

WordCount优化
WordCount优化
基本任务
PSP表格
| PSP2.1 | PSP阶段 | 预估耗时 | 实际耗时 |
|---|---|---|---|
| (分钟) | (分钟) | ||
| Planning | 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 65 |
| Development | 开发 | 90 | 102 |
| · Analysis | · 需求分析 (包括学习新技术) | 10 | 5 |
| · Design Spec | · 生成设计文档 | 10 | 12 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 | 35 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 25 |
| · Design | · 具体设计 | 10 | 5 |
| · Coding | · 具体编码 | 80 | 90 |
| · Code Review | · 代码复审 | 20 | 25 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 25 |
| Reporting | 报告 | 120 | 120 |
| · Test Report | · 测试报告 | 60 | 35 |
| · Size Measurement | · 计算工作量 | 20 | 25 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 600 | 609 |
接口实现思路
按照小组讨论的分工,我负责的是从字符串中提取并且统计词频,接口为:
HashMap<String, Integer> parseContent(String str)
这个接口接受一个String参数,表示要分析的字符串内容,返回HashMap
下面来看一下对于单词的定义,单词规定如下:
满足如下两个条件中的任意一个条件,则视为单词,
第一,由连续的若干个英文字母组成的字符串,例如,software,
第二,用连字符(即短横线)所连接的若干个英文单词也视为1个单词,例如,content-based,视为1个单词。
注意,单词不区分大小写,不考虑英文以外的其他语言,且仅考虑半角。
有关单词识别的部分典型情况的说明:
第一,Let’s,这种包含单引号的情况,视为2个单词,即let和s。
第二,night-,带短横线的单词,视为1个单词,即night。
第三,“I,带双引号的单词,视为1个单词,即i。
第四,TABLE1-2,带数字的单词,视为1个单词,即table。
第五,(see Box 3–2).8885d_c01_016,带数字、常用字符和单词的情况,视为4个单词,即see, box, d, c。
