:systemctl disable firewalld
静态IP配置
a.直接使用图形化界面配置(不推荐)
b.手动编辑配置文件进行配置

1、编辑网络配置文件 vim /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE=Ethernet BOOTPROTO=static HWADDR=00:0C:29:E2:B8:F2 NAME=ens33 DEVICE=ens33 ONBOOT=yes IPADDR=192.168.190.100 GATEWAY=192.168.190.2 NETMASK=255.255.255.0 DNS1=192.168.190.2 DNS2=223.6.6.6 需要修改:HWADDR(mac地址,centos7不需要手动指定mac地址) IPADDR(根据自己的网段,自定义IP地址) GATEWAY(根据自己的网段填写对应的网关地址) 2、关闭NetworkManager,并取消开机自启 systemctl stop NetworkManager systemctl disable NetworkManager 3、重启网络服务 systemctl restart network
免密登录
# 1、生成密钥 ssh-keygen -t rsa # 2、配置免密登录 ssh-copy-id master ssh-copy-id node1 ssh-copy-id node2 # 3、测试免密登录 ssh node1
配置好映射文件:/etc/hosts
192.168.80.100 master 192.168.80.20 node1 192.168.80.30 node2
搭建Hadoop集群
DataNode:真实数据存储的地方(block)
| 进程 | master(主) | node1(从) | node2(从) |
