

redis day2
持久化机制
client redis[内存] -----> 内存数据- 数据持久化-->磁盘
Redis官方提供了两种不同的持久化方法来将内存的数据存储到硬盘里面分别是:
-
快照(Snapshot)
-
AOF (Append Only File) 只追加日志文件
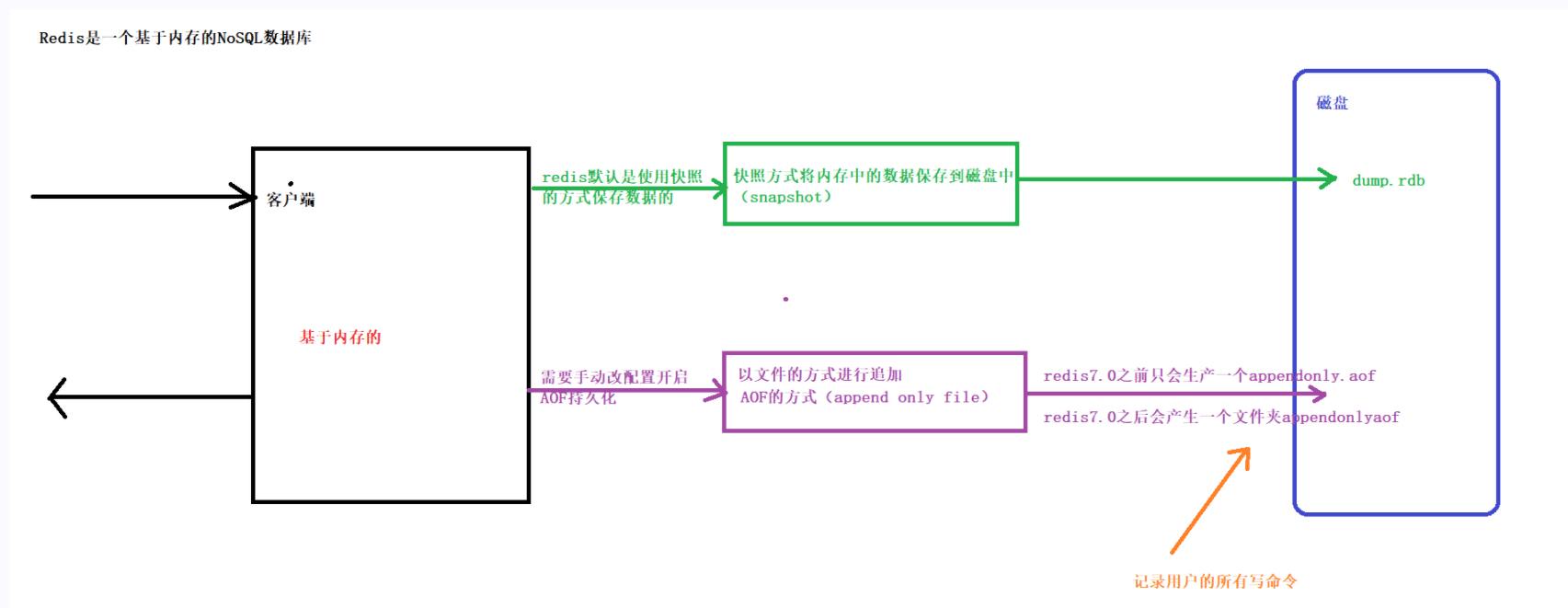
快照(Snapshot)
特点:
官方说法叫做快照持久化
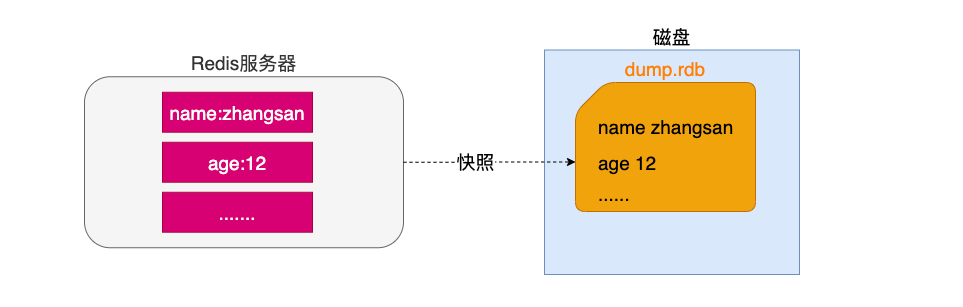
快照生成方式:
# 1.客户端方式之BGSAVE(bg就是background)
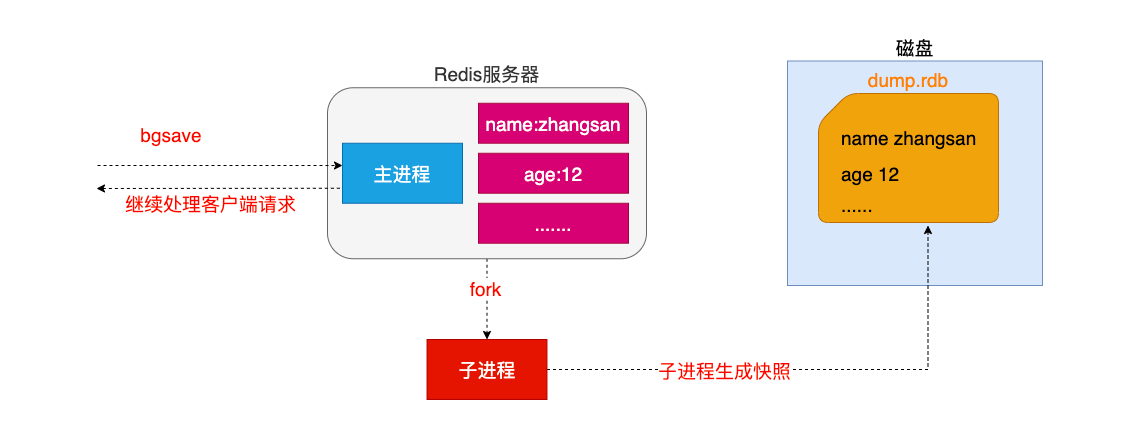
- a.客户端可以使用BGSAVE命令来创建一个快照,当接收到客户端的BGSAVE命令时,redis会调用fork¹来创建一个子进程,然后子进程负责将快照写入磁盘中,而父进程则继续处理命令请求。(rdb的形式保存数据会重新开一个进程)

`名词解释: fork当一个进程创建子进程的时候,底层的操作系统会创建该进程的一个副本,在类似于unix系统中创建子进程的操作会进行优化:在刚开始的时候,父子进程共享相同内存,直到父进程或子进程对内存进行了写之后,对被写入的内存的共享才会结束服务`
子进程运行时需要时间,这时父进程会处理别的请求,不妨碍子进程存储快照,但是新的请求没有被拍快照,所以如果这时突然断电,新的请求数据会丢掉
# 2.客户端方式之SAVE(save命令不常用,使用save命令在快照创建完毕之前,redis处于阻塞状态,无法对外服务)
直接用自己的进程拍摄,但是会有新的请求被阻塞
- b.客户端还可以使用SAVE命令来创建一个快照,接收到SAVE命令的redis服务器在快照创建完毕之前将不再响应任何其他的命令
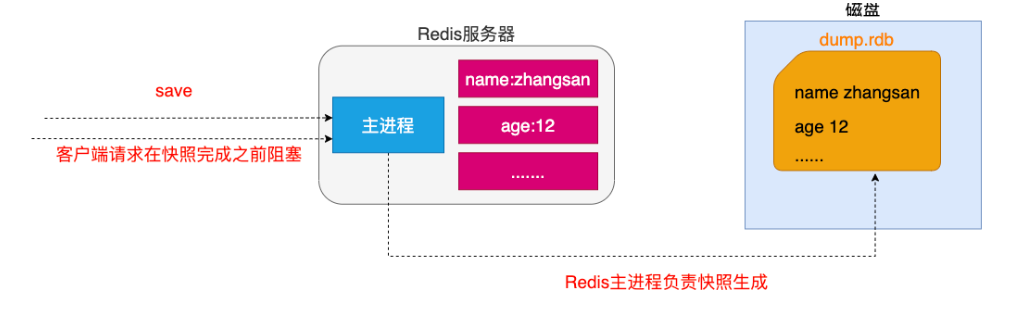
# 3.服务器配置方式之满足配置自动触发
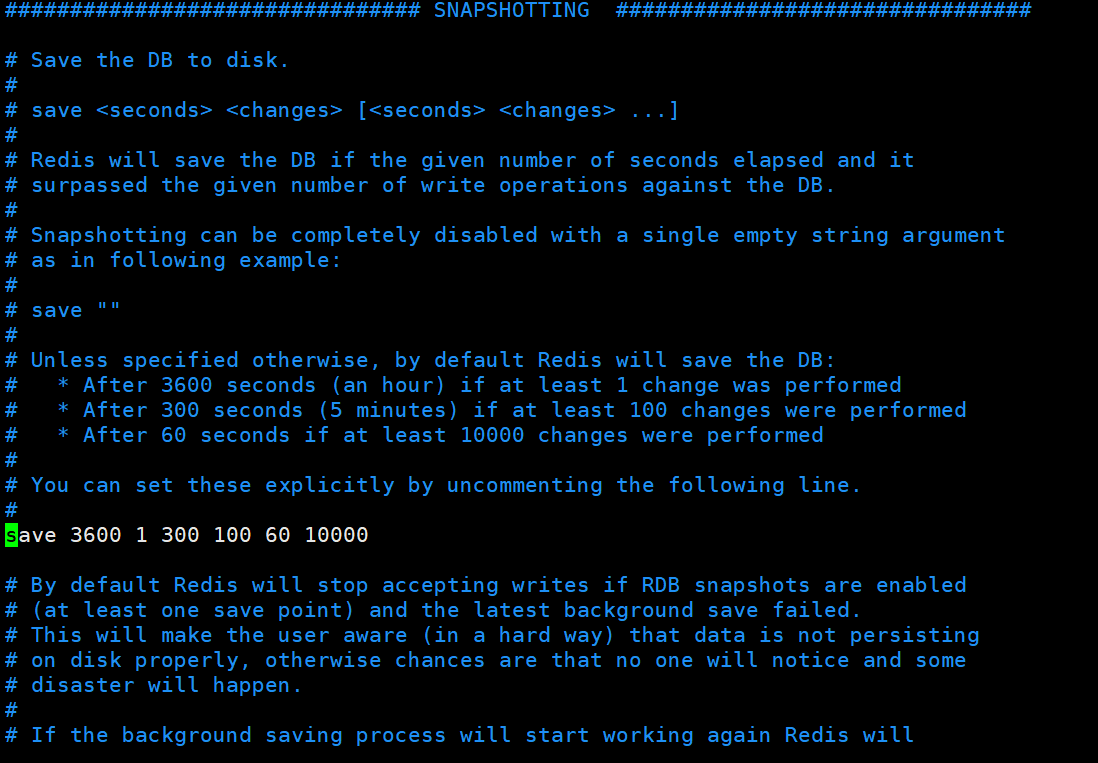
在redis.conf文件中可以修改多长时间拍摄一次快照,在SNAPSHOTTING中可以修改,这是根据业务需求决定的 - 如果用户在redis.conf中设置了save配置选项,redis会在save选项条件满足之后自动触发一次BGSAVE命令,如果设置多个save配置选项,当任意一个save配置选项条件满足,redis也会触发一次BGSAVE命令
# 4.服务器接收客户端shutdown指令
- 当redis通过shutdown指令接收到关闭服务器的请求时,会执行一个save命令,阻塞所有的客户端,不再执行客户端执行发送的任何命令,并且在save命令执行完毕之后关闭服务器
配置生成快照名称
#1.修改生成快照名称(在redis.conf文件里的snopshotting中修改) - dbfilename dump.rdb # 2.修改生成位置 - dir ./()
rdb方式优点
- RDB快照保存了某个时间点的数据,可以通过脚本执行redis指令bgsave(非阻塞,后台执行)或者save(会阻塞写操作,不推荐)命令自定义时间点备份,可以保留多个备份,当出现问题可以恢复到不同时间点的版本,很适合备份,并且此文件格式也支持有不少第三方工具可以进行后续的数据分析。