其实这么长一串总结起来就两句话:
- 单词是类似于 a、a-a、a-a-a 这种。
- 单词字母要转换成小写。
因此可以使用正则表达式来实现,代码如下(相关注释在代码中给出):
public class ContentParser {
private String regEx = "[a-zA-Z]+(-[a-zA-Z]+)*";
private Pattern pattern = Pattern.compile(regEx);
//输入文件内容,返回单词统计信息
@Test
public HashMap<String, Integer> parseContent(String content) {
HashMap<String, Integer> wordMap = new HashMap<>();
if (content == null || "".equals(content)) {
return wordMap;
}
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
String word = matcher.group().toLowerCase();
if (wordMap.containsKey(word)) {
wordMap.replace(word, wordMap.get(word) + 1);
} else {
wordMap.put(word, 1);
}
}
return wordMap;
}
}
用例设计
这里采用白盒测试 和黑盒测试的思路来进行用例设计(由于用例数量较多,这里仅给出 链接),下面分别进行说明:
黑盒测试采取等价类划分的方法,通过对上面单词的定义进行分析,对输入有如下四条划分规则:
- 是否含有字母
- 是否含有数字
- 是否含有特殊字符(除-,因为-可以被包含在单词内)
- 是否含有-
据此可以产生16个测试用例。
白盒测试对函数的路径和判定进行分析,可得到如下程序图:

通过对代码循环部分分析可以合并两个测试用例,得到五个测试用例。
测试用例文档如下:
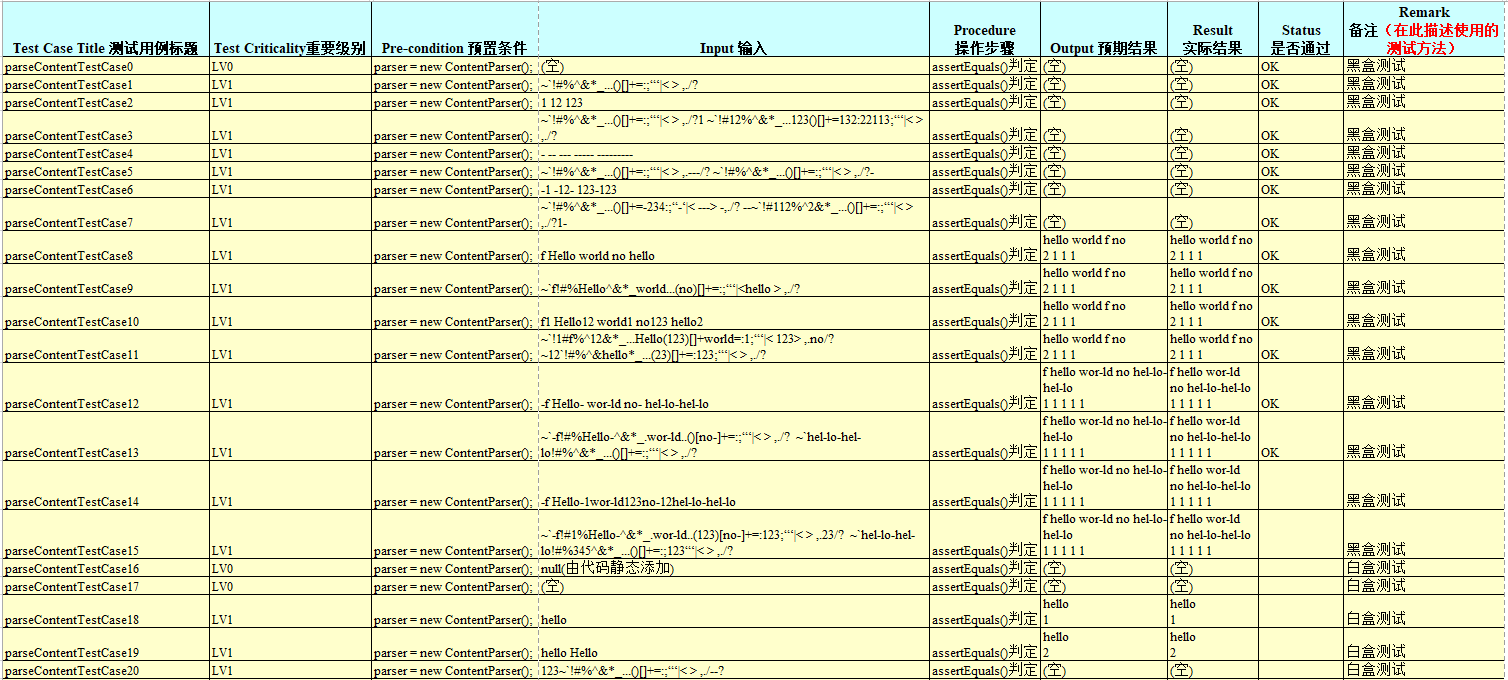
通过上面的分析可以得出结论,黑盒测试能够包含所有输入的等价类,白盒测试路径覆盖率为100%,测试用例足够少,测试足够完善,因此能够满足测试效率要求
测试结果
在代码实现时,将测试用例按照一定格式提前写入txt文件,测试时动态读取,方便了测试用例的动态管理,测试结果如下:
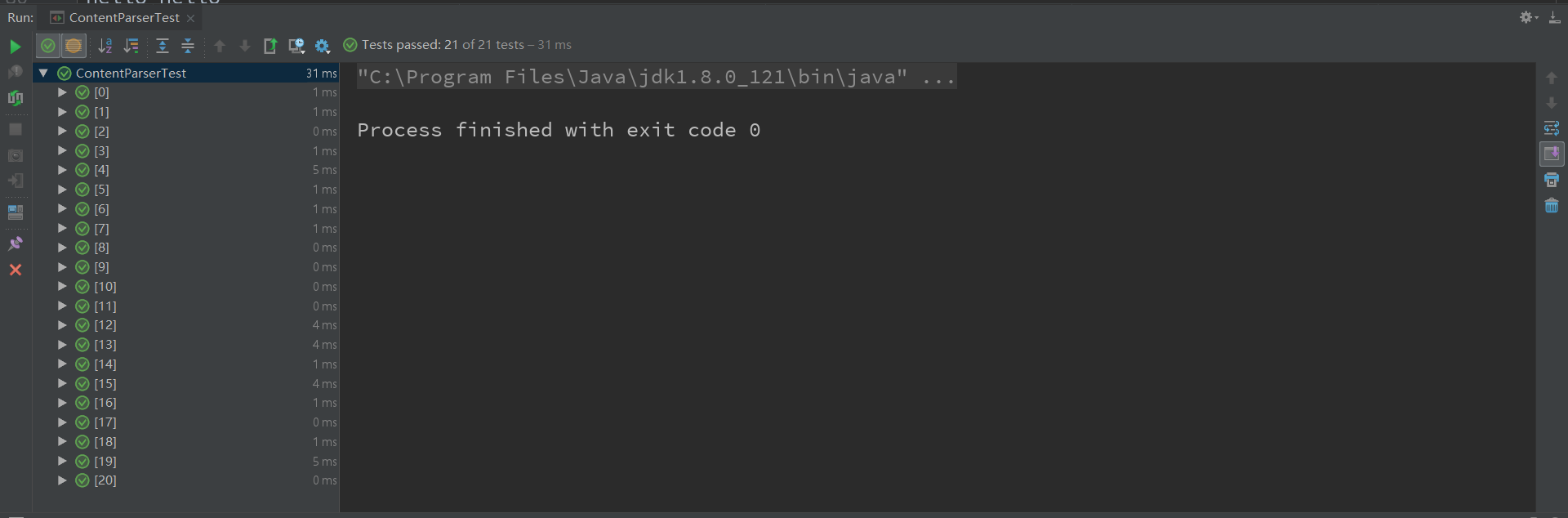
测试用例采用黑盒测试和白盒测试两种方式进行设计,黑盒测试能够包含所有输入的等价类,白盒测试路径覆盖率为100%。但是两者中出现了一部分重复的测试用例,说明黑盒测试和白盒测试具有一定的共同点。