|---|---|---|---|
| NameNode | √ | ||
| SecondaryNameNode | √ | ||
| ResourceManager | √ | ||
| DataNode | √ | √ | |
| NodeManager | √ | √ |
完全分布式搭建
上传安装包并解压
# 使用xftp上传压缩包至master的/usr/local/soft/ cd /urs/local/soft/ # 解压 tar -zxvf hadoop-2.7.6.tar.gz
配置环境变量
1 2 3 4 5 6 | vim /etc/profile(标颜色的需要加)HADOOP_HOME=/usr/local/soft/hadoop-2.7.6export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH# 重新加载环境变量source /etc/profile |
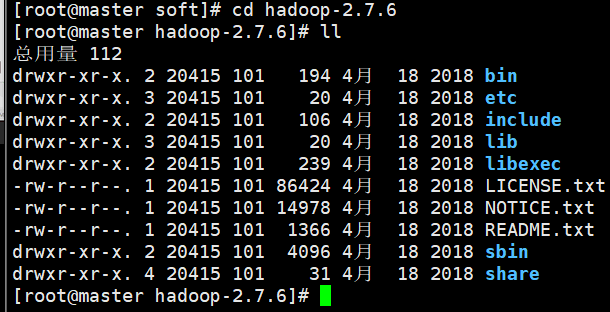
bin存放启动之后操作hadoop的命令
sbi存放启动时存放hadoop的命令
etc存放一些配置文件
lib存放超链接或者软连接
修改hadoop配置文件
目录:cd /usr/local/soft/hadoop-2.7.6/etc/hadoop/
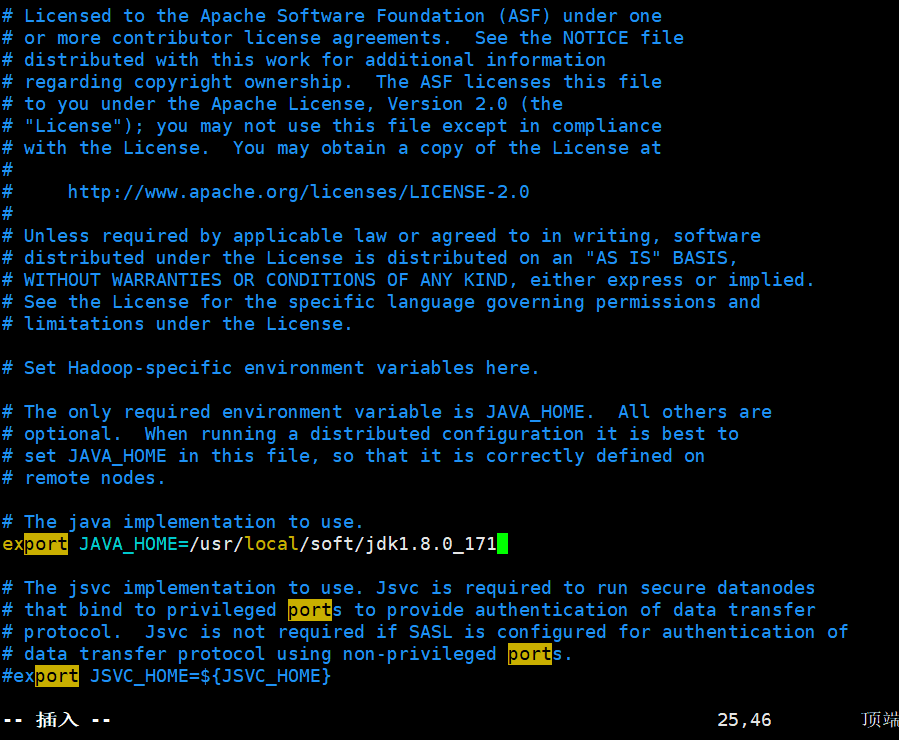
1.hadoop-env.sh
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
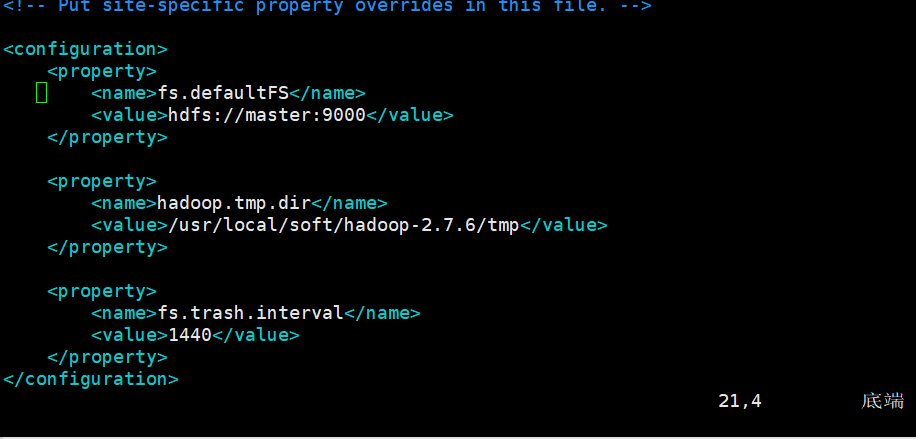
2.core-site.xml文件(hadoop核心配置)