- 比如: 可以在最近的24小时内,每小时备份一次RDB文件,并且在每个月的每一天,也备份一个RDB文件。这样的话,即使遇上问题,也可以随时将数据集还原到不同的版本。
- RDB可以最大化Redis的性能,父进程在保存 RDB文件时唯一要做的就是fork出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘工/0操作。
- RDB在大量数据,比如几个G的数据,恢复的速度比AOF的快。
rdb方式缺陷
不能实时保存数据,可能会丢失自上一次执行RDB备份到当前的内存数据
如果你需要尽量避免在服务器故障时丢失数据,那么RDB并不适合。虽然Redis允许设置不同的保存点(save point)来控制保存RDB文件的频率,但是,因为RDB文件需要保存整个数据集的状态,所以它并不是一个轻松快速的操作。因此一般会超过5分钟以上才保存一次RDB文件。在这种情况下,一旦发生故障停机,你就可能会丢失好几分钟的数据。
当数据量非常大的时候,从父进程fork子进程进行保存至RDB文件时需要一点时间,可能是毫秒或者秒,取决于磁盘IO性能
在数据集比较庞大时,fork()可能会非常耗时,造成服务器在一定时间内停止处理客户端﹔如果数据集非常巨大,并且CPU时间非常紧张的话,那么这种停止时间甚至可能会长达整整一秒或更久。虽然 AOF重写也需要进行fork(),但无论AOF重写的执行间隔有多长,数据的持久性都不会有任何损失。
AOF只追加日志文件
特点:
在redis的默认配置中AOF持久化机制是没有开启的,需要在配置中开启(在redis.conf文件中APPEND ONLY MODE下把appendonly no改成appendonly yes)
# 1.开启AOF持久化 - a.修改 appendonly yes 开启持久化 - b.修改 appendfilename "appendonly.aof" 指定生成文件名称
每次换过之后需要重启redis服务
# 1.always 【谨慎使用】 - 说明: 每个redis写命令都要同步写入硬盘,严重降低redis速度 - 解释: 如果用户使用了always选项,那么每个redis写命令都会被写入硬盘,从而将发生系统崩溃时出现的数据丢失减到最少;遗憾的是,因为这种同步策略需要对硬盘进行大量的写入操作,
所以redis处理命令的速度会受到硬盘性能的限制; - 注意: 转盘式硬盘在这种频率下200左右个命令/s ; 固态硬盘(SSD) 几百万个命令/s; - 警告: 使用SSD用户请谨慎使用always选项,这种模式不断写入少量数据的做法有可能会引发严重的`写入放大`问题,导致将固态硬盘的寿命从原来的几年降低为几个月。 # 2.everysec 【推荐默认】 - 说明: 每秒执行一次同步显式的将多个写命令同步到磁盘 - 解释: 为了兼顾数据安全和写入性能,用户可以考虑使用everysec选项,让redis每秒一次的频率对AOF文件进行同步;redis每秒同步一次AOF文件时性能和不使用任何持久化特性时的性能相差无几,
而通过每秒同步一次AOF文件,redis可以保证,即使系统崩溃,用户最多丢失一秒之内产生的数据。 # 3.no 【不推荐】 - 说明: 由操作系统决定何时同步 - 解释:最后使用no选项,将完全由操作系统决定什么时候同步AOF日志文件,这个选项不会对redis性能带来影响但是系统崩溃时,会丢失不定数量的数据,甚至丢失全部数据,另外如果用户硬盘处理写入操作不够快的话,