被测试的程序通过了所有的测试用例,说明被测程序能够很好的完成程序功能,正确应对各种合理输入数据,并且能够正确处理异常输入数据,健壮性较好。
静态测试
这里根据《阿里巴巴Java开发手册》进行代码规范分析。《阿里巴巴Java开发手册》中指出,
【强制】在使用正则表达式时,利用好其预编译功能,可以有效加快正则匹配速度。
据此我将正则表达式的预编译放在了对象初始化的过程中,这样方法不论被调用多少次,预编译只会执行一次,提高了正则匹配速度和方法执行速度:
public class ContentParser {
private String regEx = "[a-zA-Z]+(-[a-zA-Z]+)*";
private Pattern pattern = Pattern.compile(regEx);
//输入文件内容,返回单词统计信息
@Test
public HashMap<String, Integer> parseContent(String content) {
······
return wordMap;
}
}
另外,《阿里巴巴Java开发手册》中指出:
【强制】类名使用UpperCamelCase风格,但以下情形例外:DO/ BO / DTO/ VO/ AO/ PO等。
【强制】方法名、参数名、成员变量、局部变量都统一使用lowerCamelCase风格,必须遵从驼峰形式
这两点对类和方法、参数等的命名做出了规范,类统一使用大驼峰命名法,方法、变量、参数等统一使用小驼峰命名法。这样可以使得代码阅读更加方便。因此在程序中类命名为ContentParser 变量方法命名类似于wordMap、parseContent。
代码规范分析
这里分析了学号为17121的同学的代码。
从变量和方法等的命名来看 ,变量和方法的命名采用了小驼峰命名法,类的命名采用了大驼峰命名法,如sort 、writeFile() 等,符合《阿里巴巴Java开发手册》中对命名规范的规定。
从工程目录规范的角度来看 ,《阿里巴巴Java开发手册》中指出:
【强制】单元测试代码必须写在如下工程目录:src/test/java,不允许写在业务代码目录下。
说明:源码构建时会跳过此目录,而单元测试框架默认是扫描此目录。
该同学的Test文件全部放在了src/test/目录下,符合开发手册的规定,方便了测试用例的管理,提高了源码构建的效率。
静态检查工具
我采用的静态检查工具是Alibaba Java Coding Guidelines,下载地址。
检查结果
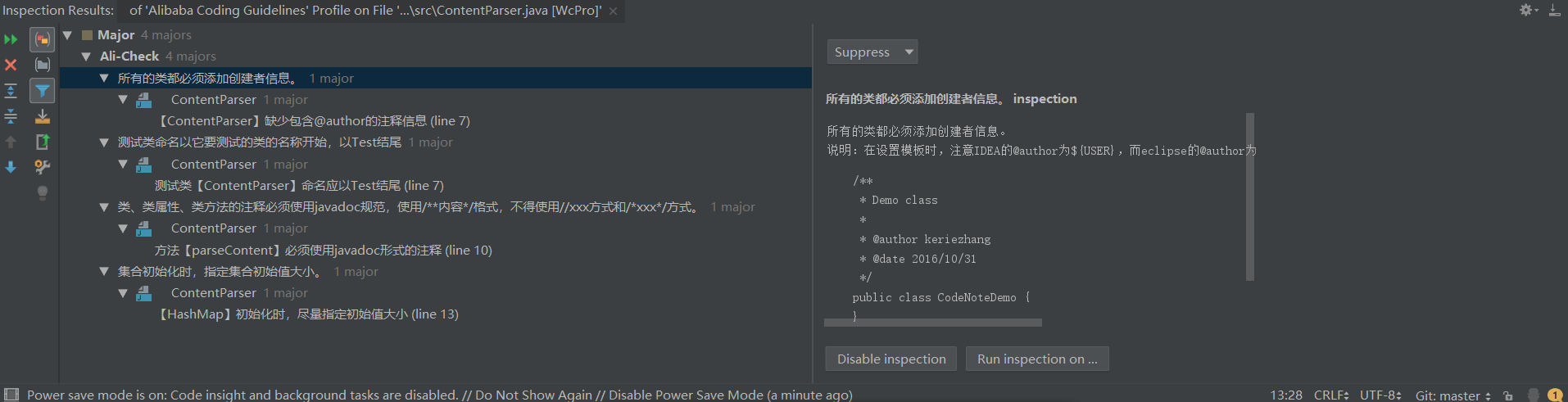
采用Alibaba Java Coding Guidelines对ContentParser进行检查,结果如下:
对ContentParserTest进行检查,结果如下:

下面对检查中出现的问题逐条进行分析:
-
对应第一条,在ContentParser中添加了author信息
-
对应第二条,因为ContentParser不是Test类,不需要以Test结尾因此属于误判。
-
对应第三条,注释内容是对方法功能的说明,因此改为使用
/**内容*/形式的注释。 -
对应第四条,由于最多分析100个单词,因此将hashmap的初值定位130。
比较好的地方是,在ContentParserTest的finally语句块中,会检查文件输出流的状态,确保不论是发生异常还是正常退出都能及时关闭。
小组代码存在的问题
- 没有及时关闭文件流
- 代码中多处出现魔法值
- 注释不规范,包括不能有尾行注释,添加author信息,使用javadoc规范注释等等
改正方法:
-
finally中判断文件流是否关闭否则关闭文件流
-
使用final定义常量
-
按照规范改写注释
高级任务
测试用例设计
我们选取了一本O'Reilly的JQury教程构造我们的测试用例,将其复制多次,得到了24.03M的txt文件,并进行测试。初步估计运行时间在1000ms以上。
优化前性能指标
测试结果如下:
| 次数 | 时间(毫秒) |
|---|---|
| 1 | 1777 |
| 2 | 1994 |
| 3 | 1978 |
| 4 | 2023 |
| 平均 | 1943 |
同行评审及结论
- 角色分工:
- 主持人&记录员:田诗园
- 讲解员:邱利光 沃锦文 王启萌 田诗园
- 评审员:邱利光 沃锦文 王启萌 田诗园
- 作者:邱利光 沃锦文 王启萌 田诗园
- 评审结果及结论
- 正则表达式效率较慢。
- 考虑到程序对查找的性能要求比较高,应当选取合适的容器类。
- 提高IO速度。
优化设计思路
- 可以用状态机来提取单词,提高效率。
- 单词统计我们采用HashMap来存储。当数据容量较少时其内部实现为一个链表,当数据量较大时,自动改用二叉树进行存储,有效提高了查询效率。
- 输出单词时,改变原来的每个单词打开一次文件的做法,只打开一次文件,全部输出后关闭文件流,提高了IO速度。
作业感想
想一想这次作业,编码的时间大概只占到了三分之一左右,剩下的时间大约三分之一用在了设计用例,编写测试框架,剩下的三分之一时间用在了写博客上。
这门课叫软件质量测试,从这次作业也可以感受到,软件测试的过程是贯穿整个开发过程中的,不管是基本功能,还是扩展任务,再到高级任务,测试的思想一直贯穿其中,基本任务要根据自己负责的模块设计二十个测试用例,扩展任务则是对自己的代码进行静态检查,也是一种软件质量测试,高级任务则是进行压力测试,检查程序的健壮性。
通过一系列测试过程,一方面让我从另一个角度了解了自己写的程序,另一方面让我对程序的健壮性有了信心,毕竟一个简单的模块写了二十个测试用例Orz
我的理解就是软件测试 贯穿了软件开发 的整个过程,保证了所开发软件的质量 。