- hadoop.tmp.dir:是 hadoop文件系统依赖的基本配置,很多配置路径都依赖它,它的默认位置是在 /tmp/{$user}下面,注意这是个临时目录!!!因此,它的持久化配置很重要的! 如果选择默认,一旦因为断电等外在因素影响,/tmp/{$user}下的所有东西都会丢失。
- fs.trash.interval:启用垃圾箱配置,dfs命令删除的文件不会立即从HDFS中删除。相反,HDFS将其移动到垃圾目录(每个用户在
/user/<username>/.Trash
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value></property><property> <name>hadoop.tmp.dir</name> <value>/usr/local/soft/hadoop-2.7.6/tmp</value></property><property> <name>fs.trash.interval</name> <value>1440</value></property> |
3.hdfs-site.xml
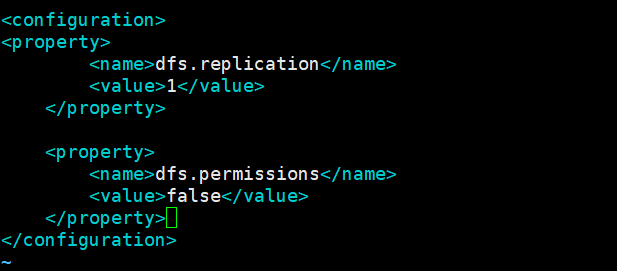
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
4.mapred-site.xml.template
- mapreduce.jobhistory.address:Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,Hadoop历史服务器是没有启动的,我们可以通过*mr-jobhistory-daemon.sh start historyserver