当缓冲区被等待写入硬盘数据填满时,redis会处于阻塞状态,并导致redis的处理命令请求的速度变慢。
# 1.修改日志同步频率 - 修改appendfsync everysec|always|no 指定
AOF文件的重写机制(重要)


下图的第一个文件是上面图片中第一个文件和第二个文件的结合,下图的第二个文件处理新的请求
redi.conf中的配置图片

当aof.incr超出68mb的100%时(即128mb)重写
AOF带来的问题:
AOF的方式也同时带来了另一个问题。持久化文件会变的越来越大。例如我们调用incr test命令100次,文件中必须保存全部的100条命令,其实有99条都是多余的。因为要恢复数据库的状态其实文件中保存一条set test 100就够了。为了压缩aof的持久化文件Redis提供了AOF重写(ReWriter)机制。
AOF重写
用来在一定程度上减小AOF文件的体积,并且还能保证数据不丢失
触发重写方式
# 1.客户端方式触发重写 - 执行BGREWRITEAOF命令 不会阻塞redis的服务 # 2.服务器配置方式自动触发 - 配置redis.conf中的auto-aof-rewrite-percentage选项 参加下图↓↓↓ - 如果设置auto-aof-rewrite-percentage值为100和auto-aof-rewrite-min-size 64mb,并且启用的AOF持久化时,那么当AOF文件体积大于64M,并且AOF文件的体积比上一次重写之后体积大了至少一倍(100%)时,
会自动触发,如果重写过于频繁,用户可以考虑将auto-aof-rewrite-percentage设置为更大
从 Redis 7.0.0 开始,Redis 使用了多部分 AOF 机制。也就是将原来的单个AOF文件拆分为基础文件(最多一个)和增量文件(可能不止一个)。
从 Redis 7.0.0 开始,在调度 AOF 重写时,Redis 父进程会打开一个新的增量 AOF 文件继续写入。子进程执行重写逻辑并生成新的基础 AOF。Redis 将使用一个临时清单文件来跟踪新生成的基础文件和增量文件。当它们准备好后,Redis 会执行原子替换操作,使这个临时清单文件生效。为了避免在 AOF 重写重复失败和重试的情况下创建大量增量文件的问题,Redis 引入了 AOF 重写限制机制,以确保失败的 AOF 重写以越来越慢的速度重试。
日志重写
注意:重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,替换原有的文件这点和快照有点类似。
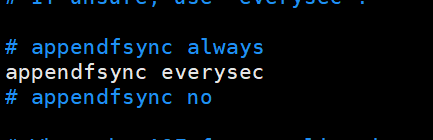
# 重写流程 - 1. redis调用fork ,现在有父子两个进程 子进程根据内存中的数据库快照,往临时文件中写入重建数据库状态的命令 - 2. 父进程继续处理client请求,除了把写命令写入到原来的aof文件中。同时把收到的写命令缓存起来。这样就能保证如果子进程重写失败的话并不会出问题。 - 3. 当子进程把快照内容写入已命令方式写到临时文件中后,子进程发信号通知父进程。然后父进程把缓存的写命令也写入到临时文件。 - 4. 现在父进程可以使用临时文件替换老的aof文件,并重命名,后面收到的写命令也开始往新的aof文件中追加。
redis7.0.0之前:(1.新文件和旧文件做的是同样的事情)