# 1、重命名文件 cp mapred-site.xml.template mapred-site.xml # 2、修改 <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property>
5.yarn-site.xml
- yarn.resourcemanager.hostname:指定yarn主节点
- yarn.log-aggregation-enable:yarn日志聚合功能开关
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
6.slaves
从节点的信息(前提是已经配置了映射)
node1
node2
在文件中有一个localhost,意思是既是主节点又是从节点,属于伪分布是搭建
最后把/usr/local/soft目录下的hadoop-2.7.6文件复制给node1,node2
cd /usr/local/soft/ scp -r hadoop-2.7.6/ node1:`pwd` scp -r hadoop-2.7.6/ node2:`pwd`
格式化namenode(第一次启动的时候需要执行。以及每次修改核心配置文件后都需要)
cd /usr/local/soft/hadoop-2.7.6/bin/(在这个目录下做)
hdfs namenode -format
格式化在master节点下去做
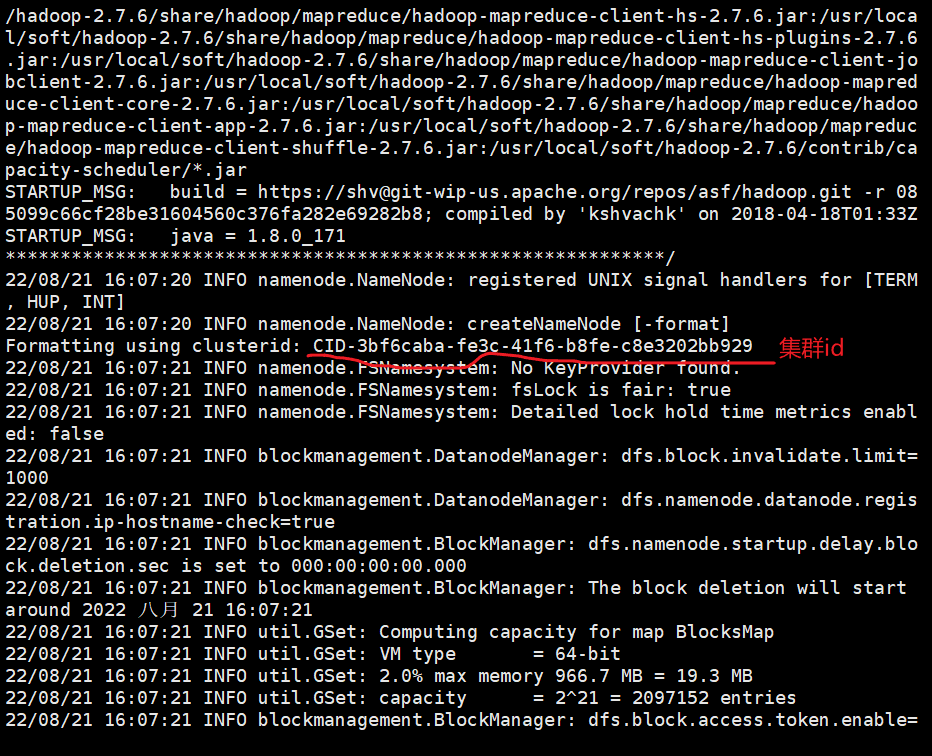
格式化之后在hadoop-2.7.6下产生一个tmp文件
在sbin目录下有单独启动hdfs和yarn的命令
后缀是cmd是windows下的命令,sh是linux的命令
start-all.sh先启动与hdfs相关的,后启动与yarn相关的
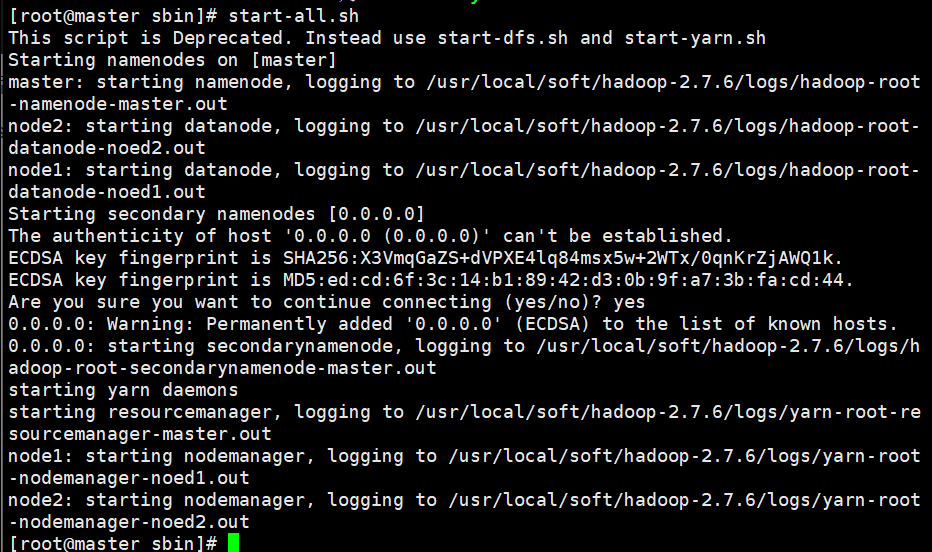
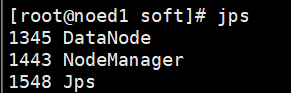
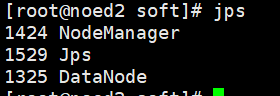
检查master、node1、node2上的进程(jps只能看java进程)
master
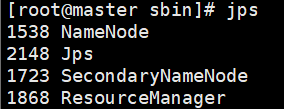
node1
node2
访问可视化工具(主节点+端口号:50070是2.7.6的固定端口号)访问HDFS的WEB界面
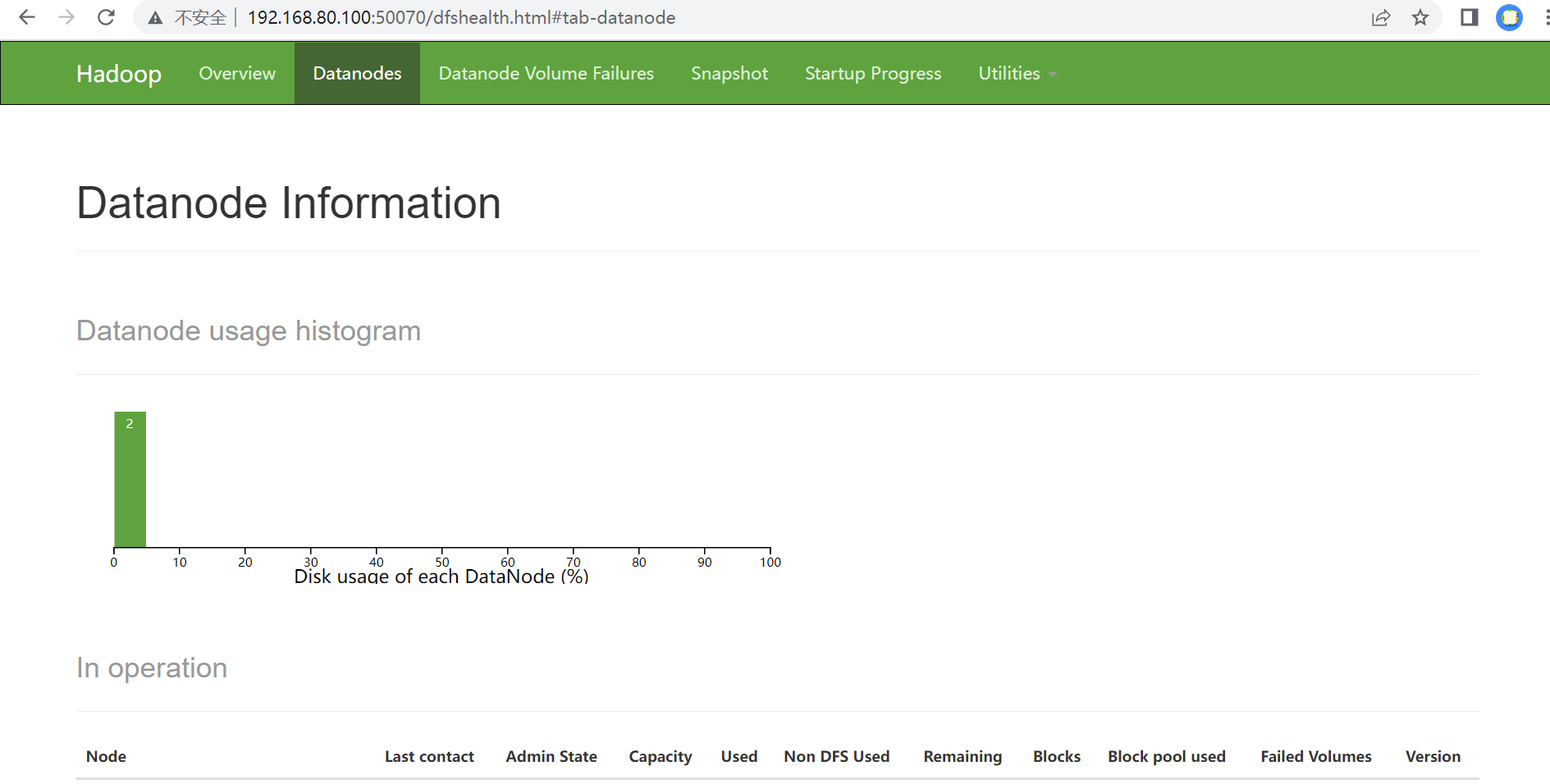
utilities里browse system file可以查看文件
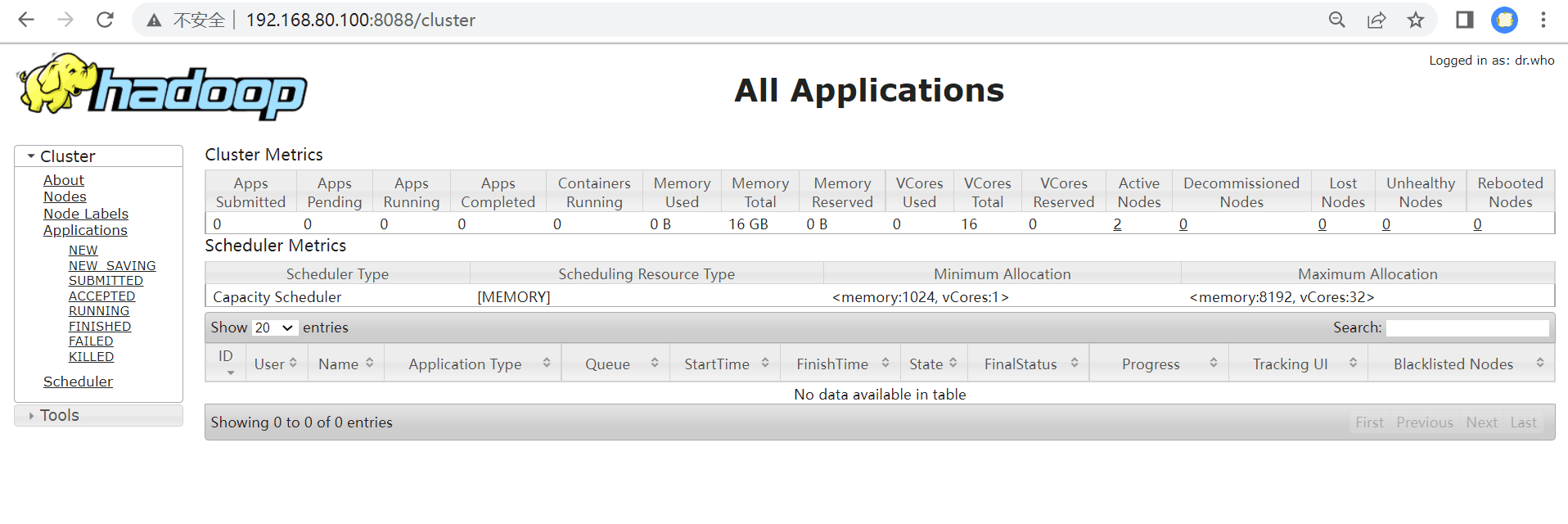
访问YARN的WEB界面(主节点+端口号:端口号是8088)
Hadoop中的常见的shell命令(前缀是hadoop fs或者是hdfs dfs) 1、如何将linux本地的数据上传到HDFS中呢? hadoop fs -put 本地的文件 HDFS中的目录 hdfs dfs -put 本地的文件 HDFS中的目录
2、如何创建HDFS中的文件夹呢? 需求:想创建/shujia/bigdata17 hadoop fs -mkdir /shujia/bigdata17 hdfs dfs -mkdir /shujia/bigdata17
在hdfs的web网页中输入/查看文件
创建递归文件
例如:hdfs dfs -mkdir -p /wyy/bigdata19/test 3、查看当前HDFS目录下的文件和文件夹 hadoop fs -ls /shujia/bigdata17 hdfs dfs -ls /shujia/bigdata17