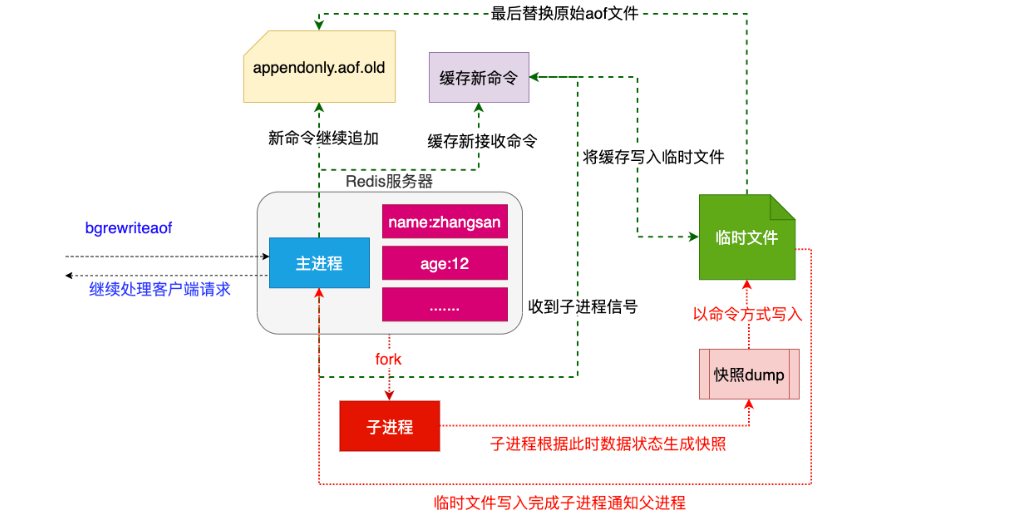
过程:先调用linux里的fork生成一个子进程,然后子进程根据此时数据状态生成一个快照,
快照以命令的方式写到临时文件,(需要时间),会有新的命令过来,继续追加,
只有一个旧文件,既要做快照,也要继续接收,redis继续接收新的命令,同时也会
把缓存写入到临时文件,临时文件完成快照通知父进程,这时临时文件会把原来的
旧文件替换掉,名字叫做appendonly.aof
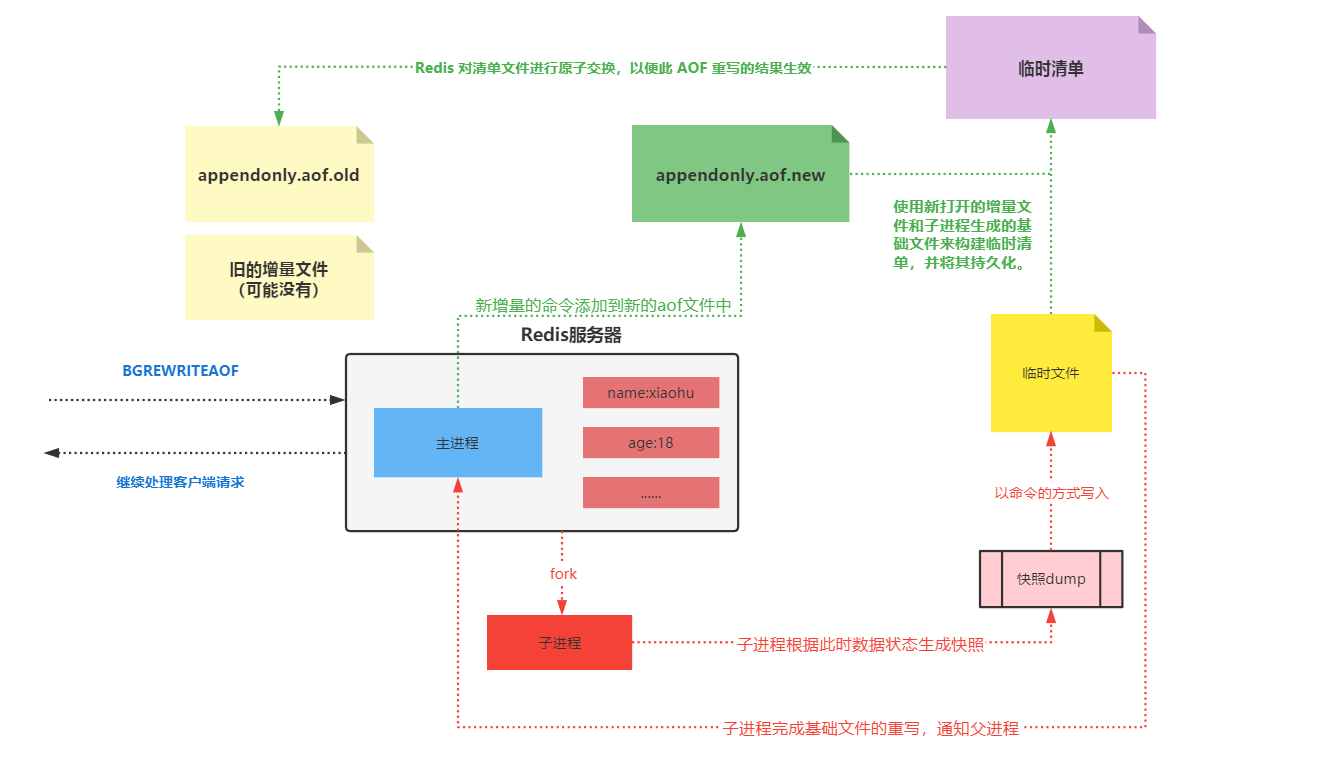
过程:
触发重写机制(通过BGREWRITEAOF或者自动触发),主进程调用fork开启
子进程,
先调用linux里的fork生成一个子进程,然后子进程根据此时数据状态生成一个快照,
快照以命令的方式写到临时文件,
有新的命令过来,主进程会重新创建一个新的aof文件,接受新的命令,临时
文件写完后通知父进程,之后把新的aof文件和临时文件合并成临时清单(底层有
自己的压缩算法把文件变小),最后把临时清单替换掉旧的aof文件(base.aof)。
然后会创建一个新的aof文件接受新的请求。
- 数据安全性相对较高,根据所使用的fsync策略(fsync是同步内存中redis所有已经修改的文件到存储设备),默认是appendfsync everysec,即每秒执行一次 fsync,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据( fsync会在后台线程执行,所以主线程可以继续努力地处理命令请求)。
- 由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中不需要seek, 即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,可以通过 redis-check-aof 工具来解决数据一致性的问题。
- Redis可以在 AOF文件体积变得过大时,自动地在后台对AOF进行重写,重写后的新AOF文件包含了恢复当前数据集所需的最小命令集合。整个重写操作是绝对安全的,因为Redis在创建新 AOF文件的过程中,append模式不断的将修改数据追加到现有的 AOF文件里面,即使重写过程中发生停机,现有的 AOF文件也不会丢失。而一旦新AOF文件创建完毕,Redis就会从旧AOF文件切换到新AOF文件,并开始对新AOF文件进行追加操作。
- AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,也可以通过该文件完成数据的重建。
- AOF文件有序地保存了对数据库执行的所有写入操作,这些写入操作以Redis协议的格式保存,因此 AOF文件的内容非常容易被人读懂,对文件进行分析(parse)也很轻松。导出(export)AOF文件也非常简单:举个例子,如果不小心执行了FLUSHALL.命令,但只要AOF文件未被重写,那么只要停止服务器,移除 AOF文件末尾的FLUSHAL命令,并重启Redis ,就可以将数据集恢复到FLUSHALL执行之前的状态。
AOF缺点
- 即使有些操作是重复的也会全部记录,AOF 的文件大小要大于 RDB 格式的文件。
- AOF 在恢复大数据集时的速度比 RDB 的恢复速度要慢。
- 根据fsync策略不同,AOF速度可能会慢于RDB。
- bug 出现的可能性更多。
RDB和AOF的选择
- 如果主要充当缓存功能,或者可以承受数分钟数据的丢失, 通常生产环境一般只需启用RDB即可,此也是默认值。
- 如果数据需要持久保存,一点不能丢失,可以选择同时开启RDB和AOF。
- 一般不建议只开启AOF。
无论使用AOF还是快照机制持久化,将数据持久化到硬盘都是有必要的,除了持久化外,用户还应该对持久化的文件进行备份(最好备份在多个不同地方)。
位图不是真正的数据类型,它是定义在字符串类型中,一个字符串类型的值最多能存储512M字节的内容
位上限:2^(9(512)+10(1024)+10(1024)+3(8b=1B))=2^32b
setbit设置某一位上的值
语法:SETBIT key offset value (offset位偏移量,从0开始)
127.0.0.1:7000> flushall OK 127.0.0.1:7000> setbit k1 1 1 0 127.0.0.1:7000> get k1 @ 127.0.0.1:7000> setbit k1 7 1 0 127.0.0.1:7000> get k1 A 127.0.0.1:7000> setbit k1 7 2 ERR bit is not an integer or out of range

127.0.0.1:7000> setbit k1 9 1 0 127.0.0.1:7000> get k1 A@

getbit过去某一位上的值
语法:GETBIT key offset
127.0.0.1:7000> getbit k1 7 1 127.0.0.1:7000> getbit k1 8 0 127.0.0.1:7000> getbit k1 1 1

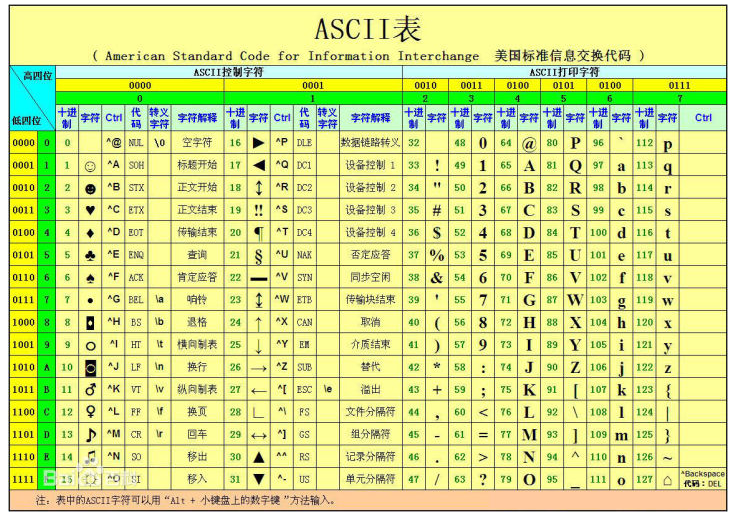
bitpos返回指定值0或1在指定区间上首次出现的下标
语法:BITPOS key bit [start] [end](字节索引,0表示第一个字节)
不指定查找范围,表示从全部内容中查找 (bitpos key bit)
127.0.0.1:7000> keys * k1 127.0.0.1:7000> bitpos k1 1 1 127.0.0.1:7000> setbit k1 1 0 1 127.0.0.1:7000> bitpos k1 1 7 127.0.0.1:7000> setbit k1 7 0 1 127.0.0.1:7000> bitpos k1 1 9
指定查找范围: BITPOS key bit start :从start+1个字节开始查找,直到尾部 BITPOS key bit start end:从start+1字节开始到end+1字节之间查找 然后将数据还原: 127.0.0.1:7000> setbit k1 1 1 0 127.0.0.1:7000> setbit k1 7 1 0
查找演示:
127.0.0.1:7000> bitpos k1 1 0 0 1 #在第一个字节中查找1首次出现的下标 127.0.0.1:7000> bitpos k1 1 0 1 #从第一个字节到值得最后一个字节查找1首次出现的下标 127.0.0.1:7000> setbit k1 1 0 1 #将指定下标的值改为0 127.0.0.1:7000> bitpos k1 1 0 0 7 # 127.0.0.1:7000> bitpos k1 1 0 7 127.0.0.1:7000> setbit k1 7 0 1 127.0.0.1:7000> bitpos k1 1 0 0 -1 #在第一个字节中没有找到1,则返回-1 127.0.0.1:7000> bitpos k1 1 0 9 #从第一个字节到值得最后一个字节查找 127.0.0.1:7000> bitpos k1 1 0 1 9 #在第1和第2个字节总找1首次出现的位置 127.0.0.1:7000> bitpos k1 1 0 2 9 #在第1到第3个字节查找1首次出现的位置,但数据总共2(小于end对应的3)个字节,不会抛错。
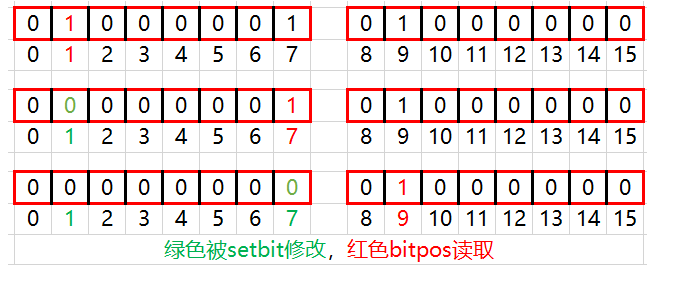
对一个或多个保存二进制位的字符串 key 进行位操作,并将结果保存到 destkey 上。operation 可以是 AND 、 OR 、 NOT 、 XOR 这四种操作中的任意一种
- BITOP AND destkey key [key ...] ,对一个或多个 key 求逻与,并将结果保存到 destkey
- BITOP OR destkey key [key ...] ,对一个或多个 key 求逻辑或,并将结果保存到 destkey
- BITOP XOR destkey key [key ...] ,对一个或多个 key 求逻辑异或,并将结果保存到 destkey
- BITOP NOT destkey key ,对给定 key 求逻辑非,并将结果保存到 destkey
除了 NOT 操作之外,其他操作都可以接受一个或多个 key 作为输入,当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作 0,空的 key 也被看作是包含 0 的字符串序列
BITOP AND destkey key [key ...]演示: 127.0.0.1:7000> flushall OK 127.0.0.1:7000> keys * (empty list or set) 127.0.0.1:7000> setbit k1 1 1 (integer) 0 127.0.0.1:7000> setbit k2 7 1 (integer) 0 127.0.0.1:7000> bitop and k3 k1 k2 (integer) 1 127.0.0.1:7000> get k3 "\x00"
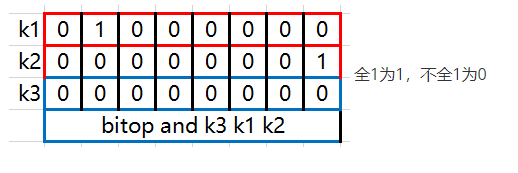
BITOP OR destkey key [key ...]演示 127.0.0.1:7000> bitop or k4 k1 k2 (integer) 1 127.0.0.1:7000> get k4 "A"
BITOP XOR destkey key [key ...]演示: 127.0.0.1:7000> bitop xor k5 k1 k2 (integer) 1 127.0.0.1:7000> get k5 "A"