查看文件内容:hdfs dfs -cat /wqy/d.txt 4、将HDFS的文件下载到Linux本地中 hadoop fs -get HDFS中的文件目录 本地要存放文件的目录 hdfs dfs -get HDFS中的文件目录 本地要存放文件的目录
例如:hdfs dfs -get /wqy/d.txt /usr/local/soft/ 5、删除命令(如果垃圾回收站大小小于被删除文件的大小,直接被删除,
不经过回收站。。。删除文件后可在垃圾站回收)
hadoop fs -rm .... # 仅删除文件 hadoop fs -rmr .... # 删除文件夹
6、移动文件 hadoop fs -mv 目标文件 目的地路径 7、HDFS内部复制文件 hadoop fs -cp [-p] ... ... # 如果想复制文件夹,加上-p参数
例如:hdfs dfs -cp /wqy/d.txt /wyy/bigdata19/test/
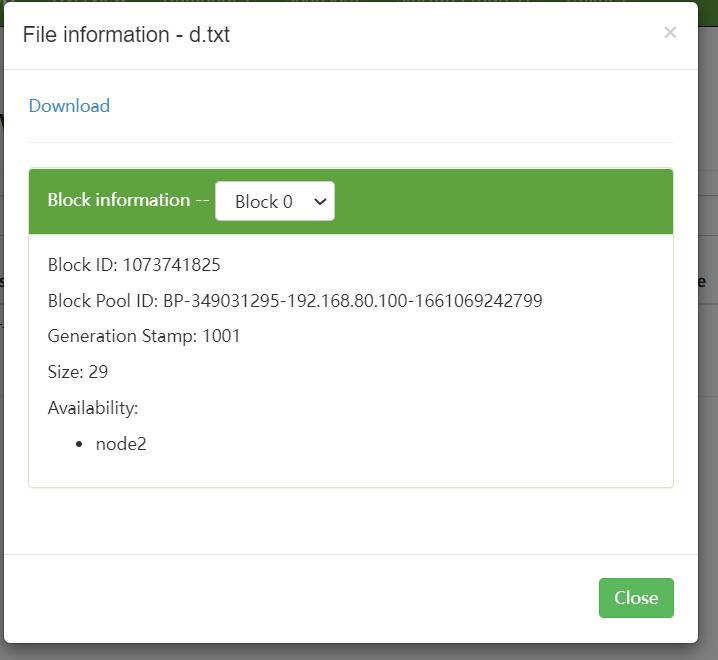
block位置:/usr/local/soft/hadoop-2.7.6/tmp/dfs/data/current/BP-349031295-192.168.80.100-1661069242799/current/finalized/subdir0/subdir0

meta是一个校验文件
在windows下配置节点映射
C:\Windows\System32\drivers\etc下hosts里配置ip地址和名字
强制格式化集群(遇到问题的简单暴力的方法)
stop-all.sh
2、删除所有节点hadoop根目录中的tmp文件夹
3、在主节点(master)中hadoop的根目录中的bin目录下,重新格式化HDFS
./hdfs namenode -format
4、启动集群



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构