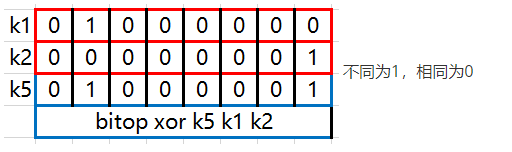
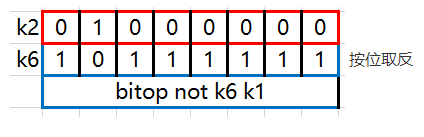
bitop not destkey key 演示: 127.0.0.1:7000> bitop not k6 k1 (integer) 1 127.0.0.1:7000> get k6 "\xbf"
bitcount 统计指定位区间上值为1的个数
-
BITCOUNT key [start] [end] start end 字节的索引 正方向,
127.0.0.1:7000> get k1 "@" 127.0.0.1:7000> bitcount k1 (integer) 1 127.0.0.1:7000> setbit k1 7 1 (integer) 0 127.0.0.1:7000> bitcount k1 (integer) 2 127.0.0.1:7000> setbit k1 9 1 (integer) 0 127.0.0.1:7000> bitcount k1 (integer) 3 #统计全部的1的总数 127.0.0.1:7000> bitcount k1 0 0 (integer) 2 #统计第一个字节中1出现的总数 127.0.0.1:7000> bitcount k1 0 1 (integer) 3 #统计第0+1到第1+1字节中1出现的总数
-
从右向左从-1开始,注意官方start、end是位,测试后是字节
127.0.0.1:7000>BITCOUNT k1 0 -1 #等同于BITCOUNT k1 (integer) 3 最常用的就是bitcount k1
redis的二进制位
127.0.0.1:7000> set k7 ab OK 127.0.0.1:7000> get k7 "ab" 127.0.0.1:7000> bitcount k7 (integer) 6 127.0.0.1:7000> bitcount k7 0 0 (integer) 3 127.0.0.1:7000> bitcount k7 1 1 (integer) 3

127.0.0.1:7000> set k8 中 OK 127.0.0.1:7000> bitcount k8 (integer) 13 127.0.0.1:7000> get k8 "\xe4\xb8\xad"
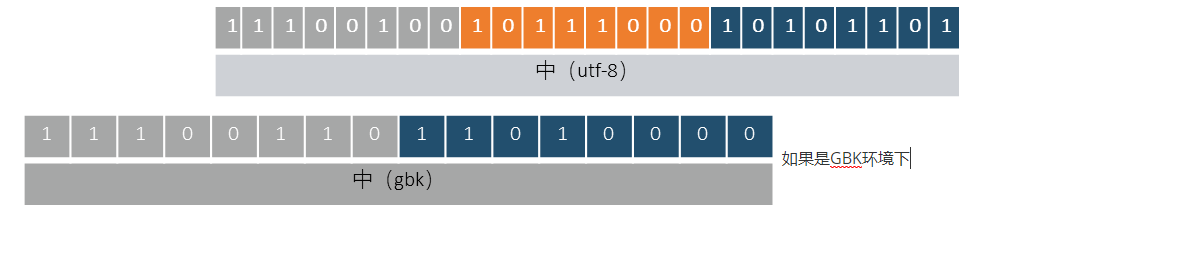
bitmap应用场景
1.网站用户签到的天数统计
用户ID为key,天作为offset,上线置为1 366> 000000000000000 366 /8=46Byte ID为18的用户,今年的第1天签到、第30天签到 127.0.0.1:7000[2]> setbit u18 1 1 (integer) 0 127.0.0.1:7000[2]> setbit u18 30 1 (integer) 0 127.0.0.1:7000[2]> bitcount u18 #统计id为18的用户签到总次数 (integer) 2 127.0.0.1:7000[2]> keys u* 1) "u18"
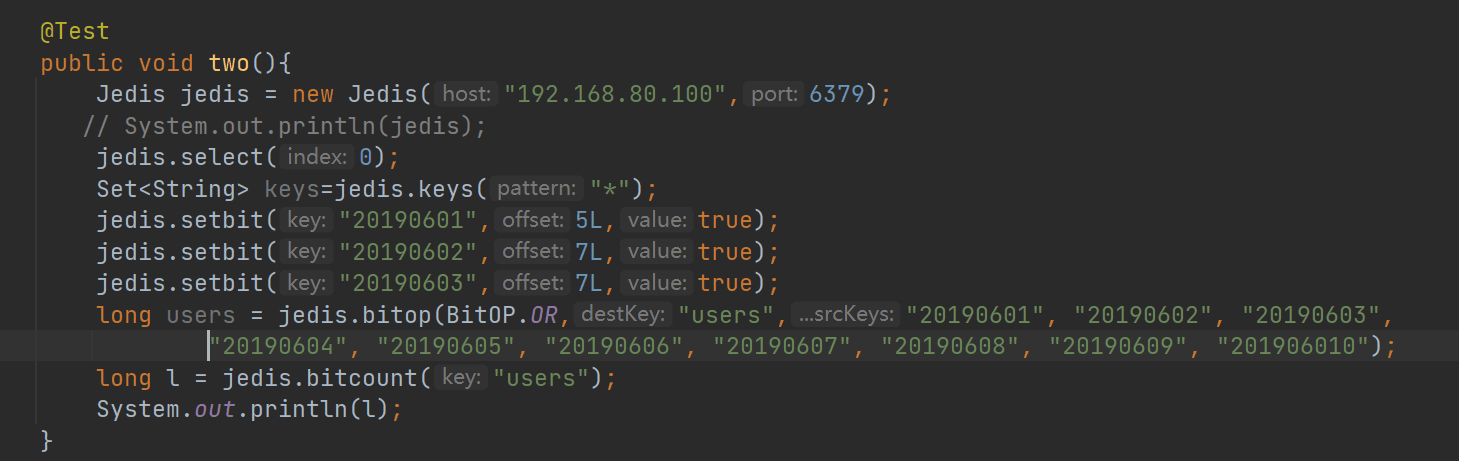
用idea实现
2.按天统计网站活跃用户
天作为key,用户ID为offset,上线置为1 求一段时间内活跃用户数 5000 0000 / 8*366= 6.3MB=*366 (五千万活跃用户1年才产生2GB左右的数据) 127.0.0.1:7000>SETBIT 20190601 5 1 #0000 0100 127.0.0.1:7000>SETBIT 20190602 7 1 #0000 0001 127.0.0.1:7000>SETBIT 20190603 7 1 #0000 0001 求6月1日到6月10日的活跃用户数 127.0.0.1:7000>BITOP OR users 20190601 20190602 20190603 ... 20190610 127.0.0.1:7000>BITCOUNT users #目标key为users 结果为2
用idea实现
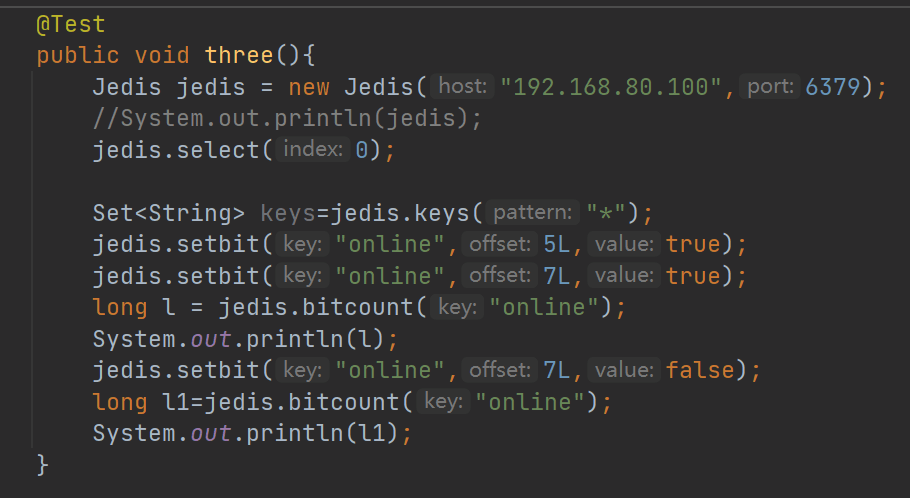
3.用户在线状态、在线人数统计
127.0.0.1:7000> SETBIT online 5 1 #0000 0100 上线为1 (integer) 0 127.0.0.1:7000> SETBIT online 7 1 #0000 0101 (integer) 0 127.0.0.1:7000> bitcount online #当前在线人数 (integer) 2 127.0.0.1:7000> SETBIT online 7 0 (integer) 1 127.0.0.1:7000> bitcount online #当前在线人数 (integer) 1
用idea实现
java操作Redis
引入依赖(我用的是4.2.3版本)
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.2.3</version>
</dependency>
创建jedis对象
public static void main(String[] args) {
//1.创建jedis对象
Jedis jedis = new Jedis("192.168.40.110", 7000);
//1.redis服务必须关闭防火墙 2.redis服务必须开启远程连接
jedis.select(0);//选择操作的库默认0号库
//2.执行相关操作
//....
//3.释放资源
jedis.close();
}
jedis在idea中的命令与在xshell中的命令一样(key,string,list,set,zset,hash)
遍历使用增强for循环
set:
set<String> keys=jedis.keys("*");
//添加值(命令与xshell中一样)
//遍历
for(String key:keys){
}
list:
List<String> list1=jedis.lrange();(long类型:常量赋值时先看一看值在不在范围内,在的话直接赋值;变量赋值会自动提升到int类型)
遍历
zset:
传一个参数
传多个参数(将多个值组装成map集合)
HashMap<Double,String> values=new HashMap<>();
传值
在redis可视化工具中查看传入的值


